LongCat-Flash-Omni Technical Report
Abstract: We introduce LongCat-Flash-Omni, a state-of-the-art open-source omni-modal model with 560 billion parameters, excelling at real-time audio-visual interaction. By adopting a curriculum-inspired progressive training strategy that transitions from simpler to increasingly complex modality sequence modeling tasks, LongCat-Flash-Omni attains comprehensive multimodal capabilities while maintaining strong unimodal capability. Building upon LongCat-Flash, which adopts a high-performance Shortcut-connected Mixture-of-Experts (MoE) architecture with zero-computation experts, LongCat-Flash-Omni integrates efficient multimodal perception and speech reconstruction modules. Despite its immense size of 560B parameters (with 27B activated), LongCat-Flash-Omni achieves low-latency real-time audio-visual interaction. For training infrastructure, we developed a modality-decoupled parallelism scheme specifically designed to manage the data and model heterogeneity inherent in large-scale multimodal training. This innovative approach demonstrates exceptional efficiency by sustaining over 90% of the throughput achieved by text-only training. Extensive evaluations show that LongCat-Flash-Omni achieves state-of-the-art performance on omni-modal benchmarks among open-source models. Furthermore, it delivers highly competitive results across a wide range of modality-specific tasks, including text, image, and video understanding, as well as audio understanding and generation. We provide a comprehensive overview of the model architecture design, training procedures, and data strategies, and open-source the model to foster future research and development in the community.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces LongCat-Flash-Omni, a very large open-source AI model that can read, see, listen, speak, and understand videos in real time. Think of it as a single “all-in-one” assistant that can handle text, images, audio, and video together, and talk back to you quickly with natural speech.
It is huge (560 billion “knobs,” called parameters), but it’s designed so that only a smaller part needs to work at any moment (about 27 billion), which keeps it fast. The team also built new ways to train and run the model so it can respond with very low delay while still being smart across many tasks.
What questions were the researchers trying to answer?
They focused on four big challenges:
- How can one model learn from and combine very different kinds of data (words, sounds, pictures, and video) without being worse at any one of them?
- How can it be good at both “offline” tasks (like analyzing a photo or a long video) and “live” tasks (like watching video and listening to speech and replying instantly)?
- How can it stay fast enough for real-time conversation, even though it’s extremely large?
- How can it be trained efficiently at massive scale when each kind of data (text, audio, vision) has different needs?
How did they build and train the system?
Here’s a simple tour of the design and training, with key terms explained in everyday language.
The model at a glance
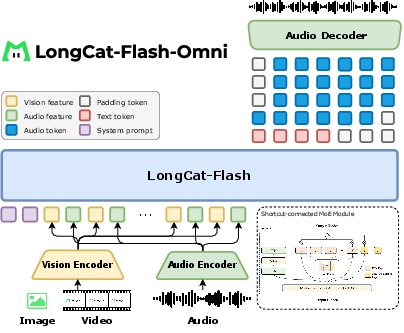
- A “Mixture-of-Experts” brain: Imagine a team of specialists. For each word or sound it processes, the model picks only a few specialists to help, instead of using the entire team. This design (MoE) gives high skill while saving time. Some “experts” can even be “skip” paths (called zero-computation experts) that avoid extra work when it’s not needed.
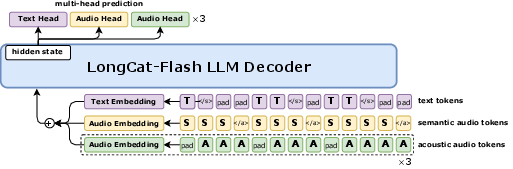
- Vision and audio “encoders”: These are like translators that turn images, video frames, and sounds into compact notes the language brain can understand.
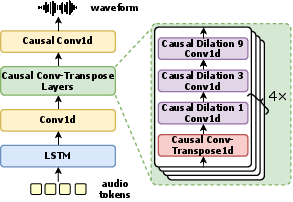
- An audio “decoder”: After the model decides what to say, this part turns its internal speech tokens (little building blocks of sound) back into a real audio waveform (so you hear a natural voice).
- Tokens: These are small pieces of information, like Lego bricks—tiny chunks of text, sound, or visual features the model uses to think.
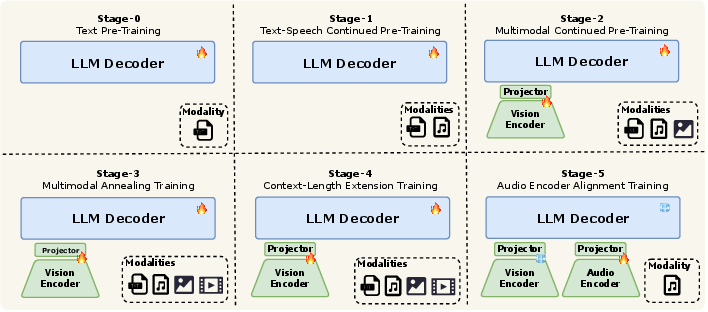
A step-by-step training plan (like moving up school grades)
Because different data types are very different, the team used a “curriculum” approach—start simple, then add complexity:
- Stage 0: Text only. First, they trained the model to be a strong reader and writer using a huge pile of text (about 16 trillion tokens).
- Stage 1: Add speech. They mixed in speech data by turning audio into discrete “speech tokens” so the model could learn how talking relates to text while keeping training simple.
- Stage 2: Add images. They brought in images (with captions) and mixed image-text data so the model could connect what it sees to what it reads and says.
- Stage 3: Add videos and specialized visual data. Video adds time and motion. They also added tasks like OCR (reading text in images), grounding (pointing to objects), GUI understanding (app screens), and STEM visuals.
- Stage 4: Long memory. They stretched the model’s “context window” (its short-term memory) up to 128,000 tokens, so it can follow long conversations, documents, or videos.
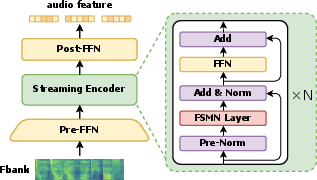
- Stage 5: Better audio input. They switched from only using “speech tokens” to also using continuous audio features through a streaming audio encoder—this captures more detail for better listening.
This gradual plan helped the model learn each skill well and then combine them smoothly.
Handling audio, images, and video
- Images: The vision encoder processes pictures and video frames at or near their original resolution to avoid losing details (instead of squeezing everything to one fixed size).
- Video: Videos are sampled at about 2 frames per second by default, with smarter sampling for very short or very long videos. The model also adds simple text timestamps like “Second{12}” to teach it about time and sequence.
- Audio:
- An audio tokenizer breaks speech into four tracks of tokens: one for meaning and three for sound details (like tone and style).
- A streaming audio encoder can listen continuously and summarize what it hears quickly (designed for low delay).
- An audio decoder turns the model’s speech tokens back into a smooth voice with very low latency.
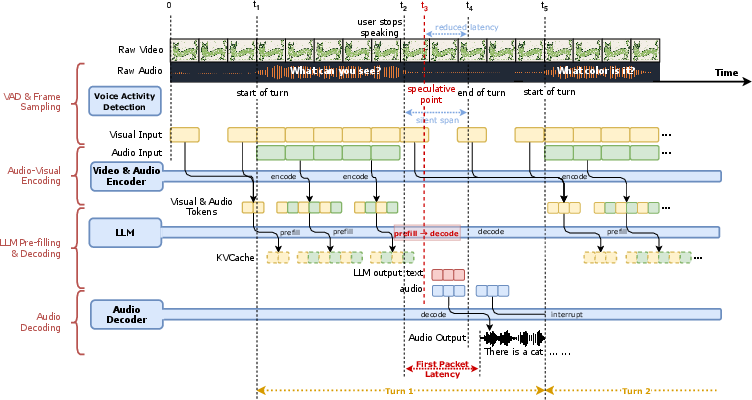
Making it fast in real time
- Chunking and interleaving: As audio and video come in, the model chops them into small 1-second chunks, lines them up by time, and feeds them in immediately—so it can start replying fast.
- Sparse-dense sampling: While the user is speaking, the model looks closely (denser sampling). While the model is speaking, it watches more lightly (sparser sampling) and saves those frames for the next turn. This balances quality and speed.
- Efficient serving: The system is engineered to keep the end-to-end delay extremely low—even though the model is huge—by activating only the needed experts and using a streaming pipeline.
Training efficiently at scale
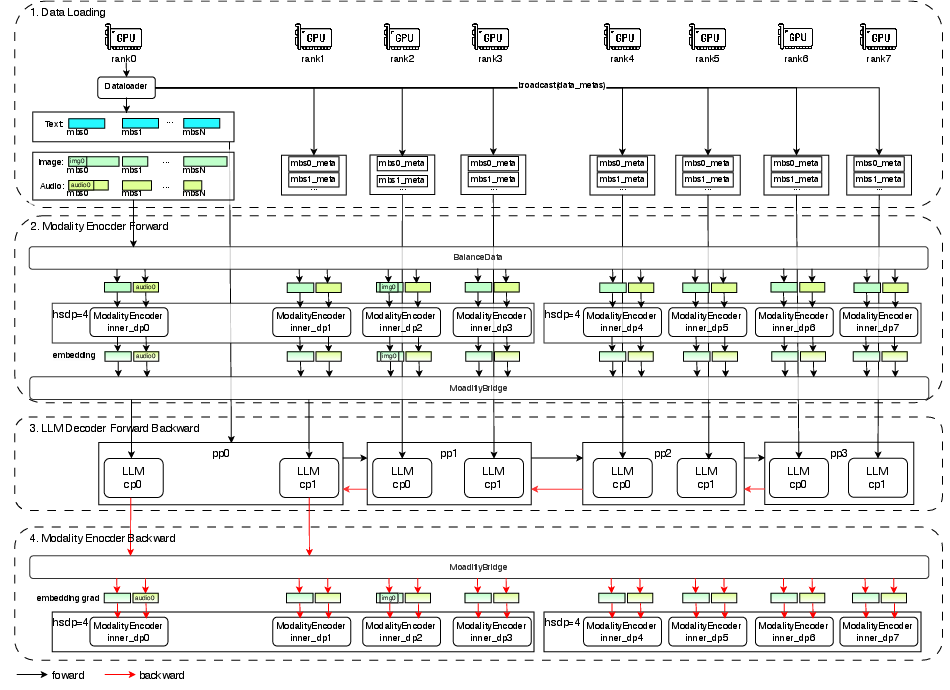
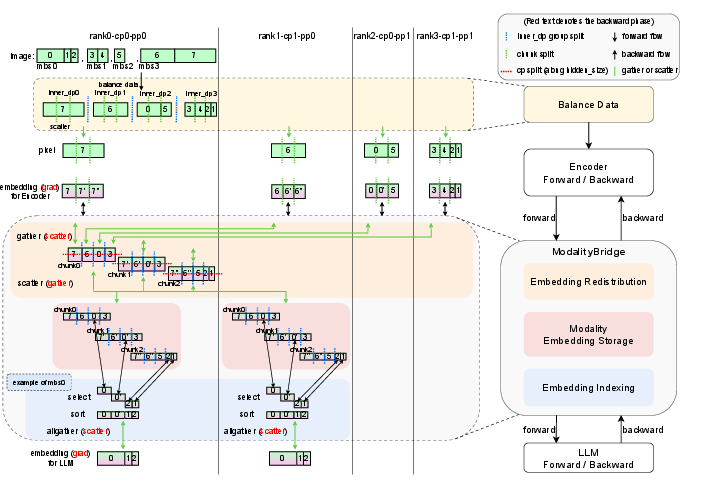
- Modality-Decoupled Parallelism: Training different parts (text brain, vision encoder, audio encoder) with the best settings for each is like running three assembly lines side-by-side, each optimized for its job. This kept their training speed above 90% of the speed of text-only training, which is unusually efficient for multimodal systems.
What did they find?
From their evaluations:
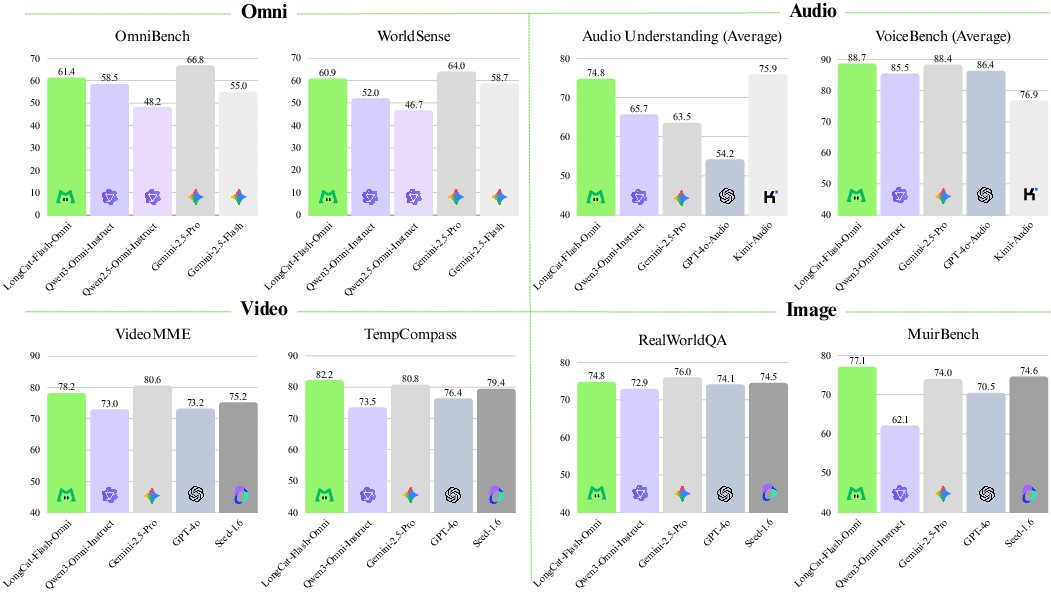
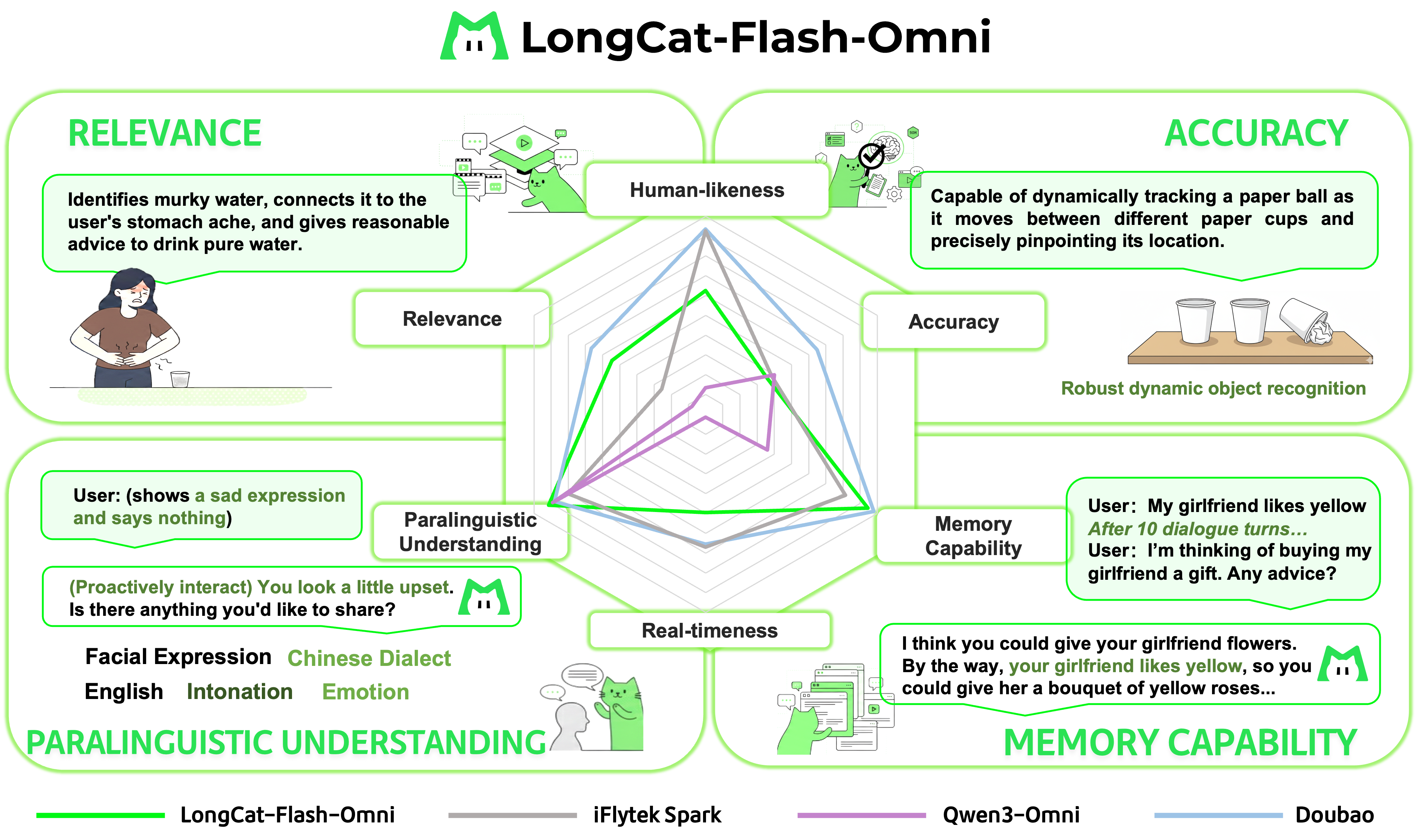
- Strong across the board: The model reaches state-of-the-art results on open omni-modal benchmarks (like Omni-Bench and WorldSense) among open-source models.
- Competitive on single-modality tasks: It performs very well on text-only, image-only, video-only, and audio-only tasks—so it didn’t sacrifice any one skill to gain others.
- Real-time interaction: It can handle live audio-visual conversations with low latency, speaking back fluently while watching and listening.
Why this matters: It shows that one unified model can understand and generate across text, images, audio, and video in real time, without slowing to a crawl or forgetting how to do basic tasks.
Why does this research matter?
- Better assistants: This kind of model could power tutors, customer support agents, and accessibility tools that can watch, listen, and talk naturally with people.
- Safer and smarter multimodal AI: The curriculum-style training and careful data curation give a path to teach AI complex, mixed media step by step, improving reliability.
- Practical at scale: Their training and serving tricks (Mixture-of-Experts, streaming design, modality-decoupled parallelism) show how to make giant multimodal models usable in the real world.
- Open-source impact: By releasing the model and sharing methods, they make it easier for researchers and developers to build on this work and create new applications.
In short, LongCat-Flash-Omni is a big step toward AI that can understand the world more like we do—by combining seeing, hearing, reading, and speaking—while staying fast enough to be genuinely helpful in real time.
Knowledge Gaps
Below is a single, focused list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper:
- Quantitative latency/QoS: no end-to-end numbers (E2E latency, jitter, tail-latency, throughput) under realistic multi-user loads.
- Hardware footprint: missing details on serving hardware, concurrency limits, and cost per real-time session.
- Energy and carbon costs: no training/inference energy usage, CO2 footprint, or efficiency-vs-quality tradeoff analysis.
- Reproducibility: incomplete hyperparameters, optimizer schedules, data mixtures per stage, and random seeds for end-to-end replication.
- Data transparency: unspecified dataset inventories, licensing/consents, language distributions, domain proportions, and contamination checks vs benchmarks.
- Safety and governance: no content moderation pipeline across modalities (image/video/audio), nor abuse-prevention policy for real-time voice.
- Privacy and PII: no strategy for PII detection/redaction in audio/video or safeguards against voice/face leakage.
- Regurgitation risk: no measurement of verbatim reproduction from training data in text, image captions, or speech.
- Voice cloning/deepfake mitigation: no watermarking, anti-spoofing, or provenance for generated speech.
- Security: absent evaluation against multimodal prompt injection, adversarial audio/image perturbations, and model backdoors.
- Multilingual coverage: unclear language support, code-switching performance, accent/ dialect robustness, and non-English TTS quality.
- Noisy conditions: no robustness results for background noise, reverberation, packet loss, low-light video, or low-bitrate streams.
- Overlapping speech: no handling of diarization, speaker separation, or cross-talk in streaming scenarios.
- Lip-sync and A/V alignment: no metrics for synchronization accuracy during low-latency interaction.
- TTS quality: missing human and objective evaluations (MOS, CMOS, intelligibility, prosody, latency-quality curves).
- Non-speech audio: model cannot generate ambient sounds/music; scope and future pathway to general audio generation unclear.
- Prosody/emotion control: no controllability mechanisms or evaluation for expressive/emotional speech generation.
- Personalization: no speaker adaptation, few-shot voice cloning, or privacy-preserving on-device personalization strategy.
- Long-context reliability: no tests of memory accuracy, retrieval stability, or hallucination rates at 128K multimodal tokens.
- KV cache scaling: absent policies for cache eviction, mixing audio/vision/text tokens, and resource usage over long sessions.
- Video sampling/compression tradeoffs: 2 FPS and hierarchical token compression unquantified in terms of action/motion fidelity.
- Timestamps-as-text: no ablation vs learned temporal embeddings; risk of spurious reliance on textual time markers.
- Chunked interleaving: unclear error accumulation, context fragmentation, and responsiveness under rapid turn-taking.
- Barge-in/endpointing: no method or metrics for barge-in handling, endpoint detection, or partial hypothesis correction.
- Audio token rate mismatch: alignment between 16.67 Hz codebooks and 80 ms encoder frames is not analyzed.
- Discrete vs continuous audio: no ablation on when discrete tokens vs continuous features help/hurt downstream tasks.
- Vision encoder scaling: native-resolution costs vs gains are not quantified; no comparison to token-merging/token-learner baselines.
- MoE routing across modalities: no analysis of expert specialization, capacity factors, load balance, or interference/forgetting.
- Cross-modal interference: no measurement of catastrophic forgetting when adding modalities or changing data ratios.
- Curriculum efficacy: limited ablations isolating each training stage’s contribution (Stage-0→5) and data mixture choices.
- Modality-Decoupled Parallelism: lacks scalability curves (nodes/links), bandwidth sensitivity, memory fragmentation, and failure modes.
- Streaming server design: missing pipeline design details, batching policies, and overlap of compute/IO for minimal latency.
- Evaluation breadth: few standardized baselines reported for ASR, audiovisual QA, VQA, OCR, GUI, and long-video reasoning.
- Human studies: no user studies of real-time interaction quality, turn-taking naturalness, or cognitive load.
- Fairness/bias: no audits for demographic biases in vision, speech, or cross-modal reasoning, or mitigation strategies.
- GUI planning: no closed-loop execution evaluation across device types, OS variations, and accessibility scenarios.
- Continual learning: no strategy for post-deployment updates, elastic modality growth, or avoiding drift/catastrophic forgetting.
- Failure analysis: absent taxonomy of common errors (visual hallucination, temporal misbinding, speech disfluency) and targeted fixes.
- Open-source completeness: unclear release of training code, MDP tooling, serving stack, and reproducible data preparation scripts.
Practical Applications
Immediate Applications
The following applications can be deployed now using the open-source LongCat-Flash-Omni model and its training/inference methods. Each item notes key sectors, potential tools/workflows, and feasibility dependencies.
- Real-time voice-and-vision customer support copilot
- Sectors: customer service, telecom, retail, finance
- What it does: Listens to live customer audio, watches agent desktop screens (GUI images/video), extracts on-screen information (OCR/table/chart), grounds instructions to UI elements, and responds in natural, low-latency speech. Maintains multi-turn memory across long calls (128K context).
- Tools/workflows: Desktop overlay capturing periodic screenshots; streaming AV interleaving API; on-screen OCR/grounding prompts; speech synthesis via multi-codebook decoder; compliance logging.
- Assumptions/dependencies: GPU-backed serving for low-latency 27B-activated inference; data privacy and consent; red-teaming/guardrails; domain prompts/fine-tuning for call policies.
- Meeting assistant with multimodal minutes and action items
- Sectors: enterprise productivity, education
- What it does: Captures meeting audio/video; generates transcripts, summaries, timelines via textual timestamps; identifies speakers, slides, diagrams, and actions; outputs spoken or written updates.
- Tools/workflows: Stream chunk-wise AV ingestion; slide image sampling at 2 FPS; long-context summarization; calendar/task integrations.
- Assumptions/dependencies: External diarization if needed; organizational privacy controls; compute provisioning for long meetings.
- Long-video analytics and indexing
- Sectors: media, sports, compliance, retail
- What it does: Summarizes and answers questions over long videos using hierarchical token compression, dynamic frame sampling, and temporal awareness (Second{i} timestamps). Supports content moderation and highlight detection.
- Tools/workflows: “Long-context media indexing” pipeline with frame sampling (sparse/dense modes), temporal QA prompts, vector store for retrieval.
- Assumptions/dependencies: GPU throughput for hours-long media; content rights; task-specific evaluation and thresholds for compliance.
- Screen-reading and document assistant (accessibility)
- Sectors: accessibility tech, enterprise operations, legal
- What it does: Reads multi-page PDFs, scans, tables, charts, and web pages aloud in real time; explains structure and content; supports Q&A over documents on-screen.
- Tools/workflows: OCR/document VQA prompts; region-level grounding; streaming TTS; keyboard navigation helpers.
- Assumptions/dependencies: On-device capture permissions; latency budgets for user experience; safety filters for sensitive content.
- GUI automation and RPA with vision grounding
- Sectors: enterprise software, operations, QA/testing
- What it does: Plans and executes multi-step workflows on desktop/mobile UIs using screenshot understanding and action sequencing (GUI data). Enables test automation, form filling, and cross-app orchestration.
- Tools/workflows: “GUI Agent Runner” calling OS automation (e.g., ADB, AppleScript, UIAutomation); screenshot-per-step + reasoning traces; retry/error-handling templates.
- Assumptions/dependencies: Sandboxed execution; reliability thresholds and human-in-the-loop; fine-tuning on target app patterns.
- STEM multimodal tutoring and assessment
- Sectors: education, training
- What it does: Explains diagrams, equations, lab images, and multi-image reasoning tasks; guides students verbally; grades visual work with textual rationales.
- Tools/workflows: Tutor app with image/video input; curriculum-aligned prompts; solution verification chains.
- Assumptions/dependencies: Content accuracy checks; pedagogy-aligned guardrails; optional domain fine-tuning.
- Compliance and QA for contact centers
- Sectors: finance, healthcare administration, insurance
- What it does: Monitors audio (and optional agent screen) for required disclosures, sensitive terms, and prohibited behaviors; produces timestamped evidence.
- Tools/workflows: Streaming ASR-style ingestion; policy prompt templates; dashboard for review and escalation.
- Assumptions/dependencies: Policy encoding and continuous evaluation; privacy/compliance approvals; latency/resource planning.
- Video-based product support and AR-style guidance
- Sectors: consumer electronics, industrial maintenance
- What it does: Users point a phone camera at a device; model recognizes components and provides step-by-step voice instructions; verifies each step visually.
- Tools/workflows: Mobile capture to server; sparse/dense frame sampling; interactive temporal prompts; speech guidance.
- Assumptions/dependencies: Uplink bandwidth; device- and domain-specific fine-tuning; safety disclaimers for physical tasks.
- Media captioning, dubbing, and descriptive audio
- Sectors: media localization, accessibility
- What it does: Generates dense video captions; converts them to natural speech with low-latency code-to-wave synthesis; supports descriptive audio for visually impaired users.
- Tools/workflows: Scene detection + caption generation; prosody control via multi-codebook tokens; batch or streaming modes.
- Assumptions/dependencies: Language coverage verification; licensing and content rights; style/fidelity tuning.
- Data labeling acceleration for vision/audio tasks
- Sectors: AI/ML tooling, data operations
- What it does: Produces dense image/video captions, temporally grounded QA pairs, and region captions; improves dataset richness and balance.
- Tools/workflows: Semi-automatic pipelines with human QA; cluster-based diversity sampling; labeling UIs with model suggestions.
- Assumptions/dependencies: Human verification to control hallucinations; bias and diversity audits; prompt templates for task schemas.
- Open-source training/inference adoption (MDP + ScMoE + streaming)
- Sectors: ML infrastructure (industry and academia)
- What it does: Replicates modality-decoupled parallelism (MDP) to train large multimodal models with ~90% text-only throughput; deploys streaming AV interleaving pipelines; adopts ScMoE with zero-computation experts for cost-effective serving.
- Tools/workflows: Reference configs for distributed training; activation-sparse serving stacks; audio code-to-wave servers.
- Assumptions/dependencies: Access to multi-node GPU clusters; engineering effort to port/compose with existing stacks; monitoring for stability.
- Multimodal search and retrieval over slide decks and PDFs
- Sectors: enterprise knowledge management
- What it does: Indexes slides, charts, scanned documents, and embedded images; supports natural-language and visual queries with pinpointed references and timestamps/page numbers.
- Tools/workflows: Vision-native-resolution encoding; multimodal embeddings; long-context retrieval-augmented generation (RAG).
- Assumptions/dependencies: Document ingestion pipelines; governance for sensitive data; latency/throughput SLOs.
Long-Term Applications
The following applications are feasible with further research, scaling, compression, domain adaptation, or safety/validation work.
- On-device multimodal assistant (distilled from 560B to small footprint)
- Sectors: mobile, wearables, automotive
- What it could do: Low-latency voice/vision assistant running partly on-device for privacy; offline screen reading; spoken conversations and tool use.
- Dependencies: Model compression/distillation; hardware acceleration; energy constraints; robust fallback to edge/cloud.
- Full-stack autonomous GUI and enterprise agents
- Sectors: enterprise IT, back-office automation
- What it could do: Reliable, end-to-end execution across complex apps with verification, rollback, and exception handling; learns from demonstrations at scale.
- Dependencies: Formal safety/verification layers; program synthesis or constrained action schemas; comprehensive red-teaming; strong evals.
- Clinical-grade telehealth triage and documentation
- Sectors: healthcare
- What it could do: Video/audio symptom capture, document parsing of forms, generation of visit summaries; clinician-in-the-loop decision support.
- Dependencies: Clinical validation and regulatory approval; medical-domain pretraining/fine-tuning; HIPAA/GDPR-compliant deployments; bias/safety studies.
- Socially aware robots and embodied agents
- Sectors: robotics, eldercare, hospitality
- What it could do: Real-time AV dialog grounded in the environment; long-horizon memory; emotion/prosody-adaptive speech.
- Dependencies: Robust perception-action loops; safety constraints; integration with navigation/manipulation stacks; continual learning.
- Cross-lingual speech-to-speech assistants with lip/temporal sync
- Sectors: live translation, media localization
- What it could do: Real-time speech translation and dubbing aligned with visual context and timing.
- Dependencies: High-quality multilingual speech/vision data; evaluation for latency and translation adequacy; cultural/brand style controls.
- Personalized cognitive prosthetics with lifelong memory
- Sectors: consumer productivity, accessibility
- What it could do: Continuous capture of daily audio-visual context with 128K+ memory; proactive reminders, retrieval, and narrative summaries.
- Dependencies: Privacy-by-design memory stores; user-controlled data governance; on-device processing; safety and consent frameworks.
- Multimodal misinformation and deepfake analysis
- Sectors: policy, platform integrity, journalism
- What it could do: Temporal and spatial cross-checks across audio and video to detect inconsistencies and manipulations; content provenance assistance.
- Dependencies: Dedicated training on forensics datasets; calibrated detectors; access to metadata/provenance signals; high-stakes evaluation.
- Industrial inspection and safety monitoring
- Sectors: manufacturing, energy, logistics
- What it could do: Analyze live video feeds for procedure adherence; voice-guided workflows; anomaly descriptions with timestamps.
- Dependencies: Domain-specific training; ruggedized edge deployments; integration with control systems; liability and safety certification.
- Advanced educational assessment and simulation
- Sectors: education, vocational training
- What it could do: Automated assessment of lab demonstrations and presentations via video; multimodal simulations with spoken feedback and rubric-based grading.
- Dependencies: Validity/reliability studies; alignment with accreditation standards; fairness audits; dataset coverage for diverse tasks.
- Scalable multimodal research platform
- Sectors: academia, public sector research
- What it could do: A reproducible base for studying multimodal alignment, long-context reasoning, and real-time interaction; community benchmarks and data pipelines.
- Dependencies: Sustained compute funding; standardized evaluation suites; curated open datasets with permissive licenses.
Notes on Assumptions and Dependencies Across Applications
- Compute and deployment: Achieving “millisecond-level” real-time interaction typically requires GPU inference with optimized streaming pipelines; scaling to many concurrent users needs careful scheduling and batching.
- Safety and governance: Multimodal systems raise new safety issues (e.g., misinterpretation of images, privacy of captured screens); robust guardrails, auditing, and human oversight are essential.
- Domain adaptation: High-stakes domains (healthcare, finance, industrial) require domain-specific fine-tuning and rigorous validation.
- Privacy and compliance: Live AV capture demands consent, secure transmission, storage minimization, and regulatory compliance.
- Evaluation: Temporal grounding and long-context performance should be measured with task-specific metrics and human-in-the-loop QA prior to production deployment.
Glossary
- 2D-RoPE (2D rotary position embeddings): A positional encoding method that extends rotary embeddings to two dimensions for vision transformers. Example: "2D rotary position embeddings (2D-RoPE)"
- 3D convolution: A convolution over spatial and temporal dimensions for video feature processing. Example: "a 3D convolution with temporal stride of 2"
- Action recognition: The task of identifying actions in videos. Example: "Action recognition video QA data"
- AGI (Artificial General Intelligence): A hypothetical form of AI with general, human-level intelligence across tasks. Example: "AGI"
- Annealed learning rate: A training schedule where the learning rate is gradually reduced. Example: "under an annealed learning rate"
- ASR (Automatic Speech Recognition): Technology that transcribes spoken language into text. Example: "ASR-style tasks to build basic speech perception capability."
- Audio detokenization: The process of converting discrete audio tokens back into waveforms. Example: "multi-codebook audio detokenization scheme"
- Audio tokenizer: A model that converts audio waveforms into discrete token sequences. Example: "an audio tokenizer is employed to convert raw speech into four-codebook discrete tokens"
- Causal transposed convolution: A transposed convolution constrained to use only past context, enabling streaming generation. Example: "causal transposed convolution layers"
- Codebook (in audio tokenization): A discrete set of symbols used to quantize and represent audio features. Example: "four-codebook discrete tokens"
- Contrastive Vision-Language Pretraining: Training that aligns image and text representations by contrasting matched vs. mismatched pairs. Example: "Contrastive Vision-Language Pretraining"
- Context window: The maximum number of tokens a model can attend to in a single sequence. Example: "context window of up to 128K tokens"
- CTC loss (Connectionist Temporal Classification): A loss function for sequence labeling without frame-level alignment. Example: "CTC loss"
- Curriculum learning: A strategy that trains models on simpler tasks before harder ones. Example: "leverages curriculum learning"
- Dynamic Video Frame Sampling: Adapting the frame sampling rate based on video duration to balance efficiency and information. Example: "Dynamic Video Frame Sampling"
- Early-Fusion Training: A paradigm where multimodal inputs are fused early in the model. Example: "Effective Early-Fusion Training"
- Fbank features: Log Mel filter bank features commonly used as acoustic inputs. Example: "takes 80-dimensional Fbank features as input."
- Feature distillation: Using a teacher model’s features as auxiliary targets to guide training. Example: "feature distillation from a frozen pretrained vision model"
- Forced alignment: Aligning audio with transcriptions at the time-stamp level. Example: "for forced alignment"
- FSMN (Feedforward Sequential Memory Network): A neural architecture that models long-term dependencies with memory blocks. Example: "FSMN layers"
- GAN (Generative Adversarial Network): A framework with a generator and discriminator trained in opposition. Example: "generative adversarial network (GAN) framework."
- Grounding: Linking language to specific regions or objects in images/videos. Example: "Grounding Data"
- GUI (Graphical User Interface): Visual interfaces with elements like buttons and menus for human-computer interaction. Example: "Graphical User Interface (GUI) data"
- Hierarchical Token Compress in Video Inputs: A multi-step approach to reduce video token count for efficiency. Example: "Hierarchical Token Compress in Video Inputs"
- LayerScale: A technique that scales residual branch outputs with learnable parameters for stability. Example: "a LayerScale module"
- LLM backbone: The core LLM that processes and generates tokens. Example: "LLM backbone"
- LongCat-Audio-Codec: The project’s audio codec for tokenizing and decoding speech with low-latency streaming. Example: "LongCat-Audio-Codec"
- LongCat-ViT: The project’s Vision Transformer used as the vision encoder. Example: "LongCat-ViT achieves high performance across multimodal tasks,"
- Look-ahead: Allowing limited future context to reduce latency while preserving streaming behavior. Example: "look-ahead of only three frames."
- MLA (Multi-head Latent Attention): An attention mechanism variant for efficient LLMs. Example: "Multi-head Latent Attention (MLA)"
- Mixture-of-Experts (MoE): An architecture that routes tokens to specialized expert subnetworks. Example: "Mixture-of-Experts (MoE) LLM."
- Modality-decoupled parallelism (MDP): A distributed training strategy that separates modality components for efficiency. Example: "modality-decoupled parallelism (MDP) strategy."
- Multilingual speech aligner: A tool for aligning speech to text across languages. Example: "multilingual speech aligner"
- Native Resolution Encoding: Processing images/videos at their original resolution to preserve details. Example: "Native Resolution Encoding"
- Next-token prediction (NTP): The standard autoregressive objective of predicting the next token. Example: "next-token prediction (NTP)"
- OCR (Optical Character Recognition): Extracting text from images or documents. Example: "OCR Data"
- Paralinguistic: Non-lexical aspects of speech like emotion, prosody, and timbre. Example: "paralinguistic analysis"
- Pixel-unshuffle: An operation that rearranges pixels to reduce spatial resolution and computational cost. Example: "2 pixel-unshuffle operation"
- Pre-Norm: A Transformer variant where normalization precedes attention/FFN blocks. Example: "a Pre-Norm configuration"
- Pseudo-label: Labels generated by a model to augment or supervise training data. Example: "pseudo-label generation"
- Query-Key normalization: Normalizing attention query/key vectors to stabilize training. Example: "Query-Key normalization."
- RMSNorm: Root Mean Square Layer Normalization, a normalization technique alternative to LayerNorm. Example: "RMSNorm layer"
- ScMoE (Shortcut-connected MoE): An MoE architecture with shortcut connections for efficiency. Example: "Shortcut-connected MoE (ScMoE)"
- Semantic clustering: Grouping data by semantic similarity for balanced sampling. Example: "semantic clustering"
- SigLIP: A vision-LLM with sigmoid loss used for image-text similarity. Example: "SigLIP similarity"
- Sparse-Dense Sampling Strategy: A strategy that varies sampling density across interaction phases to balance cost and information. Example: "Sparse-Dense Sampling Strategy"
- Streaming audio decoding: Real-time conversion of audio tokens to waveform with minimal latency. Example: "streaming audio decoding"
- Streaming Audio-Visual Feature Interleaving: Interleaving synchronized audio-video feature chunks for low-latency processing. Example: "Streaming Audio-Visual Feature Interleaving"
- Temporal sentence grounding: Localizing segments in video that correspond to a textual description. Example: "temporal sentence grounding"
- Temporal stride: The step size over time used in temporal convolutions or sampling. Example: "temporal stride of 2"
- Textual Timestamps: Inserting textual time markers to improve temporal awareness. Example: "Textual Timestamps"
- VAD (Voice Activity Detection): Detecting speech segments and removing silence/noise. Example: "VAD system"
- Vision Transformer (ViT): A transformer architecture applied to images/videos via patch embeddings. Example: "Vision Transformer (ViT)"
- Vision-language projector: A module aligning visual features to the LLM’s token space. Example: "vision-language projector"
- Vocoder: A model that converts acoustic features (e.g., mel-spectrograms) into waveforms. Example: "vocoders"
- Zero-computation experts: MoE experts that perform no computation to reduce overhead while preserving routing structure. Example: "zero-computation experts"
Collections
Sign up for free to add this paper to one or more collections.

