Budget-Aware Tool-Use Enables Effective Agent Scaling
Abstract: Scaling test-time computation improves performance across different tasks on LLMs, which has also been extended to tool-augmented agents. For these agents, scaling involves not only "thinking" in tokens but also "acting" via tool calls. The number of tool calls directly bounds the agent's interaction with the external environment. However, we find that simply granting agents a larger tool-call budget fails to improve performance, as they lack "budget awareness" and quickly hit a performance ceiling. To address this, we study how to scale such agents effectively under explicit tool-call budgets, focusing on web search agents. We first introduce the Budget Tracker, a lightweight plug-in that provides the agent with continuous budget awareness, enabling simple yet effective scaling. We further develop BATS (Budget Aware Test-time Scaling), an advanced framework that leverages this awareness to dynamically adapt its planning and verification strategy, deciding whether to "dig deeper" on a promising lead or "pivot" to new paths based on remaining resources. To analyze cost-performance scaling in a controlled manner, we formalize a unified cost metric that jointly accounts for token and tool consumption. We provide the first systematic study on budget-constrained agents, showing that budget-aware methods produce more favorable scaling curves and push the cost-performance Pareto frontier. Our work offers empirical insights toward a more transparent and principled understanding of scaling in tool-augmented agents.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how AI “agents” that use online tools (like search engines and web browsers) can get better results when they’re aware of a limited budget of actions. Think of the agent as a smart helper trying to answer tough questions by searching the web. It has two kinds of effort:
- Thinking: using words and tokens inside its own brain.
- Acting: calling tools, like running a search or opening a webpage.
The main idea is simple: giving the agent more chances to act doesn’t help unless it knows how many actions it has left and uses them wisely. So the authors teach the agent to be “budget-aware” and show that this leads to better performance for the same or lower cost.
What questions did the researchers ask?
They focused on three easy-to-understand questions:
- If an AI agent knows how many tool calls it can make, will it use its actions more wisely and do better?
- Can a simple “budget tracker” message inside the agent’s workflow improve results without extra training?
- Can a more advanced framework, built around budget awareness, plan and verify better to get the most out of a limited budget?
How did they do the research?
They tested web-search agents that answer questions by:
- Searching the web.
- Browsing and reading webpages.
- Reasoning over the information they find.
They studied “test-time scaling,” which means giving the agent more thinking or acting time during the answer process, not more training. Two common styles are:
- Sequential scaling: the agent takes more steps in a single run.
- Parallel scaling: the agent runs multiple separate attempts and then combines the answers.
They introduced two main tools to make agents budget-aware:
Budget Tracker (simple plug-in)
- This is a lightweight add-on that tells the agent, at every step, how many tool calls it has used and how many are left.
- It’s just a small message added into the agent’s prompt. No extra training needed.
- Analogy: Imagine you’re allowed 10 Google searches and 5 webpage reads to solve a puzzle. After each action, a small note tells you “Searches used: 3, searches left: 7; Browses used: 1, browses left: 4.” You plan your next move based on what’s left.
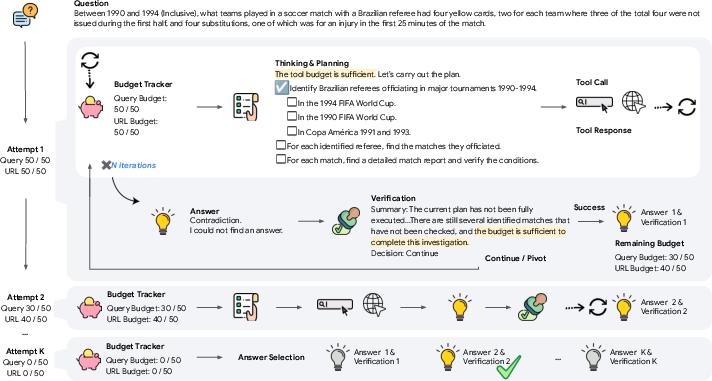
BATS: Budget-Aware Test-time Scaling (full framework)
- BATS keeps track of the remaining budget continuously.
- It has two smart behaviors:
- Planning: It breaks the problem into steps (like a checklist), decides when to explore broadly and when to verify details, and adjusts based on how much budget is left.
- Self-verification: When it thinks it has an answer, it checks if the clues truly support it. If not, it decides whether to dig deeper on the same lead or pivot to try a different path—again guided by the remaining budget.
They also created a unified cost metric:
- Tokens cost: the “thinking” cost (how many words the model reads/writes), priced like cloud AI services do.
- Tool calls cost: the “acting” cost (each search or browse has a price).
- Unified cost adds these together, so you can fairly compare different agents and strategies.
Finally, they tested on real web-search benchmarks (BrowseComp, BrowseComp-ZH in Chinese, and HLE-Search) using popular AI models (like Gemini-2.5 and Claude).
What did they find, and why is it important?
They discovered several key things:
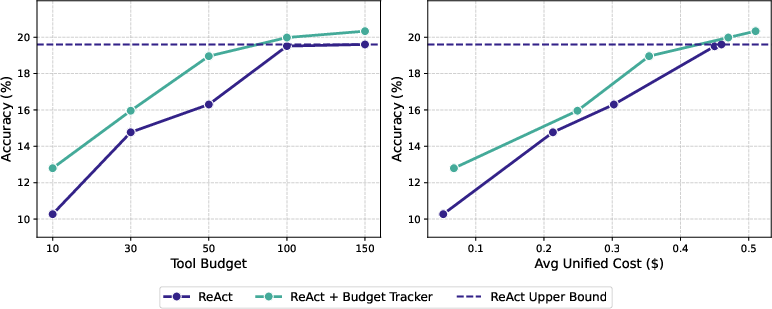
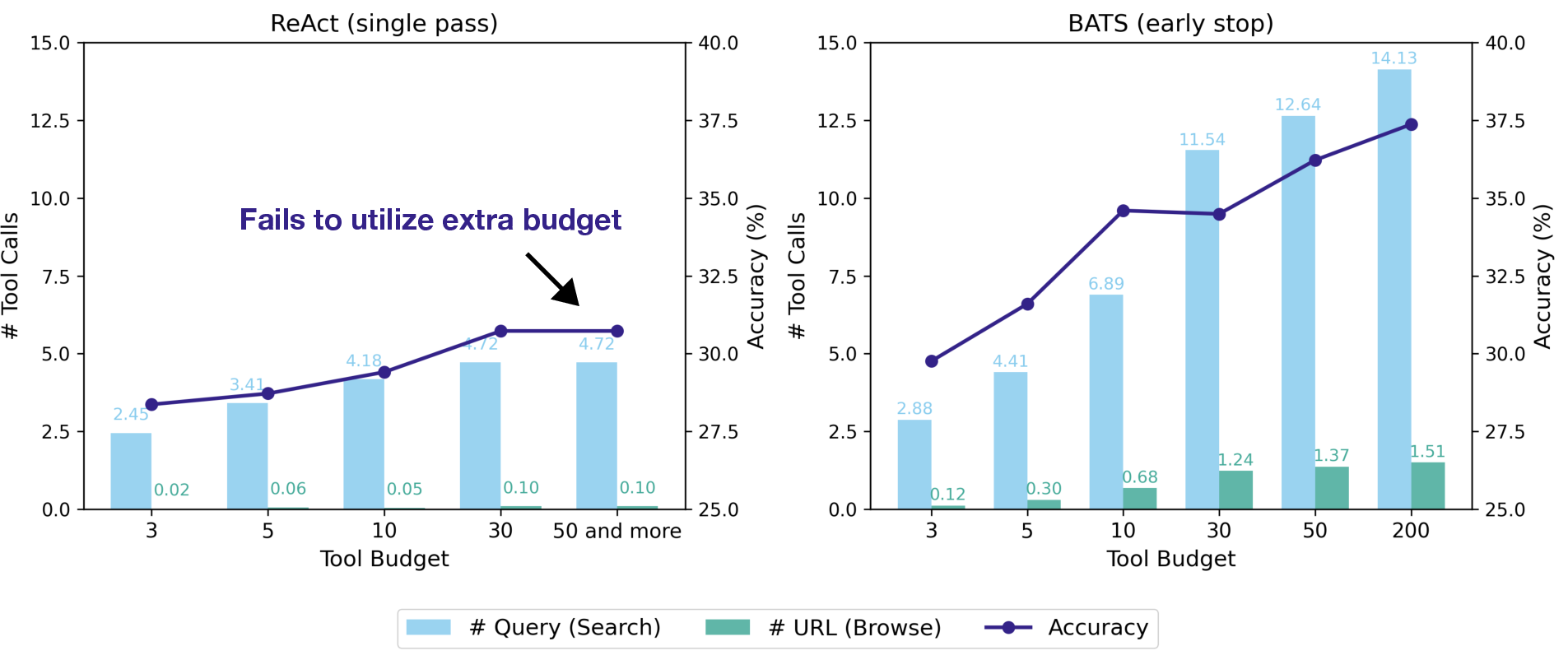
- Simply giving an agent a bigger action budget does not guarantee better results. Standard agents hit a “performance ceiling” because they don’t realize they have more resources to use.
- Adding the Budget Tracker alone improves accuracy across different models and datasets. It helps the agent keep exploring when it still has budget, instead of stopping too early.
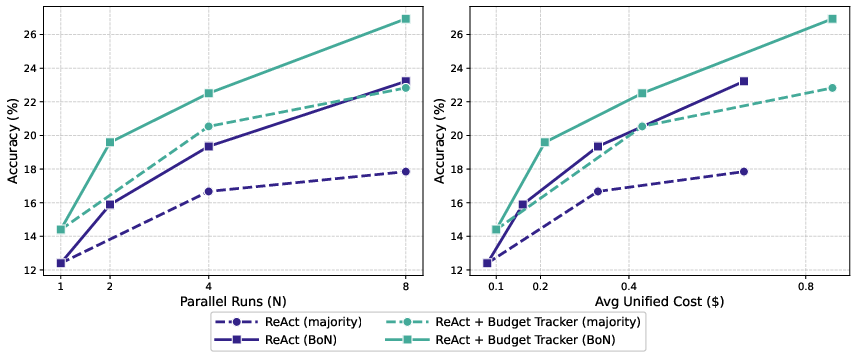
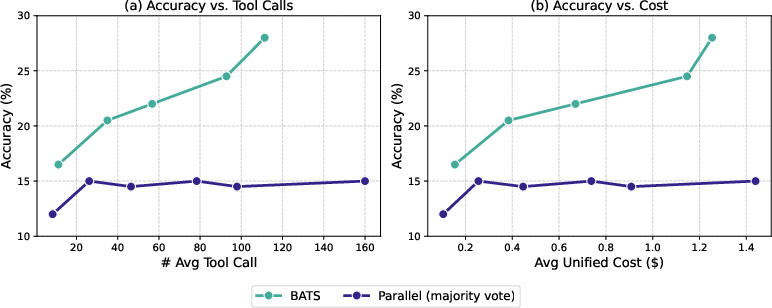
- BATS, the full budget-aware framework, beats standard methods under the same budget. It chooses smarter paths, uses fewer wasteful tool calls, and gets higher accuracy.
- When they measure “unified cost” (tokens + tool calls), budget-aware methods achieve a better balance: more correct answers for the same or lower cost. This pushes the “Pareto frontier,” which means they found better trade-offs between cost and performance.
In plain terms: If you tell the agent how many actions it has and help it plan and verify carefully, it gets more bang for its buck.
Why does this matter?
- For users and companies: Budget-aware agents waste less money and time while finding better answers. That’s important when each search or browse has a real cost.
- For AI developers: The paper shows a simple, training-free way (Budget Tracker) to improve agents. It also offers a more powerful framework (BATS) for smarter planning and self-checking under limits.
- For research: It introduces a fair way to compare agents using a unified cost, and it shows that “acting wisely” matters as much as “thinking more.”
Overall, this work helps build AI agents that are more efficient, reliable, and cost-effective when solving complex tasks with limited resources—just like a careful student who knows how many searches they can make and uses each one thoughtfully.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable items for future research.
- Generalization beyond web search: The study only instantiates budget-aware scaling with search and browse; it remains unknown how Budget Tracker and BATS transfer to other tool ecosystems (e.g., code execution, databases, calculators, vision tools, multi-API orchestration).
- Cross-tool budget allocation: The paper does not investigate principled methods to optimally allocate per-tool budgets (e.g., search vs. browse) under a fixed total budget or adaptively reallocate across tools during execution.
- Learning vs. prompting: BATS is fully prompt-based; open question whether learning-based controllers (e.g., RL, bandits, imitation learning) can outperform prompt-only budget awareness for planning, verification, and budget allocation.
- Theoretical guarantees: No formal analysis of optimality, regret, or convergence for budget-aware test-time scaling; derive conditions where budget-aware strategies provably outperform budget-agnostic baselines.
- Scaling laws under budgets: The paper reports empirical curves but lacks a modeling framework to characterize marginal utility per tool call/token, diminishing returns, and asymptotic performance under budget constraints.
- Joint token–tool optimization: While a unified cost metric is proposed, there is no algorithm that jointly optimizes token usage and tool calls; explore dynamic scheduling of “thinking” vs. “acting” under cost constraints.
- Unified cost metric specification: The exact price parameters (P_i), currency normalization, and token pricing assumptions are not fully specified; evaluate sensitivity to provider pricing, cache-hit rates, and regional cost variability.
- Latency and throughput: The study evaluates cost and accuracy but not time-to-answer or wall-clock latency; quantify latency–accuracy–cost trade-offs and their practical implications.
- Robustness to web noise and drift: No analysis of robustness to stale pages, SEO spam, adversarial content, or time-varying search results; build benchmarks and stress tests for noisy or shifting web environments.
- Reproducibility of tool responses: Search and browse results are inherently non-deterministic and time-sensitive; document seeds, timestamps, and caching strategies to enable reproducible evaluation.
- LLM-as-a-judge reliability: Accuracy is judged by Gemini-2.5-Flash; quantify judge agreement, bias, and error rates (e.g., via multi-judge ensembles, human verification, or calibrated confidence).
- Apples-to-oranges baseline comparisons: Many baselines are not budget constrained or are task-tuned; establish standardized, budget-matched evaluation protocols (same budgets, tools, judges) for fair comparison.
- Statistical rigor: The paper reports averages (some over three runs) without confidence intervals, significance tests, or variance analyses; include statistical tests and error bars across seeds and time.
- Failure mode taxonomy: Limited qualitative analysis of where budget-aware strategies fail (e.g., premature pivots, over-exploration, mis-verification); derive a systematic taxonomy with targeted fixes.
- Planner design ablations: No ablation on tree-structured plan vs. alternative planning forms (flat lists, graph plans, programmatic planners); test how plan representation impacts budget efficiency.
- Verification module internals: The paper lacks metrics on verifier decisions (CONTINUE/PIVOT/SUCCESS rates), false positives/negatives, and the impact of trajectory compression on downstream reasoning.
- Sensitivity to prompting details: Budget Tracker prompt design (policy guidelines, update frequency, formatting) isn’t ablated; test alternative budget signaling strategies and their robustness across models.
- Model coverage: Experiments use proprietary models (Gemini, Claude) but not open-weight LLMs; evaluate portability to widely used open-source models with different cost profiles and capabilities.
- Multilingual breadth: Beyond Chinese (BrowseComp-ZH), the approach isn’t tested across more languages or scripts; measure cross-lingual performance and region-specific web ecosystems.
- Extreme low/high budgets: Limited exploration of edge cases (ultra-low budgets <3 calls, ultra-high budgets where context saturation becomes critical); characterize viability thresholds and saturation regimes.
- Context management: The verifier compresses trajectories, but there’s no quantification of compression quality, information loss, and impact on subsequent reasoning and accuracy.
- Cache-hit accounting: Token cost mentions cache hits, yet empirical cache-hit rates and their effect on unified cost are not reported; measure and optimize caching strategies.
- Aggregation strategies in parallel scaling: Majority vote and Best-of-N are used, but the paper doesn’t explore cost-aware aggregators, confidence-weighted voting, or judge-aware ensembles.
- Tool diversity: Results rely on Google Custom Search, Jina.ai, and Crawl4AI; test alternative providers (e.g., Bing, Kagi, DDG) and different scrapers to assess robustness and portability.
- Safety considerations: The paper doesn’t address safety (e.g., harmful content, deceptive pages, privacy) under budget constraints; integrate safety checks and evaluate their cost–performance impact.
- Real-world constraints: Rate limits, quota management, and API failures are not modeled; develop controllers that are robust to provider constraints and transient errors.
- Data freshness and temporal grounding: No mechanism to ensure answers are time-aware; evaluate how budget-aware strategies handle queries requiring up-to-date information.
- Human-grounded evaluation: Beyond LLM judges, there’s no human evaluation for correctness, evidence quality, and attribution; add human assessments and citation verification protocols.
- Parameter sensitivity: Temperature, thinking budgets, and max tokens vary across models without systematic sensitivity studies; quantify how these hyperparameters affect budget use and accuracy.
- Cost units and currency normalization: Tables include “¢” artifacts and omit precise currency normalization; standardize cost reporting (e.g., $USD per query) and publish the exact pricing schedule used.
- Code, prompts, and artifact availability: Some appendix prompts and implementation details are referenced but not included; release full prompts, seeds, logs, and code for reproducibility.
- Generalization to multi-agent orchestration: The paper doesn’t explore budget-aware coordination among multiple agents or runs; study resource-aware scheduling and information sharing across agents.
- Tool bundling and macro-actions: BATS triggers tools via specific tokens but doesn’t evaluate bundled actions (e.g., multi-query batches) or programmatic pipelines that may be more cost-efficient.
- Interaction with training-based agents: It remains unclear whether BATS can augment or replace training-heavy agents; test hybrid setups combining learned search policies with budget-aware scaling.
- Mechanisms for misreported budgets: The agent assumes accurate budget signals; study robustness when budget trackers are noisy, delayed, or adversarially manipulated.
Practical Applications
Immediate Applications
The following applications can be deployed today by leveraging the paper’s Budget Tracker (prompt-level plug-in), BATS (budget-aware orchestration with planning and self-verification), and unified cost metric (tokens + tool calls). Each item notes likely sectors, product/workflow ideas, and key assumptions or dependencies.
- Bold: Budget-aware enterprise research assistants
- Sector: software, enterprise knowledge management, professional services
- What: Integrate Budget Tracker into existing ReAct-style agents (e.g., internal search copilots) to control API spend while improving answer quality under fixed budgets. Use BATS for adaptive planning (explore vs. pivot) on web and intranet sources.
- Tools/products/workflows: “Budget-aware agent” mode in enterprise copilots; cost dashboards using the unified cost metric; budget-forcing prompts; BATS verification to validate citations before finalizing answers.
- Assumptions/dependencies: Stable access to search/browse APIs (e.g., Google Custom Search, Jina, Crawl4AI); accurate token/tool metering; LLMs respond faithfully to budget prompts.
- Bold: FinOps-style monitoring for agentic systems
- Sector: software, MLOps/FinOps
- What: Adopt the unified cost metric to monitor token and tool-call spend per task, team, or workflow. Compare cost–performance scaling curves and tune budgets for the best Pareto trade-offs.
- Tools/products/workflows: “Unified cost” telemetry in model gateways; budget thresholds and alerts; A/B tests of scaling strategies; cost-aware agent evaluation reports.
- Assumptions/dependencies: Reliable pricing metadata for tokens and external tools; logging and attribution across multi-step runs; buy-in from FinOps and ML platform teams.
- Bold: Budget-aware due diligence and competitive intelligence
- Sector: finance, corporate strategy, consulting
- What: Use BATS for web research that must respect vendor query limits and per-inquiry spend caps; dynamically deepen promising leads and pivot early from low-yield paths.
- Tools/products/workflows: Due diligence playbooks implemented as BATS plans; verification to cross-check key claims; per-vendor quota management.
- Assumptions/dependencies: Access to data-vendor APIs with known pricing/limits; governance for data use and audit logs; judge model for answer validation.
- Bold: Legal and regulatory research with cost controls
- Sector: legal services, compliance
- What: Apply Budget Tracker to legal research agents to throttle queries to paid databases and avoid runaway tool use; BATS verifies that all constraints (jurisdiction, time frame) are satisfied before concluding.
- Tools/products/workflows: “Budget-aware Westlaw/Lexis” connectors; structured constraint checklists; cost-per-matter reporting.
- Assumptions/dependencies: Licensing and API access; secure handling of sensitive queries; correctness validated by human review.
- Bold: Healthcare literature and guideline triage (non-clinical decision support)
- Sector: healthcare (research ops, medical education)
- What: Use BATS to conduct budgeted literature searches (PubMed, guidelines, society statements), balancing breadth and depth with verification of inclusion/exclusion criteria.
- Tools/products/workflows: Study-screening plans as BATS checklists; budget-aware browsing of full texts; summary verification before handoff to clinicians/researchers.
- Assumptions/dependencies: Non-diagnostic use; access to literature APIs and institutional subscriptions; human-in-the-loop for clinical accuracy and compliance.
- Bold: Customer support and helpdesk triage
- Sector: customer service, SaaS
- What: Budget-aware agents retrieve from KBs, forums, logs, and CRM under per-ticket budgets; BATS verification checks that suggested resolutions align with documented procedures.
- Tools/products/workflows: Tiered budgets by ticket severity; exploration vs. verification toggles; cost/performance SLAs.
- Assumptions/dependencies: Secure connectors to internal tools; clear escalation pathways; robust retrieval plugins.
- Bold: OSINT, journalism, and threat intelligence with rate-limit safety
- Sector: media, cybersecurity, public-interest research
- What: Run BATS to prioritize leads, pivot from dead ends, and keep within scraping/rate-limit and ToS constraints; verification checks corroboration across sources.
- Tools/products/workflows: Source coverage plans; budget capping per domain; evidence tracking and citation verification.
- Assumptions/dependencies: Compliance with robots.txt/ToS; ethical review; provenance capture and human editorial oversight.
- Bold: Education and student research copilots
- Sector: education
- What: Provide students with research assistants that surface remaining “search budget,” encouraging better planning and source diversity; BATS checks assignment-specific constraints before finalizing summaries.
- Tools/products/workflows: Classroom research quotas; rubric-aligned verification; per-student cost dashboards.
- Assumptions/dependencies: Age-appropriate content filtering; academic integrity policies; access to safe browsing/search tools.
- Bold: Marketing and market landscaping
- Sector: marketing, product management
- What: Budget-aware landscape mapping—gather competitor features, pricing, reviews within per-campaign budgets; BATS verifies claims across multiple sources.
- Tools/products/workflows: Campaign-specific budgets; structured checklists for feature extraction; automated brief generation with source traceability.
- Assumptions/dependencies: Access to target sites/APIs; deduplication and de-spam; compliance with data use policies.
- Bold: Developer tooling and agent SDKs
- Sector: software
- What: Package Budget Tracker and BATS as SDK plugins for popular agent frameworks to expose real-time budget state, planning, and self-verification.
- Tools/products/workflows: Middleware that injects budget prompts; orchestrators with per-tool quotas; evaluation harnesses using the unified cost metric.
- Assumptions/dependencies: Framework compatibility (ReAct-like loops); configurable tool adapters; observability integrations.
- Bold: Procurement and API governance
- Sector: enterprise IT, procurement
- What: Enforce per-tool budgets at the API gateway and surface remaining budgets to agents (via Budget Tracker) to guide behavior; monitor against the unified cost metric for vendor negotiations.
- Tools/products/workflows: Policy-as-code for API quotas; cost rollups by vendor/tool; budget-aware retries and backoffs.
- Assumptions/dependencies: API gateway with policy enforcement; centralized billing; legal/data governance alignment.
- Bold: Personal assistants with spend awareness
- Sector: consumer/daily life
- What: Assistants that display remaining monthly “web-research budget,” prompting users to decide when to dig deeper versus accept an approximate answer.
- Tools/products/workflows: Budget widgets in chat UI; per-task budget presets (quick answer vs. deep dive); verification “confidence checks.”
- Assumptions/dependencies: Consumer-friendly cost metering; transparent pricing; opt-in controls.
Long-Term Applications
These applications require further research, scaling, model improvements, standardized pricing interfaces, and/or broader tooling ecosystems beyond web search and browse.
- Bold: Multi-agent, budget-aware resource markets
- Sector: software, operations research
- What: Allocate shared budgets across agent swarms using market/auction mechanisms; agents bid for tool calls and verify outcomes to maximize team utility.
- Tools/products/workflows: Resource allocators; cost-aware schedulers; cross-agent verification protocols.
- Assumptions/dependencies: Reliable utility signals; coordination frameworks; fairness/safety guarantees.
- Bold: Generalized multi-tool orchestration with unified costs
- Sector: software, data platforms
- What: Extend BATS beyond web tools to structured DBs, code execution, vector search, proprietary APIs, and multimodal tools with heterogeneous pricing.
- Tools/products/workflows: Tool portfolios with per-call cost models; dynamic cost-aware routing; unified cost standard.
- Assumptions/dependencies: Standardization of tool pricing metadata; accurate latency/cost prediction; robust tool-use semantics.
- Bold: Autonomous research pipelines (R&D, drug discovery, materials)
- Sector: healthcare/life sciences, manufacturing
- What: Budget-aware orchestration across literature mining, data extraction, simulation calls, and lab scheduler APIs; verify intermediate hypotheses before expensive steps.
- Tools/products/workflows: Lab-ops connectors; staged verification gates; cost-sensitive experiment planning.
- Assumptions/dependencies: High-precision domain tools; regulatory compliance; human-in-the-loop governance.
- Bold: Real-time FinOps autopilot for LLM agents
- Sector: finance, cloud ops
- What: Agents adapt planning to dynamic token and API prices (spot pricing, vendor changes), continuously pushing the cost–performance frontier.
- Tools/products/workflows: Price feeds; cost-aware policy learners; dashboards with real-time Pareto tuning.
- Assumptions/dependencies: Live pricing APIs; stable optimization signals; guardrails against oscillations.
- Bold: Policy and standards for cost–performance reporting
- Sector: policy, industry consortia
- What: Establish unified cost benchmarks for agent evaluations; require cost–accuracy disclosures in public deployments and government procurements.
- Tools/products/workflows: Standard evaluation suites; audit templates; procurement checklists.
- Assumptions/dependencies: Consensus on metric definitions; participation by vendors; third-party auditors.
- Bold: Safety via budget-aware constraints and formal guarantees
- Sector: AI safety, compliance
- What: Use budget ceilings and verification gates to constrain tool thrashing, data exfiltration, or harmful actions; analyze failure modes under cost constraints.
- Tools/products/workflows: Formal specs for budget-constrained behavior; red-teaming with unified cost metrics; verifiable logs.
- Assumptions/dependencies: Measurable safety objectives; formal verification techniques adapted to agents; provable adherence.
- Bold: Training-time budget awareness
- Sector: AI research
- What: Fine-tune models on cost-labeled trajectories so budget awareness is intrinsic, improving robustness beyond prompt-level signals.
- Tools/products/workflows: Datasets with token/tool cost annotations; reinforcement learning with cost-sensitive rewards; curriculum on exploration vs. verification.
- Assumptions/dependencies: High-quality trajectory data; stable training methods; generalization across tools.
- Bold: Public-sector services under explicit cost/rate limits
- Sector: government, civic tech
- What: Budget-bounded agents for FOIA triage, benefits eligibility screening, and open-data queries that comply with rate limits and budgets while maximizing coverage and equity.
- Tools/products/workflows: Policy-aware BATS plans; audit trails; citizen-facing transparency on costs.
- Assumptions/dependencies: Security accreditation; accessibility requirements; multilingual support.
- Bold: Robotics and real-world planning with action budgets
- Sector: robotics, logistics
- What: Generalize “tool calls” to physical actions/sensor queries; plan and verify using limited action/energy budgets (e.g., warehouse picking, inspection rounds).
- Tools/products/workflows: Cost models for actions/sensing; simulation-informed planning; verification via sensor fusion.
- Assumptions/dependencies: Reliable sim2real transfer; precise cost estimation for actions; safety constraints.
- Bold: Edge–cloud offloading with budget/energy co-optimization
- Sector: mobile/edge, energy
- What: Agents decide when to compute locally vs. call cloud tools based on unified cost that blends dollars, latency, and energy.
- Tools/products/workflows: On-device budget trackers; latency/energy predictors; adaptive offloading policies.
- Assumptions/dependencies: Accurate local energy models; user QoS preferences; variable network conditions.
- Bold: Marketplace-aware budgeting across heterogeneous data vendors
- Sector: finance, data marketplaces
- What: Allocate a fixed budget across vendors with different prices/quality; learn bandit-style policies on when to deepen with a vendor vs. pivot.
- Tools/products/workflows: Vendor scoring pipelines; dynamic budget splitters; outcome-based pricing feedback.
- Assumptions/dependencies: Comparable quality metrics; transparent pricing; contracts permitting automated access.
Notes on Assumptions and Dependencies (cross-cutting)
- Unified cost accuracy depends on correct token accounting (input/output/cache hits) and up-to-date per-tool pricing.
- Budget Tracker and BATS currently demonstrated for web search/browse; generalization to complex tools may need additional tool schemas and richer verification prompts.
- Effectiveness hinges on LLM adherence to budget prompts and quality of self-verification; weaker models may require stricter guardrails or human oversight.
- Judge models used for verification/selection introduce cost and potential bias; organizations may substitute domain-specific judges or human review.
- Compliance, data privacy, and ToS constraints must be honored when browsing/scraping; rate-limits and robots.txt adherence are essential.
- Context window limits and summarization fidelity affect long-horizon tasks; improved compression/summarization may be needed for very large searches.
- For high-stakes domains (healthcare, legal, public policy), outputs should be treated as decision support with human-in-the-loop validation.
Glossary
- Agent test-time scaling: The study of how an agent's performance changes with its available test-time resources. "We formulate agent test-time scaling as how an agent's performance scales with its budget for external tool-call interaction,"
- BATS (Budget Aware Test-time Scaling): A framework that adapts planning and verification based on remaining budget to improve agent performance. "we introduce BATS (Budget Aware Test-time Scaling), an advanced framework that leverages this awareness to dynamically adapt its planning and verification strategy, deciding whether to
dig deeper'' on a promising lead orpivot'' to new paths based on remaining resources." - Best-of-N: An aggregation method that selects the single best answer from N sampled runs. "We report Majority Vote, Best-of-N and Pass@N results, following common test-time scaling practice"
- Budget awareness: An agent’s explicit understanding of remaining resource limits that guides tool use and reasoning. "they lack ``budget awareness'' and quickly hit a performance ceiling."
- Budget-constrained optimization objective: An optimization formulation that maximizes accuracy subject to strict per-tool call constraints. "We formulate the agent test-time scaling problem as a budget-constrained optimization objective:"
- Budget-forcing strategy: A prompting technique that encourages continued tool use when budget remains. "In sequential scaling, we adopt the budget-forcing strategy~\citep{DBLP:journals/corr/abs-2501-19393} by appending the following message when the agent proposes an answer: \"Wait, you still have remaining tool budget, use more search and browse tools to explore different information sources before concluding.\""
- Budget Tracker: A lightweight plug-in that surfaces real-time remaining budgets inside the agent’s loop. "Budget Tracker is a lightweight plug-in that can be applied to both a standard ReAct agent (top) and more advanced orchestration frameworks like BATS (bottom)."
- Cache hit tokens: Tokens billed at lower cost due to reuse from cached context across iterations. "distinguishing among input, output, and cache hit tokens."
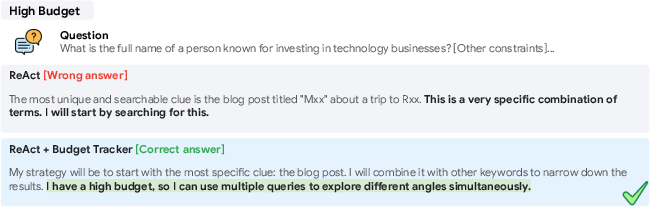
- Constraint decomposition: Breaking problem requirements into exploration and verification clues to guide search. "we prompt the agent to first perform constraint decomposition and to categorize the clues implied in the question into two types: (1) exploration, which expand the candidate space, and (2) verification, which validate specific properties."
- Early stopping: Ending execution before exhausting budget when a confident answer is reached. "We analyze how effectively agents can solve questions under budget constraints when allowed to stop early, without exhausting all tool calls."
- FLOPs budget: A constraint on computational effort measured in floating-point operations. "AgentTTS~\citep{DBLP:journals/corr/abs-2508-00890} optimizes LLM size and sampling numbers under a unified FLOPs budget"
- LLM-as-a-judge: Using a LLM to select or evaluate the best answer among candidates. "Finally, an LLM-as-a-judge selects the best answer across all verified answers."
- Majority Vote: Aggregating multiple runs by choosing the most common answer. "We report Majority Vote, Best-of-N and Pass@N results, following common test-time scaling practice"
- Orchestration framework: The agent system that coordinates reasoning, planning, verification, and tool use. "Budget Tracker, a light-weight, plug-in module compatible with any agent orchestration framework that enables effective budget-aware tool use."
- Pareto frontier: The set of optimal trade-offs where improving cost or performance worsens the other. "push the cost-performance Pareto frontier."
- Parallel scaling: A strategy that runs multiple independent attempts in parallel and aggregates them. "Mainstream scaling strategies such as sequential and parallel scaling enable models to utilize more effort, elicit deeper reflection, and refine their outputs"
- Pass@N: The probability that at least one of N sampled attempts is correct. "We report Majority Vote, Best-of-N and Pass@N results, following common test-time scaling practice"
- Planning module: A component that allocates stepwise effort and guides tool use based on budget. "A planning module adjusts stepwise effort to match the current budget"
- Post-hoc cost metric: A cost measure computed after execution to analyze and compare strategies. "we introduce in Section~\ref{sec:prob_instantiation} a unified post-hoc cost metric for analyzing agents' test-time scaling."
- ReAct: A pattern that alternates reasoning (“think”) and acting (tool calls) for agents. "Building on the ReAct framework, we incorporate the Budget Tracker immediately after each tool response to inform the agent of its remaining budget."
- ReAct-style loop: An iterative cycle alternating internal reasoning and external actions. "The agent follows an iterative ReAct-style loop, alternating between internal thinking and external actions."
- Self-verification module: A subsystem that checks constraints and resource use to validate proposed answers. "Once the agent proposes an answer, the self-verification module re-evaluates the reasoning trajectory and corresponding resource usage."
- Sequential scaling: A strategy where a model iteratively refines its output through multiple steps. "Mainstream scaling strategies such as sequential and parallel scaling enable models to utilize more effort, elicit deeper reflection, and refine their outputs"
- Temperature sampling: Generating diverse reasoning paths by sampling with a nonzero temperature. "For parallel scaling, we use temperature sampling to generate diverse reasoning paths."
- Test-time scaling: Increasing inference-time computation (tokens, tool calls, or runs) to improve performance. "Test-time scaling for tool-augmented agents expands both thinking (tokens) and acting (tool calls)."
- Tool-augmented agents: Agents equipped with tools (e.g., search, browse) to interact with external environments. "extend test-time scaling to tool-augmented agents, where LLMs are equipped with various tools to interact with the external environment such as search engines or APIs."
- Tool-call budget: A predefined limit on the number of invocations per tool. "explicit tool-call budgets, focusing on web search agents."
- Unified cost metric: A single measure combining token usage and tool-call expenses for fair comparison. "we formalize a unified cost metric that jointly accounts for the economic costs of both internal token consumption and external tool interactions."
- Verification module: A component that decides whether to continue, pivot, or stop based on constraints and budget. "a verification module decides whether to
dig deeper'' into a promising lead orpivot'' to alternative paths based on resource availability."
Collections
Sign up for free to add this paper to one or more collections.