Visual Odometry with Transformers
Abstract: Modern monocular visual odometry methods typically combine pre-trained deep learning components with optimization modules, resulting in complex pipelines that rely heavily on camera calibration and hyperparameter tuning, and often struggle in unseen real-world scenarios. Recent large-scale 3D models trained on massive amounts of multi-modal data have partially alleviated these challenges, providing generalizable dense reconstruction and camera pose estimation. Still, they remain limited in handling long videos and providing accurate per-frame estimates, which are required for visual odometry. In this work, we demonstrate that monocular visual odometry can be addressed effectively in an end-to-end manner, thereby eliminating the need for handcrafted components such as bundle adjustment, feature matching, camera calibration, or dense 3D reconstruction. We introduce VoT, short for Visual odometry Transformer, which processes sequences of monocular frames by extracting features and modeling global relationships through temporal and spatial attention. Unlike prior methods, VoT directly predicts camera motion without estimating dense geometry and relies solely on camera poses for supervision. The framework is modular and flexible, allowing seamless integration of various pre-trained encoders as feature extractors. Experimental results demonstrate that VoT scales effectively with larger datasets, benefits substantially from stronger pre-trained backbones, generalizes across diverse camera motions and calibration settings, and outperforms traditional methods while running more than 3 times faster. The code will be released.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Visual Odometry with Transformers — Explained Simply
What is this paper about?
This paper is about teaching a computer to figure out how a camera moves through the world just by looking at a video from a single camera (called “monocular” visual odometry). Think of it like tracing the path your phone takes as you walk around your house, using only the video it records—no extra sensors, no fancy calibration steps. The authors introduce a new method called VoT (Visual odometry Transformer) that does this quickly and accurately.
What questions are the researchers trying to answer?
The paper asks:
- Can we estimate a camera’s motion directly from video frames without using complex, hand-crafted steps like feature matching or bundle adjustment?
- Can a transformer (a kind of AI model) learn the camera’s movement from long videos and work well in different places (indoors, outdoors) and with different cameras?
- Is this simpler, “end-to-end” approach both accurate and fast?
How does their method work?
Here’s the big idea, explained with everyday analogies:
- End-to-end learning: Instead of building a pipeline with many separate tools (like trying to fix a bike with lots of specialized gadgets), their model learns everything in one go—input: video frames; output: how the camera moved between frames.
- Transformers: A transformer is an AI model that uses “attention” to focus on the most important parts of the data. Imagine reading a mystery novel and remembering key clues from earlier chapters while understanding a new chapter. The model does something similar across video frames.
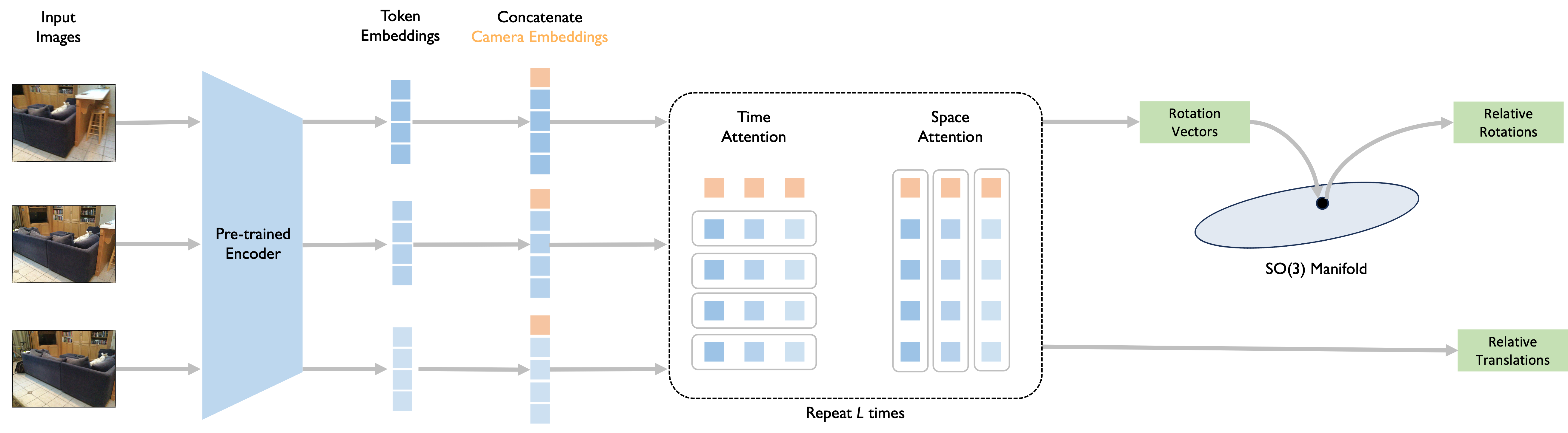
- Feature extraction (the encoder): Each video frame is turned into a set of “tokens” (small patches), like cutting a photo into tiles and describing each tile. A pre-trained Vision Transformer (ViT) creates a compact description (features) for every frame.
- Time-space attention (the decoder): The model first looks across time (how parts of the image change between frames) and then across space (how parts within the same frame relate).
- Temporal attention: Like comparing the same corner of a room across multiple frames to see how it moves.
- Spatial attention: Like checking how different parts of a single frame relate, so the model understands the scene layout.
- A special “camera token” summarizes each frame—like a headline for that frame.
- Pose prediction: For each pair of consecutive frames, the model predicts:
- Rotation: how much the camera turned (like turning your head left/right/up/down).
- Translation: how much the camera moved (like stepping forward/backward/sideways).
- The rotation is made valid by projecting it onto the set of proper rotations (called the SO(3) manifold). Think of it like adjusting a slightly off steering wheel reading to the nearest correct angle.
- Training: The model is taught using:
- Rotation loss: measures the smallest angle difference between predicted and true rotations.
- Translation loss: measures how far the predicted movement is from the true movement.
- These are combined to guide learning.
What did they find?
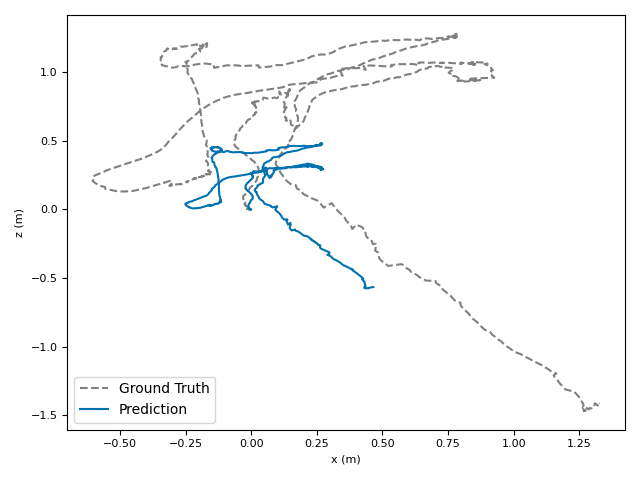
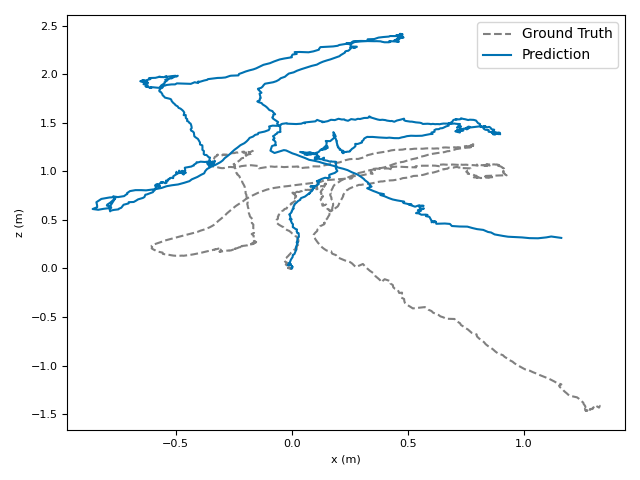
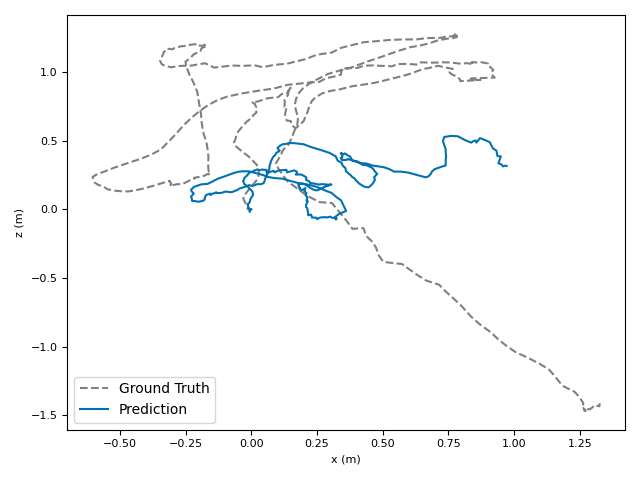
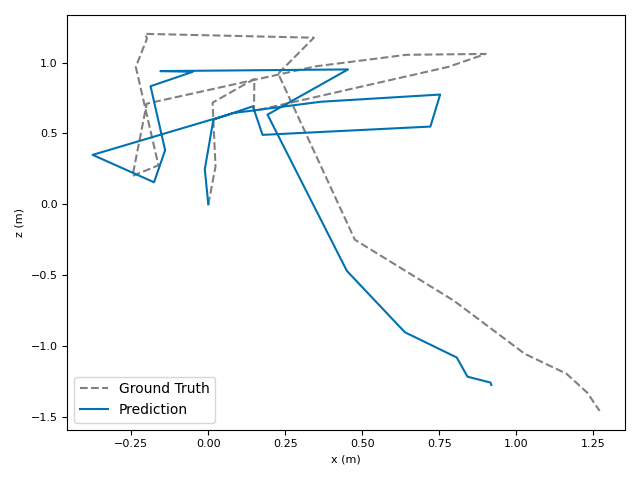
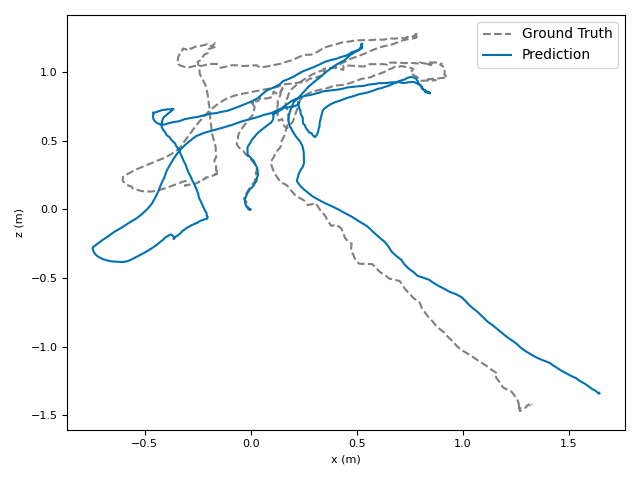
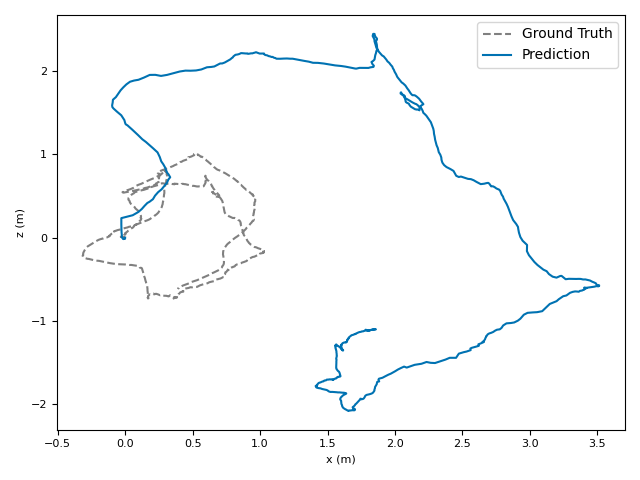
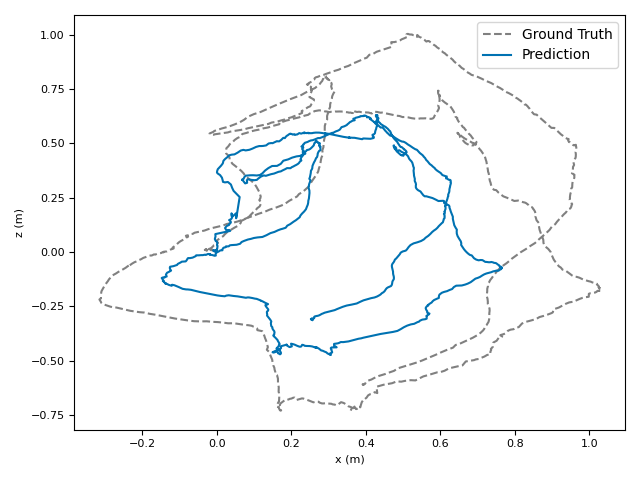
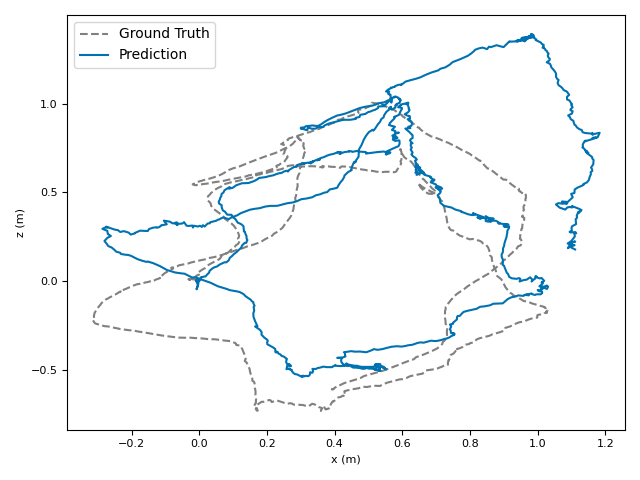
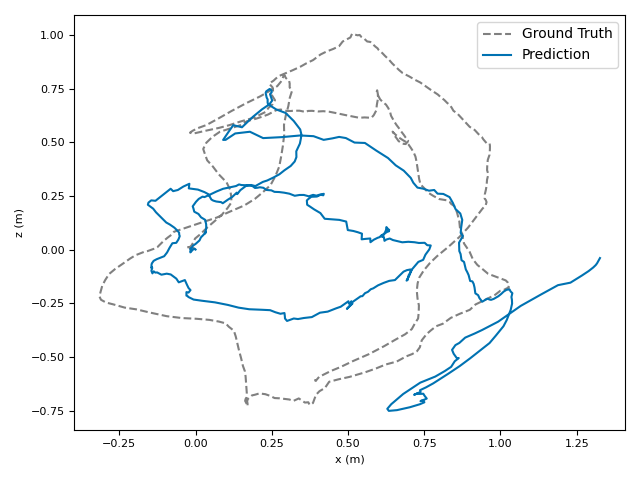
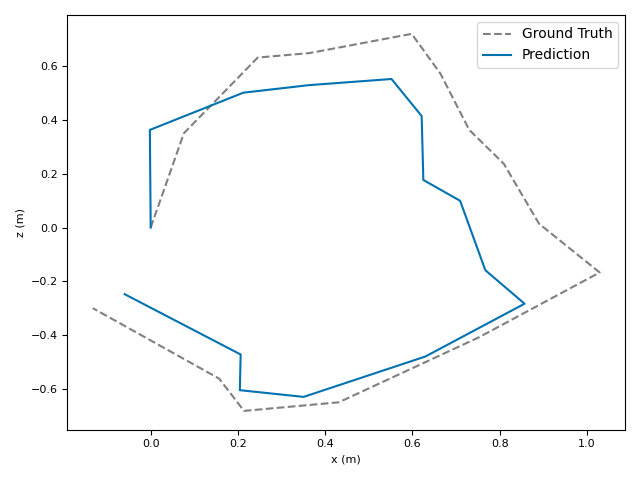
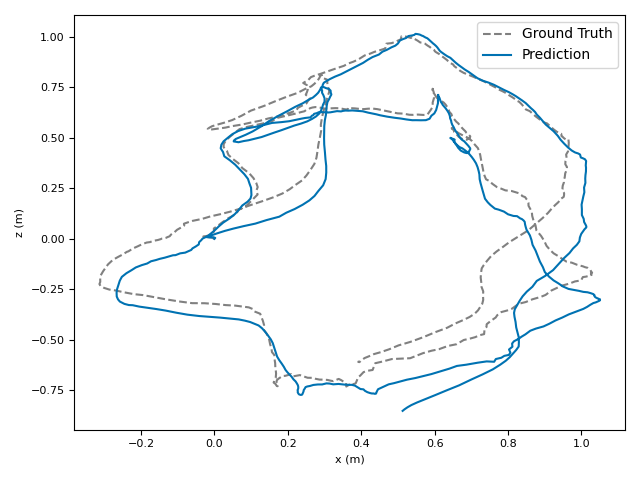
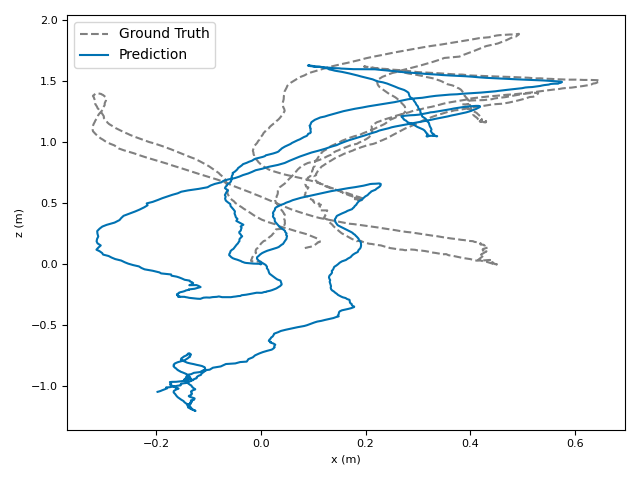
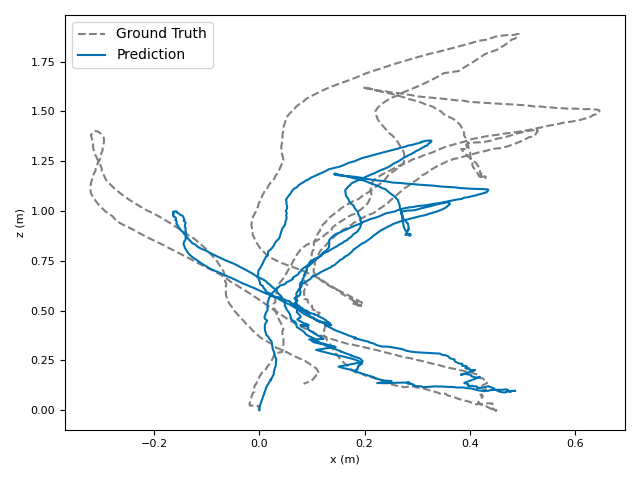
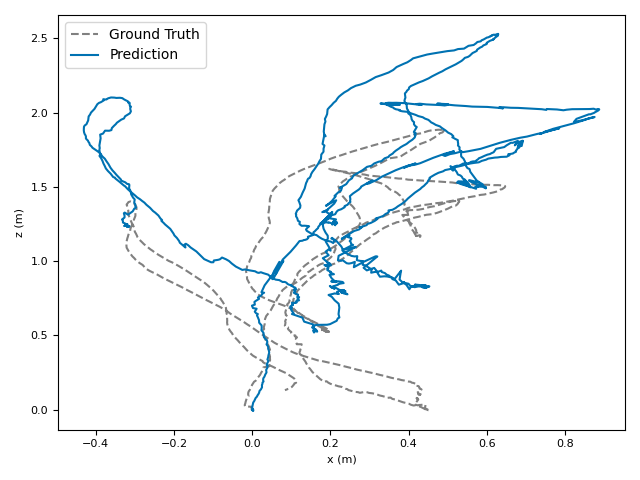
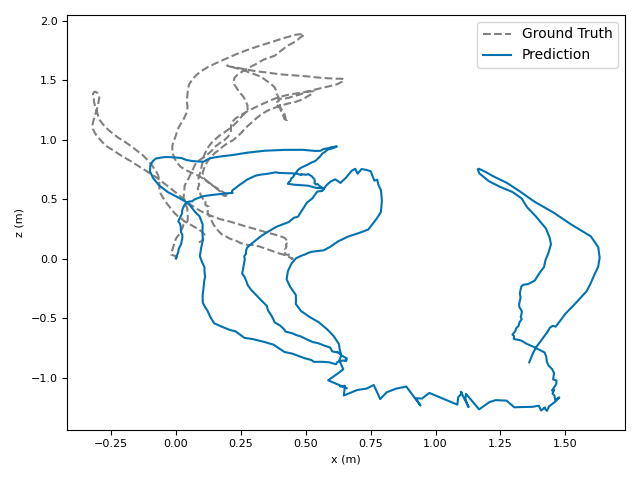
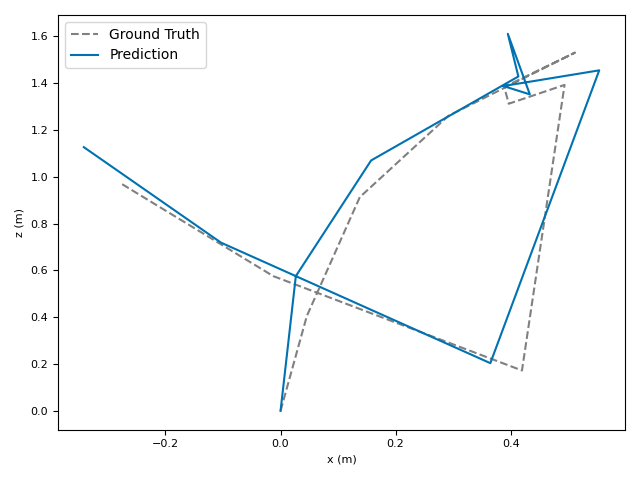
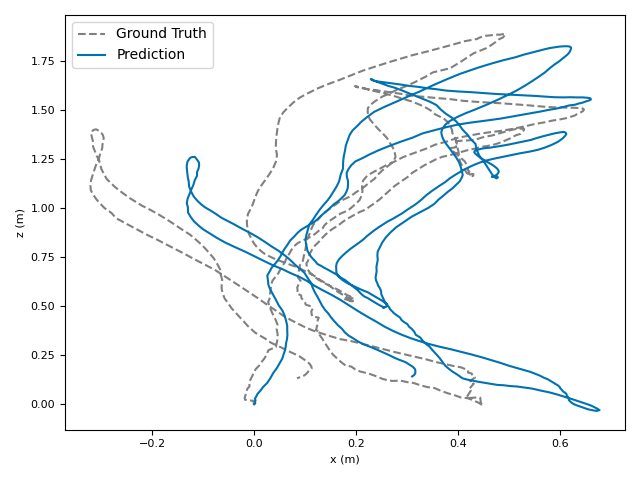
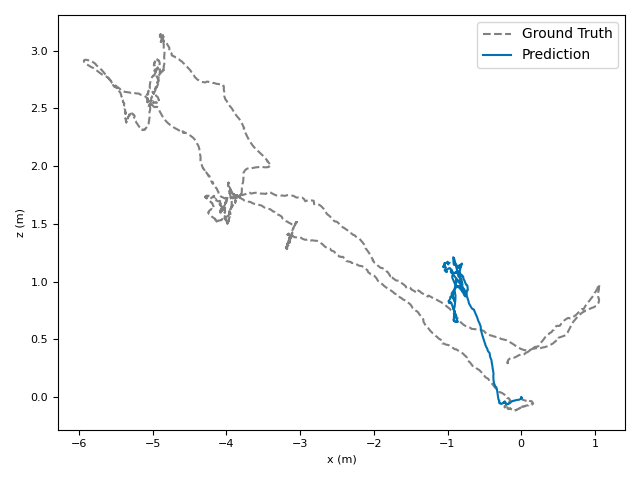
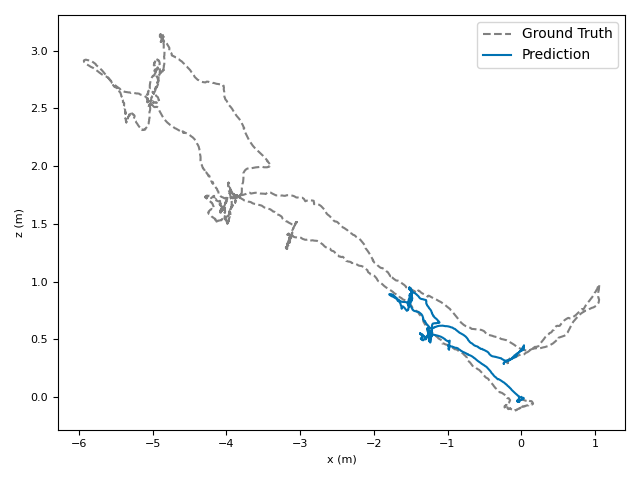
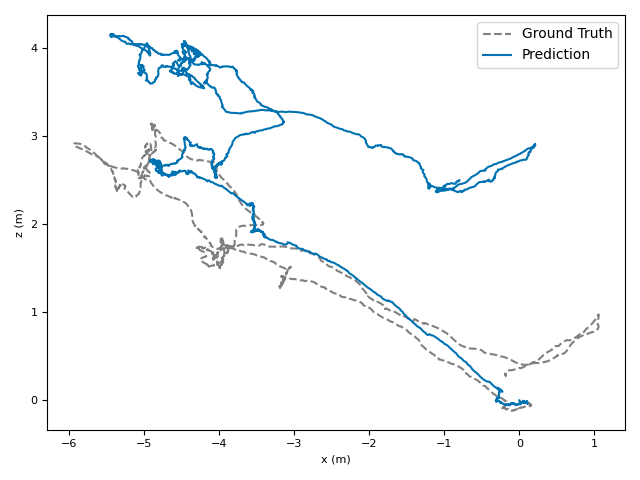
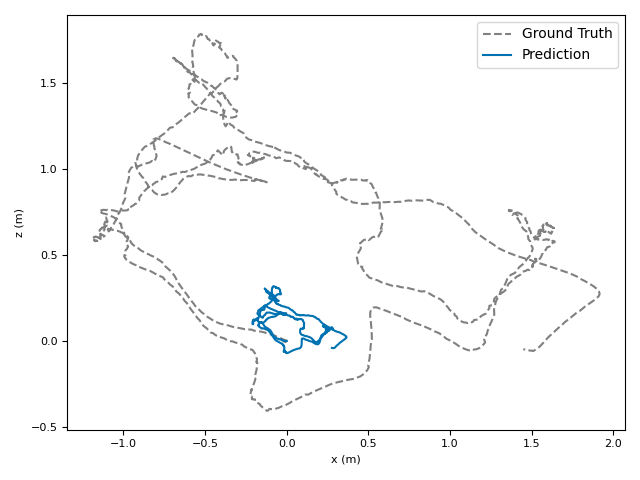
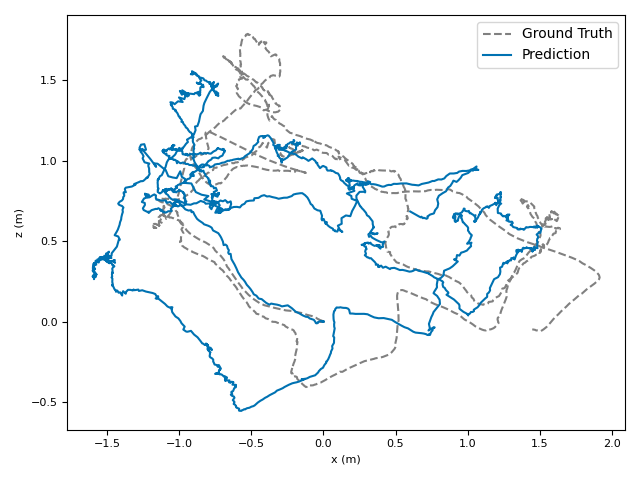
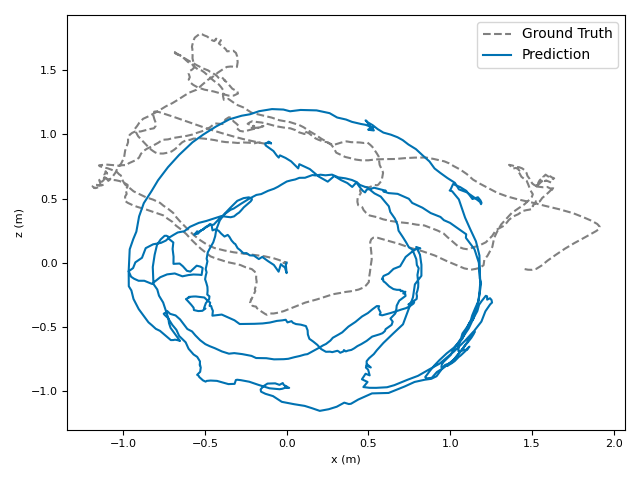
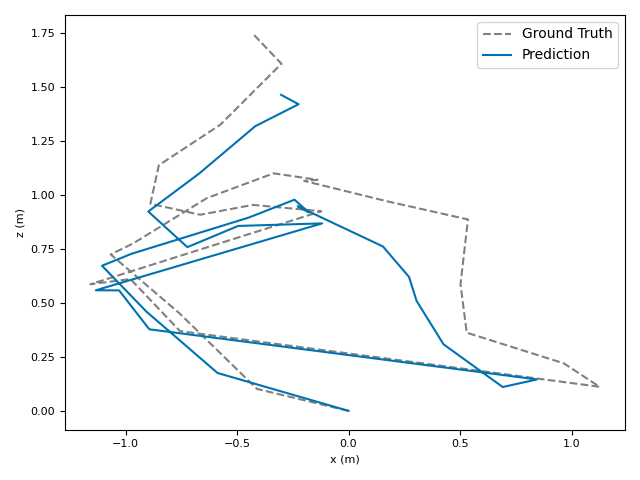
The researchers tested VoT on big, well-known datasets (ARKitScenes, ScanNet, KITTI, TUM RGB-D) and compared it to both classic methods and modern deep models.
Key results:
- Accuracy: VoT often wins or is among the best on important metrics:
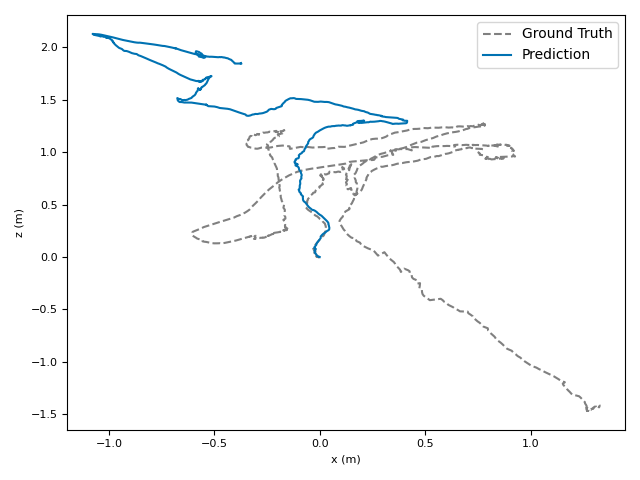
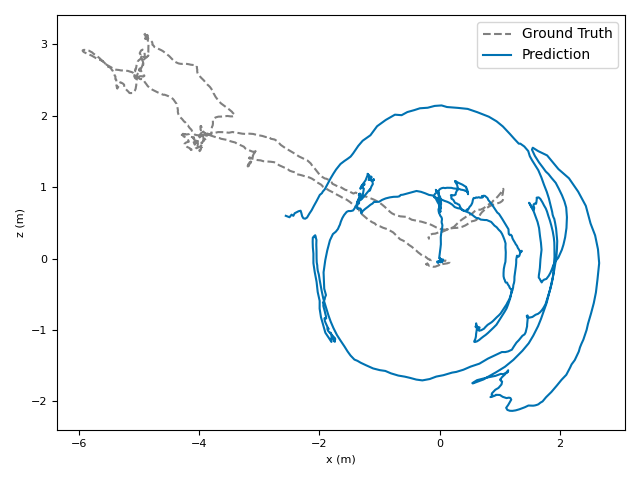
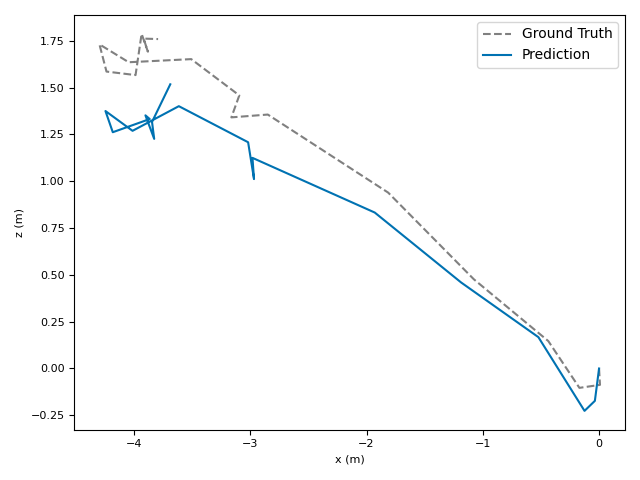
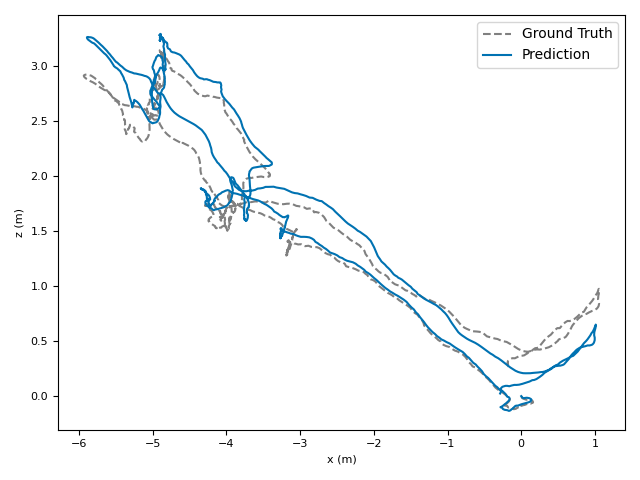
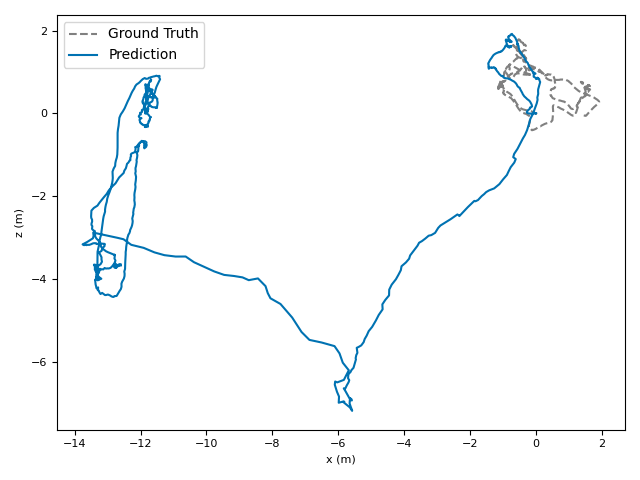
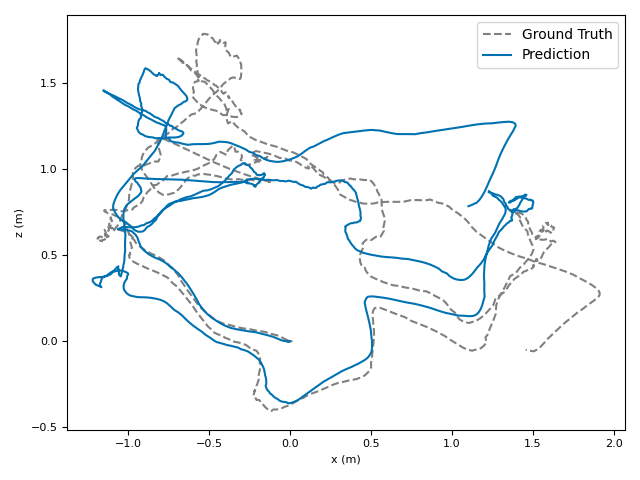
- ATE (Absolute Translation Error): how far off the path is, in meters.
- ARE (Absolute Rotation Error): how far off the camera’s turning is, in degrees.
- RTE/RRE (Relative errors): how much drift happens per small step along the route.
- Generalization: VoT works well across different places and different camera settings without needing camera parameters (no calibration needed).
- Speed: VoT runs over 3× faster than popular methods, making it more practical for real-time use.
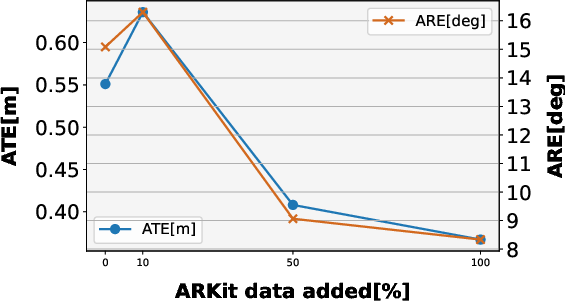
- Scalability: Training on more data and using stronger pre-trained encoders leads to better results. Time-space attention is both more accurate and more efficient than using full attention.
- Simplicity: No bundle adjustment, no feature matching, no extra geometry tasks—just direct pose prediction.
Why that’s important:
- It cuts complexity while boosting speed and accuracy.
- It works across different environments (indoors, outdoors) and camera setups.
- It’s easier to use and extend, and can benefit from larger datasets over time.
Why does this matter?
This research shows that a simpler, end-to-end transformer model can handle visual odometry well. That’s useful for:
- AR/VR: Smoothly tracking a headset or phone as you move.
- Robotics and drones: Understanding movement using a single camera, even in new places.
- Self-driving and mapping: Faster, reliable motion estimates without complex calibration steps.
Limitations and future directions
- Current training focuses on mostly static environments (not many moving people or cars). Performance might drop in very dynamic scenes.
- Future improvements could come from training on more varied videos, bigger models, and better pre-trained feature extractors.
In short
VoT is a fast, accurate, and simpler way to estimate how a camera moves through the world using only video. By using a transformer with smart time-and-space attention and training it end-to-end, the model avoids complicated hand-crafted steps, scales well with data, and works across different environments—making it a strong, practical approach for real-world visual odometry.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following concrete gaps, limitations, and unanswered questions remain based on the paper and its experiments:
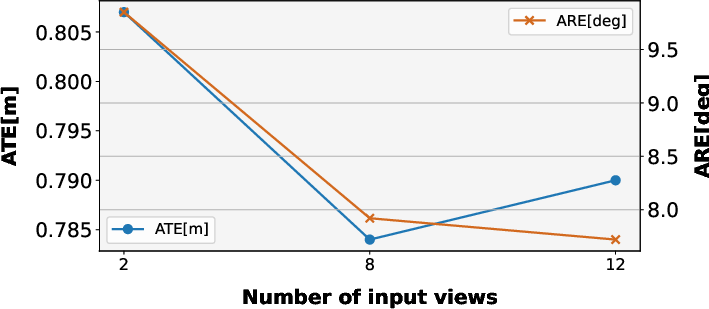
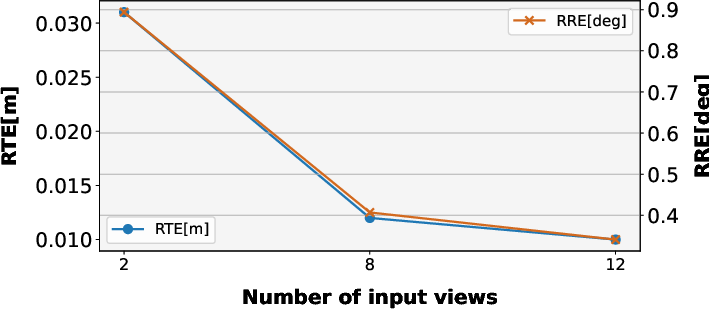
- Long-horizon odometry remains underexplored: the model is trained/inferred with short windows (e.g., 8–12 frames), and the paper does not detail a streaming or chunking strategy for sequences with thousands of frames nor quantify drift accumulation over very long trajectories.
- Causality for real-time deployment is unclear: VoT appears to use bidirectional attention over a frame batch; a strictly causal variant (only past frames) for online VO and its accuracy/speed trade-offs are not evaluated.
- Composition from predicted relative poses to a globally consistent trajectory is unspecified, including how errors accumulate, whether any smoothing is applied, and how failure cases propagate.
- Absence of loop closure or lightweight global optimization: while the paper deliberately avoids bundle adjustment, it leaves open whether minimal, learned or differentiable global corrections (e.g., sliding-window optimization or loop-closure-aware attention) could reduce drift without heavy hand-crafted pipelines.
- Robustness in dynamic scenes with moving objects is acknowledged as a limitation but not quantified; there is no evaluation on datasets with strong dynamics or motion segmentation strategies to mitigate such effects.
- Sensitivity to camera intrinsics is not analyzed: performance under controlled changes to focal length, principal point, field of view, and lens distortion (including fisheye) is unknown when no camera parameters are provided.
- Rolling-shutter and photometric artifacts (motion blur, low light, HDR, exposure flicker) are mentioned but not systematically tested; controlled robustness benchmarks are needed.
- Scale estimation origins and failure modes are not characterized: when and why the learned absolute scale succeeds or fails across domains and devices (especially outdoors) remain unclear.
- OOD generalization is only validated on TUM_RGBD; broader tests across diverse devices (e.g., smartphone brands, action cameras, head-mounted cameras), sensors (global vs rolling shutter), and environments (industrial, crowded urban) are missing.
- Image resolution and patch size effects are not studied: all experiments fix 224×224 resolution and a single patch size; the impact of higher resolution, multi-scale features, or variable patching on accuracy and drift is unexplored.
- Efficient long-range attention variants are not compared beyond “full vs time-space”: alternatives (divided space-time, axial, sparse local-global, memory tokens) and their effect on long-context modeling, accuracy, and compute are open.
- Camera embedding design choices are not ablated: including/excluding camera tokens in temporal attention, alternative aggregators (CLS tokens, pooling, cross-attention), or multi-token summaries per frame could affect performance.
- SVD-based SO(3) projection is used but its differentiability and numerical stability in training are not analyzed; gradient behavior under near-singular predictions and alternative continuous parametrizations (e.g., Lie algebra, 6D rotation) merit study.
- Loss design and hyperparameter sensitivity are not reported (e.g., values of λ, γ, schedules): effects of different rotation/translation losses, multi-step consistency, cycle or SE(3) regularization, and curriculum strategies are unknown.
- The encoder is frozen; the benefits and risks of fine-tuning (full, partial, adapters), domain adaptation, and sample efficiency vs compute are not assessed.
- Training label quality and robustness are not addressed: ARKitScenes/ScanNet poses can be noisy; the impact of label noise, robust losses, or data cleaning on generalization and scale accuracy is unexplored.
- Streaming performance across hardware is only profiled on a single GPU (L4) and one scene; latency, throughput, memory footprint, and energy on CPUs, mobile SoCs, and embedded platforms are not evaluated.
- Failure-case taxonomy is absent: scenarios with low parallax, pure rotations, textureless surfaces, repetitive patterns, heavy occlusions, and fast motion spikes are not analyzed or mitigated.
- Optional use of camera parameters is not investigated: whether providing intrinsics when available improves accuracy or reduces drift, and how to design parameter-aware tokens, is open.
- Weak geometric priors are not tested: lightweight epipolar or rigidity constraints (e.g., contrastive match consistency) might improve generalization without reverting to full hand-crafted pipelines.
- The stride and frame-rate sensitivity are not studied: varying temporal sampling, irregular timestamps, and dropped frames in real recordings could affect accuracy; adaptive temporal modeling is open.
- Uncertainty estimation is missing: the model outputs deterministic poses without confidence/covariance; uncertainty-aware odometry for downstream fusion and failure detection remains to be developed.
- Integration into SLAM is not explored: how VoT serves as a front-end within mapping, loop closure, and relocalization pipelines, and the end-to-end benefits vs classical components, are not assessed.
- Self-supervised or weakly supervised extensions are absent: reducing reliance on accurate pose labels (e.g., via photometric, geometric, or cycle constraints) and leveraging unlabelled videos are open directions.
- Domain coverage and data curation pipelines are not specified: systematic strategies to scale to more diverse devices/environments, balance domains, and detect/correct dataset biases could materially affect generalization.
Glossary
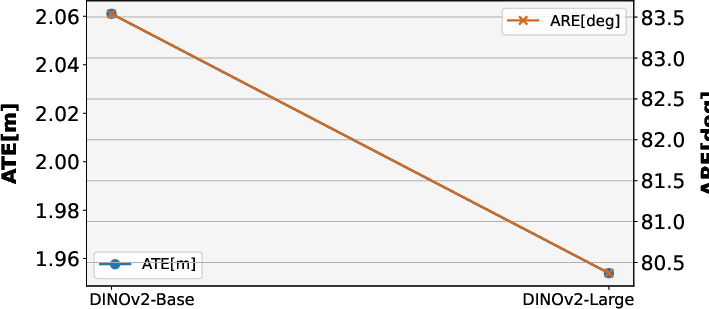
- Absolute Rotation Error (ARE): A metric measuring the root mean squared error of angular orientation differences between estimated and ground-truth trajectories. "We evaluate visual odometry using Absolute Translation Error (ATE) and Absolute Rotation Error (ARE)~\citep{teed2023dpvo,chen2024leapvo}."
- Absolute Translation Error (ATE): A metric measuring the root mean squared error of translation between estimated and ground-truth trajectories. "ATE is the RMSE of translation between estimated and ground-truth trajectories, while ARE is the RMSE of angular orientation differences."
- AdamW: An optimization algorithm that decouples weight decay from gradient updates to improve generalization during training. "Our model is trained with the AdamW~\citep{loshchilov2017adamw} optimizer for 300 epochs."
- Axial attention: An efficient attention variant that applies attention along a single axis (spatial or temporal) to reduce complexity in video transformers. "or employing efficient variants such as divided space-time, sparse local-global, and axial attention \citep{bertasius2021timesformer, arnab2021vivit, zhao2022tuber}."
- Bundle adjustment: A post-optimization technique that jointly refines camera poses and 3D structure by minimizing reprojection error. "However, their performance critically relies on postprocessing techniques such as bundle adjustment or feature matching to refine the estimates of camera poses."
- Camera embeddings: Learnable tokens added per frame to summarize information for pose estimation within spatial attention layers. "To summarize the information in each frame, we use camera embeddings, which are learnable embeddings in spatial attention sub-layers."
- Camera parameters: Calibration values (e.g., intrinsics) required by some methods to recover scale and accurate poses. "Existing methods generalize poorly because they rely on small, hard-to-scale architectures, complex hand-crafted components, and often require camera parameters, limiting real-world use."
- Cosine learning rate schedule: A training schedule where the learning rate follows a cosine curve, typically with warmup, to stabilize optimization. "We adopt a cosine learning rate schedule with an initial learning rate of 0.00001 and a warmup phase of 30 epochs."
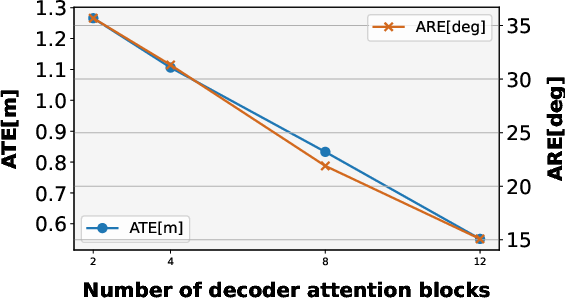
- Decoder: The part of a transformer architecture that aggregates and attends over features to produce task-specific outputs. "The decoder consists of a stack of identical layers, each containing three sub-layers."
- Divided space-time: A factorized attention approach that separately handles spatial and temporal components for efficiency in video modeling. "or employing efficient variants such as divided space-time, sparse local-global, and axial attention \citep{bertasius2021timesformer, arnab2021vivit, zhao2022tuber}."
- Drift: The accumulation of error in a trajectory estimate over time due to small pose estimation inaccuracies. "Unlike SLAM which corrects errors via loop closure~\citep{cadena2016past_present_future_of_slam,campos2021orbslam3,yugay2024magicslam}, these systems tend to accumulate camera tracking errors (drift)."
- End-to-end: A design where the model directly maps inputs to outputs without hand-crafted modules, trained jointly with a unified objective. "Motivated by these limitations, we propose a direct `end-to-end' pose regression approach that eliminates hand-crafted modules and auxiliary tasks."
- Frobenius norm: A matrix norm equal to the square root of the sum of squared entries, used to measure distance between matrices. "Projecting outputs onto the nearest valid rotation matrix on the SO(3) manifold using the Frobenius norm consistently yields the best results, highlighting its suitability for our formulation."
- Geodesic loss: A loss measuring angular distance on the rotation manifold between predicted and ground-truth rotations. "The rotation loss, denoted as $\mathcal{L}_{\text{rotation}(R, \hat{R})$, is the geodesic loss between the predicted rotation and the ground-truth rotation , defined as"
- Loop closure: A SLAM process that detects revisiting locations to correct accumulated drift in trajectories. "Unlike SLAM which corrects errors via loop closure~\citep{cadena2016past_present_future_of_slam,campos2021orbslam3,yugay2024magicslam}, these systems tend to accumulate camera tracking errors (drift)."
- Multi-head self-attention: An attention mechanism with multiple heads enabling the model to focus on different aspects of the input simultaneously. "The ViT layer follows the standard architecture, consisting of a multi-head self-attention module and a feed-forward network."
- Permutation-invariant: A property where the model’s computations do not inherently depend on input order, requiring positional encodings for sequence tasks. "Since the transformer architecture is permutation-invariant, we augment it with sinusoidal position encodings~\citep{vaswani2017transformer}."
- Procrustes problem (special orthogonal Procrustes): An optimization to find the closest valid rotation matrix to a predicted matrix under the Frobenius norm. "Rotation vectors are projected to the closest valid rotation matrix by solving the special orthogonal Procrustes~\citep{bregier2021deepregression} problem:"
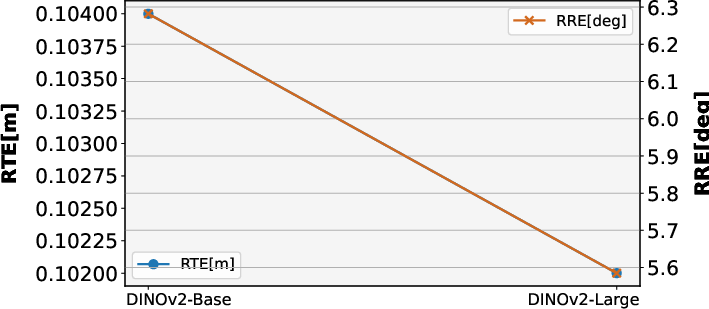
- Relative Rotation Error (RRE): A metric measuring drift in rotation over unit-length segments of a trajectory. "In addition, we report Relative Translation Error (RTE) and Relative Rotation Error (RRE), which measure the drift in translation and rotation over unit trajectory segments."
- Relative Translation Error (RTE): A metric measuring drift in translation over unit-length segments of a trajectory. "In addition, we report Relative Translation Error (RTE) and Relative Rotation Error (RRE), which measure the drift in translation and rotation over unit trajectory segments."
- RMSE: Root Mean Squared Error, a standard measure of discrepancy between predicted and true values. "ATE is the RMSE of translation between estimated and ground-truth trajectories, while ARE is the RMSE of angular orientation differences."
- Rolling shutter artifacts: Image distortions caused by row-wise exposure timing, affecting motion estimation. "Traditional monocular visual odometry methods~\citep{engel2014lsd, engel2018direct,campos2021orbslam3} are sensitive to illumination and rolling shutter artifacts, and more importantly, cannot adequately estimate the scale of the scene."
- Scaled dot-product attention: The core attention operation that scales query-key dot products before softmax to stabilize gradients. "Specifically, the temporal attention performs the scaled dot-product attention in the -th head along the temporal dimension as"
- Sinusoidal position encodings: Fixed positional embeddings using sine and cosine functions to inject order information into transformers. "Since the transformer architecture is permutation-invariant, we augment it with sinusoidal position encodings~\citep{vaswani2017transformer}."
- Singular value decomposition: A matrix factorization used to solve the Procrustes problem and project rotations onto SO(3). "The optimization problem is solved via singular value decomposition of following~\cite{umeyama1991lse}."
- SO(3) manifold: The mathematical space of 3D rotation matrices representing rigid body orientations. "we project them onto the SO(3) manifold and employ a loss function that computes the shortest distance between the predicted and ground-truth rotation matrices."
- Spatial attention: Attention applied across spatial tokens within a frame to model intra-frame relationships. "The first sub-layer is a multi-head temporal attention module, followed by a multi-head spatial attention module, and the final sub-layer is a feed-forward network."
- Stereo visual odometry: Visual odometry that uses stereo camera inputs to estimate motion and scale. "This growing interest is particularly notable when compared to systems that rely on stereo vision~\citep{wang2017stereo_dso,engel2014lsd} or multimodal inputs, such as visual-inertial odometry~\citep{stumberg2018direct_sparse_visual_inertial,christian2015robotics_science_systems}."
- Temporal attention: Attention applied along the time dimension to model inter-frame dependencies. "The first sub-layer is a multi-head temporal attention module, followed by a multi-head spatial attention module, and the final sub-layer is a feed-forward network."
- Time-space attention: A decoupled attention design that alternates temporal and spatial attention for efficient video modeling. "Time-space attention not only reduces computational cost but also consistently improves accuracy."
- Token embeddings: Vector representations of image patches produced by an encoder for downstream processing. "Given multiple input frames, a frozen image encoder extracts per-image token embeddings."
- Vision Transformer (ViT): A transformer architecture for images that operates on patch tokens. "As the Vision Transformer (ViT) \citep{dosovitskiy2020vit} has become the dominant architecture in computer vision, our pre-trained encoders are based on ViT."
- Visual-inertial odometry: Motion estimation that fuses visual data with inertial measurements to improve robustness. "Many different modalities of visual odometry have been explored by past work, including visual-inertial odometry~\citep{christian2015robotics_science_systems,stumberg2018direct_sparse_visual_inertial} and stereo visual odometry~\citep{engel2014lsd,wang2017stereo_dso}."
Practical Applications
Below are actionable applications derived from the paper’s findings and innovations in end-to-end monocular visual odometry with transformers (VoT). Each item notes sector relevance, feasibility timeline, and key dependencies that may affect deployment.
Immediate Applications
- Monocular odometry module for mobile robots and drones (Robotics)
- Use case: Drop-in pose estimation for indoor warehouse robots, delivery robots, AGVs, and small UAVs when GPS/LiDAR are unavailable or costly.
- Tools/products/workflows: ROS2 node for VoT; EKF-based fusion with existing localization stacks; TensorRT-optimized inference for edge GPUs.
- Assumptions/dependencies: Static or semi-static scenes; acceptable drift without loop closure; IMU fusion recommended for aggressive motion or high-speed flight.
- AR/VR device motion tracking without calibration (Software, XR)
- Use case: Stabilized head/camera tracking for AR apps on smartphones/headsets across diverse camera parameters.
- Tools/products/workflows: Unity/Unreal plugin; mobile SDK (iOS/Android) wrapping PyTorch/ONNX/TensorRT VoT inference; app-side smoothing of trajectories.
- Assumptions/dependencies: Consistent frame rates and reasonable lighting; performance may degrade in highly dynamic scenes; battery/thermal constraints on mobile.
- Camera tracking for VFX and post-production (Media/Entertainment)
- Use case: Offline camera solve from monocular footage for matchmoving/previs without lens calibration or markers.
- Tools/products/workflows: Plugins for Blender/Nuke/After Effects; batch trajectory export to standard pose formats (e.g., Alembic/FBX).
- Assumptions/dependencies: Long-sequence drift may require light trajectory smoothing or sparse alignment; robust handling of motion blur/rolling shutter varies by footage.
- Video stabilization and horizon leveling (Consumer software)
- Use case: Stabilize action cam/smartphone footage by re-rendering frames using predicted camera motion.
- Tools/products/workflows: Integrated into mobile editing apps; pipeline: VoT pose → smoothing → crop/re-time.
- Assumptions/dependencies: Cropping/zoom for stabilization; fast motions and heavy blur may reduce pose quality.
- Rapid trajectory labeling for research datasets (Academia)
- Use case: Auto-annotate camera poses for new video datasets where ground truth is missing, speeding up dataset curation.
- Tools/products/workflows: Batch processing pipeline; quality gates on ATE/RTE; manual review loop for outliers.
- Assumptions/dependencies: Domain similarity to training data (indoor/outdoor); OOD generalization is good but not guaranteed.
- CCTV/body-worn camera analytics with moving cameras (Security, Retail)
- Use case: Distinguish camera motion from scene dynamics; index streams by segments of stable motion.
- Tools/products/workflows: Stream processing microservice; alerts for unexpected camera movement; analytics dashboards.
- Assumptions/dependencies: Variable FPS, motion blur, and compression artifacts; calibration-free operation tolerated.
- Phone-based indoor mapping aids for photogrammetry (AEC, Real estate)
- Use case: Provide initial camera trajectories to speed up SfM and reduce solver failures, enabling quick scans of rooms/offices.
- Tools/products/workflows: Pre-align frames before RealityCapture/Metashape; export absolute-scale poses when feasible.
- Assumptions/dependencies: No loop closure; drift over long paths; dynamic activity (people/tools) may affect accuracy.
- Fallback localization in autonomous driving stacks (Automotive)
- Use case: Camera-only odometry when LiDAR/GPS degrades (e.g., tunnels, urban canyons).
- Tools/products/workflows: VoT module feeding an EKF with IMU; watchdog to switch in/out based on health metrics.
- Assumptions/dependencies: High-speed, high-dynamics domain; robust IMU synchronization; formal safety/verification required.
- Teaching and reproducible baselines in VO courses (Academia, Education)
- Use case: Demonstrate end-to-end VO without bundle adjustment/camera parameters; study scaling laws.
- Tools/products/workflows: PyTorch notebooks; assignments using public datasets (ScanNet, TUM RGB-D, KITTI).
- Assumptions/dependencies: Compute availability for training; pre-trained backbones (CroCo/DUST3R) improve outcomes.
- Teleoperation path visualization from monocular feeds (Robotics)
- Use case: Provide operators with live trajectory overlays for remote driving/inspection robots.
- Tools/products/workflows: Web UI visualizing live poses; compressed streaming of pose sequences.
- Assumptions/dependencies: Network jitter; dynamic obstacles; fusion with other sensors recommended.
- Pre-alignment for NeRF or Gaussian Splatting pipelines (Software, 3D)
- Use case: Initialize camera poses to speed convergence and reduce reconstruction failures.
- Tools/products/workflows: Preprocessor for nerfstudio/gsplat; optional fine alignment inside the 3D pipeline.
- Assumptions/dependencies: Stable exposure and motion; absolute scale quality impacts scene realism.
- Energy-efficient edge inference (Energy, Software)
- Use case: Reduce compute and latency versus optimization-heavy SLAM in embedded/edge scenarios.
- Tools/products/workflows: Quantized inference (INT8/FP16) on NPUs/edge GPUs; batch processing of frames.
- Assumptions/dependencies: Accuracy-vs-power trade-offs; careful calibration of quantization to retain rotation fidelity (SO(3) projection).
Long-Term Applications
- Foundation odometry model across domains and devices (Software, Robotics, XR)
- Use case: Universal camera-pose service that generalizes to indoor/outdoor, mobile/vehicle, consumer/industrial cameras.
- Tools/products/workflows: Cloud API with device-agnostic models; continual learning pipelines.
- Assumptions/dependencies: Scaling training to heterogeneous, dynamic datasets; robustness to severe domain shifts; governance of updates.
- Visual–inertial VoT (VIO) for drift reduction (Robotics, Automotive, XR)
- Use case: Fuse VoT with IMU to gain robustness in fast motion and challenging conditions.
- Tools/products/workflows: Differentiable filtering (EKF/UKF) or learned fusion; time-sync tools.
- Assumptions/dependencies: Reliable IMU synchronization; additional training; certification in safety-critical use.
- End-to-end SLAM with loop closure and global optimization (Software, Robotics)
- Use case: Extend VoT to correct long-term drift via learned memory/place recognition and differentiable loop closure.
- Tools/products/workflows: VoT-SLAM architecture with temporal memory; graph optimization layers.
- Assumptions/dependencies: Research on scalable memory/attention; curated long video datasets with loop closures.
- OS-level integration in mobile platforms (Healthcare, Education, Consumer)
- Use case: System services for AR/VR, indoor navigation, and camera stabilization across apps.
- Tools/products/workflows: iOS/Android runtime modules; vendor-specific NPU acceleration.
- Assumptions/dependencies: Platform adoption; access to camera pipelines; privacy/compliance.
- Multi-camera/360° rigs and self-calibration (Robotics, Media)
- Use case: Robust pose estimation from synchronized multi-view cameras without explicit calibration.
- Tools/products/workflows: Multi-stream transformer; self-calibration routines; rig management tools.
- Assumptions/dependencies: Precise time sync; training on multi-view data; handling parallax and distortion.
- GPS-denied navigation for emergency response and mining (Public safety, Energy)
- Use case: Reliable monocular localization in smoke/dust/low light using specialized sensors.
- Tools/products/workflows: Sensor fusion with thermal/event cameras; ruggedized edge compute.
- Assumptions/dependencies: Extreme OOD conditions; domain-specific pretraining; robust hardware.
- Production-grade automotive localization (Automotive)
- Use case: Redundant perception channel for localization in L2+/L3 systems.
- Tools/products/workflows: Safety-certified pipeline; formal verification; continuous validation in fleet.
- Assumptions/dependencies: Regulatory approval; extensive corner-case testing; lifecycle management.
- Swarm UAVs and microrobots with monocular VO (Robotics)
- Use case: Lightweight camera-only navigation for tiny platforms.
- Tools/products/workflows: Highly optimized inference on micro-NPUs; cooperative localization protocols.
- Assumptions/dependencies: Severe motion/rolling shutter; resource limits; event-camera variants.
- Privacy-preserving indoor navigation for consumers (Consumer, Policy)
- Use case: On-device navigation without persistent maps or cloud uploads.
- Tools/products/workflows: Local inference with ephemeral trajectories; opt-in floorplan integration.
- Assumptions/dependencies: UX for map-free navigation; policy compliance (GDPR/CCPA); device heterogeneity.
- Medical endoscope and surgical camera tracking (Healthcare)
- Use case: Pose estimation from monocular surgical videos to aid navigation and tool tracking.
- Tools/products/workflows: Domain-adapted VoT with sterile hardware accelerators; integration into OR software.
- Assumptions/dependencies: Dynamic fluids/tissue motion; specialized training datasets; stringent reliability standards.
- Hardware acceleration and quantization for NPUs/FPGAs (Energy, Semiconductors)
- Use case: Low-power, high-throughput odometry for edge devices.
- Tools/products/workflows: Model compression, mixed-precision kernels; memory-optimized attention variants.
- Assumptions/dependencies: Maintaining rotation fidelity under quantization; co-design with hardware vendors.
- Standardization and benchmarking for camera-only odometry (Policy, Academia)
- Use case: Common, alignment-free metrics (ATE/RTE/RRE/ARE) and test suites for real-world deployment.
- Tools/products/workflows: Open benchmarks; procurement guidelines for public-sector robotics.
- Assumptions/dependencies: Community consensus; representative datasets across geographies and devices.
Notes on feasibility across applications:
- VoT’s strengths (end-to-end, calibration-free, faster inference, strong generalization to varied camera parameters) enable immediate deployment in many camera-motion tracking scenarios.
- Drift is expected without loop closure; long-term mapping and mission-critical autonomy will benefit from fusion (IMU, place recognition) or SLAM extensions.
- Performance depends on pre-training quality and domain match; dynamic environments and extreme conditions may require retraining or multimodal fusion.
- For mobile and embedded deployment, careful optimization (quantization, memory footprint, attention efficiency) is needed to preserve accuracy, especially for rotation (SO(3) projection).
Collections
Sign up for free to add this paper to one or more collections.