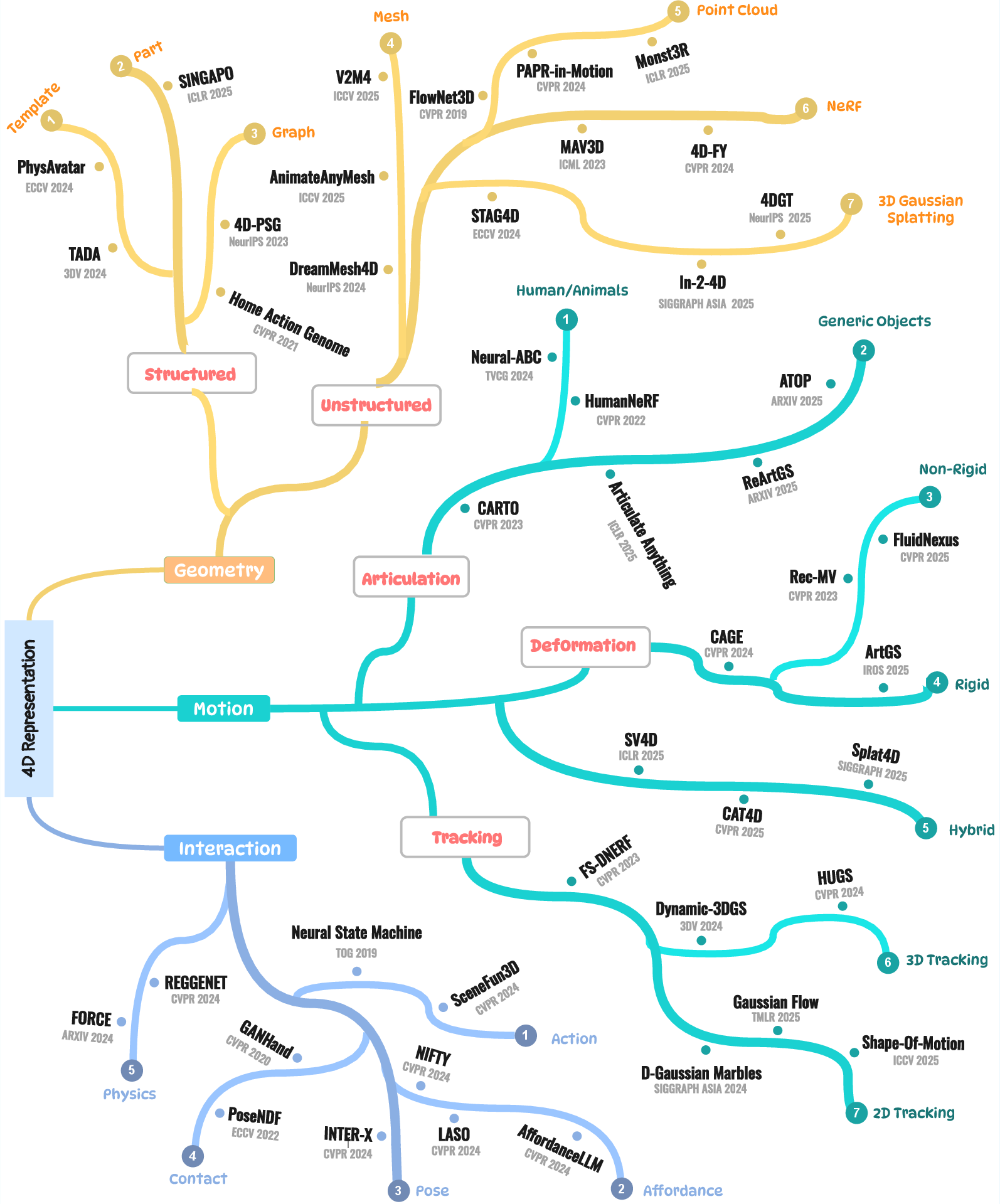
Advances in 4D Representation: Geometry, Motion, and Interaction
Abstract: We present a survey on 4D generation and reconstruction, a fast-evolving subfield of computer graphics whose developments have been propelled by recent advances in neural fields, geometric and motion deep learning, as well 3D generative artificial intelligence (GenAI). While our survey is not the first of its kind, we build our coverage of the domain from a unique and distinctive perspective of 4D representations\/}, to model 3D geometry evolving over time while exhibiting motion and interaction. Specifically, instead of offering an exhaustive enumeration of many works, we take a more selective approach by focusing on representative works to highlight both the desirable properties and ensuing challenges of each representation under different computation, application, and data scenarios. The main take-away message we aim to convey to the readers is on how to select and then customize the appropriate 4D representations for their tasks. Organizationally, we separate the 4D representations based on three key pillars: geometry, motion, and interaction. Our discourse will not only encompass the most popular representations of today, such as neural radiance fields (NeRFs) and 3D Gaussian Splatting (3DGS), but also bring attention to relatively under-explored representations in the 4D context, such as structured models and long-range motions. Throughout our survey, we will reprise the role of LLMs and video foundational models (VFMs) in a variety of 4D applications, while steering our discussion towards their current limitations and how they can be addressed. We also provide a dedicated coverage on what 4D datasets are currently available, as well as what is lacking, in driving the subfield forward. Project page:https://mingrui-zhao.github.io/4DRep-GMI/


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper is a survey — like a well-organized guide — about “4D representation.” 4D here means 3D things that change over time. Think of a 3D movie scene: shapes, people, and objects moving, bending, and interacting across seconds. The authors explain the main ways researchers represent, learn, and generate this kind of moving 3D world, and they give practical advice on when to use which method.
They group the topic into three pillars:
- Geometry: how you store the shape and look of things
- Motion: how things move or deform over time
- Interaction: how multiple things (like a person and an object) touch, affect, or use each other
The key questions the paper answers
- What are the main ways to represent 3D things that change over time (4D)?
- What are the strengths and weaknesses of each kind of representation?
- Which representation should you pick for a specific task (like animation, editing, robotics, or VR)?
- How do different types of motion (like joints vs. squishy deformations) affect your choice?
- How do we represent interactions (like a hand grasping a cup) in a way machines can learn from?
- What datasets and AI tools are available today, and what’s still missing?
How the authors approached the topic
Instead of listing every paper, the authors take a “representation-first” approach: they pick clear, strong examples and explain what each representation is good or bad at. They also connect these choices to real needs: computing speed, available data (few or many cameras), desired output (realistic video vs. editable 3D assets), and so on.
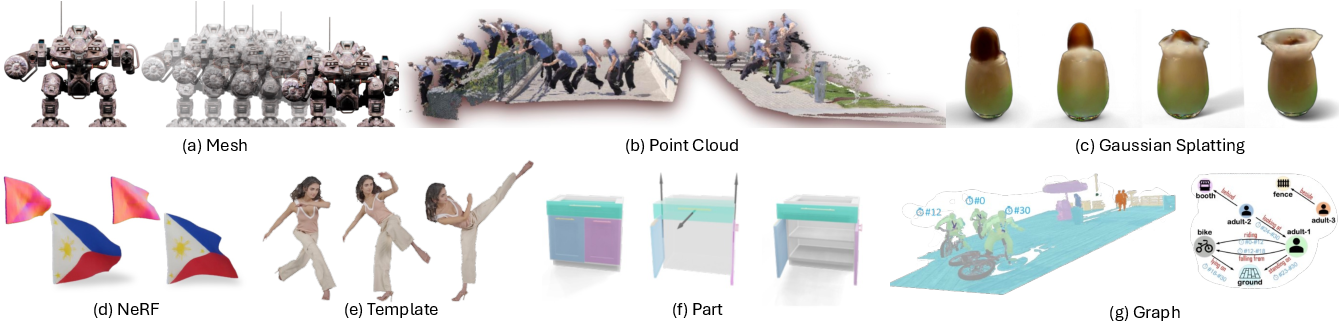
To make this concrete, they explain two big families of geometry representations with everyday analogies:
- Unstructured (no built-in “parts” or “rules”):
- Meshes: like a wireframe net that covers the surface of an object
- Point clouds: lots of tiny dots floating in 3D that sample the shape
- NeRFs: a learned function that tells you the color and “thickness” along a ray, great for realistic views
- 3D Gaussian Splatting: thousands of soft “paint blobs” in 3D rendered very fast
- Structured (built-in parts and relationships):
- Templates with skeletons: like a puppet rig (e.g., human body with joints) that drives a mesh
- Part-based models: like LEGO-like components (doors, handles, wheels) with known motions
- Spatio-temporal scene graphs: a graph that tracks objects and their relationships over time
They also break down motion into simple types:
- Articulated motion: rigid pieces connected by joints, like elbows or hinges
- Deformation-based motion: bendy, stretchy stuff, like cloth or faces
- Tracking-based motion: following where things go frame-to-frame
- Hybrid motion: mixes of the above
Finally, they cover interaction: how to represent actions, contact, affordances (what you can do with an object), and physics in a way AI can use.
Main findings and why they matter
Here are the main takeaways, explained in simple terms.
- There’s no one “best” 4D representation — pick the right tool for the job.
- Want realistic video from images? NeRFs and Gaussian Splatting are great at view synthesis.
- Want editable, animatable assets (like for games/movies)? Meshes and structured rigs are easier to control.
- Want to learn from real-world sensors (like self-driving cars)? Point clouds are natural and scalable.
- Unstructured vs. structured is a big choice:
- Unstructured methods (like NeRFs or Gaussian blobs) look great and handle messy shapes (smoke, hair), but can be harder to edit, animate, or enforce physics on.
- Structured methods (like skeletons and parts) are easier to control, transfer motion across objects, and ensure realistic behavior — but they need more assumptions and category-specific knowledge.
- Motion modeling changes everything:
- Articulated motion (like joints) is well-handled by rigs and skinning (think puppets).
- Non-rigid motion (cloth, soft tissue) needs deformation fields or physics priors.
- Big, fast motions and topological changes (things splitting/merging) are still hard for many methods.
- Temporal consistency (no flicker) is a core challenge:
- When learning from videos, models often produce flicker or “wobble” over time.
- Methods add special tricks: smoothness losses, deformation fields, optical flow guidance, or tracking to keep the motion stable.
- Data matters:
- Many methods assume lots of synchronized multi-view videos — which are expensive to capture.
- New research tries to work with sparse inputs (like a single video) using flow, depth, or help from generative models (e.g., video diffusion) to fill in missing views.
- Physics and interaction are rising in importance:
- To make believable animations and useful robotics, models need to understand contact, collisions, and materials.
- People are combining learned models with physics engines or “differentiable physics” to get realistic behavior.
- Big AI models help, but aren’t magic:
- LLMs and video foundation models can guide tasks like part discovery (“that’s a drawer; it slides”), but they still struggle with precise geometry and long, complex motions.
- Better datasets and benchmarks are needed to push this further.
What methods look like under the hood (in everyday language)
- Mesh animation: keep one consistent wireframe and move its vertices over time. This is clean for texturing and editing, but changing topology (splitting/merging) is tough.
- Point clouds: great for sensor data; easy to record, hard to render photo-realistically without gaps. New tricks blend colors/features to smooth visuals.
- NeRFs: imagine asking a neural “oracle” what color/density is at any point and direction, then integrating along a camera ray. Stunning images, slower to train; can flicker when extended over time.
- Gaussian Splatting: fill space with thousands of soft blobs, then splat them into the image super fast. Excellent for real-time rendering; motion must carefully deform blobs to stay coherent.
- Skeleton templates (e.g., SMPL): use a puppet rig; each vertex follows joints based on learned weights. Fast and controllable. Add-ons model clothes, hair, and soft tissue for realism.
- Part-based: break objects into meaningful parts (door, handle, shelf), learn how each moves, and reconstruct the whole. Great for manipulation and robotics.
- Scene graphs: represent who’s where, who’s doing what, and how relationships evolve over time; powerful for reasoning, harder to match the photo-real detail of pixel-based methods.
Why this matters
- Movies and games: better tools to create lively 3D scenes that are both realistic and easy to edit.
- VR/AR: more believable, interactive worlds where objects behave with proper physics.
- Robotics: understanding parts, joints, and interactions lets robots open doors, use tools, and move safely around people.
- E-commerce and education: interactive 3D products and scientific visualizations that move correctly over time.
- Research: a shared “map” of representations helps teams pick smart solutions and build on each other’s work.
Implications and future impact
- Expect hybrid systems: photo-real unstructured models (for visuals) combined with structured layers (for control, editing, and physics).
- Better handling of “long-range” motions: more stable methods that don’t flicker, even with big movements or few camera views.
- Stronger physics and interaction: models that understand contact, materials, and cause-and-effect will power safer robots and more convincing animation.
- Smarter part discovery: AI that automatically finds parts and their functions will unlock wider categories beyond humans and furniture.
- Richer datasets and benchmarks: to fairly compare methods and push toward real-world deployment.
- LLMs and video foundation models as “coaches”: guiding structure and semantics, while geometry-focused models handle precision and realism.
In short, the paper is a practical guide to the fast-moving world of 4D. It explains what tools we have to represent moving 3D scenes, when to use each tool, and how to combine them to make believable, controllable, and useful digital worlds.
Knowledge Gaps
Below is a single, concise list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each point is framed to be actionable for future research.
- Decision frameworks for representation selection: No principled, task-driven methodology exists to map application constraints (e.g., editability, physics, real-time) to optimal 4D representations and training regimes.
- Cross-representation benchmarking: Lack of standardized, multi-factor benchmarks comparing meshes, point clouds, NeRFs, 3DGS, templates, parts, and scene graphs across geometry fidelity, temporal coherence, editability, interaction modeling, physical plausibility, and compute.
- Sparse-input dynamic reconstruction: Robust learning from monocular or few-view videos remains underdeveloped across all representations, with weak guarantees on temporal consistency and motion realism.
- Long-range, large-displacement motion: Representations and training strategies that handle minutes-long sequences with large motions, occlusions, re-appearances, and topological events are missing.
- Cross-representation conversion with temporal guarantees: Methods to convert point cloud ↔ mesh ↔ NeRF/3DGS while preserving temporal alignment, identity, materials, and physical constraints are lacking.
- Mesh topology evolution: Mechanisms for splitting/merging surfaces and handling topological changes in 4D while maintaining per-vertex correspondence and textures are still open.
- Scene-level mesh dynamics: Generating and tracking multiple interacting meshes with varying scales, constraints, collisions, and independent deformations—beyond object-centric pipelines—remains unresolved.
- Dynamic point cloud generation: Systematic approaches for synthesizing high-quality 4D point clouds with view-consistent appearance, dense coverage, and editable motion are scarce.
- Physics in point clouds: Enforcing collisions, contacts, conservation laws, and material properties within point-based pipelines is largely unexplored.
- Void-free appearance from points: General solutions for continuous, artifact-free rendering from sparsely sampled dynamic point clouds (beyond point-associated feature interpolation) are incomplete.
- NeRF temporal stability: Architectures and training objectives with provable or measurable reductions in flicker and deformation artifacts, especially under sparse views, are missing.
- Real-time dynamic NeRF: Alternatives to ray marching and fast inference/editing mechanisms for dynamic scenes have not reached robust, real-time performance across diverse content.
- Gaussian splatting under large motion: Adaptive covariance learning, reorientation stability, and consistent deformation of Gaussians for high-speed or complex motions need principled solutions.
- Time-consistent mesh extraction from 3DGS: Reliable, temporally coherent surface reconstruction with materials and semantic labels from dynamic Gaussians is an open challenge.
- Native space-time 4DGS design: Unified formulations that natively encode space-time variation with appropriate regularization and efficiency, plus rigorous comparative studies, are missing.
- Generalizable template discovery: Methods to infer skeletal structures, skinning weights, and category-specific shape spaces from sparse examples or unlabeled data across diverse object classes are needed.
- Physics-integrated templates: Combining learned skinning with differentiable simulation to capture soft tissues, cloth, hair, contact, and collision in a unified, efficient pipeline remains underdeveloped.
- Cross-category motion transfer: Transferring articulated motion between disparate topologies and categories (e.g., human ↔ animal ↔ robot) with minimal supervision is not solved.
- Functional part decomposition at scale: Automatic, semantically meaningful segmentation and completion of functional parts with strong zero-shot generalization and large-scale datasets is missing.
- Articulation inference from partial observations: Robust recovery of joint types, axes, limits, kinematic loops, and multi-DoF joints under occlusion and sparsity needs better models and uncertainty handling.
- Scalable 4D scene graphs: Learning with 4D nodes (trajectories/events), spatio-temporal edges (causal, co-visibility, time-scoped properties), and efficient algorithms/datasets for large scenes is immature.
- Multi-layer models (graphs + geometry): Practical APIs, training strategies, and tools to connect 4D scene graphs as an abstraction layer over unstructured geometry for joint reasoning and editing are lacking.
- Hybrid motion models: Seamless integration of articulation, deformation, and tracking (with conflict resolution and uncertainty propagation) across representations remains an open problem.
- Deformation fields with topology changes: Learning invertible/bijective mappings that gracefully handle birth/death, merging/splitting, and severe occlusions while keeping correspondence is unresolved.
- Ambiguity and uncertainty in correspondence: Probabilistic deformation fields, confidence-aware tracking, and principled uncertainty modeling under low-texture and occlusion are underexplored.
- Guidance under sparse views: The impact and mitigation of artifacts from auxiliary priors (optical flow, depth, generative guidance) in NeRF/3DGS training lacks quantification and robust methodologies.
- Evaluation metrics for 4D: Standardized metrics that capture temporal coherence, interaction fidelity (contacts/affordances), physical plausibility, and editability/control are missing.
- 4D datasets with interactions and physics: Scarcity of large-scale, multi-view, long-duration datasets with ground truth for contact, forces, material properties, and causal events hampers progress.
- LLM/VFM grounding for 4D: Reliable, controllable mapping from text/video prompts to actionable 4D geometry/motion/interaction, with safety constraints and error diagnosis, remains open.
- Intuitive high-level editing: Unified, cross-representation controls (text/audio/gesture) for motion, deformation, and interaction that yield predictable edits are underdeveloped.
- Scalability and compute for long sequences: Memory-efficient training/inference (streaming, online learning, compression) across minutes-long dynamics with consistent quality is an open challenge.
- Real-time with physics: Achieving real-time 4D pipelines that combine differentiable rendering, physical priors, and interaction (closed-loop robotics/AR/VR) is not yet broadly demonstrated.
- Uncertainty-aware pipelines: End-to-end modeling and propagation of uncertainty across time, representations, and modules to support robust decision-making is missing.
Practical Applications
Immediate Applications
Below are actionable, deployable-now use cases mapped to sectors, with suggested tools/workflows and key dependencies that affect feasibility.
- Media, Entertainment, and Games
- Animated asset creation from text or video using mesh-based 4D generation
- What: Turn a single video or prompt into a temporally consistent animated mesh for VFX, trailers, and indie games.
- Tools/workflows: DCC plugin that runs a “reconstruct-and-refine” pipeline (video-to-mesh per frame + deformation-based registration); 4D inbetweening to reduce hand-keyframing.
- Dependencies/assumptions: Clean footage or high-quality prompts; camera calibration or robust self-calibration; GPU availability; tolerance for limited topology change (meshes).
- Real‑time dynamic scene rendering with 3D Gaussian Splatting (3DGS)
- What: Previz and interactive look-dev with real-time playback of captured dynamic scenes.
- Tools/workflows: 3DGS renderer integrated into Unreal/Unity for dynamic shot review; monocular-to-4DGS capture for on-set visualization.
- Dependencies/assumptions: Adequate video coverage or robust sparse-view methods; temporal coherence regularization; tile-based rasterization hardware.
- AR/VR and Telepresence
- Live or offline avatarization using template-based models (e.g., SMPL-family)
- What: Drive personalized avatars from monocular video for telepresence, training, or fitness apps.
- Tools/workflows: Pose tracking + neural skinning fields for clothing/hair; temporal smoothing to remove jitter; lightweight streaming rig.
- Dependencies/assumptions: Good body visibility; temporal priors to suppress jitter; optional physics priors for apparel plausibility.
- Dynamic environment capture for AR occlusion and placement
- What: Room‑scale 4D reconstructions to support occlusion-aware AR and motion-aware anchoring.
- Tools/workflows: Video-to-dynamic point maps with DUST3R/VGGT-style feed-forward models; point-to-mesh/GS conversion for rendering.
- Dependencies/assumptions: Calibrated or self-calibrated camera tracks; controlled lighting; mobile-capable inference or cloud offload.
- Robotics and Embodied AI
- Articulated object understanding for manipulation
- What: From a few images or a short video, infer part segmentation and joint parameters to auto-generate URDFs for doors, drawers, tools.
- Tools/workflows: Part-based decomposition with LLM-guided semantics; joint type/axis/state regression; kinematic tree inference; policy training in sim.
- Dependencies/assumptions: Adequate views of moving parts; ground/foundation models that generalize beyond furniture; grasping hardware limits.
- Spatio-temporal scene graphs for task planning
- What: Convert egocentric video into event-centric 4D scene graphs for planning (“open fridge,” “place bottle”).
- Tools/workflows: Detection/tracking + temporal relation extraction; graph neural networks for planning; integration with manipulation stacks.
- Dependencies/assumptions: Accurate 2D/3D tracking; domain schemas for actions/affordances; latency constraints for closed-loop use.
- Autonomous Driving and Mapping
- Dynamic point cloud understanding for perception stacks
- What: Deploy scene flow, tracking, and forecasting with LiDAR-native models for robust motion understanding.
- Tools/workflows: FlowNet3D/PointPWC-style modules; tracking-by-attention for dynamic point maps; forecasting bridges to planning.
- Dependencies/assumptions: Quality LiDAR or stereo/RGB-D; synchronization; well-curated ground truth; robustness to weather/lighting.
- Monocular video to dynamic point maps for localization and simulation
- What: Convert dashcam feeds into dynamic point maps to augment HD maps and generate realistic “replay” simulations.
- Tools/workflows: Feed-forward pointmap inference + temporal tracking; export to 3DGS/mesh for rendering in simulators.
- Dependencies/assumptions: Camera calibration; scale recovery; motion blur mitigation; privacy filtering.
- E‑Commerce and Retail
- Interactive 4D product visualization and try-on
- What: Show products with moving parts (furniture, appliances) and personalized try-on on user avatars.
- Tools/workflows: Part-based articulation for product demos; template-based avatars with garment layers; web viewer using 3DGS or mesh.
- Dependencies/assumptions: Product CAD or good multi-view media; skinning weights for garments; browser GPU support.
- Healthcare and Biomechanics
- Gait and posture analysis from monocular video
- What: Extract SMPL-like pose/shape sequences for rehab tracking or ergonomics.
- Tools/workflows: Temporal pose estimators with smoothness priors; export to analytics dashboards.
- Dependencies/assumptions: Clinical tolerance for accuracy; controlled capture; privacy compliance.
- Activity monitoring in eldercare using 4D scene graphs
- What: Detect and summarize activities (fall events, prolonged inactivity) as spatio-temporal relations.
- Tools/workflows: Multi-camera tracking; scene graph construction; rule-based or learned event detectors.
- Dependencies/assumptions: Consent and data governance; robust detection under occlusions; alarm fatigue management.
- Software and Developer Tools
- Interchange and conversion pipelines across 4D reps
- What: Libraries to convert between point clouds, meshes, NeRFs, and 3DGS with temporal coherence.
- Tools/workflows: Bidirectional converters (pointmap↔mesh, NeRF↔GS); validators for flicker/consistency; dataset packagers.
- Dependencies/assumptions: Reliable surface extraction from GS/NeRF; metadata standards (camera, timing).
- Academia and Benchmarking
- 4D dataset curation and consistent evaluation
- What: Adopt common metrics and protocols for temporal coherence, tracking, and motion quality across representations.
- Tools/workflows: Open benchmarks with per-rep metrics; scripts for optical flow/geometry consistency; leaderboards per motion type.
- Dependencies/assumptions: Licensing; annotation budgets; cross-rep comparability.
- Policy and Compliance
- Immediate data governance practices for 4D capture
- What: Privacy-preserving pipelines (blurring, on-device processing) and consent protocols for dynamic capture.
- Tools/workflows: Automatic PII redaction in videos/point clouds; retention controls; dataset documentation templates.
- Dependencies/assumptions: Jurisdictional rules (GDPR/CCPA); stakeholder buy-in; audit tooling.
Long‑Term Applications
These require further research, scaling, or engineering before broad deployment.
- Universal 4D editing and reasoning platform
- What: A single workspace to edit geometry, motion, and interactions across meshes, point clouds, NeRFs, and 3DGS, with seamless conversion and temporal guarantees.
- Potential products: Cross-representation 4D editor with “edit in one, propagate to all” and explainable motion graphs.
- Dependencies/assumptions: Robust, loss-minimizing converters; common scene graph schema; standardized temporal metadata; efficient differentiable renderers.
- Physics‑grounded, interactive digital humans
- What: Avatars with soft‑tissue, garments, hair, and contact-aware interactions that can be controlled by text/video/VR.
- Potential products: Fitness and telepresence avatars with realistic dynamics; virtual fitting rooms with drape and collision realism.
- Dependencies/assumptions: Scalable neural‑physics hybrids; fast cloth/hair solvers on edge devices; validated material models.
- Generalizable template learning and auto‑rigging from sparse data
- What: Learn category‑agnostic templates (skeletons, skinning) from few examples; “Rig Anything” tools for rapid content creation and robotics.
- Potential products: One‑click rigging assistants for DCC and robotics (URDF/SDFormat export).
- Dependencies/assumptions: Large, diverse 4D corpora; reliable part discovery; LLM/VFM grounding for function.
- Household and industrial robots manipulating unseen articulated objects
- What: Robust perception + kinematics inference + policy learning that generalizes to novel appliances and tools.
- Potential products: On‑device articulation discovery; task planners over 4D scene graphs with causal reasoning.
- Dependencies/assumptions: Sim‑to‑real transfer from 4DGS/NeRF‑based simulators; safe exploration; tactile integration.
- City‑scale dynamic digital twins
- What: Continually updated 4D reconstructions of urban spaces for traffic optimization, construction monitoring, and public safety.
- Potential products: Operations dashboards; “what‑if” simulations; policy impact analysis.
- Dependencies/assumptions: Multi‑source ingestion (CCTV, drones, vehicles); privacy-by-design; scalable storage/compute; standardized 4D scene graphs.
- Multimodal 4D reasoning via LLMs and Video Foundation Models (VFMs)
- What: Causal and temporal reasoning on 4D scene graphs for narrative understanding, compliance checks, or robotics instruction.
- Potential products: Timeline QA, anomaly detection, automatic procedure verification.
- Dependencies/assumptions: Reliable grounding of language to 4D entities/relations; long‑context memory; safety guardrails.
- On‑device, real‑time 4D capture for mobile and wearables
- What: Capture dynamic scenes with phones/glasses and stream compact 4D representations for AR and communication.
- Potential products: Live 4D calling; persistent AR anchors tied to dynamic environments.
- Dependencies/assumptions: Efficient, low‑power 4DGS/pointmap inference; hardware acceleration; bandwidth‑aware codecs.
- Interoperability standards and compliance for 4D content
- What: Open standards for 4D assets (geometry + motion + interaction), rights management, and provenance.
- Potential products: 4D asset manifests; licensing frameworks; conformance suites.
- Dependencies/assumptions: Cross‑industry consortium; legal harmonization; support in major DCC/game engines.
- Physics‑aware differentiable simulators coupled with neural 4D rendering
- What: Unified training environments where policies learn from realistic visuals and physically plausible dynamics.
- Potential products: Training-as-a-service for manipulation/driving; content engines for science/education.
- Dependencies/assumptions: Stable differentiable physics at scale; co‑simulation with rendering; reproducible benchmarks.
- Healthcare: non‑invasive 4D monitoring and analysis
- What: From external video to internal state estimation (e.g., respiratory motion, joint load) and rehab digital twins.
- Potential products: Home rehab trackers with outcome predictions; clinician tools for progress visualization.
- Dependencies/assumptions: Clinically validated accuracy; bias assessment; regulatory approvals (FDA/CE).
- Energy, Construction, and Infrastructure
- What: 4D progress tracking and hazard prediction from sparse site videos; planning via event‑level 4D graphs.
- Potential products: Automated progress pay apps; safety early‑warning systems.
- Dependencies/assumptions: Robust outdoor capture; integration with BIM/digital twins; legal frameworks for monitoring.
Notes on cross‑cutting assumptions
- Data: Quality and diversity of 4D datasets (views, motions, interactions) heavily impact generalization across sectors.
- Compute: Many methods require GPUs and benefit from hardware-accelerated rasterization or ray marching; on‑device scenarios need model compression.
- Calibration: Camera/lidar calibration and synchronization remain critical for accuracy, especially under sparse views.
- Safety and ethics: Privacy, consent, and bias mitigation are necessary for public deployment (healthcare, cities, retail).
- Standards: Interchange formats for geometry, motion, and spatio‑temporal relations are foundational for ecosystem tooling and reproducibility.
Glossary
- 3D Gaussian Splatting (3DGS): An explicit point-based rendering approach that models scenes with 3D anisotropic Gaussian primitives and rasterizes them efficiently. "neural radiance fields (NeRFs) and 3D Gaussian Splatting (3DGS)"
- 4D inbetweening: The synthesis of intermediate 4D frames to smoothly interpolate motion over time. "4D inbetweening"
- 4DGS: A space-time extension of Gaussian Splatting that encodes dynamic variations directly within the Gaussian representation. "native 4DGS"
- Articulated motion: Motion composed of rigid parts connected by joints, producing globally non-rigid behavior. "articulated motion"
- Auto-decoder: A training paradigm where each timestamp or instance has a learnable embedding optimized in tandem with the network. "auto-decoder manner"
- Backward deformation: Mapping observed points back to a canonical space to query static attributes for rendering or analysis. "backward deformation"
- Canonical space: A static reference configuration to which dynamic frames are related via learned deformations. "static canonical space"
- CCD (Continuous Collision Detection): A physics technique that detects collisions across time to prevent interpenetrations during motion. "CCD"
- Continuum mechanics: A physics framework for modeling materials and deformations as continuous media. "embed continuum mechanics"
- Covariance matrix: A 3D matrix describing the spatial spread and orientation of a Gaussian primitive. "Each Gaussian is defined by its 3D covariance matrix"
- Deformation field: A learned function describing how points move from canonical to observed space (or vice versa) over time. "continuous deformation field"
- Deformation-guided representation: A paradigm that factorizes dynamics into a canonical space and time-varying deformation fields. "Deformation-guided Representation"
- Differentiable physics: Physics models integrated into learning pipelines with gradients enabling end-to-end optimization. "differentiable physics"
- Differentiable rendering: Rendering formulations that support gradient computation for learning scene representations. "real-time differentiable rendering"
- Elastodynamics: The study and simulation of time-dependent elastic deformations in materials. "interactive elastodynamics"
- Elastic priors: Regularization terms that bias learned deformations toward physically plausible elastic behavior. "elastic priors"
- Forward warping: Mapping points from canonical space to observed space for explicit representations during animation. "forward warping"
- Gaussian primitives: Discrete 3D Gaussian entities used to represent and render scenes. "Gaussian primitives"
- Hash encodings: Learned mappings that provide adaptive-resolution features via hashing for efficient neural scene representations. "learned hash encodings"
- Hash grids: Spatial feature grids indexed via hashing to accelerate neural field training and inference. "hash grids"
- Hex-planes: Planar feature decompositions used to store spatial-temporal information for faster NeRF training. "Hex-planes"
- Invertibility: A property of deformation mappings ensuring consistent forward and backward transformations. "Invertibility ensures bidirectional consistency"
- K-planes: A set of learned planes storing features that are interpolated to condition compact neural decoders. "K-planes"
- Kinematic chains: Hierarchical joint-link structures defining how transformations propagate in articulated models. "kinematic chains"
- Kinematic loops: Cyclic constraints in kinematic structures that allow for mechanisms with looped linkages. "kinematic loops"
- Kinematic tree: A hierarchical representation of articulated objects where joints govern part transformations. "kinematic trees"
- Linear blend skinning (LBS): A standard mesh deformation technique that blends joint transformations using per-vertex weights. "linear blend skinning (LBS)"
- MANO: A parametric template model for 3D hand shape and pose with articulated joints. "MANO~\cite{MANO:SIGGRAPHASIA:2017}"
- Material Point Method (MPM): A particle-grid hybrid simulation method well-suited for large deformations and topology changes. "Material Point Method (MPM)~\cite{stomakhin2013material}"
- Neural Radiance Fields (NeRFs): Continuous neural scene representations that map 3D positions and view directions to color and density for volumetric rendering. "neural radiance fields (NeRFs)"
- Neural skinning fields: Learned functions that predict skinning weights or deformations for off-surface points under articulation. "Neural skinning fields"
- Non-rigid motion: Motion characterized by local deformations that alter shape, such as cloth or facial expressions. "Non-rigid motion"
- Optical flow: Per-pixel 2D motion estimates between frames used as priors for dynamic reconstruction. "optical flow"
- Position-based dynamics: A simulation technique that enforces constraints directly in position space for robust deformation. "position-based dynamics"
- Quaternion: A compact 4D parameterization of 3D rotations used in rigid transformations. "quaternion"
- Ray marching mechanism: The process of integrating along rays through a volume to render colors in neural fields. "ray marching mechanism"
- Revolute joint: A 1-DoF joint that rotates about an axis, common in articulated mechanisms. "revolute, prismatic, or fixed"
- Prismatic joint: A 1-DoF joint that translates along an axis, enabling sliding motions. "revolute, prismatic, or fixed"
- Scene flow: 3D motion field estimation of points in a scene across time. "scene flow estimation"
- Score distillation sampling: A technique that leverages pretrained diffusion models to guide optimization via score-matching signals. "score distillation sampling"
- SDF (Signed Distance Function): A scalar field giving the signed distance to a surface, used to enforce geometric and physical consistency. "enforcing SDF and kinematic constraints"
- Skinning weights: Per-vertex weights defining the influence of each joint in LBS-based mesh deformation. "skinning weights"
- SMPL: A widely used parametric human body model with shape and pose parameters and a skeletal structure. "SMPL~\cite{SMPL:2015}"
- Spatio-Temporal Scene Graphs: Graph representations encoding entities and their relations over time in dynamic environments. "Spatio-Temporal Scene Graphs"
- Temporal consistency losses: Training objectives that penalize frame-to-frame appearance or geometry deviations to reduce flicker. "temporal consistency losses"
- Tile-based rasterization: A GPU-friendly rendering strategy that processes primitives in screen-space tiles for efficiency. "tile-based rasterization"
- URDF (Unified Robot Description Format): A standardized specification for robot models including joints, links, and limits. "URDF-standard representation"
- Voxel grids: Discrete volumetric data structures storing features or densities on a 3D grid for fast sampling. "voxel grids"
- Volume rendering: The integration of density and color along rays to synthesize images from volumetric representations. "volume rendering"
Collections
Sign up for free to add this paper to one or more collections.

