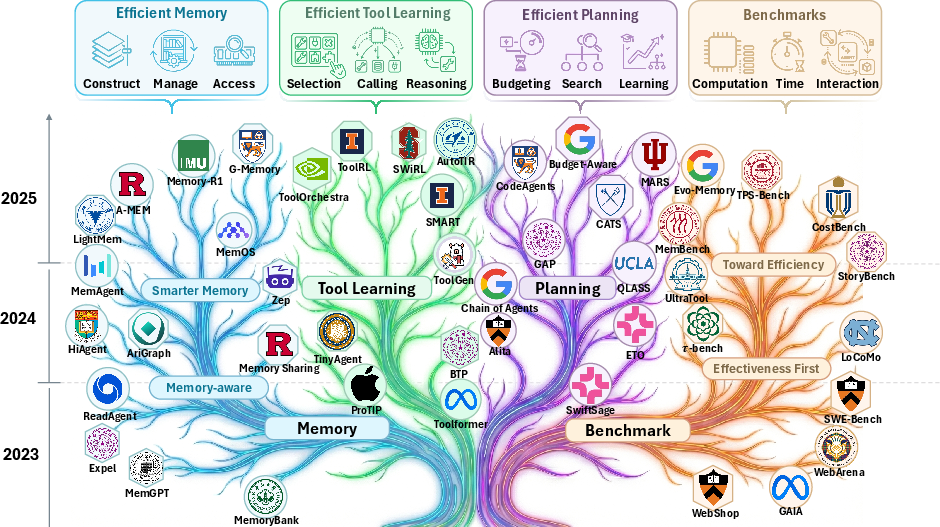
Toward Efficient Agents: Memory, Tool learning, and Planning
Abstract: Recent years have witnessed increasing interest in extending LLMs into agentic systems. While the effectiveness of agents has continued to improve, efficiency, which is crucial for real-world deployment, has often been overlooked. This paper therefore investigates efficiency from three core components of agents: memory, tool learning, and planning, considering costs such as latency, tokens, steps, etc. Aimed at conducting comprehensive research addressing the efficiency of the agentic system itself, we review a broad range of recent approaches that differ in implementation yet frequently converge on shared high-level principles including but not limited to bounding context via compression and management, designing reinforcement learning rewards to minimize tool invocation, and employing controlled search mechanisms to enhance efficiency, which we discuss in detail. Accordingly, we characterize efficiency in two complementary ways: comparing effectiveness under a fixed cost budget, and comparing cost at a comparable level of effectiveness. This trade-off can also be viewed through the Pareto frontier between effectiveness and cost. From this perspective, we also examine efficiency oriented benchmarks by summarizing evaluation protocols for these components and consolidating commonly reported efficiency metrics from both benchmark and methodological studies. Moreover, we discuss the key challenges and future directions, with the goal of providing promising insights.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making “AI agents” more efficient. An AI agent is like a smart helper built on top of a LLM. Instead of just answering one question, it can remember things, plan multi-step tasks, and use tools (like a calculator, a web browser, or other apps) to get stuff done. The problem is that these agents can be slow and expensive to run because they read long histories, call many tools, and take many steps. The paper surveys (reviews and organizes) recent ideas for making agents faster and cheaper without losing their ability to solve problems well. It focuses on three key parts: memory, tool use, and planning, and shows how to measure efficiency fairly.
Key Objectives and Questions
To make the paper’s goals easy to understand, think of an AI agent like a student doing a big project. The authors ask:
- How can the agent remember only the important parts, instead of re-reading everything every time?
- How can the agent use outside tools less often but more smartly?
- How can the agent plan fewer, better steps to reach the goal?
- How do we fairly compare speed and cost versus accuracy, and what are good tests (benchmarks) to measure that?
Methods and Approach
This is a survey paper. That means the authors read many recent research papers, grouped them by what they try to improve (memory, tools, planning), and pulled out the most useful patterns and principles.
To explain the agent’s workflow in everyday terms:
- Imagine you give the agent a task. It loops through steps like a student: 1) It checks its notes (memory), 2) Makes a plan (planning), 3) Uses a tool if needed (tool learning), 4) Looks at the result (observation), 5) Decides what to do next.
Why does this get costly?
- Tokens: Think of “tokens” like the number of words the agent reads and writes. Longer chats and bigger prompts cost more time and money.
- Latency: This is waiting time. More steps and more tool calls mean you wait longer.
- Tool calls: Using external services (like browsing or running code) can be slow or cost money.
- Retries: If the agent makes mistakes and tries again, that adds more cost.
The paper explains two ways to judge efficiency:
- Same cost, better performance; or
- Same performance, lower cost. They also talk about a “Pareto frontier,” which is just a curve showing the best balance between quality and cost—moving closer to the curve means you’re more efficient.
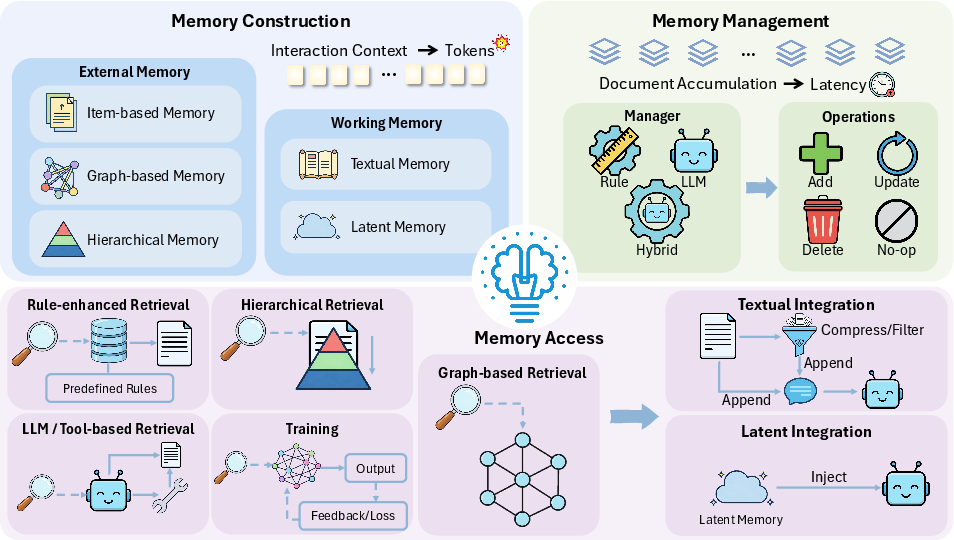
The survey goes deep on memory because it’s the biggest efficiency problem. The authors describe several approaches using simple analogies:
- Working memory (what’s in the agent’s head right now):
- Text summaries: Like keeping a neat, short set of notes instead of the whole history. The agent regularly rewrites and compresses its notes so they stay small and focused.
- Latent memory (not text): Like brain signals the model can store and reuse without re-reading everything. This can be faster because it avoids long prompts.
- External memory (stored outside, like notebooks or a library):
- Item-based: Save small, well-structured snippets (topics, tips, common mistakes, user facts) so retrieval is quick.
- Graph-based: Build a knowledge graph (like a map of people, places, facts, and how they connect) to look up what’s relevant without scanning everything.
- Hierarchical: Organize memory in layers (short-term, mid-term, long-term) so the agent can start broad and zoom in only when needed.
- Memory management (keeping notes tidy):
- Rule-based: Simple rules like “delete old items” or “move summaries to long-term storage” so memory doesn’t explode.
- LLM-based: Ask the model to decide what to keep, merge, or rewrite for better relevance.
- Hybrid: Use fast rules most of the time, and ask the model only when a smarter decision is needed.
- Memory access (picking what to read):
- Better retrieval: Score items by relevance, recency, importance, or attributes to fetch only the most helpful bits.
- Graph retrieval: Follow connections between facts to build a small subgraph that matches the question.
The paper also reviews planning and tool use (beyond what’s shown in the excerpt):
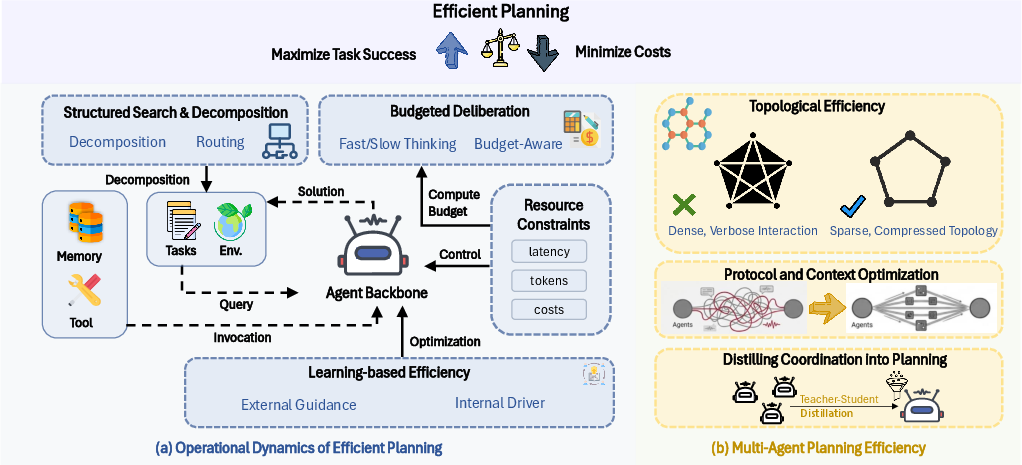
- Planning: Reduce the number of steps by using controlled search, caching good plans, or splitting tasks into clear subgoals.
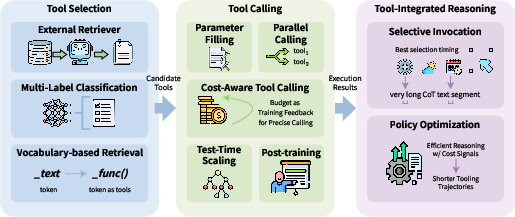
- Tool learning: Train the agent to only call tools when necessary, and choose the right tool the first time to cut down retries and delays.
Main Findings and Why They Matter
Here are the main takeaways the authors highlight, explained simply:
- Compress and manage context: Summarizing and organizing memory (especially with layers or graphs) can massively cut token usage, which reduces cost and speeds up responses.
- Be selective with tools: Reward strategies that solve tasks with fewer tool calls. When tools are used, do it purposefully to avoid repeat work.
- Plan efficiently: Use controlled search and smart planning to reach the goal with fewer steps. Reuse good plans when possible.
- Measure efficiency fairly: Don’t just look at accuracy; also track tokens, latency, number of steps, tool calls, and total cost. Compare systems at the same cost or same accuracy to see who’s truly more efficient.
- Trade-offs are real: Aggressive pruning or too-simple rules can make things fast but hurt accuracy. The best systems balance rules with learning and pick the right memories and tools at the right time.
These findings matter because they show how to build agents that are both capable and affordable. That means more people and organizations can use them for real tasks without huge bills or long waits.
Implications and Impact
Efficient agents can:
- Run faster and cheaper, making them practical for everyday use (like tutoring, research assistance, coding, or customer support).
- Scale to long projects with lots of steps and history without bogging down.
- Be more fair and accessible, since lower cost means more people can use them.
- Reduce environmental impact by cutting computation.
Looking ahead, the paper suggests combining simple rules with smart, learned decisions; improving memory architectures; reducing tool calls with better judgment; and building better benchmarks to measure both cost and quality. If researchers follow these principles, future agents will feel more “thoughtful”: they’ll remember what matters, plan smartly, and use tools wisely—getting high-quality results with much less waste.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, framed to guide actionable future research.
- Lack of standardized, reproducible efficiency metrics across agents and tasks (e.g., unified definitions of cost components, latency sources, amortized retrieval/indexing costs, and a consistent way to report the Pareto frontier of effectiveness versus cost).
- No common instrumentation framework to attribute end-to-end cost to specific modules (generation, memory access/management, planning, tool I/O, retries), making cross-paper comparisons and ablations difficult.
- Limited theoretical foundations for agent efficiency (e.g., formal cost models with provable bounds for memory compression on accuracy, optimal retrieval frequency, or planning depth vs. success trade-offs).
- Insufficient head-to-head empirical benchmarks comparing textual, latent, graph-based, and hierarchical memory under fixed cost budgets and matched tasks; most evidence remains piecemeal and task-specific.
- Unknown break-even points for summarization/compression: when do the extra LLM calls to compress/merge outweigh downstream savings in tokens/latency, and how do these thresholds vary by task and model?
- Sparse analysis of retrieval overhead (index-building, neighbor expansion, graph maintenance) and its amortized cost over long horizons; most evaluations focus on token savings, not end-to-end wall-clock or energy.
- Unclear strategies for verifying correctness of compressed or distilled memories (e.g., ensuring summaries and structured attributes don’t entrench hallucinations or stale facts).
- Conflict resolution and consistency in long-term memory (especially KGs) lacks robust, automated validation pipelines; how to detect contradictions, propagate updates, and enforce temporal validity efficiently?
- Latent memory portability and persistence remain underexplored: how to serialize, version, and securely reuse KV/activation memories across sessions, users, and model updates without leaking or degrading performance?
- Limited guidance on adaptive tiering for hierarchical memory (promotion/demotion triggers, heat/utility scoring) learned from data rather than hand-crafted rules; optimal policies are unknown.
- Cost-aware retrieval policies are not well defined: when to query external memory or tools versus rely on working/latent memory, under explicit budgets and uncertainty.
- The interplay between memory, tool learning, and planning is under-characterized; joint optimization strategies that minimize tool calls and steps while preserving accuracy are missing.
- Tool latency heterogeneity and real-world constraints (API rate limits, network jitter, caching hits/misses) are not modeled in efficiency evaluations; agents need robust, production-grade cost models.
- Safety, privacy, and compliance for external and shared memories are largely unaddressed (data minimization, redaction, right-to-be-forgotten, poisoning and adversarial entries in shared KBs).
- Multi-agent shared memory raises unresolved issues around synchronization, consistency, deduplication, governance, and incentive-compatible access under token/latency budgets.
- Continual learning in parametric or test-time-trainable memory (e.g., Titans) lacks methods to avoid catastrophic interference and to bound compute during updates at inference time.
- Graph-based memory scalability is uncertain: index maintenance, temporal reasoning, and multi-hop retrieval costs at scale are not quantified under strict latency/compute budgets.
- Attribute-augmented memory (e.g., tags, values, personas) needs standardized schema, validation, and drift detection; current approaches rely on LLM extraction without error bounds.
- Plan caching and reuse are promising but under-evaluated; cache invalidation, versioning across environment changes, and template generalization to novel tasks require systematic study.
- Little analysis of energy/carbon accounting for agentic systems; efficiency claims rarely include power usage or sustainability metrics.
- Cross-modal and cross-lingual memory efficiency is unexplored (images, code, structured data); how do compression, retrieval, and latent memories extend beyond text?
- Engine and hardware constraints for latent memory (KV manipulation, attention injection) are not standardized; portability across closed APIs and open-source stacks is unclear.
- Stopping criteria and meta-control for planning (when to terminate reasoning, cut search depth, or switch strategies) need learnable, cost-aware policies with guarantees.
- Dataset and benchmark gaps for efficiency-oriented evaluation: long-horizon tasks with budget constraints, cost-limited leaderboards, and standardized logging to enable reproducible cost-performance comparisons.
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that translate the survey’s efficiency principles (context compression and management, selective memory access, plan caching, and tool-call minimization) into concrete products and workflows across sectors.
- Sector: Customer Support/CRM (Industry)
- Use case: Cost-optimized chatbots with compact working memory and tiered external memory
- What to build:
- A “MemoryOps” middleware that deploys hierarchical memory (e.g., MemGPT/MemoryOS/LightMem patterns) to summarize sessions into short-term pages, topic segments, and long-term user profiles.
- Attribute-augmented experience KB (MemInsight/A-MEM/ACE/Agent KB) to retrieve only relevant resolutions and avoid token overflow.
- Value: Reduces per-interaction tokens and latency; improves response consistency for repeat customers.
- Dependencies/assumptions:
- Reliable LLM with function-calling, embedding store, and latency SLAs.
- PII governance for long-term user memory; retrieval quality tuning to avoid noise.
- Sector: E-commerce & Telecom Contact Centers (Industry)
- Use case: Plan-cached agents for repetitive workflows (refunds, swaps, plan changes)
- What to build:
- “Plan Cache Service” that stores de-contextualized execution templates (agentic plan caching) and ranked reusable strategies (ReasoningBank/ACE).
- Value: Fewer steps and tool/API calls per ticket; faster handling time.
- Dependencies/assumptions:
- Policy to validate cache hits; guardrails to detect stale templates.
- Versioned tool APIs and change monitoring.
- Sector: Enterprise Knowledge Work (Legal, Consulting, Support) (Industry)
- Use case: Structured retrieval over long documents and case history
- What to build:
- Graph-based memory store (GraphReader, Zep, Mem0g, AriGraph) for entity–relation indexing and multi-hop retrieval.
- Page/segment gists with coarse-to-fine access (ReadAgent, LightMem).
- Value: Shrinks prompts; surfaces only the minimal, relevant evidence; reduces “lost-in-the-middle” effects.
- Dependencies/assumptions:
- Document pre-processing pipelines; schema for entities/relations.
- Continuous monitoring for contradiction and staleness (D‑SMART-like checks).
- Sector: Software Engineering (Industry/Academia)
- Use case: IDE-integrated code assistants that reuse learned fixes and workflows
- What to build:
- Experience library (Agent KB/ACE) that captures fix patterns and error modes; plan caching of build/test pipelines.
- Value: Cuts repeated exploration; reduces tool calls (CI, linters); fewer tokens per iteration.
- Dependencies/assumptions:
- Secure repo access; dedup policies; LLM-based merge/rank tuned to code domain.
- Sector: Healthcare Documentation & Triage Support (Industry/Healthcare)
- Use case: Documentation agents with hierarchical and time-aware memory
- What to build:
- Temporal knowledge graph for patients (Zep-like) linked to episode summaries and personas (MemoryOS/LD-Agent).
- Value: Smaller prompts for longitudinal contexts; faster recall of relevant episodes.
- Dependencies/assumptions:
- HIPAA/GDPR compliance; clinician-in-the-loop verification; strict retrieval filters.
- Sector: Education (Industry/Daily Life)
- Use case: Personalized tutors with topic-indexed progress and spaced reinforcement
- What to build:
- Topic-structured student memories (MemoChat/RMM) combined with forgetting-curve management (MemoryBank/H‑MEM).
- Value: Efficient personalization with minimal tokens per session; targeted review.
- Dependencies/assumptions:
- Accurate importance/recency scoring; parental consent and data rights.
- Sector: Finance Research & Ops (Industry)
- Use case: Research assistants using attribute-augmented retrieval and decay
- What to build:
- Attribute-tagged note bank (MemInsight/A‑MEM) with recency/importance/time-decay scoring; update/merge via LLM-based CRUD (Mem0/Memory‑R1).
- Value: Limits prompt size while keeping recent market context salient; fewer retries.
- Dependencies/assumptions:
- Compliance review; staleness detection; audit trails for memory edits.
- Sector: Web Automation/Browsing Agents (Software)
- Use case: Workflow memoization and caching for common sites
- What to build:
- Cache of site-specific strategies and login/payment flows (plan caching + ReasoningBank).
- Value: Lower step counts; fewer browser tool invocations.
- Dependencies/assumptions:
- Site change detection; fallback to exploration when cache misses or invalid.
- Sector: On-device/Edge Assistants (Software/Hardware)
- Use case: Latency- and memory-efficient personal assistants
- What to build:
- Latent memory pools and KV cache compression (MemoryLLM, M+, MemoRAG, Activation Beacon) to reduce repeated encoding and context length.
- Value: Lower compute and cost on-device; faster response under small context windows.
- Dependencies/assumptions:
- Access to model hooks for KV/activation injection; privacy controls; memory footprint budgets.
- Sector: Multi-agent Operations (Industry)
- Use case: Shared memory to reduce duplicated tool calls in swarming teams
- What to build:
- Shared memory hubs with selective addition and staged retrieval (MS, G‑Memory, MIRIX) plus token-budgeted routers.
- Value: Cuts redundant API hits; faster convergence to a solution.
- Dependencies/assumptions:
- Concurrency control; permissions; routing quality at scale.
- Sector: MLE/Platform Teams (Industry)
- Use case: Agent cost-governance and benchmarking
- What to build:
- Dashboards tracking Pareto trade-offs (tokens/latency/steps vs. success), and policy to enforce memory/tool/planning budgets per workflow.
- Value: Immediate spend control; standardized evaluation across teams.
- Dependencies/assumptions:
- Instrumentation for token/tool/latency logs; agreed efficiency metrics.
Long-Term Applications
These opportunities require further research, scaling, or productization—for example, standardized interfaces for latent memory, robust graph maintenance, RL for tool minimization, and regulated deployment.
- Sector: Personal OS-level Assistants (Daily Life/Software)
- Use case: Lifelong, privacy-preserving memory across devices and apps
- What to build:
- System-wide agent memory with MemOS-like type-aware tiers (plaintext/activations/parameter deltas) and lifecycle governance; hybrid management and conflict resolution.
- Rationale: Unified, efficient recall under strict budgets improves usefulness without context sprawl.
- Dependencies/assumptions:
- OS integration for secure memory APIs; standard schemas; local retrieval acceleration; robust hybrid management to avoid drift.
- Sector: Regulated Clinical Decision Support (Healthcare)
- Use case: Agents with longitudinal patient KGs and rule-enforced consistency
- What to build:
- OWL-compliant knowledge graphs (D‑SMART) fused with hierarchical memory for episodes; plan/search controllers that minimize unnecessary tool calls.
- Rationale: Efficiency reduces latency in time-critical settings while maintaining traceability and consistency.
- Dependencies/assumptions:
- Regulatory approval; validation datasets; guarantees for retrieval precision/recall and contradiction handling; human oversight.
- Sector: Autonomous R&D and Scientific Discovery (Academia/Industry)
- Use case: Lab agents that learn and reuse experimental playbooks
- What to build:
- Experience libraries of protocols and failure modes (ReasoningBank/Agent KB) plus controlled search/planning with step budgets; memory-guided tool scheduling.
- Rationale: Cuts instrument time and cloud costs; faster iteration.
- Dependencies/assumptions:
- High-fidelity lab-tool interfaces; simulator-to-reality gaps; safety and audit logs.
- Sector: Large-scale Autonomous Coding (Software/Robotics)
- Use case: End-to-end coding agents that learn organization-wide practices
- What to build:
- Enterprise-wide plan caches, policy-compliant fix patterns, and multi-agent shared memory with role-aware routing (LEGOMem/MIRIX).
- Rationale: Major reductions in repeated exploration and CI cycles.
- Dependencies/assumptions:
- Standardized action vocabularies; dependency graph awareness; strong guardrails for security and IP.
- Sector: Enterprise Knowledge Fabric (Industry)
- Use case: Organization-level dynamic KGs and memory for all departments
- What to build:
- Cross-team temporal KGs (Zep-like) with hybrid maintenance (graph rules + LLM verification), and experience KBs with de-dup/versioning at scale (MemOS).
- Rationale: Minimizes redundant searches and retrieval noise in large corpora.
- Dependencies/assumptions:
- Data stewardship; governance for updates and access controls; compute for graph indexing.
- Sector: Green/Responsible AI Policy (Policy/Industry)
- Use case: Efficiency reporting and standards for agent deployments
- What to build:
- Auditable efficiency metrics (tokens, latency, external calls, retries) and Pareto-tradeoff disclosures; carbon-aware budgets for agent workflows.
- Rationale: Aligns cost and environmental impact with performance.
- Dependencies/assumptions:
- Industry consensus on metrics and reporting; tooling for verifiable logs.
- Sector: Hardware–Software Co-design (Energy/Hardware/Software)
- Use case: Memory-augmented inference platforms
- What to build:
- Accelerators with native activation-memory pools and fast KV mixing; support for test-time trainable memory (Titans/MemGen) and two-tier GPU/CPU memories (M+).
- Rationale: Lowers energy and latency of long-horizon agents.
- Dependencies/assumptions:
- Stable APIs for latent memory injection; compiler/runtime support; workload benchmarks.
- Sector: Education at Population Scale (Education/Policy)
- Use case: Persistent learner profiles with efficient, ethical personalization
- What to build:
- Topic/skill graphs, spaced-retrieval policies, and hierarchical content indices with rigorous privacy controls and portability across institutions.
- Rationale: Improves learning outcomes without costly, long prompts.
- Dependencies/assumptions:
- Consent frameworks; interoperability standards; fairness audits for memory policies.
- Sector: Safety-critical Autonomy (Aviation/Industrial Robotics)
- Use case: Agents with strict memory consistency and controlled planning
- What to build:
- Logic-checked graph memories (OWL/temporal constraints), controlled search planners with step/tool budgets, and verified caches with automatic invalidation.
- Rationale: Efficiency and correctness under operational constraints.
- Dependencies/assumptions:
- Formal verification; certification processes; simulation-to-reality validation.
- Sector: Agent Ecosystems and Marketplaces (Industry/Developer Tools)
- Use case: Exchange of reusable strategies and memory artifacts
- What to build:
- Standardized formats for experience entries (Agent KB/ACE) and plan templates; marketplaces and CI for quality/risk checks.
- Rationale: Reduces duplication of exploration across organizations.
- Dependencies/assumptions:
- IP/licensing models; provenance tracking; security scanning of shared artifacts.
These applications assume access to modern LLMs with function calling, embedding search, and (when needed) low-level hooks for KV/activation manipulation; robust retrieval infrastructure; and organizational policies for privacy, safety, and versioning. As methods mature—particularly hybrid memory management, graph consistency checks, and planning that explicitly trades steps for success—agents will more reliably hit favorable Pareto points (effectiveness vs. cost) in production.
Glossary
- Activation Beacon: A method that uses special tokens to capture and compress layer-wise activations, forming compact latent memory for long contexts. "Activation Beacon~\citep{zhang2024long} partitions the context into chunks and fine-grained units, interleaves beacon tokens by a compression ratio, and uses progressive compression to distill layer-wise KV activations into the beacons, which are accumulated as latent memory while raw-token activations are discarded."
- Agentic plan caching: Storing reusable plan templates distilled from successful executions to avoid re-planning. "Agentic plan caching~\citep{zhang2025costefficientservingllmagents} turns a successful run into a reusable cache entry by rule-based filtering the execution log and then using a lightweight LLM to remove context-specific details, storing the result as a (keyword, plan template) pair."
- Context window saturation: Exceeding the model’s maximum prompt length due to long interactions, causing performance and efficiency issues. "This multi-step execution leads to prohibitive latency, context window saturation, and excessive token consumption, raising profound concerns regarding the long-term sustainability and equitable accessibility of these increasingly capable systems."
- CRUD: An acronym for Create, Read, Update, Delete operations used in memory management. "Adaptive memory CRUD and memory distillation, via two RL-trained agents"
- Discount factor: A parameter in decision processes that weights future rewards less than immediate ones. "The environment dynamics are given by the transition kernel , the reward function , and the discount factor ."
- Ebbinghaus forgetting curve: A model describing how memory retention decreases over time, used to manage which memories to retain. "MemoryBank~\citep{zhong2024memorybank} introduces an Ebbinghaus-inspired memory update rule that decays memories over time while reinforcing important ones."
- FIFO: First-In, First-Out policy for buffering or memory replacement. "MemGPT~\citep{packer2023memgpt} constructs a hierarchical memory by partitioning the in-context prompt into system instructions, a writable working context, and a FIFO message buffer, and storing the remaining history and documents in external recall and archival memory."
- Graph-based memory: Storing information as nodes and edges representing entities and relations for structured retrieval and reasoning. "Graph-based memory represents entities and their relations as a structured graph."
- Hierarchical memory: Multi-level organization of memory enabling coarse-to-fine, on-demand access. "Hierarchical memory organizes information into multiple linked levels, enabling coarse-to-fine, on-demand access."
- Initialization distribution: A distribution defining the initial state of agent memory. "and an initialization distribution over the initial memory."
- Knowledge base (KB): A structured repository of facts or domain knowledge used by an agent. "Memory~\citep{yang2024memory3} encodes a KB as sparse explicit key–value memory injected into attention at decoding time to avoid repeated document reading."
- Knowledge graph (KG): A graph representation of entities and relationships used for storing and reasoning over knowledge. "Another line of work constructs long-term memory directly as a dynamic knowledge graph, turning interactions into entities, relations, and time-aware facts that can be incrementally updated."
- KV cache: A cache of key–value pairs from transformer attention used to speed up and condition generation. "updating a memory-token KV cache across windows with separate weight matrices"
- KV space: The space of key–value attention representations where activations can be compressed or stored. "compact latent memory by compressing long contexts into a small set of activations in KV space."
- Latent environment state space: The hidden state space representing the environment in a decision process. "Here denotes the latent environment state space"
- Latent memory: Non-textual, continuous memory (e.g., activations, hidden states) used to condition the model without tokens. "Latent memory can arise inside the model or be stored externally and injected as continuous conditioning."
- Lost in the middle phenomenon: Degraded retrieval or reasoning when relevant information is buried in long contexts. "as observed in the âlost in the middleâ phenomenon \citep{liu2024lost}."
- Memory tokens: Special tokens that store or carry compressed latent information for reuse across steps. "produces compact latent memory tokens as the stored representation."
- Pareto frontier: The set of optimal trade-offs between cost and effectiveness where improving one dimension worsens the other. "This trade-off can also be viewed through the Pareto frontier between effectiveness and cost."
- Partially observable Markov decision process (POMDP): A framework modeling decision-making under uncertainty with limited observations. "We model an LLM-based agent interacting with an environment as a partially observable Markov decision process (POMDP) augmented with an external tool interface and an explicit memory component."
- RAG (Retrieval-Augmented Generation): A technique that retrieves external documents to augment an LLM’s context for generation. "External memory refers to information stored outside the model in token-level form, including document collections, knowledge graphs, and retrieval systems such as RAG."
- Sliding-window attention: An attention mechanism that restricts attention to a moving window to handle long sequences efficiently. "Sliding-window attention; test-time trainable neural long-term memory"
- Soft prompts: Learnable continuous vectors prepended to model inputs to condition behavior without textual tokens. "such as soft prompts, KV cache, and hidden states."
- Tool interface: The specification of how an agent calls external tools and receives outputs. "a tool interface , which specifies how tool calls are executed and what tool outputs are returned to the agent."
- Transition kernel: The probabilistic rule describing environment dynamics from one state to the next. "The environment dynamics are given by the transition kernel , the reward function , and the discount factor ."
- Vector similarity search: Retrieving items by comparing vector embeddings for semantic similarity. "embedding the aggregated augmentations for vector similarity search."
- Working memory: The subset of information directly available during generation, including prompt tokens or latent states. "Working memory is the information directly available at inference time that conditions generation."
Collections
Sign up for free to add this paper to one or more collections.