- The paper presents TraceRL, which optimizes RL training by aligning post-training objectives with inference trajectories using a diffusion-based value model.
- The framework achieves significant performance gains on mathematical and coding benchmarks, outperforming leading autoregressive models.
- TraceRL supports both full-attention and block-attention architectures, reducing computational cost while enabling efficient parallel decoding.
TraceRL: A Trajectory-Aware Reinforcement Learning Framework for Diffusion LLMs
Introduction and Motivation
The paper introduces TraceRL, a trajectory-aware reinforcement learning (RL) framework designed for diffusion LLMs (DLMs), addressing the critical mismatch between post-training objectives and inference trajectories in existing DLM RL methods. DLMs, particularly those employing masked diffusion and block attention, have demonstrated significant advantages in parallel decoding and bidirectional context modeling, but their RL post-training has lagged behind autoregressive (AR) models in both theoretical alignment and empirical performance. TraceRL directly optimizes the preferred inference trajectory, leveraging a diffusion-based value model to enhance training stability and variance reduction. The framework is applicable to both full-attention and block-attention DLM architectures, enabling efficient scaling and superior reasoning performance.
Theoretical Foundations and Objective Alignment
The core insight motivating TraceRL is the observation that standard random masking objectives used in DLM post-training do not align with the sequential, context-dependent nature of language inference. In block diffusion models, semi-autoregressive fine-tuning partially addresses this by conditioning on earlier context, but full-attention DLMs suffer from increased computational cost when adopting similar objectives. The paper demonstrates, via controlled experiments, that aligning the post-training objective with the model's preferred inference trace yields optimal performance, even under equal or lower computational budgets.
TraceRL formalizes RL training over the actual inference trajectory, decomposing the generation process into a sequence of trace steps. For each rollout, the framework aggregates every s neighboring steps (shrinkage parameter) to reduce computational complexity, and applies policy optimization using PPO-style clipped objectives. The diffusion-based value model provides token-wise, prefix-conditioned advantages, enabling stable and efficient credit assignment throughout the trajectory.
Implementation Details and Algorithmic Pipeline
The TraceRL algorithm proceeds as follows:
- Rollout Generation: For each task, the policy model generates a response, recording the trajectory of decoded tokens at each step.
- Trajectory Shrinkage: Steps are aggregated via the shrinkage parameter s to balance granularity and efficiency.
- Reward Assignment: Verifiable rewards (e.g., task correctness, unit test pass rate) are assigned to the final step, with process-level rewards optionally distributed across the trajectory.
- Value Model Inference: A frozen diffusion-based value network estimates token-wise values, serving as a baseline for advantage calculation.
- Policy and Value Updates: The policy is updated via PPO-style objectives using normalized advantages, while the value network is updated via clipped regression losses.
The framework supports both full-attention and block-attention architectures, with block diffusion models benefiting from highly parallelized training via block-wise slicing.
Empirical Results and Benchmarking
TraceRL is evaluated on a suite of complex reasoning tasks, including mathematics (MATH500, GSM8K, AIME2024) and coding (LiveCodeBench-V2, LiveBench). The TraDo series of DLMs, trained solely with TraceRL, consistently outperform strong AR baselines such as Qwen2.5-7B-Instruct and Llama3.1-8B-Instruct, despite being smaller in scale. Notably, TraDo-8B-Instruct achieves a 6.1% relative accuracy improvement over Qwen2.5-7B-Instruct and 51.3% over Llama3.1-8B-Instruct on mathematical reasoning benchmarks.
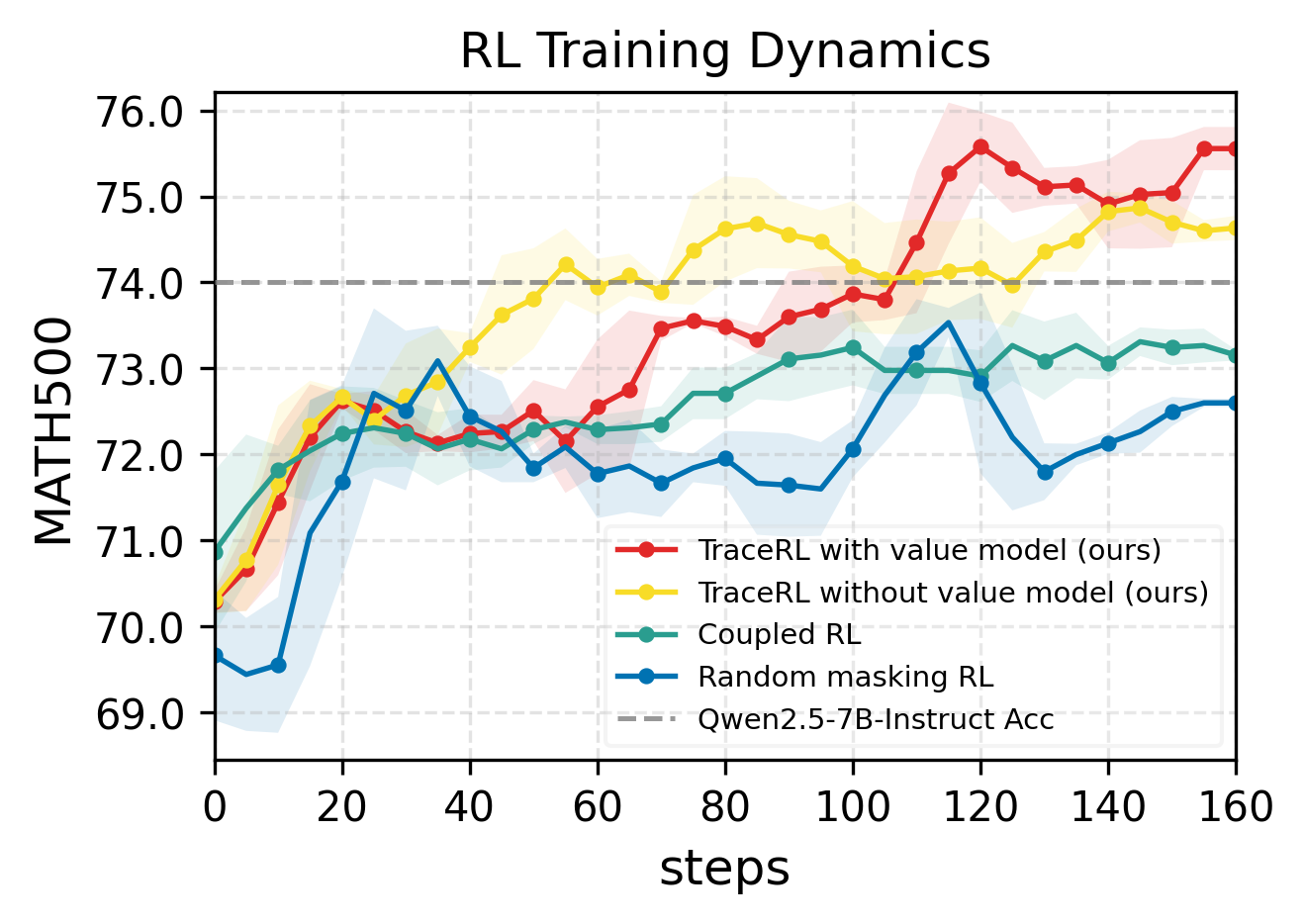
Figure 1: RL training dynamics and benchmark results, demonstrating TraceRL's superior optimization and the TraDo models' strong performance across math and coding tasks.
The framework also enables the first long-CoT DLM, TraDo-8B-Thinking, which achieves an 18.1% relative accuracy gain on MATH500 compared to Qwen2.5-7B-Instruct, and demonstrates robust performance on extended reasoning tasks with significantly longer response lengths.
Ablation Studies and Training Stability
Ablation experiments confirm the efficacy of TraceRL over existing RL methods, both with and without the diffusion-based value model. Incorporating the value model leads to reduced training variance and more stable optimization, as evidenced by smoother learning curves and fewer fluctuations.
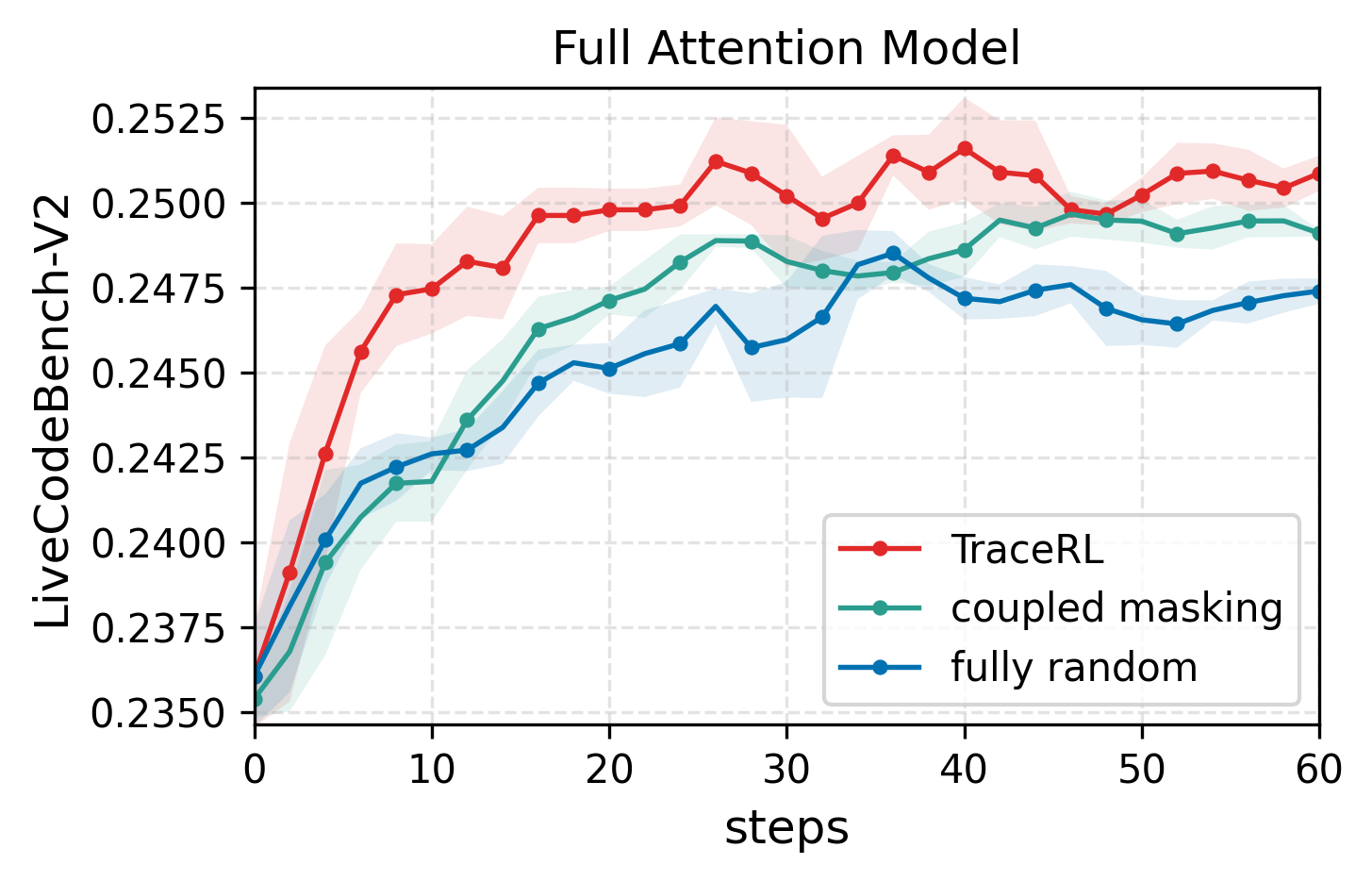
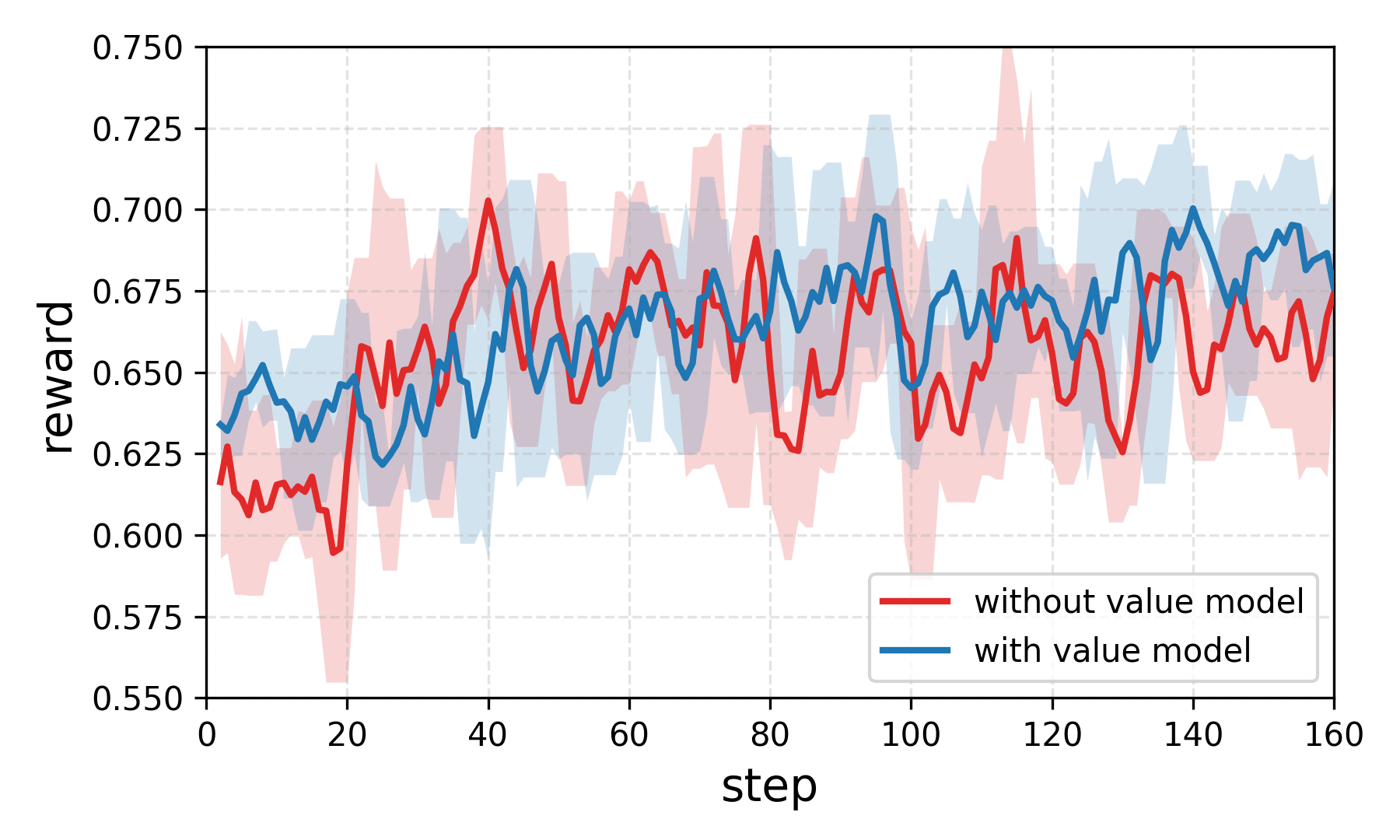
Figure 2: (a) RL training ablations for Dream-7B-Coder-Instruct on coding tasks. (b) Value model incorporation reduces training fluctuations in the 4B math model.
TraceRL also facilitates block size scaling in block diffusion models, enabling larger block sizes without sacrificing performance or sampling flexibility. This is critical for inference acceleration, as larger blocks allow for more parallel token generation.
Practical Implications and Open-Source Framework
The paper releases a comprehensive open-source framework for building, training, and deploying DLMs, supporting diverse architectures and integrating accelerated KV-cache techniques for both inference and RL sampling. The framework includes implementations of various supervised fine-tuning and RL methods, facilitating reproducible research and practical deployment in mathematics, coding, and general reasoning tasks.
Theoretical and Practical Implications
TraceRL's trajectory-aware optimization addresses a fundamental limitation in DLM RL training, providing a principled approach to credit assignment and objective alignment. The diffusion-based value model extends variance reduction techniques to the discrete diffusion setting, enabling stable scaling to larger models and longer reasoning chains. The empirical results challenge the prevailing assumption that AR models are inherently superior for complex reasoning, demonstrating that DLMs, when properly optimized, can match or exceed AR performance with significant inference acceleration.
Future Directions
Potential avenues for future research include:
- Process-Level Rewards: Extending the value model to incorporate richer process-level rewards, enabling finer-grained supervision and improved reasoning fidelity.
- Scaling to Larger Architectures: Applying TraceRL to even larger DLMs and more diverse tasks, exploring the limits of parallel decoding and bidirectional context modeling.
- Integration with Long-CoT and Self-Improvement: Combining TraceRL with advanced reasoning templates and self-improvement algorithms to further enhance reasoning capabilities and sample efficiency.
- Efficient RL Credit Assignment: Investigating alternative advantage estimation and credit assignment strategies tailored to the unique properties of diffusion-based generation.
Conclusion
TraceRL establishes a robust, scalable RL framework for diffusion LLMs, aligning training objectives with inference trajectories and enabling state-of-the-art performance on complex reasoning tasks. The integration of a diffusion-based value model and support for diverse architectures positions TraceRL as a foundational method for future DLM research and deployment. The open-source framework further accelerates progress in this domain, providing the community with practical tools for advancing both theoretical understanding and real-world applications.