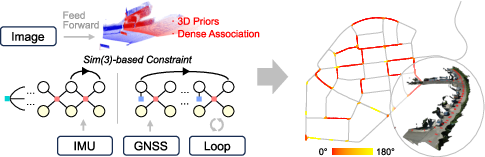
MASt3R-Fusion: Integrating Feed-Forward Visual Model with IMU, GNSS for High-Functionality SLAM
Abstract: Visual SLAM is a cornerstone technique in robotics, autonomous driving and extended reality (XR), yet classical systems often struggle with low-texture environments, scale ambiguity, and degraded performance under challenging visual conditions. Recent advancements in feed-forward neural network-based pointmap regression have demonstrated the potential to recover high-fidelity 3D scene geometry directly from images, leveraging learned spatial priors to overcome limitations of traditional multi-view geometry methods. However, the widely validated advantages of probabilistic multi-sensor information fusion are often discarded in these pipelines. In this work, we propose MASt3R-Fusion,a multi-sensor-assisted visual SLAM framework that tightly integrates feed-forward pointmap regression with complementary sensor information, including inertial measurements and GNSS data. The system introduces Sim(3)-based visualalignment constraints (in the Hessian form) into a universal metric-scale SE(3) factor graph for effective information fusion. A hierarchical factor graph design is developed, which allows both real-time sliding-window optimization and global optimization with aggressive loop closures, enabling real-time pose tracking, metric-scale structure perception and globally consistent mapping. We evaluate our approach on both public benchmarks and self-collected datasets, demonstrating substantial improvements in accuracy and robustness over existing visual-centered multi-sensor SLAM systems. The code will be released open-source to support reproducibility and further research (https://github.com/GREAT-WHU/MASt3R-Fusion).




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots and devices to understand where they are and build a 3D map of the world as they move. That skill is called SLAM: Simultaneous Localization and Mapping. The authors combine a smart vision model (that can guess 3D shapes from images) with motion sensors (IMU) and satellite positioning (GNSS/GPS) to make SLAM work better, faster, and more reliably—even in tough places where normal methods fail.
What questions did the researchers ask?
They set out to solve these simple-sounding but tricky problems:
- How can we make SLAM work well in places with few visual details (like plain walls) or bad lighting?
- How can we fix the “scale problem” in vision-only SLAM (images alone often can’t tell how big or far things really are)?
- How can we keep maps accurate over long time spans and big areas, not just in short clips?
- Can we tightly combine a modern vision model with IMU and GNSS so the system stays accurate, fast, and globally consistent?
How did they do it?
Think of the system as a team of experts:
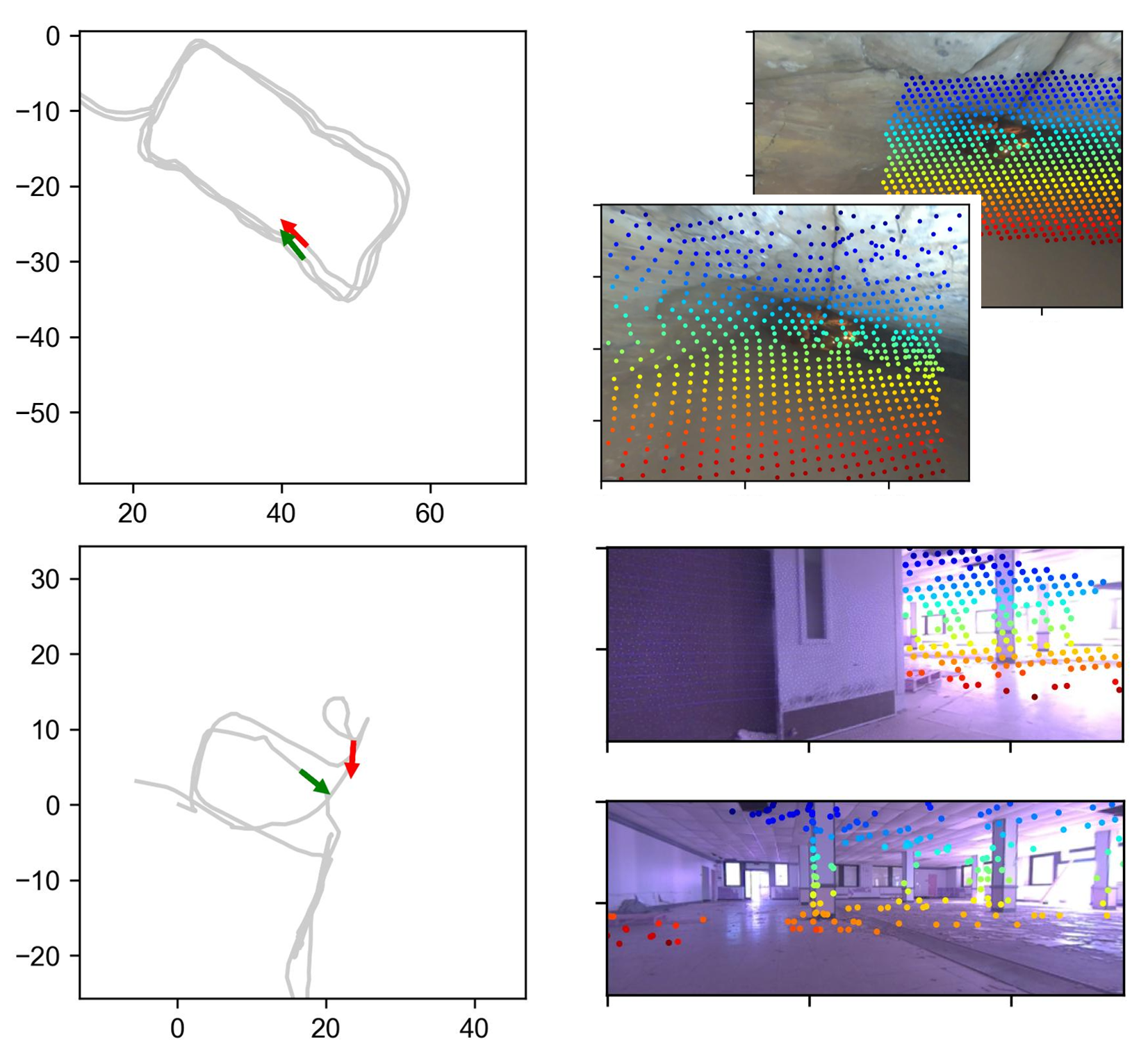
- The camera plus a “feed-forward” neural network acts like a quick 3D sketch artist. From pairs of images, it directly outputs a detailed 3D “pointmap,” which tells you where each pixel’s 3D point likely lies (but not yet its true size).
- The IMU (like the accelerometer and gyroscope in your phone) measures motions and rotations many times per second.
- GNSS (like GPS) gives global position (when available) to prevent long-term drift.
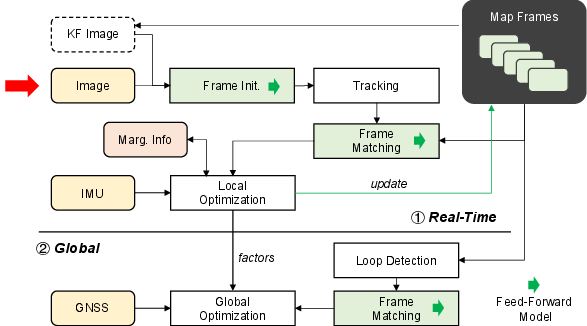
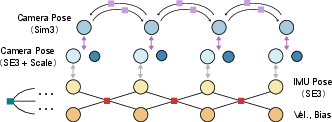
They connect these experts using a mathematical “web” called a factor graph, which gathers all observations and finds the best overall estimate of the device’s path and the map.
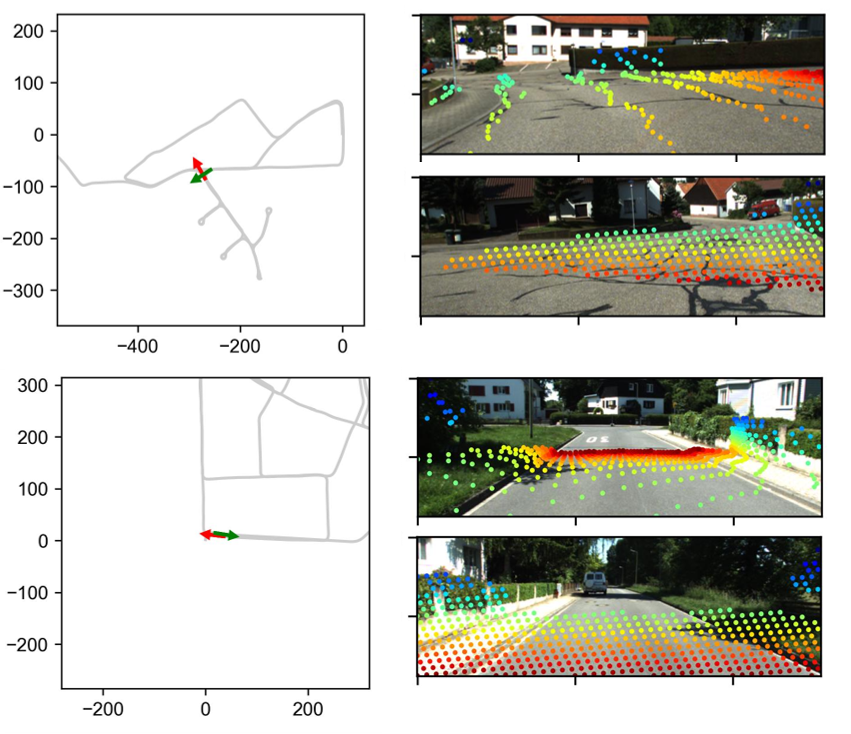
The feed-forward vision part: pointmaps
- A modern neural network (inspired by models like MASt3R/DUSt3R) looks at two images and directly predicts a dense 3D pointmap: a 3D point for almost every pixel.
- This is powerful because the model has “3D priors”—learned knowledge about how the world typically looks—so it can guess 3D structure even when textures are weak.
- Catch: this 3D map has unknown scale (is the room 3 meters wide or 30?). Vision alone can be “scale ambiguous.”
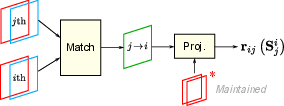
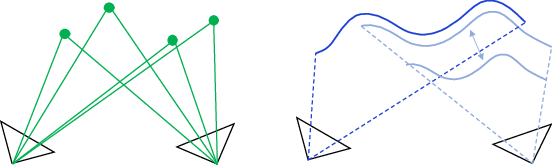
Aligning 3D pointmaps (instead of classic feature tracking)
Traditional SLAM often tracks many individual points and solves a big, slow puzzle called bundle adjustment. Here, the authors do something simpler and faster:
- They align the dense 3D pointmaps from different frames to figure out how the camera moved between them (its rotation, position, and a scale factor—think “where, which way, and how big”).
- This “pointmap alignment” uses lots of pixels at once and takes advantage of the network’s 3D knowledge.
- They compute heavy, pixel-by-pixel math on the GPU for speed, then compress the information and pass it to the CPU to fuse with the other sensors.
Mixing sensors with a factor graph
- They keep a sliding window of the most recent keyframes (important snapshots) and states: camera pose, scale, velocity, and IMU bias.
- Visual constraints live in “Sim(3)” space (position, rotation, plus scale). IMU and GNSS live in “SE(3)” space (position and rotation, with real-world meters). The authors bridge these worlds by separating “scale” as its own variable so all measurements can be combined consistently.
- They use “marginalization” to summarize old information so the problem stays small and fast, like keeping a short to-do list and a smart summary of past work.
Real-time stage vs. global stage
- Real-time stage: estimate motion and local 3D structure quickly using the feed-forward pointmaps + IMU in a small sliding window. This gives smooth, metric-scale motion with low drift, and it runs in real time on a laptop GPU (about 8 GB).
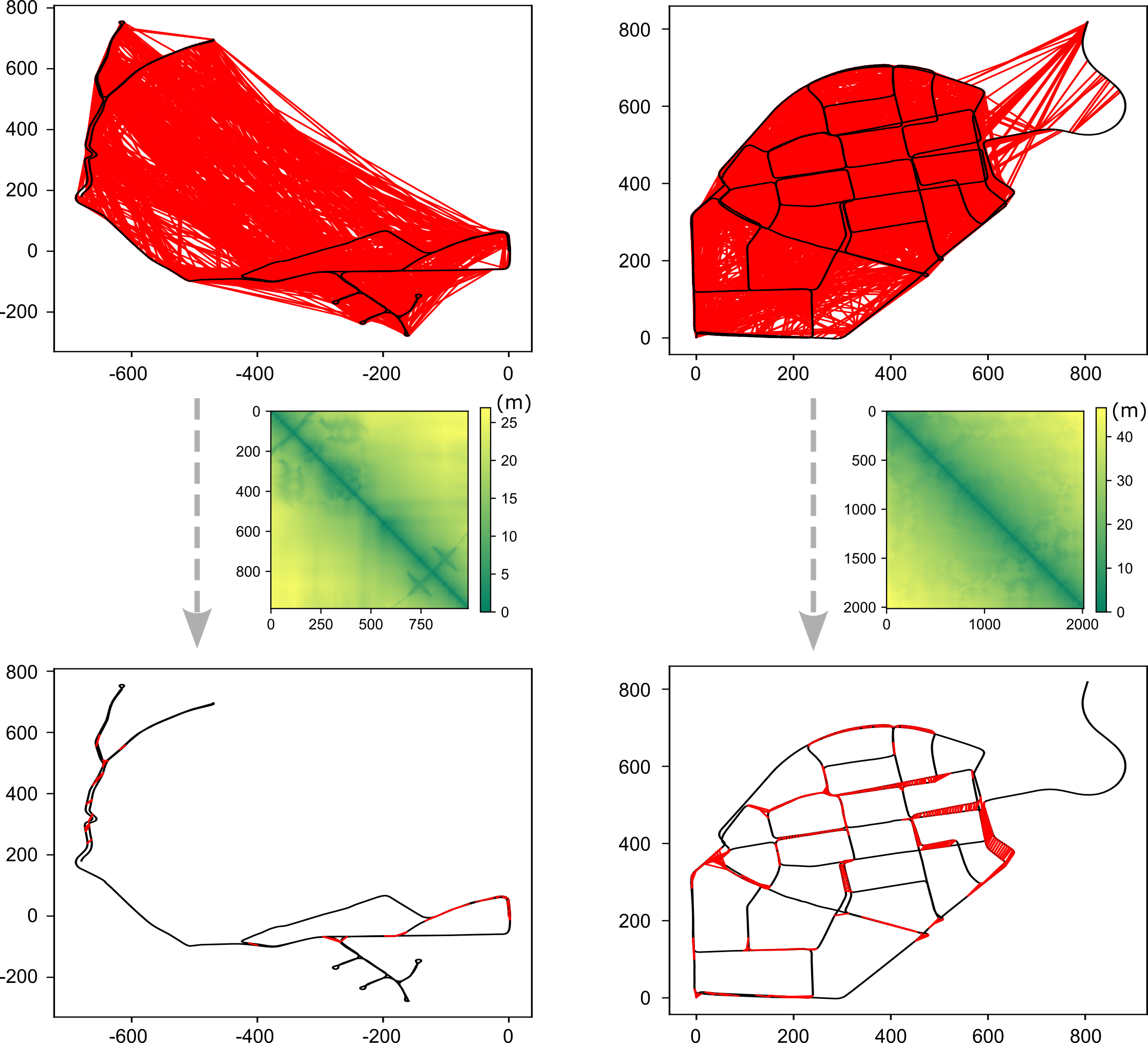
- Global stage: after logging data, they add “loop closures” (recognizing you’ve been here before, even from a very different angle) and GNSS positions. Then they do a larger optimization to make the whole map and trajectory globally consistent.
Smarter loop closures
- The feed-forward vision model can match scenes across huge viewpoint changes (helpful for loop closure).
- But to avoid false matches and save time, they first filter candidates using a fast geometric uncertainty check: “Is it even plausible these two frames could see the same area?” This keeps the bold matches but cuts down bad ones.
- Then they verify remaining candidates with the dense 3D matching, and finally fuse them into the global graph for a drift-free map.
Careful number handling
- GPU math is fast but uses lower precision (float32). World-scale mapping can need higher precision (float64). They compute dense vision parts locally on the GPU, then convert results to stable, double-precision constraints for the global solver—best of both worlds.
What did they find?
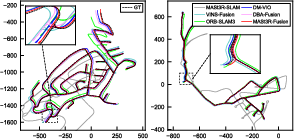
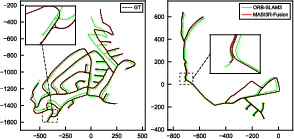
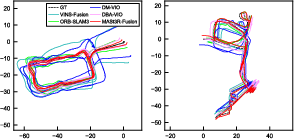
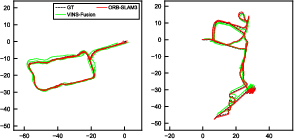
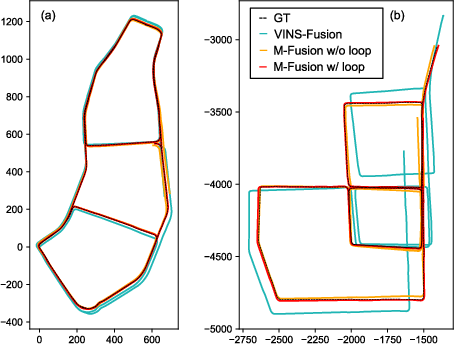
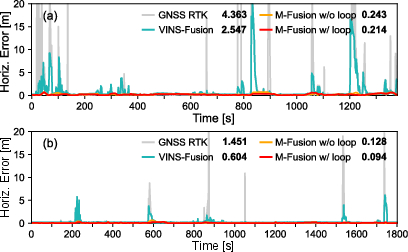
Across public benchmarks and their own datasets, this system:
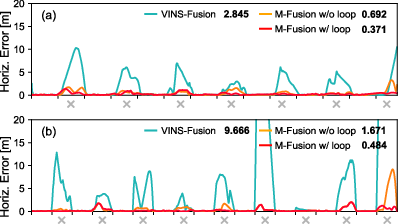
- Was more accurate and more robust than existing visual-centered multi-sensor SLAM systems.
- Kept real-time performance while giving metric-scale 3D understanding (knowing true sizes and distances).
- Produced maps that stay consistent globally by using loop closures and GNSS.
- Handled long sequences using only about 8 GB of GPU memory, thanks to efficient design.
In short: better accuracy, stronger robustness, real-time speed, and global consistency—all together.
Why does this matter?
This kind of SLAM is useful for:
- Robots and drones that must move safely and reliably in complex places.
- Autonomous cars needing strong position and map estimates in cities, forests, or tunnels.
- Augmented/extended reality apps that must place virtual objects precisely in the real world.
- Large-scale 3D mapping where speed and global accuracy both matter.
By tightly combining a powerful vision model with IMU and GNSS, the system works in more places, with fewer failures, and produces cleaner, more reliable maps.
Takeaway
MASt3R-Fusion shows that the future of SLAM blends learned 3D perception (fast, dense pointmaps) with classic sensor fusion (IMU, GNSS) in a smart optimization framework. The result is a high-functionality SLAM system that tracks motion in real time, understands scene structure at metric scale, and builds globally consistent maps. The authors will release their code, helping others build on this work.
Knowledge Gaps
Below is a single, concrete list of knowledge gaps, limitations, and open questions left unresolved by the paper. Each item is phrased to be actionable for future research.
- Lack of calibration-free operation: the method assumes known camera intrinsics and distortion; there is no strategy to handle unknown or time-varying calibration, rolling shutter, or lens distortion online.
- Heuristic handling of pointmap inaccuracies: the approach downweights residuals with a fixed mask and empirical threshold, without a principled per-pixel uncertainty model or calibrated confidence-to-covariance mapping from the feed-forward network.
- Scale parameterization and identifiability: maintaining per-keyframe scale s_i may introduce gauge freedoms and over-parameterization; there is no explicit regularization (e.g., continuity priors) or proof of identifiability when combining Sim(3) visual constraints with SE(3) IMU/GNSS.
- Validity of the Sim(3)→SE(3) isomorphic transformation: the diagonal mapping used to transfer Hessians/Jacobians is not theoretically validated under all operating conditions (e.g., large scales, strong scale-translation coupling); no empirical ablation quantifies its impact vs. alternative formulations.
- Mixed-precision numerical effects: dense residuals/Hessians are computed in float32 on GPU and mapped to float64; the accuracy/stability trade-offs, failure modes in very large-scale trajectories, and potential benefits of mixed-precision or compensated summation are not analyzed.
- Two-view limitation of the visual backbone: the system relies on MASt3R two-view regression; it does not explore multi-view feed-forward models or jointly decoding longer temporal windows to improve consistency, reduce ambiguity, and provide better uncertainties.
- Dynamic scene handling is ad hoc: removing dynamic points via depth residuals lacks motion segmentation, object tracking, or explicit dynamic modeling; robustness to crowded urban scenes or fast-moving objects remains unclear.
- Loop-closure candidate filtering relies on 2D horizontal simplification: the uncertainty model ignores vertical motion and elevation changes, which may degrade performance in multilevel or hilly environments.
- Heuristic selection of the “point of interest” and median depth L: there is no validation of sensitivity to L, nor a more principled view-based overlap predictor (e.g., frustum intersection, learned overlap, or 3D visibility tests).
- Retrieval and verification scalability: the paper does not detail large-scale indexing (ANN structures), memory footprints for token storage, or runtime for dense verification when sequences grow to millions of frames.
- Limited GNSS modeling: only position measurements are fused; velocities, headings, doppler, pseudorange/carrier-phase, and multi-constellation/RTK/PPP models (with multipath/ambiguity/outlier handling) are not considered.
- Unknown extrinsics and time offsets: IMU–camera extrinsics and camera–IMU–GNSS time offsets are assumed known; there is no online self-calibration or robustness to mis-synchronization.
- Global optimization uses relative loop poses first, then Hessian-form constraints: the conditions under which this two-stage strategy guarantees convergence/stability, and how many inliers are needed before switching, are not formally established.
- No real-time loop closure: loop closures are handled offline in the global stage; the feasibility of online loop closing without breaking real-time constraints is not explored.
- Occlusion-aware matching is absent: the dense association does not explicitly model occlusions, visibility, or out-of-FOV points, which can bias residuals in large-baseline projections.
- Robustness to severe visual degradation: performance under night-time, glare, fog/rain/snow, low-light, and repetitive textures is not quantified; no fallback (e.g., LiDAR, thermal) is considered when the visual model fails.
- Uncertainty propagation from visual constraints: beyond network confidences and Huber kernels, there is no rigorous probabilistic treatment of per-point covariance, correlation across pixels, or uncertainty propagation through the factor graph.
- Evaluation and ablations are under-specified: the paper lacks detailed runtime (CPU/GPU), memory profiles, energy consumption, and module-wise ablations (e.g., effect of IMU, GNSS, loop filtering, downweight mask, isomorphic mapping) across diverse sensors/datasets.
- Map representation and compression: the system produces dense pointmaps but does not address long-term map storage, compression, redundancy removal, or rendering-friendly representations (e.g., 3DGS/NeRF) for XR/robotics.
- Multi-session alignment and lifelong operation: cross-session alignment, map merging, drift management across days with changing illumination/weather, and session-to-session consistency policies are not developed.
- Failure detection and recovery: there is no mechanism to detect catastrophic visual model failures or loop-closure errors (beyond robust kernels), nor strategies for recovery (e.g., relocalization, hypothesis management).
- Sensitivity to hyperparameters: thresholds (e.g., τ for downweighting, σ_d/σ_n for uncertainty, candidate list size) are empirically chosen; their impact on recall/precision, accuracy, and robustness remains unstudied.
- Descriptor upsampling for subpixel matching: bilinear upsampling of descriptors may distort their statistics; the benefit vs. learned super-resolution or correlation refinement is not evaluated.
- Limited exploitation of IMU priors: aside from preintegration, no higher-order IMU models (e.g., bias random walk tuning, temperature compensation, gravity alignment strategies) or adaptive weighting schemes are studied.
- Domain adaptation of the visual model: MASt3R is used off-the-shelf; training or fine-tuning with domain-specific data, multi-sensor conditioning, or uncertainty calibration is not investigated.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed today using the paper’s open-source system and its described workflow.
- Warehouse and factory mobile robots (Robotics, Logistics, Manufacturing)
- What to deploy: Replace or augment existing visual SLAM stacks with MASt3R-Fusion to get metric-scale, low-drift localization in low-texture environments (e.g., polished floors, repetitive shelving).
- Tools/products/workflows: ROS2 node wrapping the real-time sliding-window VIO; GPU-backed feed-forward pointmap regression; offline global optimization pass with loop closures; optional GNSS anchoring for outdoor yards.
- Assumptions/dependencies: Known camera intrinsics and distortion; IMU–camera extrinsic calibration; time synchronization; 8 GB+ GPU for real-time; GNSS may be unavailable indoors (loop closures become critical).
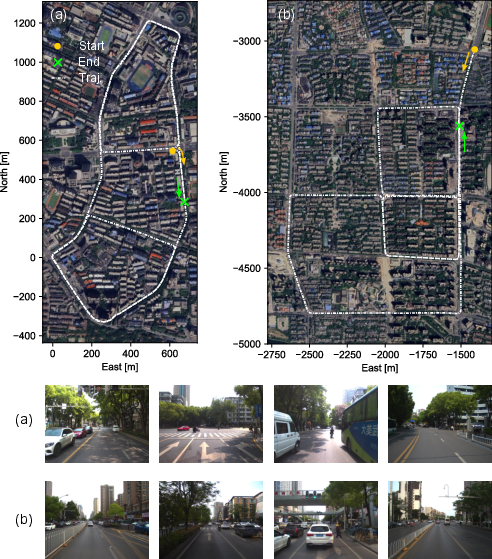
- UAV mapping and inspection (Robotics, Energy/Infrastructure)
- What to deploy: Onboard VIO for drift-minimized flight and post-mission globally consistent mapping of bridges, distribution lines, and plants using GNSS-integrated global optimization.
- Tools/products/workflows: Flight logging of images/IMU/GNSS; run MASt3R-Fusion real-time for pose tracking; post-process logs with hierarchical factor graph and loop closures to produce georeferenced maps.
- Assumptions/dependencies: Accurate IMU, GNSS visibility, sensor time-sync; camera intrinsics; sufficient compute (onboard or ground).
- Post-processing for autonomous driving datasets (Automotive, Software)
- What to deploy: Improve trajectory accuracy and map consistency in recorded runs (dashcam + IMU + GNSS) for HD map creation, relocalization, and annotation pipelines.
- Tools/products/workflows: Batch pipeline that ingests logs, constructs Hessian-form visual constraints, performs loop candidate filtering, then global optimization with GNSS; exports drift-free trajectories and dense scene structure.
- Assumptions/dependencies: High-quality GNSS (preferably RTK in some use cases), camera intrinsics, sensor calibration; not a full real-time driving stack yet.
- Handheld mobile mapping for construction sites and surveying (Surveying/Geodesy, Construction)
- What to deploy: Use a handheld rig (camera + IMU + optional GNSS) to generate metric-scale, globally consistent site maps without extensive control points.
- Tools/products/workflows: Real-time pose tracking for operator feedback; dense pointmap capture; offline loop closure and GNSS fusion for global consistency; output to CAD/BIM/GIS.
- Assumptions/dependencies: Camera calibration; GNSS availability/quality outdoors; site with sufficient visual cues for loop closure; compute resources for global optimization.
- XR/AR prototyping in labs and pilot deployments (XR, Education)
- What to deploy: Replace purely vision-based tracking with multi-sensor fusion to stabilize AR experiences in low-texture rooms and challenging illumination.
- Tools/products/workflows: Integrate MASt3R-Fusion tracking as a service (camera + IMU) in AR prototypes; log-and-optimize workflow across sessions for persistent mapping.
- Assumptions/dependencies: Device IMU access and calibration; camera intrinsics; GPU availability; mobile optimization needed for battery-constrained devices.
- Robotics labs: ground-truth-lite tracking and evaluation (Academia)
- What to deploy: Use the system as a high-accuracy baseline for experiments, ablations, and teaching (factor graphs, Sim(3)→SE(3) transformation, dense constraint design).
- Tools/products/workflows: Reproducible pipelines; datasets instrumented with Hessian-form constraints; teaching modules on hierarchical factor graphs and multi-sensor fusion.
- Assumptions/dependencies: Availability of sensor suites; calibration and synchronization; GPU for dense visual constraints.
- Emergency response scene mapping (Public Safety)
- What to deploy: Rapid indoor/outdoor mapping from helmet/body-worn camera + IMU in GNSS-denied areas, with post-mission globally consistent maps via aggressive loop closures.
- Tools/products/workflows: Lightweight real-time tracking for situational awareness; log-all data; robust loop filtering (uncertainty-aware) to avoid false closures; produce navigable maps for teams.
- Assumptions/dependencies: Challenging lighting and smoke degrade visuals; GNSS-denied; post-mission compute; reliable IMU and time sync.
- Facility digital twin updates (Building Management, Smart Infrastructure)
- What to deploy: Periodic camera+IMU scans to update large facility models (warehouses, hospitals), leveraging dense pointmaps and globally consistent trajectories.
- Tools/products/workflows: Routine capture runs; loop closure across sessions; alignment with existing twins via GNSS/known anchors; integrate with 3D model pipelines.
- Assumptions/dependencies: Visual access; anchors or GNSS outdoors; calibration; compute for global optimization.
- ROS2 module and SDK offering (Software)
- What to deploy: A packaged open-source module exposing the real-time sliding-window VIO and offline global optimizer, with utilities for IMU preintegration, Sim(3)-to-SE(3) isomorphic mapping, and loop candidate filtering.
- Tools/products/workflows: ROS2 nodes; C++/Python APIs; GPU/CPU heterogeneous compute (float32 GPU local, float64 CPU global); integration into existing navigation stacks.
- Assumptions/dependencies: Maintainability of codebase; community uptake; adherence to open-source license; developer familiarity with factor graphs and sensor fusion.
Long-Term Applications
Below are use cases that need further research, scaling, optimization, or productization before wide deployment.
- City-scale, lifelong SLAM for autonomous fleets (Automotive, Smart Cities)
- Vision: Fleet-wide collection of camera/IMU/GNSS data to build and maintain globally consistent, loop-closure-rich maps across seasons and illumination changes.
- Tools/products/workflows: Cloud-based hierarchical factor graphs; multi-session merging; robust outlier handling; standardized loop verification; map serving for relocalization.
- Assumptions/dependencies: Scalable compute; multi-camera and multi-sensor arrays; strong GNSS in urban canyons or alternative anchors; privacy and data governance.
- Smartphone-grade AR core integration (XR, Consumer Electronics)
- Vision: On-device feed-forward pointmap regression + IMU fusion for robust indoor/outdoor tracking on NPUs/GPUs.
- Tools/products/workflows: Model compression, quantization, and hardware acceleration; energy-aware scheduling; cross-session map persistence.
- Assumptions/dependencies: Optimized, lightweight models; device IMU access and calibration; camera distortion handling; standards for privacy and safety.
- Collaborative multi-robot SLAM with shared factor graphs (Robotics)
- Vision: Robots exchange Hessian-form constraints and loop closures to cooperatively build consistent maps in real time.
- Tools/products/workflows: Communication protocols; distributed optimization; conflict resolution in multi-agent loops; GNSS or anchor integration where available.
- Assumptions/dependencies: Time-sync across agents; bandwidth constraints; robust place recognition under viewpoint/appearance changes.
- Safety-certified navigation stacks for regulated environments (Aviation, Automotive, Industrial)
- Vision: Multi-sensor fusion with formal verification and fail-safe mechanisms leveraging Sim(3)→SE(3) transformations and uncertainty-aware loop verification.
- Tools/products/workflows: Certification processes; redundancy (GNSS, wheel odometry, LiDAR); safety monitors and watchdogs; traceable logs and replay.
- Assumptions/dependencies: Regulatory compliance; extensive validation datasets; hardware redundancy; conservative parameterization.
- Precision agriculture and large-area infrastructure asset management (Agriculture, Energy/Utilities)
- Vision: Periodic, georeferenced scans for field mapping, crop monitoring, and asset inspection with drift-free trajectories.
- Tools/products/workflows: GNSS (RTK) integration; robust handling of repetitive textures (rows); domain-adapted feed-forward models for dynamic scenes.
- Assumptions/dependencies: High-precision GNSS; environmental robustness; custom training for vegetation/dynamic conditions.
- Renderable digital twins integrating 3DGS/NeRF (AEC, Media/Entertainment)
- Vision: Fuse metric-scale SLAM outputs with 3D Gaussian Splatting or NeRF to create photorealistic, globally consistent digital twins.
- Tools/products/workflows: Pipelines that transform pointmaps to renderable assets; global alignment with CAD/BIM; session stitching and editing tools.
- Assumptions/dependencies: Stable cross-modal alignment; compute for training/rendering; standardized formats.
- Domain-specific feed-forward models and hardware acceleration (Semiconductor, Edge AI)
- Vision: ASICs or specialized accelerators that execute pointmap regression and dense association in real time with float32/float64 bridging for large-scale precision.
- Tools/products/workflows: Model distillation; mixed-precision strategies; memory-aware scheduling for long sequences; hardware–software co-design.
- Assumptions/dependencies: Vendor ecosystem; sustained model accuracy after compression; compatibility with factor graphs.
- Open standards and policy for multi-sensor SLAM logs and maps (Policy, Standards)
- Vision: Define interoperable formats for VIO/GNSS logs, Hessian-form constraints, and global maps to enable cross-vendor reproducibility and auditability.
- Tools/products/workflows: Working groups; public benchmarks; conformance tests; guidance on GNSS+vision integrity monitoring.
- Assumptions/dependencies: Stakeholder consensus; commitment to open-source; data-sharing agreements.
Assumptions and Dependencies Common Across Applications
- Accurate camera intrinsics and distortion handling are required; paper notes instability without calibration despite the model’s camera-agnostic promise.
- Reliable IMU–camera extrinsic calibration and time synchronization between sensors.
- GPU availability (8 GB suffices for arbitrarily long sequences with the sliding-window design) and CPU for double-precision global optimization.
- GNSS quality and availability determine georeferencing; in GNSS-denied settings, loop closures and the uncertainty-aware filtering become critical.
- Environmental factors: low-texture scenes, dynamic objects, and adverse illumination are addressed by the feed-forward priors but may still require masking, robust kernels, and parameter tuning.
- Integration into existing stacks (ROS2, autopilots) and workflows requires engineering effort, testing, and sometimes regulatory consideration (safety-critical domains).
Glossary
Below is an alphabetical list of advanced domain-specific terms drawn from the paper, each with a short definition and a verbatim usage example from the text.
- 3D Gaussian Splatting (3DGS): A rendering technique that represents scenes using collections of 3D Gaussian primitives for fast, photorealistic visualization. "3D Gaussian Splatting (3DGS)\cite{matsuki_gaussian_2024}."
- Bundle Adjustment (BA): A nonlinear optimization that jointly refines camera poses and 3D point parameters to minimize reprojection error across multiple views. "we revisit the widely used BA technique"
- Cauchy robust kernel: A robust loss function that reduces the influence of outliers during optimization. "a Cauchy robust kernel function is applied to the loop closure constraints"
- Descriptor map: A dense per-pixel feature representation used for fine-grained image matching. "together with two descriptor maps."
- Differentiable Dense Bundle Adjustment (DBA): An end-to-end trainable dense variant of bundle adjustment enabling gradient-based learning. "a differentiable dense bundle adjustment (DBA) module."
- Extrinsic transformation: The rigid-body transform relating different sensor coordinate frames (e.g., camera-to-IMU). "is the IMU-camera extrinsic transformation."
- Factor graph: A graphical model representing variables and constraints as nodes and factors for probabilistic inference and optimization. "A sliding-window factor graph is maintained over a fixed number of keyframes."
- Feed-forward pointmap regression: A neural approach that directly predicts per-pixel 3D points (pointmaps) from images without iterative optimization. "tightly integrates feed-forward pointmap regression with complementary sensor information"
- GNSS (Global Navigation Satellite System): Satellite-based systems (e.g., GPS) providing global position measurements. "global navigation satellite system (GNSS)"
- GNSS lever-arm: The fixed spatial offset between the GNSS antenna phase center and another sensor (e.g., IMU) on the platform. "IMU-GNSS lever-arm"
- Hessian: The second-order derivative (curvature) matrix used in optimization to approximate cost surfaces and accelerate convergence. "the Hessian-form inforamtion "
- Huber robust kernel: A robust loss function that is quadratic for small residuals and linear for large residuals to mitigate outliers. "Huber robust kernel function"
- IMU (Inertial Measurement Unit): A sensor providing accelerations and angular velocities for motion estimation. "inertial measurement units (IMUs)"
- IMU pre-integration: A technique that integrates IMU measurements between keyframes to form motion constraints independent of absolute states. "classic IMU pre-intergration\cite{forster_imu_2015}"
- Isomorphic group transformation: A mapping that expresses Sim(3) transformations equivalently as SE(3) plus a scalar scale to unify optimization. "we introduce the isomorphic group transformation."
- Jacobian: The first-order derivative (sensitivity) matrix relating small changes in parameters to changes in residuals. "the -to- Jacobian."
- Lie algebra: The tangent space at the identity of a Lie group used to parameterize small perturbations of transformations. "where is the Lie algebra"
- Loop closure: The detection and enforcement of revisited locations to correct drift and ensure global consistency. "Loop closure detection is crucial for achieving consistent mapping"
- Marginalization: The process of eliminating variables (e.g., old states) from a factor graph while preserving their effect via summary factors. "Probabilistic marginalization is applied to maximize information utilization"
- Markov process: A stochastic process where the future state depends only on the current state, used here to simplify odometry uncertainty. "we simplify the position estimation as a Markov process"
- Multi-view stereo (MVS): Methods that reconstruct 3D geometry from multiple images by exploiting photometric and geometric consistency. "multi-view stereo (MVS)"
- Navigation frame: A global coordinate system (e.g., ENU) used to express positions and orientations for navigation tasks. "in the navigation frame"
- Odometry: The estimation of relative motion (trajectory) over time, typically from onboard sensors. "visual odometry"
- Permutation equivariance: A neural property where outputs permute correspondingly with input permutations, beneficial for set-structured data. "permutation equivariance\cite{wang_pi_2025}"
- Photometric consistency: The assumption that corresponding pixels across views have similar intensity/color, used for visual alignment. "photometric consistency"
- Pose graph optimization: Global optimization over a graph of pose nodes connected by relative constraints to enforce consistency. "pose graph optimization that loses a large amount of visual/inertial information."
- Pose-only modeling: Optimization approaches that avoid explicit 3D point variables and operate purely on poses. "pose-only modeling\cite{wang_po-kf_2025}"
- Pre-integration term: A temporary constraint formed by integrating IMU data to synchronize measurements at different timestamps. "introduce a temporary pre-integration term"
- Ray proximity: A geometric matching strategy aligning points by comparing their directions (rays) rather than absolute depth. "dense matching based on ray proximity"
- Reprojection error: The difference between observed pixel locations and projections of estimated 3D points, used as a visual residual. "resemble the reprojection error"
- Right-hand perturbations: A convention applying small incremental updates on the right side of group elements during optimization. "we use right-hand perturbations"
- Schur complement: A matrix operation used to eliminate variables (e.g., landmarks) efficiently from large optimization problems. "through Schur complement"
- SE(3): The Lie group of 3D rigid-body transformations (rotation and translation). "metric-scale SE(3) factor graph"
- Sim(3): The Lie group of 3D similarity transformations (rigid motion plus uniform scale). "Sim(3)-based visual alignment constraints"
- SL(4) manifold: The special linear group in 4D used to model projective transformations and address scale/projective ambiguities. "on the SL(4) manifold"
- SLAM: Simultaneous Localization and Mapping—estimating sensor trajectory and environment map from sensor data. "Visual SLAM is a widely utilized technique"
- Sliding-window optimization: A strategy that optimizes a fixed-size recent subset of states to enable real-time performance. "real-time sliding-window optimization"
- SO(3): The Lie group of 3D rotations. ""
- Spatial priors: Learned or assumed structural knowledge about 3D scenes used to improve reconstruction and alignment. "leveraging learned spatial priors"
- Visual alignment constraints: Residuals enforcing consistency between visual observations across frames via geometric alignment. "Sim(3)-based visual alignment constraints"
- Visual-Inertial Odometry (VIO): Fusion of visual and inertial measurements to estimate motion robustly and with metric scale. "Based on the odometry essence of VIO"
Collections
Sign up for free to add this paper to one or more collections.

