- The paper introduces a motion-centric approach that bypasses global pose optimization by directly estimating 6-DoF camera velocity from sparse optical flow and a 3D ray-based model.
- It employs robust estimation using RANSAC and lightweight nonlinear refinement, ensuring real-time performance on low-power platforms.
- Benchmark evaluations on EuRoC, KITTI, and TUM-VI demonstrate comparable accuracy to state-of-the-art systems with processing speeds 6–13× faster.
SMF-VO: Direct Ego-Motion Estimation via Sparse Motion Fields
Introduction and Motivation
The SMF-VO framework introduces a fundamental shift from the prevalent "pose-centric" paradigm in visual odometry (VO) and visual-inertial odometry (VIO) towards a "motion-centric" approach that directly estimates instantaneous 6-DoF camera velocity (linear and angular) from the visual motion field. Traditional VO/VIO systems depend heavily on local mapping, explicit pose estimation (e.g., P3P/PnP), and continuous bundle adjustment of a large number of landmarks, imposing substantial computational costs and memory requirements that impede deployment on resource-constrained platforms.
In contrast, SMF-VO circumvents global pose optimization by leveraging sparse optical flow and the motion field equation to estimate frame-to-frame camera motion. This allows the system to achieve real-time performance on low-power hardware without sacrificing accuracy. Notably, the method generalizes to arbitrary camera models, including wide-FoV and fisheye lenses, through a 3D ray-based formulation—a critical requirement for contemporary robotics and AR/VR applications.
Methodology
SMF-VO capitalizes on the classical relationship between optical flow and camera motion described by the motion field equation. Given a set of correspondences and either known or triangulated depths, each point's observed motion in the image (or as a 3D ray) casts linear constraints on the camera's 6-DoF velocity:
P˙=−v−ω×P
and for its projection p,
u=A(p)ω+B(p)/Zv
A batch of n≥3 correspondences forms an over-constrained linear system. The 3D ray-based reparameterization further extends this model to arbitrary camera intrinsics and distortion models. The solution is obtained via ordinary linear least squares, eliminating the overhead of P3P/PnP or RANSAC-backed non-linear solvers (although RANSAC is used for outlier filtering).
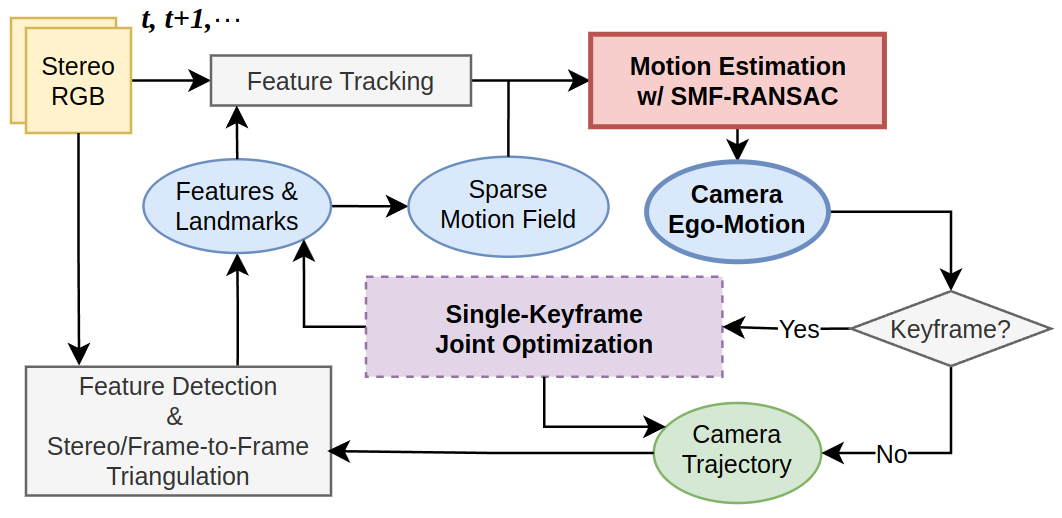
Figure 1: Overview of the SMF-VO pipeline illustrating sparse feature tracking, motion field estimation, RANSAC for robust fitting, and optional nonlinear bundle adjustment.
Robust Estimation and Outlier Handling
Feature points are tracked via classical methods such as KLT/Lucas-Kanade between consecutive frames. RANSAC robustifies the motion estimation by sampling minimal subsets, estimating motion, and selecting the solution with the largest inlier set according to both geometric error and ray angular consistency. Post-processing includes a lightweight on-demand nonlinear refinement (when a keyframe is created) by optimizing only the latest keyframe pose and its associated map points, keeping overall complexity independent of trajectory length.
Ray-Based Generalization
The core innovation is a 3D ray-based motion field equation, formulated as:
r˙=[r]×ω+(rr⊤−I)v/d
where r is a normalized 3D bearing vector, and d is the Euclidean point depth. This representation is agnostic to projection model, mitigating the reduced reliability of 2D-pixel-based constraints at image peripheries and allowing accurate velocity inference with fisheye or non-pinhole cameras.
Optional Local Nonlinear Optimization
Upon keyframe creation, a compact joint optimization (robust bundle adjustment) further refines the frame-to-landmark geometry over only the current keyframe and its observed features. The cost function directly minimizes angular reprojection error between observed and predicted rays, robustified by a Cauchy loss to mitigate outliers.
Empirical Evaluation
Accuracy and Efficiency
SMF-VO was evaluated on EuRoC, KITTI, and TUM-VI datasets, targeting both small-scale (indoors, aerial robotics) and large-scale (autonomous driving) domains, as well as wide-FoV/fisheye scenarios. All experiments executed on a Raspberry Pi 5 (2.4 GHz quad-core ARM CPU) without hardware acceleration.
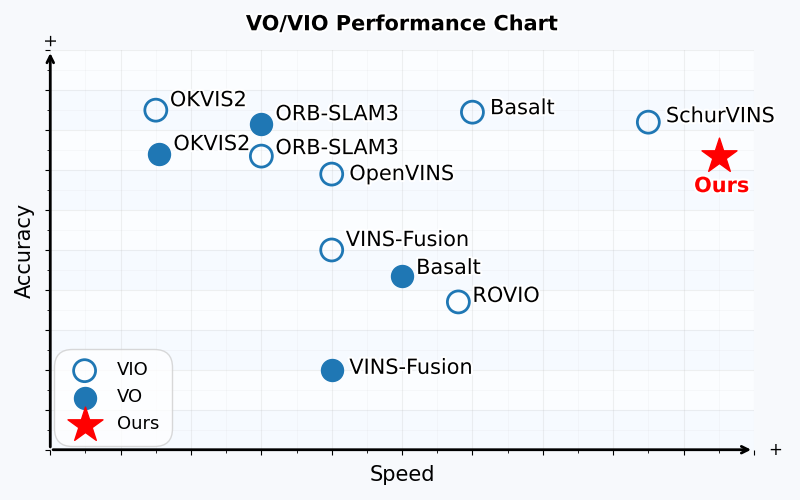
Figure 2: SMF-VO attains higher speed than conventional VO/VIO methods while maintaining comparable accuracy across benchmarks.
EuRoC
- Achieves average RMSE ATE (Absolute Trajectory Error) within ≈ 0.1 meters, ranking just behind ORB-SLAM3 and OKVIS2 in accuracy.
- Outperforms all baselines in computational speed: <10 ms/frame (>100 FPS), roughly 6–13× faster than state-of-the-art systems.
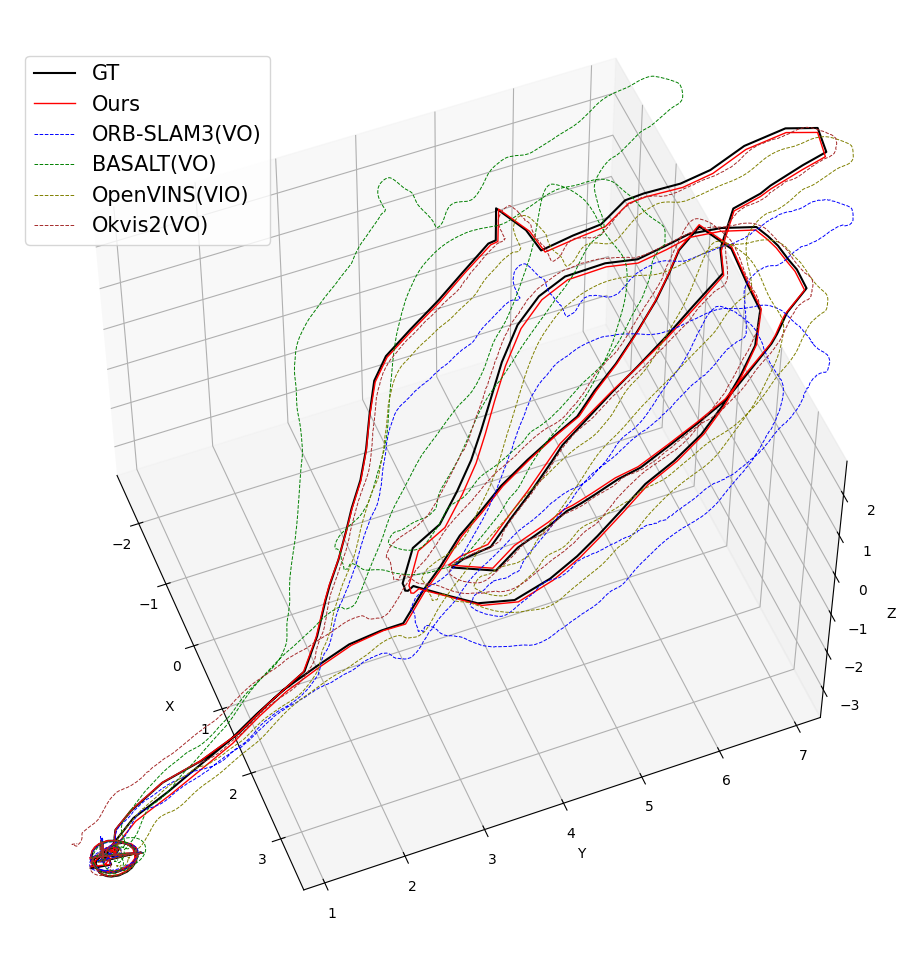
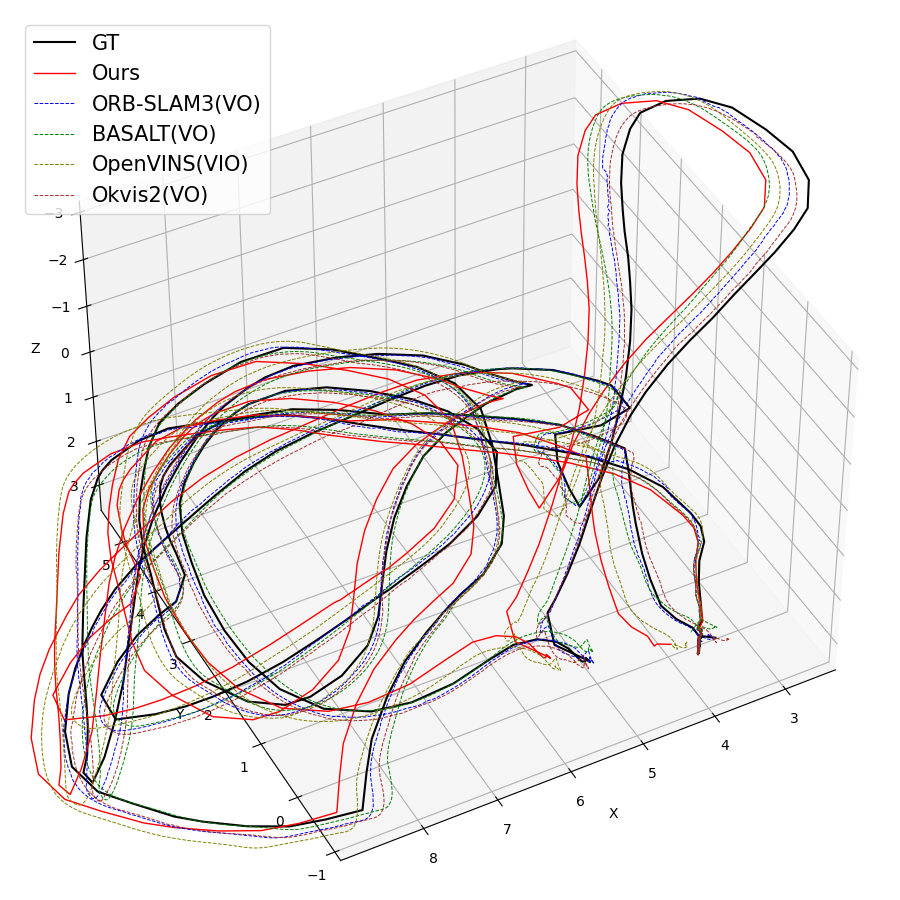
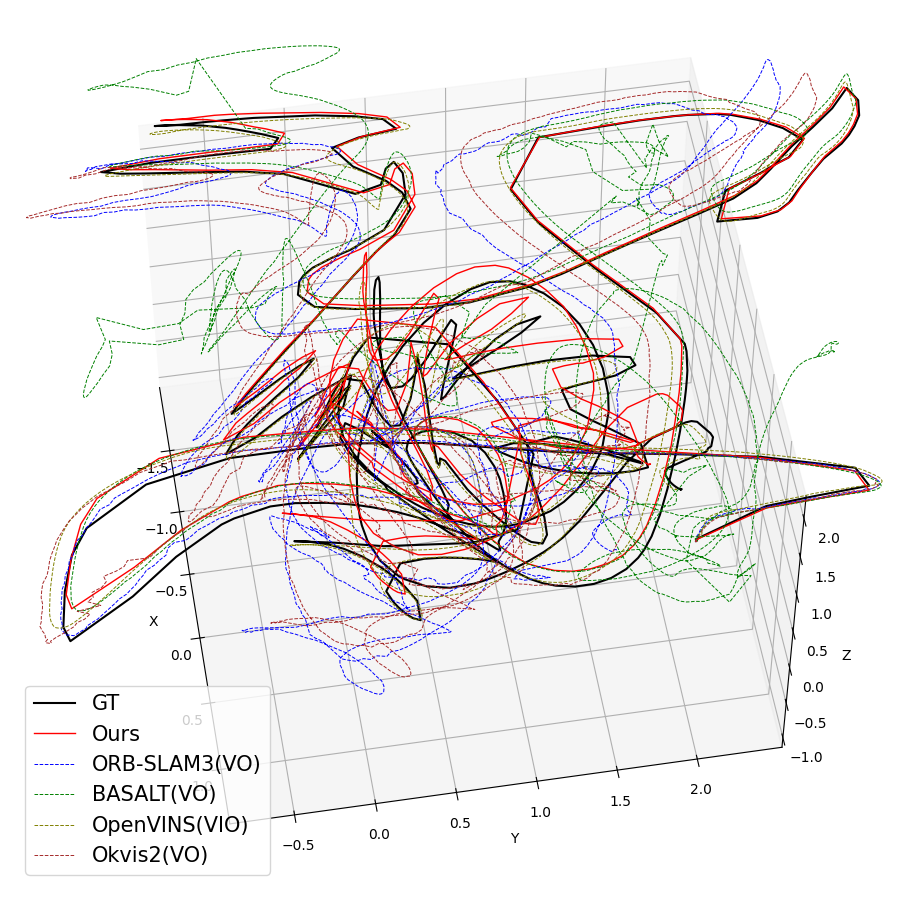
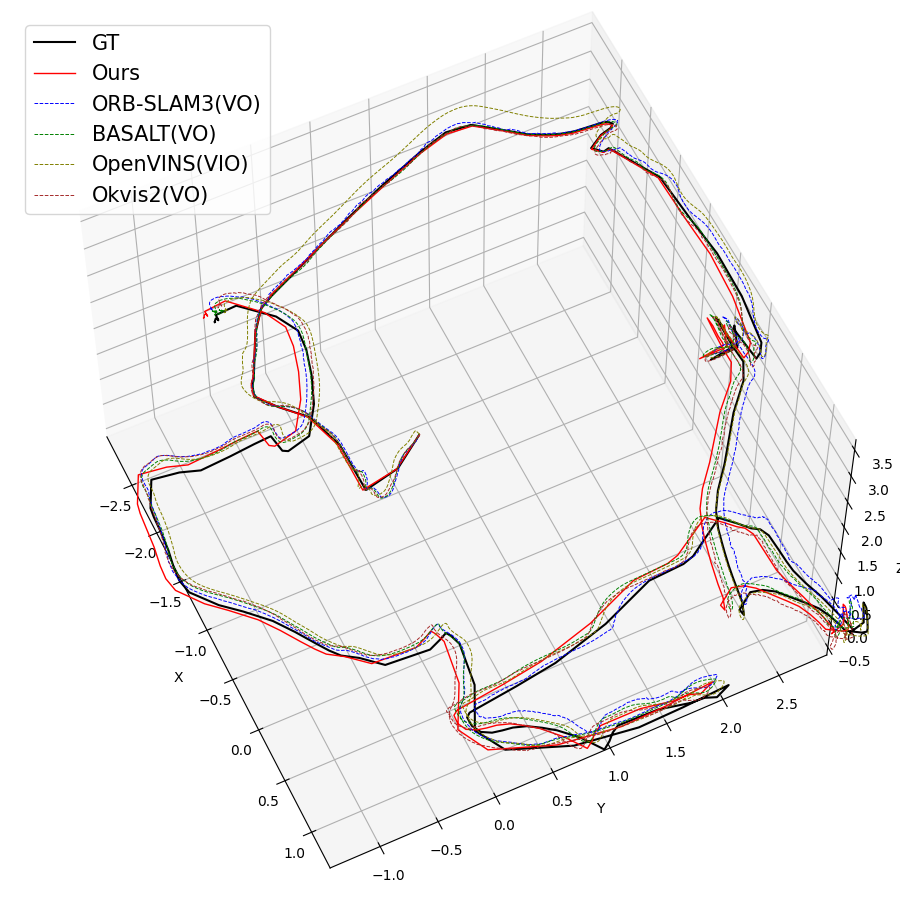
Figure 3: Qualitative trajectory estimates for various EuRoC sequences, showing SMF-VO matches or surpasses established methods.
KITTI
- Comparable accuracy to ORB-SLAM3 and BASALT, especially considering KITTI's higher resolution and outdoor environments.
- Maintains <20 ms/frame performance, unmatched by direct and graph-based optimization methods.
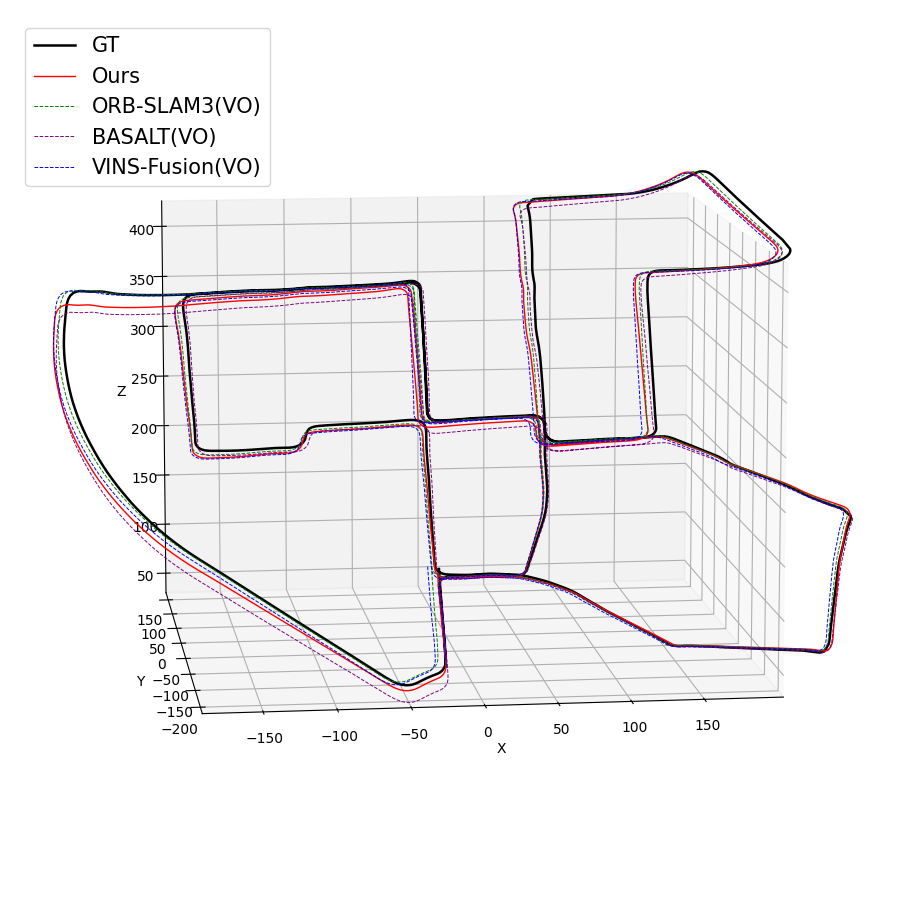

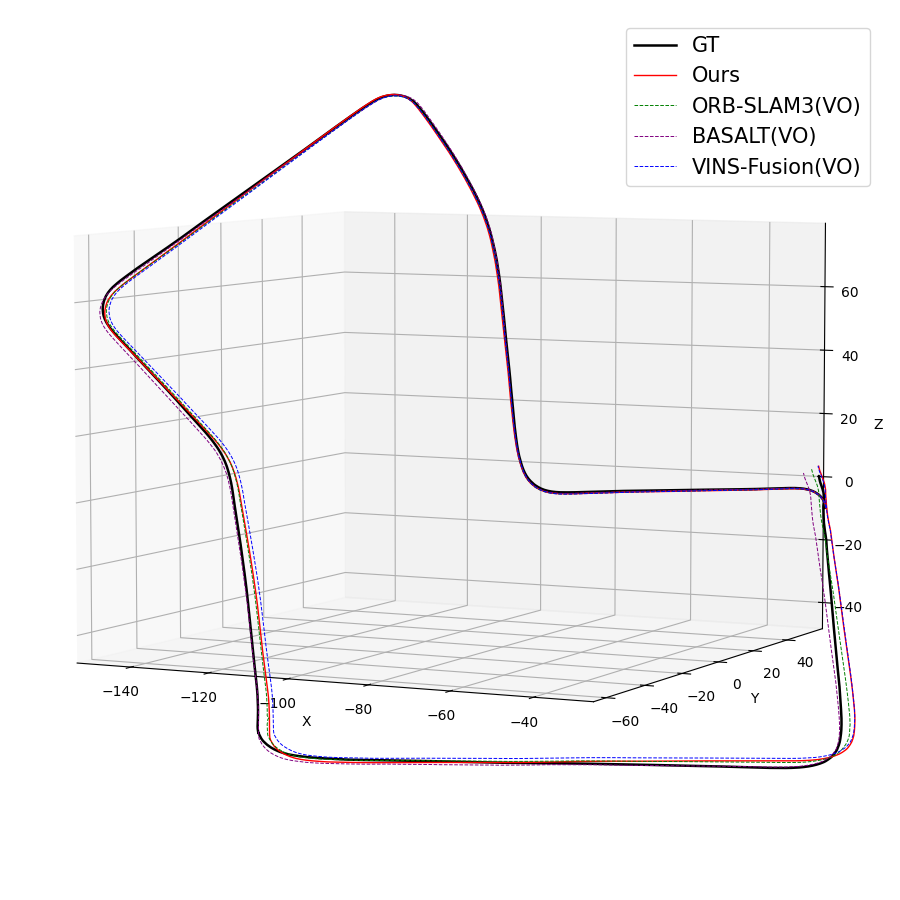
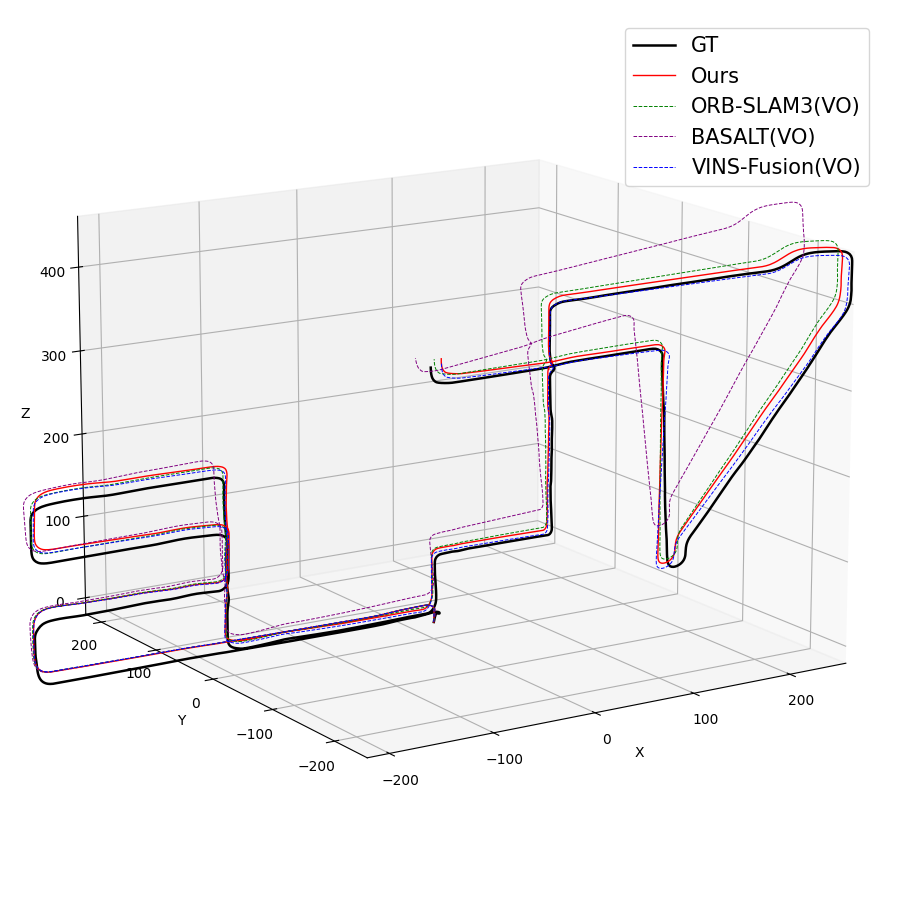
Figure 4: KITTI trajectories indicate robust tracking and low drift over long and dynamic outdoor drives.
TUM-VI Room
- Second-best VO accuracy with ∼0.08m average RMSE, slightly trailing ORB-SLAM3.
- Maintains ∼8× faster runtime than ORB-SLAM3 and ∼1.5× faster than BASALT, proving scalability to wide-FoV/fisheye data and challenging indoor motions.
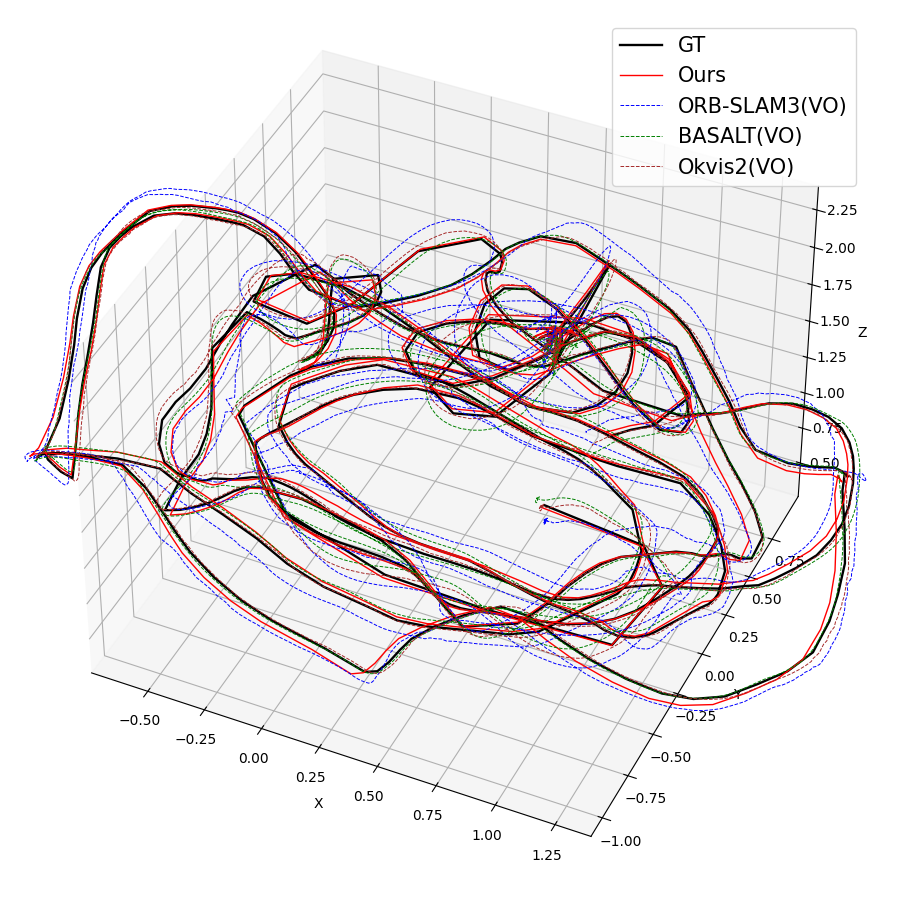
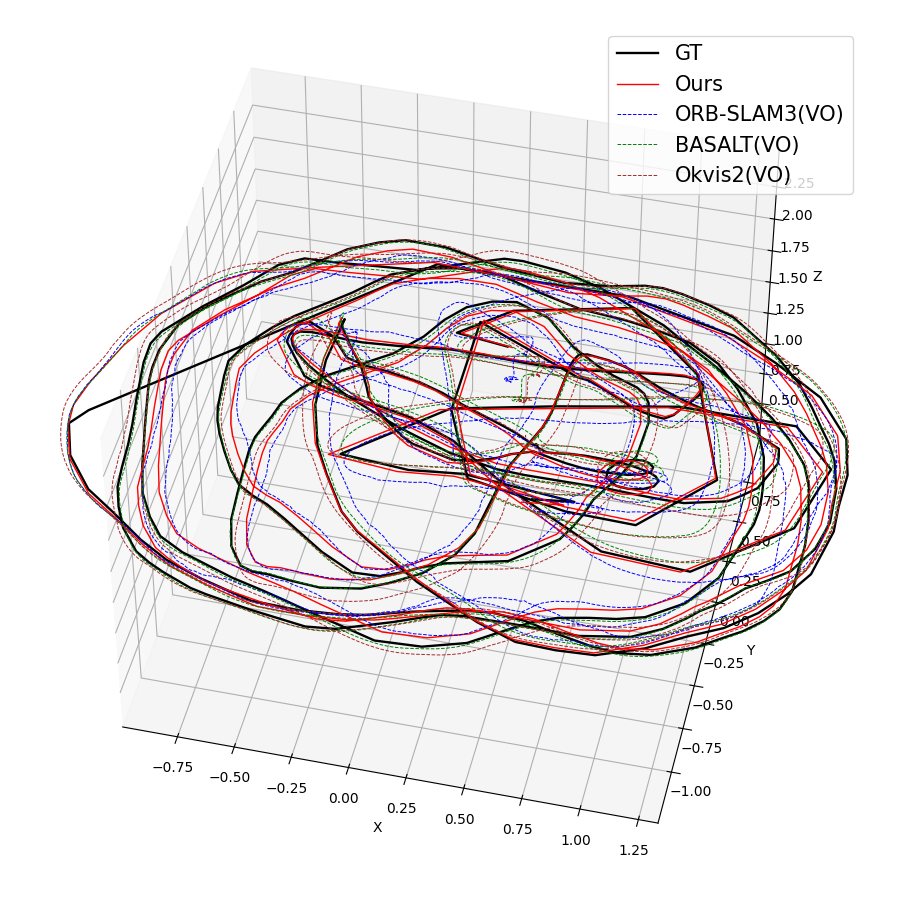
Figure 5: Trajectory estimation matches reference systems even with wide-FoV TUM-VI data.
Ablation and Robustness
Peer ablation indicates:
- The 3D ray-based formulation is consistently more robust and accurate than the pixel-based analog, especially for wide-field and non-pinhole data. The performance advantage grows in the absence of local optimization.
- Lightweight, bundle-adjustment-style optimization can be selectively applied to tackle accumulated drift without significant runtime penalty.
Implications and Future Directions
Theoretical Impact
SMF-VO formalizes a motion-field-centric state estimation paradigm, rigorously demonstrating that ego-motion can be reliably reconstructed by aggregating per-frame sparse 2D or ray velocities and optional lightweight optimization. This stands in contrast to the dominant pose-centric canon, which presumes the necessity of iterative pose reoptimization, global mapping, and large SLAM graphs even for short-term odometry.
Practical Significance
- Resource-Awareness: With consistent >100 FPS on modest embedded CPUs, the approach solves real-time visual odometry for hardware-limited robotic platforms, AR glasses, and wearables.
- Flexibility: Camera model independence ensures compatibility with the growing diversity of imaging hardware in robotics, especially for omnidirectional and wide-angle applications.
- Reduced SWaP (size, weight, power): Bypassing global mapping substantially reduces memory and thermal requirements.
- Deployment Simplicity: Only standard RGB inputs and sparse keypoint tracking are required. No IMU or external calibration is needed to achieve low drift except in highly degenerate cases.
Limitations and Prospects
- As the method does not maintain a persistent scene map, it is susceptible to long-term drift and may not support robust relocalization or loop closure without additional mapping modules.
- Scale recovery depends on depth estimates, requiring stereo or sufficient parallax for robustness.
- Theoretical connections to event-camera, direct methods, or self-supervised learning frameworks suggest straightforward extension into event-based robotics and spatiotemporal sensor fusion.
Ongoing and future work should:
- Integrate IMU/event data for degenerate or visually ambiguous motions.
- Explore robust integration strategies for loop closure without substantial computational overhead.
- Investigate end-to-end learned sparse correspondence pipelines compatible with SMF-VO’s motion-centric solvers.
Conclusion
SMF-VO advocates and realizes a new operational paradigm—direct motion-centric ego-motion estimation from sparse optical flow using a 3D ray-based motion field model. The resulting system achieves high accuracy and unprecedented computational efficiency, as evidenced by extensive benchmarking on standard datasets and embedded hardware. The generalization to arbitrary camera models and the ability to scale down to microcontrollers offer broad-reaching utility in robotics, AR/VR, and vision-enabled devices, setting a new standard for practical, real-time, map-free visual odometry.

