- The paper introduces Inpainting-Guided Policy Optimization (IGPO), which injects partial ground-truth reasoning hints into masked diffusion LLMs to overcome sparse reward challenges.
- It employs a training pipeline that combines length-aligned supervised fine-tuning with entropy-based gradient filtering to stabilize reinforcement learning.
- Empirical results on GSM8K, Math500, and AMC benchmarks show significant performance gains and faster convergence compared to standard approaches.
Inpainting-Guided Policy Optimization for Diffusion LLMs
Overview and Motivation
This work introduces Inpainting-Guided Policy Optimization (IGPO), a reinforcement learning (RL) framework specifically designed for masked diffusion LLMs (dLLMs). Unlike autoregressive LLMs, dLLMs generate text by iteratively unmasking tokens in parallel, enabling unique capabilities such as inpainting—where future reasoning hints can be injected during generation via bidirectional attention. The paper leverages this architectural property to address a fundamental challenge in RL for LLMs: exploration inefficiency due to sparse rewards and frequent sample waste when models fail to discover correct solutions, especially in complex reasoning tasks.
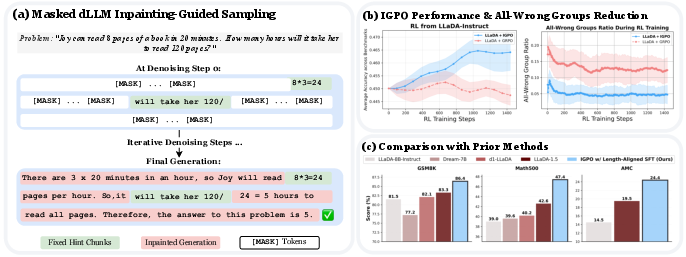
Figure 1: (a) dLLMs can be conditioned on future reasoning hints via inpainting, enabling guided exploration. (b) IGPO outperforms standard GRPO sampling and reduces all-wrong group occurrences. (c) The full training recipe achieves SoTA performance among full-attention masked dLLMs across three mathematical benchmarks.
Masked Diffusion LLMs and RL Challenges
Masked dLLMs employ a forward diffusion process that corrupts token sequences by introducing mask tokens, with a monotonic noise schedule. Generation proceeds by denoising masked positions, leveraging bidirectional attention. This contrasts with autoregressive models, which decode left-to-right and cannot condition on future tokens.
Policy optimization for dLLMs is complicated by the lack of sequential factorization, making tokenwise probability estimation intractable. The paper adopts mean-field approximations for efficient single-pass estimation of token-level and sequence-level terms, following prior work (DiffuGRPO). Group-based RL methods such as Group-relative Policy Optimization (GRPO) are particularly vulnerable to exploration failures: when all sampled responses in a group are incorrect, the advantage signal collapses to zero, resulting in degenerate gradients and wasted compute.
IGPO: Algorithmic Design
IGPO addresses the zero-advantage dilemma by strategically injecting partial ground-truth reasoning traces as hints during online sampling. When all sampled responses for a prompt are incorrect, IGPO segments the ground-truth trace into variable-length chunks and injects a random subset as fixed hints. The dLLM then inpaints the remaining masked positions, generating completions conditioned on both the prompt and injected hints. Only correct inpainted completions are used to replace a fraction of the original incorrect responses, restoring reward variance and enabling non-zero advantages for effective policy gradient updates.
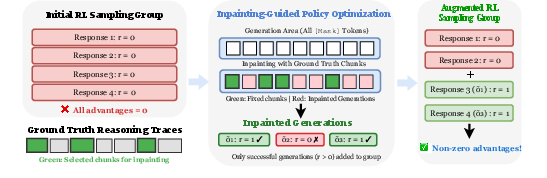
Figure 2: Overview of IGPO: when all sampled responses are incorrect, hint-guided inpainting generates additional responses using ground-truth reasoning chunks as injected hints, enabling reward variance for policy optimization.
The IGPO objective modifies GRPO by incorporating the augmented sampling procedure, ensuring that only verified correct inpainted responses are included in the RL group. Entropy-based gradient filtering is applied to hint token positions: updates are restricted to the top-τ percentile of highest-entropy positions, mitigating instability from off-policy learning.
Length-Aligned Supervised Fine-Tuning
A critical component of the training recipe is Length-Aligned SFT, which rewrites verbose reasoning traces into concise, structured versions using LLaMA-4-Maverick. This aligns SFT data length with RL sampling and evaluation, addressing the computational constraints of full-attention dLLMs and eliminating distribution mismatch. Empirical results demonstrate that SFT on rewritten traces provides stronger initialization for RL, yielding higher final performance.
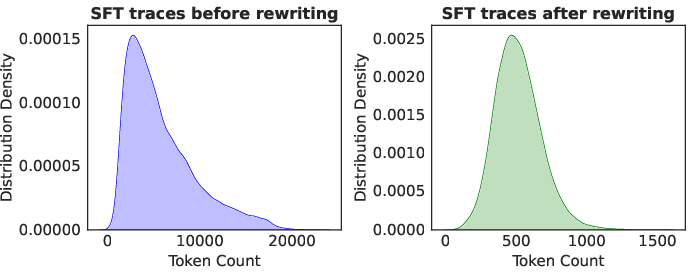
Figure 3: Token length distribution before and after revision; rewritten traces are constrained to below 1500 tokens, eliminating extreme outliers and aligning SFT, RL, and evaluation lengths.
Empirical Results
The proposed training pipeline—Length-Aligned SFT followed by RL with IGPO—achieves substantial improvements on GSM8K, Math500, and AMC benchmarks. Notably, the cumulative gains are +4.9% on GSM8K, +8.4% on Math500, and +9.9% on AMC relative to the LLaDA-Instruct baseline. IGPO consistently reduces the all-wrong group ratio by approximately 60%, restoring non-degenerate gradients and accelerating convergence.
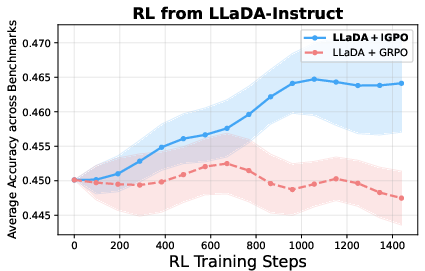
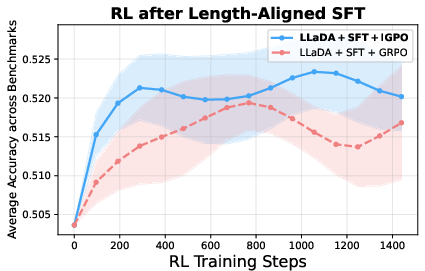
Figure 4: RL training curves of IGPO versus normal GRPO sampling; IGPO exhibits superior and more stable training performance under both initialization checkpoints.
Ablation and Analysis
Partial hint injection outperforms full hint injection, as self-generated inpainted traces provide a more effective learning signal by bridging on-policy generation with ground-truth guidance. Entropy clipping further stabilizes training: restricting updates to high-entropy hint positions yields the best performance and prevents instability from large off-policy gradients.
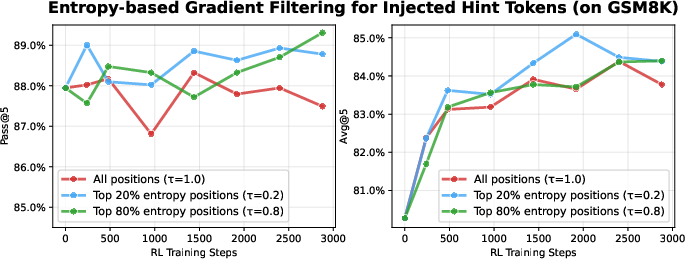
Figure 5: Impact of entropy clipping threshold on hint tokens; learning from only the top 20% highest-entropy positions achieves optimal stability and performance.
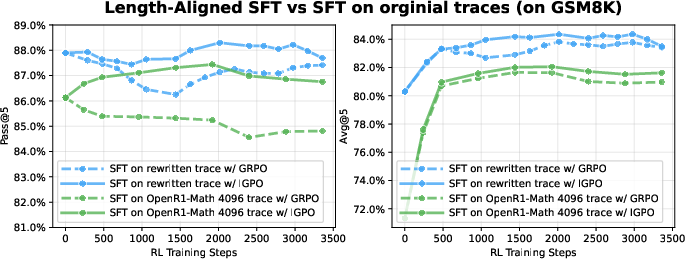
Figure 6: SFT and RL training dynamics with rewritten versus original traces; rewritten traces yield higher SFT performance and superior final RL accuracy, with IGPO consistently outperforming standard RL.
Practical and Theoretical Implications
IGPO demonstrates that architectural properties of dLLMs—specifically, inpainting via bidirectional attention—can be systematically exploited to overcome critical RL optimization challenges. The methodology bridges supervised and reinforcement learning paradigms, maintaining on-policy generation for non-injected tokens and reducing distributional mismatch. The entropy-based filtering mechanism provides a principled approach to stabilizing off-policy learning in RL for dLLMs.
Practically, the approach establishes a new state-of-the-art for full-attention masked dLLMs on mathematical reasoning tasks, with strong numerical results and robust training dynamics. The framework is extensible to other RL algorithms and can be adapted for multimodal or code generation tasks, given the flexibility of dLLMs.
Theoretically, the work suggests that guided exploration via inpainting can interpolate between imitation and RL, offering a general recipe for leveraging model-specific inductive biases in policy optimization. The success of length-aligned SFT further highlights the importance of data distribution alignment across training phases.
Future Directions
Potential future developments include extending IGPO to block-based or cached diffusion architectures for improved inference efficiency, integrating more sophisticated hint selection strategies, and exploring applications in domains beyond mathematical reasoning, such as code synthesis or multimodal generation. Further research may investigate the interplay between inpainting-guided exploration and other RL stabilization techniques, as well as scaling laws for dLLMs under guided RL.
Conclusion
Inpainting-Guided Policy Optimization (IGPO) leverages the unique inpainting capabilities of masked diffusion LLMs to address exploration inefficiency in RL. By injecting partial reasoning hints and applying entropy-based gradient filtering, IGPO restores reward variance, stabilizes training, and achieves state-of-the-art performance on mathematical reasoning benchmarks. The methodology demonstrates how architectural properties can be harnessed for effective policy optimization, providing a robust framework for RL in diffusion-based LLMs and suggesting promising directions for future research in scalable, guided exploration.