Keyframe-Based Feed-Forward Visual Odometry
Abstract: The emergence of visual foundation models has revolutionized visual odometry~(VO) and SLAM, enabling pose estimation and dense reconstruction within a single feed-forward network. However, unlike traditional pipelines that leverage keyframe methods to enhance efficiency and accuracy, current foundation model based methods, such as VGGT-Long, typically process raw image sequences indiscriminately. This leads to computational redundancy and degraded performance caused by low inter-frame parallax, which provides limited contextual stereo information. Integrating traditional geometric heuristics into these methods is non-trivial, as their performance depends on high-dimensional latent representations rather than explicit geometric metrics. To bridge this gap, we propose a novel keyframe-based feed-forward VO. Instead of relying on hand-crafted rules, our approach employs reinforcement learning to derive an adaptive keyframe policy in a data-driven manner, aligning selection with the intrinsic characteristics of the underlying foundation model. We train our agent on TartanAir dataset and conduct extensive evaluations across several real-world datasets. Experimental results demonstrate that the proposed method achieves consistent and substantial improvements over state-of-the-art feed-forward VO methods.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about teaching computers (like robots or drones) to figure out where they are and how they’re moving just by looking at camera images. That skill is called visual odometry (VO). The authors build on a powerful “foundation model” called VGGT that can estimate camera motion and 3D shape directly from images. Their key idea: don’t feed every single image to the model. Instead, smartly pick only the most useful images (called keyframes). They use reinforcement learning (a kind of trial-and-error training with rewards) to learn how to pick these keyframes automatically so the system becomes both more accurate and more efficient.
The main questions the paper asks
- Can we make feed-forward VO models (like VGGT) more accurate and faster by choosing only the most helpful frames instead of using every frame?
- Since foundation models work with complex internal features (not simple geometry rules), can a learned policy decide which frames matter most?
- Will a learned keyframe picker trained on simulated data still work well on real-world videos?
How their method works, in simple terms
Imagine you’re on a journey and you’re taking photos every step. Many photos look almost the same, so they don’t help much in figuring out how you moved. Traditional VO/SLAM systems solve this by keeping only “important snapshots” (keyframes). But newer “foundation models” usually just take a chunk of all photos without filtering, which can waste time and even hurt accuracy. The authors combine the best of both worlds: the power of a foundation model plus smart keyframe picking.
Here’s the flow:
- Sliding window (a small backpack of recent photos)
- The system looks at a small set of recent images at a time (a “window,” size 8 in the paper).
- The first image in the window is the anchor frame, like a starting reference.
- The model (VGGT) estimates each image’s pose (where the camera is and where it’s looking) relative to the anchor frame.
- Using the anchor’s known global position, the system turns these relative poses into global positions.
- What is a keyframe?
- A keyframe is an image that’s “worth keeping” because it adds useful new information (like a new angle or a big move).
- The system tries to keep a good set of keyframes that cover the motion well without being repetitive.
- How the system decides keyframes (reinforcement learning)
- The “agent” (a small neural network) looks at:
- A compact summary of what each image shows (the “CLS token,” which you can think of as a short description learned by the vision model).
- The relative motion between frames (how much the camera moved and turned).
- Based on this info, the agent decides: should the newest image be kept as a keyframe or tossed?
- After making a decision, the system checks how accurate the estimated camera path is (compared to ground truth during training). That accuracy becomes the reward:
- Better path = higher reward.
- The agent learns to make choices that improve accuracy and avoid keeping redundant frames.
- There’s also a tiny penalty/reward for adding/removing keyframes so the agent doesn’t “cheat” by always keeping or always discarding.
- The “agent” (a small neural network) looks at:
- Training and tools
- They train the keyframe agent with PPO (a popular reinforcement learning algorithm).
- Training is done on TartanAir, a big simulated dataset with different scenes and lighting/weather conditions.
- They add random changes (like brightness shifts or dropped frames) during training to make the agent more robust.
- Why this fits foundation models
- Traditional keyframe rules rely on geometry formulas (like measuring distances and angles).
- Foundation models like VGGT work with high-level features inside a transformer (think: rich, abstract “understanding” of images).
- The agent uses those same kinds of features (like CLS tokens), so the decisions “match” what the foundation model finds useful.
What they found and why it matters
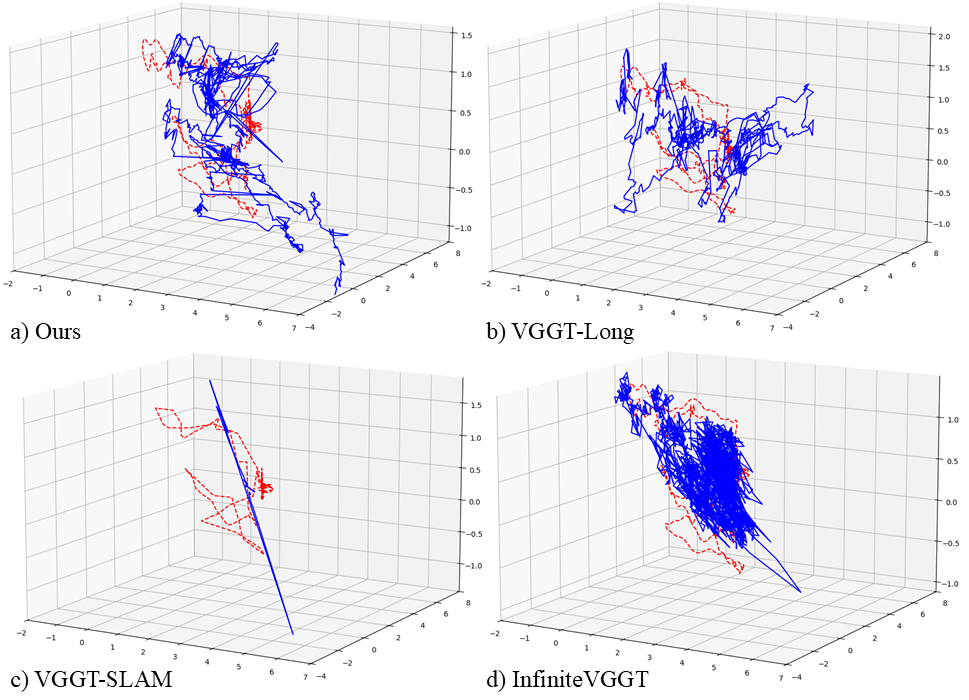
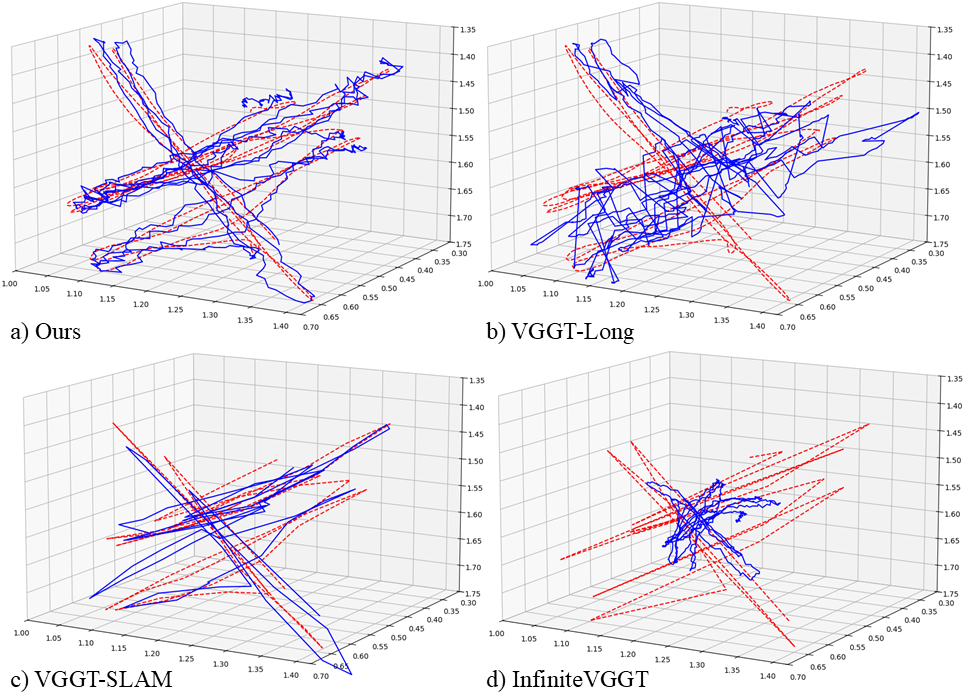
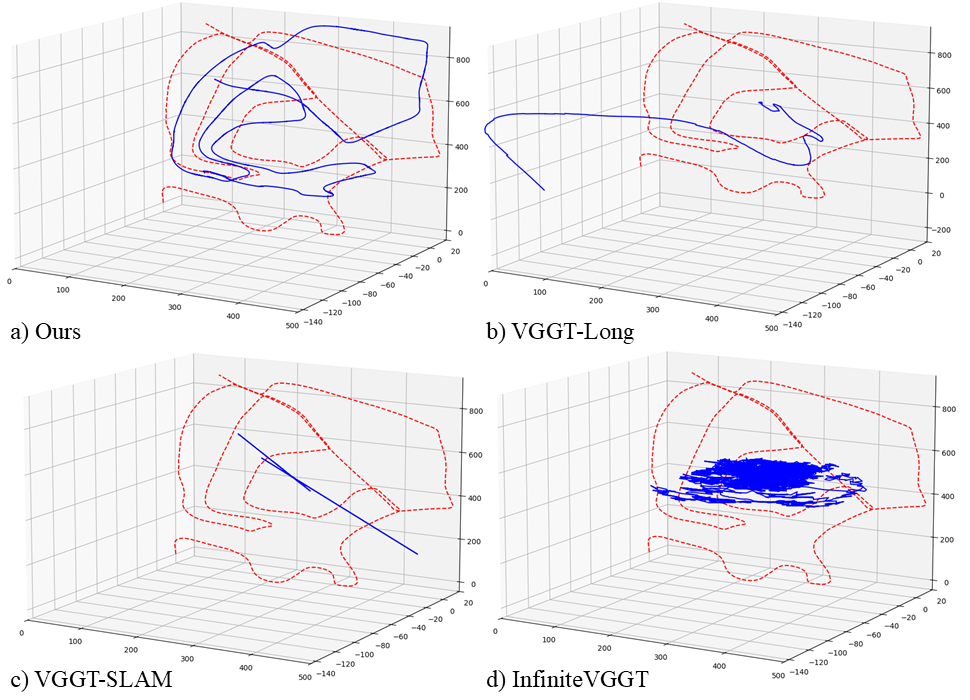
The authors tested their method on several real-world datasets without retraining:
- EuRoC (indoor drone flights),
- TUM-RGBD (handheld indoor scenes),
- KITTI (outdoor driving).
Key takeaways:
- Their learned keyframe method consistently improved accuracy over strong feed-forward baselines that don’t filter frames.
- It often matched or beat systems that rely on extra post-processing steps, even though their method doesn’t use those extras.
- It worked well across different environments (tight indoor spaces and large outdoor roads).
- The decision-making overhead is tiny (well under 1 millisecond per frame), so it doesn’t slow the system down.
- Training only on simulated data still gave good results in the real world, showing strong generalization.
In short: choosing the right frames helps a lot, even for powerful foundation models. And learning how to choose them beats simple hand-made rules.
Why this is important
- Smarter, faster robots and drones: By skipping boring or redundant frames, a robot uses less computing power and gets a cleaner, more accurate path.
- Better use of big vision models: Foundation models are powerful but heavy. A good keyframe policy makes them more practical for long videos and real-time tasks.
- Fewer hand-crafted rules: Instead of manually tuning dozens of thresholds and tricks, the system learns a policy that fits the model’s internal “language.”
- A step toward full feed-forward SLAM: Today this is odometry (estimating motion). The same ideas could help add long-term memory (loop closing) in the future, moving toward fully feed-forward SLAM systems.
In one sentence
The paper shows that teaching a small “coach” to pick the most informative frames makes a big, smart vision model much better at figuring out how a camera moves—more accurate, more efficient, and more ready for the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following items identify what remains missing, uncertain, or unexplored in the paper and can guide future research:
- Reward design only penalizes translational error; the omission of rotational error and scale drift in the reward may bias keyframe decisions. Evaluate alternative reward formulations that jointly consider , , and scale (e.g., SE(3)/Sim(3) components and relative pose errors).
- The Umeyama-based alignment uses “the first few poses in the window,” but the number of poses and sensitivity to this choice are unspecified. Quantify the impact of alignment window size on training stability and policy quality.
- Hyperparameters in the reward (e.g., $\lambda_{\mathrm{threshold}$, clipping at −1, $\alpha_{\mathrm{keyframe}$, , ) are heuristically set without sensitivity analysis. Provide robustness studies and guidelines for tuning across datasets and motion regimes.
- The observation compresses per-frame features to the mean of DINOv2 CLS tokens, losing temporal order and potential geometric cues (e.g., inter-frame parallax). Compare against richer observations (e.g., concatenated CLS tokens with positional encodings, cross-view attention features, learned parallax proxies).
- The action space is limited to a binary “keep/discard latest frame” decision, which prevents explicit replacement or eviction of specific keyframes. Explore expanded action spaces (e.g., select which frame in the window to evict, adjust window size, or re-weight frames).
- No analysis of the learned keyframe distribution (e.g., % frames kept, average spacing, parallax statistics). Report selection rates, spatial/temporal distributions, and correlations with tracking error and scene characteristics.
- Initialization treats the first 7 frames as keyframes; the impact of this heuristic on early drift and downstream performance is unexamined. Evaluate alternatives (e.g., parallax-based warm start, curriculum scheduling).
- Sliding-window anchor-shift strategy is adopted without comparison to chunk-overlap Sim(3) alignment. Empirically compare anchor-based vs. overlap-based alignment for different motion patterns and scene scales.
- The method is evaluated only on monocular RGB; potential gains from stereo or multi-camera inputs are unexplored. Assess whether multi-view setups change the optimal keyframe policy.
- Generalization relies on training exclusively on synthetic TartanAir and evaluation on EuRoC, TUM-RGBD, and KITTI, but failure modes and domain gaps are not analyzed. Identify conditions (e.g., texture-poor, repetitive structure, lighting extremes) where the policy degrades and study domain adaptation strategies.
- Dynamic-scene robustness is not explicitly tested (e.g., TUM fr3 dynamic sequences, pedestrians/vehicles in KITTI). Evaluate performance under varying levels of scene dynamics and consider observation features that explicitly discount moving objects.
- Real-time feasibility is unclear: average per-step time ≈380 ms on an RTX 4090 (≈2.6 Hz). Report throughput vs. image resolution and window size, memory footprint, and performance on resource-constrained hardware (e.g., Jetson, embedded GPUs).
- Memory usage and computational savings from keyframe selection are not quantified. Measure reductions in VGGT calls, tokens processed, peak VRAM, and end-to-end energy consumption relative to “keep-all” baselines.
- Only ATE RMSE is reported; complementary metrics (RPE, orientation error, scale error, drift rate) are missing. Add comprehensive metrics to isolate where gains occur (local accuracy vs. global consistency).
- The privileged critic leverages ground-truth of current and future states, which may limit reproducibility and applicability. Quantify training improvements due to privilege and investigate non-privileged critics or offline imitation/preference learning.
- Training depends on ground-truth poses for rewards; learning without GT (self-supervision, proxy signals, consistency losses) is not addressed. Explore GT-free or weakly supervised policy learning for real-world deployment.
- Policy adaptation at inference time is not considered. Investigate online/continual RL or meta-learning to adapt the keyframe policy to new environments and sensors.
- The agent architecture is a small MLP; no comparison to attention-based or recurrent policies that might capture temporal dependencies and inter-frame relationships more effectively. Benchmark alternative architectures.
- The use of DINOv2 CLS tokens as the sole semantic descriptor may overlook geometry-rich tokens or multi-layer features more predictive of VO performance. Study feature selection from the backbone (e.g., mid-level tokens, multi-scale encodings).
- Parallax handling is a core motivation, yet parallax is not measured or used explicitly in the observation or reward. Define and incorporate a parallax proxy to guide selection and report its effects.
- The paper claims strong generalization but also shows sequences where the method is not best (e.g., KITTI 04). Provide systematic error analysis and categorize failure cases to inform policy improvements.
- Interaction with loop closure and global optimization is left for future work. Design experiments that integrate the RL keyframe policy with lightweight loop closure to assess synergy or conflicts.
- The method is only validated on VGGT; transferability to other 3D vision foundation models (e.g., MASt3R, Fast3R, CUT3R, FlashVGGT) is untested. Evaluate cross-backbone transfer and whether the observation/policy needs re-training.
- Robustness to sensor artifacts (rolling shutter, lens distortion, motion blur) and calibration errors is not explicitly studied. Include perturbation tests and domain augmentation targeting these factors.
- No uncertainty estimation is produced or used; uncertainty-aware selection (e.g., using pose/depth confidence) could improve decisions. Integrate uncertainty metrics from the backbone into observations and rewards.
- The decision cadence and window size are fixed (8); the impact of window size on accuracy, latency, and policy behavior is not explored. Perform a systematic sweep and consider adaptive window sizing.
- The policy may be sensitive to normalization of relative poses (running mean/std), especially under domain shift. Analyze normalization stability and alternatives (e.g., robust scaling).
- The rollout data excludes “uninitialized and error states,” possibly biasing learning away from recovery behaviors. Include and study recovery episodes to improve robustness after tracking loss.
- Baseline coverage omits classic VO/SLAM (DSO, ORB-SLAM3, DPVO) under matched settings. Add cross-paradigm comparisons to contextualize gains and limitations of feed-forward keyframe selection.
- The runtime table shows “Aggregator” dominates computation but is not decomposed. Provide a detailed breakdown (token extraction, attention layers, heads) to target optimization efforts.
Glossary
- Absolute Trajectory Error (ATE): A metric that measures the difference between estimated and ground-truth trajectories, often summarized by RMSE. "we have selected the Root Mean Square Error (RMSE) of Absolute Trajectory Error (ATE) as the metric for assessing performance."
- anchor frame: A designated reference frame within a window whose global pose is known and used to express other frames’ poses. "The first frame in the current window serves as the anchor frame, whose pose is already known in the global coordinate system."
- chunking: Partitioning long image sequences into smaller overlapping subsets (chunks) for separate processing and later alignment. "introduced chunking and loop closure to achieve globally aligned long-term pose estimation."
- CLS token: The special classification token in transformer-based vision models that aggregates global information from an image. "The observation consists of the mean of CLS tokens extracted by the ViT encoder from all frames within the keyframe window"
- conditional Mutual Information: The mutual information between variables conditioned on a third variable, used here to quantify frame information content. "Schmuck et al.~\cite{schmuck2019redundancy} quantify keyframe information using Mutual Information, assessing content via conditional Mutual Information."
- cross-attention: An attention mechanism that relates features across different inputs (e.g., across frames) to capture cross-view relationships. "alternates between frame-wise self-attention and global cross-attention layers."
- DINOv2: A self-supervised vision foundation model used to extract per-image feature tokens. "It first extracts per-image visual feature tokens using DINOv2~\cite{oquab2023dinov2}."
- direct visual odometry: A VO approach that estimates motion directly from image intensities rather than discrete features. "Direct methods, exemplified by DSO~\cite{engel2017direct}, use pixel intensity to identify key image regions and analyze their motion across frames to estimate camera pose."
- entropy ratio: A probabilistic criterion comparing the uncertainty (entropy) between frames to decide keyframes. "Pumarola et al.~\cite{pumarola2017pl} select keyframe by comparing the entropy ratio between frames to a predefined threshold."
- feed-forward visual odometry (VO): A VO pipeline that estimates poses in a single pass without iterative optimization or feedback loops. "We propose a keyframe-based feed-forward VO"
- foundation model (visual foundation model): A large, general-purpose model trained on broad data (often transformer-based) that supports multiple downstream vision tasks. "The recent emergence of feed-forward visual foundation models has made it possible to establish a unified VO pipeline that requires no calibration and tuning with great generalization capabilities."
- loop closure: The process of detecting previously seen places to correct accumulated drift and globally align trajectories. "incorporated sliding-window mechanisms with loop closure, enabling VGGT to efficiently process long image sequences."
- Lucas–Kanade (LK) optical flow: A classic method for estimating optical flow by minimizing photometric error over small patches. "VGGT-LK also uses an identical sliding window, while incorporating LucasâKanade (LK) optical flow with a fixed threshold of 50 to determine keyframes."
- Markov Decision Process (MDP): A formal framework for sequential decision-making defined by states, actions, transition probabilities, rewards, and a discount factor. "we formulate the task as a Markov Decision Process (MDP), denoted as ."
- Mutual Information: An information-theoretic measure of shared information between variables, used to quantify the informativeness of frames. "Schmuck et al.~\cite{schmuck2019redundancy} quantify keyframe information using Mutual Information, assessing content via conditional Mutual Information."
- parallax: Apparent displacement between views that provides geometric cues for depth; low inter-frame parallax weakens depth/pose estimation. "degraded performance caused by low inter-frame parallax, which provides limited contextual stereo information."
- point clouds: Collections of 3D points representing scene geometry, typically reconstructed from multi-view images. "including camera poses, depth maps, and point clouds."
- privileged critic: An RL critic network that is given additional (e.g., ground-truth or future) information to stabilize training. "we adopt a privileged critic from ~\cite{messikommer2024reinforcement} to improve training stability."
- Proximal Policy Optimization (PPO): A policy-gradient RL algorithm that stabilizes updates by clipping policy changes. "We utilize the PPO~\cite{schulman2017proximal} algorithm implemented in Stable Baselines3~\cite{raffin2021stable} to train our agent."
- proportional–derivative (PD) controller: A control mechanism combining proportional and derivative terms to regulate a variable (here, keyframe thresholds). "Chen et al.~\cite{chen2021dynamic} introduced a proportionalâderivative(PD) controller to adaptively adjust the threshold for keyframe selection."
- reinforcement learning (RL): A learning paradigm where an agent learns to take actions by maximizing cumulative rewards through interaction with an environment. "our approach employs reinforcement learning to derive an adaptive keyframe policy in a data-driven manner"
- self-attention: An attention mechanism that relates different positions within the same input to capture contextual dependencies. "alternates between frame-wise self-attention and global cross-attention layers."
- Sim(3) transformations: Similarity transformations in 3D that include rotation, translation, and uniform scaling, used to align sub-trajectories. "align adjacent chunks via Sim(3) transformations, yielding a globally aligned trajectory."
- Simultaneous Localization and Mapping (SLAM): The problem of estimating both the pose of a sensor and a map of the environment simultaneously. "Visual Odometry (VO) and Simultaneous Localization and Mapping (SLAM) constitute the backbone for robotics"
- sliding window: A fixed-size subset of recent frames processed together to estimate and refine poses incrementally. "We maintain a fixed-size sliding window of the input frames."
- Structure-from-Motion (SfM): The process of reconstructing 3D structure and camera motion from multiple images. "Extensive research in both VO/SLAM~\cite{younes2017keyframe} and Structure-from-Motion (SfM)~\cite{conti2024range} has demonstrated that a well-designed keyframe method can effectively improve performance while reducing computational burden."
- translational error: The positional component of pose error measuring the difference in translation between estimated and ground-truth poses. "The translational error between the estimated and ground truth poses is then calculated and represented as ."
- Umeyama algorithm: A method for estimating the similarity transformation (including scale) that best aligns two point sets in a least-squares sense. "We use the Umeyama algorithm to estimate the transformation that aligns the estimated trajectory with the ground truth"
- value function: In RL, the expected cumulative discounted reward from a given state under a policy. "Following the control policy , the expected sum of discounted rewards at each time step can be expressed by its value function:"
- ViT (Vision Transformer): A transformer-based architecture for image processing that operates on tokenized patches (including a CLS token). "CLS tokens extracted by the ViT encoder"
- Visual Odometry (VO): Estimating the motion (pose) of a camera over time from visual input. "Visual Odometry (VO) and Simultaneous Localization and Mapping (SLAM) constitute the backbone for robotics"
Practical Applications
Below are practical, real-world applications derived from the paper’s feed-forward visual odometry with RL-based keyframe selection. Each item specifies sector(s), the application category, potential tools/products/workflows, and assumptions/dependencies that affect feasibility.
Immediate Applications
These can be deployed now with current models and hardware.
- Robotics and industrial automation: drop-in keyframe policy module for foundation-model VO
- Use case: Replace heuristic frame filtering in warehouse AMRs, inspection robots, and UAVs with the RL keyframe policy to cut redundant computation and improve trajectory accuracy in GPS-denied settings.
- Tools/products/workflows: ROS node or Jetson-ready “KeyframeRL” plugin for VGGT-based VO; sliding-window anchor alignment workflow as described in the paper; simple config to tune window size and action penalties.
- Assumptions/dependencies: Access to VGGT (or similar) weights; GPU or strong edge compute; camera frame rates consistent with windowing; drift managed without loop closure in long routes.
- AR/VR and mobile software: more stable head/phone tracking via adaptive keyframe selection
- Use case: Improve tracking stability in low-parallax scenes (e.g., slow head motions, indoor scans) by filtering visually redundant frames before feed-forward VO.
- Tools/products/workflows: Mobile SDK integrating DINOv2 CLS token extraction and RL policy; on-device sliding window; lightweight actor-critic decision step.
- Assumptions/dependencies: Sufficient mobile AI acceleration (e.g., GPU/NN cores); integration with existing camera pipelines; latency budgets permit sub-millisecond decisions.
- Mapping/Survey (A/E/C): faster, cheaper SfM and VO pre-processing
- Use case: Pre-select informative keyframes from long video scans to accelerate cloud SfM/VO pipelines, reducing compute bills while preserving map quality.
- Tools/products/workflows: CLI “Dataset Keyframe Sampler” that reads sequences, emits curated frame lists; batch alignment using Umeyama for QA.
- Assumptions/dependencies: Domain shift from TartanAir training may require minor fine-tuning; consistent timestamping and metadata; monocular-only constraints for some workflows.
- Drone operations and public safety: improved short-term localization in inspection flights
- Use case: Utility line, bridge, and roof inspections gain robustness when motion is slow or repetitive; reduced memory/cost by ignoring redundant frames.
- Tools/products/workflows: UAV firmware plugin with policy inference; live sliding window anchored to last reliable pose; telemetry validation via ATE monitoring.
- Assumptions/dependencies: Reliable camera synchronization; edge compute power; absence of loop closure increases drift over very long flights.
- Academic research: benchmarking and analysis of foundation-model VO
- Use case: Evaluate how learning-based keyframe selection interacts with high-dimensional latent spaces in VGGT; extend to other 3D foundation models.
- Tools/products/workflows: Reproduce PPO-based training on TartanAir; privileged critic setup for stability; open benchmarks on EuRoC, TUM-RGBD, KITTI.
- Assumptions/dependencies: Availability of datasets/ground truth; compute for multi-env rollouts; reproducible training settings.
- Software engineering/MLOps: cost-aware inference routing for VO services
- Use case: Production services dynamically throttle frames to meet latency/throughput SLAs while keeping trajectory error within bounds.
- Tools/products/workflows: Policy-driven frame gate before VGGT; metrics-based reward shaping aligned to service SLOs; observability dashboards for ATE and latency.
- Assumptions/dependencies: Monitoring stack; policy retraining for new domains; consistent performance of latent features across cameras.
- Consumer robotics: improved navigation for home robots (vacuum, lawn)
- Use case: Reduce failure modes in texture-poor areas and repetitive motion by prioritizing useful frames for VO.
- Tools/products/workflows: Lightweight inference module on ARM+GPU SoCs; periodic anchor reset; small window sizes (e.g., 8 frames) validated in the paper.
- Assumptions/dependencies: Camera quality in low light; compute budget; monocular assumptions (no IMU fusion in this paper).
- Education and training: lab modules on RL for vision foundations
- Use case: Teach students how RL can align decisions with the latent representations of “black-box” foundation models.
- Tools/products/workflows: Course materials using PPO + Stable Baselines3; assignments comparing heuristic vs RL selection; ablation exercises (CLS tokens, pose inputs).
- Assumptions/dependencies: GPU access in labs; simplified datasets; reproducible seeds.
Long-Term Applications
These require further research, scaling, or development (e.g., loop closure, broader generalization, certification).
- Fully feed-forward SLAM with learned keyframes and loop closure
- Use case: End-to-end SLAM without geometric post-processing, combining short-term RL keyframe memory with learned loop closure for global consistency.
- Tools/products/workflows: Extended policy for long-term memory; learned place recognition; multi-window alignment beyond Sim(3).
- Assumptions/dependencies: Robust loop closure learning; drift mitigation; cross-scene generalization; memory and latency scaling.
- Autonomous driving: foundation-model VO as part of multi-sensor fusion
- Use case: Use adaptive keyframe selection to stabilize monocular VO input to fusion stacks (camera+IMU+LiDAR), especially in low-parallax highway conditions.
- Tools/products/workflows: VO lane within perception stack; policy fine-tuned on automotive datasets; safety monitoring with redundancy checks.
- Assumptions/dependencies: Regulatory approvals; domain-specific tuning; rigorous validation for edge cases (weather, night).
- Healthcare robotics and navigation (endoscopy, hospital logistics)
- Use case: Stabilize visual navigation in constrained, repetitive spaces; reduce compute and energy while maintaining localization accuracy.
- Tools/products/workflows: Medical-grade VO modules with learned keyframe policy; validated on clinical datasets; energy-aware frame gating.
- Assumptions/dependencies: Clinical validation/standards; sterilizable hardware constraints; privacy and data governance.
- Energy and infrastructure digital twins at scale
- Use case: Large-area mapping for wind/solar farms and pipelines using drones; adaptive frame selection reduces flight time and cloud compute costs.
- Tools/products/workflows: Fleet-level data collection with federated keyframe policies; cloud SLAM pipelines with learned prefilters.
- Assumptions/dependencies: Cross-site generalization; robust performance under harsh conditions; secure data transfer.
- Multi-robot collaborative mapping with shared policies
- Use case: Robots share/transfer learned keyframe policies to coordinate efficient scene coverage and reduce redundant observations.
- Tools/products/workflows: Policy distillation and transfer; shared anchors; distributed alignment services.
- Assumptions/dependencies: Communication reliability; policy synchronization; conflict resolution in heterogeneous fleets.
- Privacy-preserving, on-device mapping and VO
- Use case: Keep sensitive environments off the cloud by performing efficient VO on-device with selective frames, minimizing data exposure.
- Tools/products/workflows: Encrypted on-device policies; local alignment; optional federated learning for policy updates.
- Assumptions/dependencies: Strong edge hardware; secure model update mechanisms; regulatory compliance.
- Video compression and streaming informed by VO keyframes
- Use case: Use the RL keyframe policy to guide I-frame placement in vision-centric streams where downstream tasks rely on geometry consistency.
- Tools/products/workflows: Encoder plugins that read CLS tokens and motion cues; task-aware compression profiles.
- Assumptions/dependencies: Integration with video codec stacks; balancing compression vs task accuracy; dataset-specific tuning.
- Standardization, benchmarking, and certification for foundation-model VO
- Use case: Develop guidelines and tests that reflect latent-space-aware decision policies (beyond geometric heuristics) for safety-critical deployments.
- Tools/products/workflows: Open benchmarks including policy evaluation; certification suites measuring ATE under domain shifts; policy interpretability tooling.
- Assumptions/dependencies: Community adoption; traceability for RL decisions; reproducible training/inference regimes.
Collections
Sign up for free to add this paper to one or more collections.