- The paper introduces a taxonomy for agentic multimodal LLMs, emphasizing autonomous decision-making, proactive tool use, and cross-domain interaction.
- It contrasts dense and mixture-of-experts architectures and discusses training strategies like CPT, SFT, and RL to enhance model performance.
- The survey identifies open challenges in efficiency, long-term memory, safety, and evaluation that are critical for deploying autonomous, agentic AI systems.
Agentic Multimodal LLMs: A Comprehensive Survey
Introduction and Motivation
The surveyed work provides a systematic and technical overview of Agentic Multimodal LLMs (Agentic MLLMs), delineating the paradigm shift from static, workflow-bound MLLM agents to models endowed with agentic capabilities—autonomous decision-making, dynamic planning, proactive tool use, and robust generalization across domains. The survey establishes a conceptual taxonomy, reviews foundational architectures, training and evaluation methodologies, and synthesizes the state of the art in internal intelligence, tool invocation, and environment interaction. The implications for AGI, practical deployment, and future research are critically discussed.
From MLLM Agents to Agentic MLLMs
Traditional MLLM agents are characterized by static, pre-defined workflows, passive execution, and domain-specificity. In contrast, agentic MLLMs are formalized as adaptive policies within a Markov Decision Process (MDP) framework, capable of dynamic workflow adaptation, proactive action selection, and cross-domain generalization. The survey formalizes these distinctions both conceptually and mathematically, emphasizing the transition from hand-crafted pipelines to models that optimize policies over action and environment spaces.
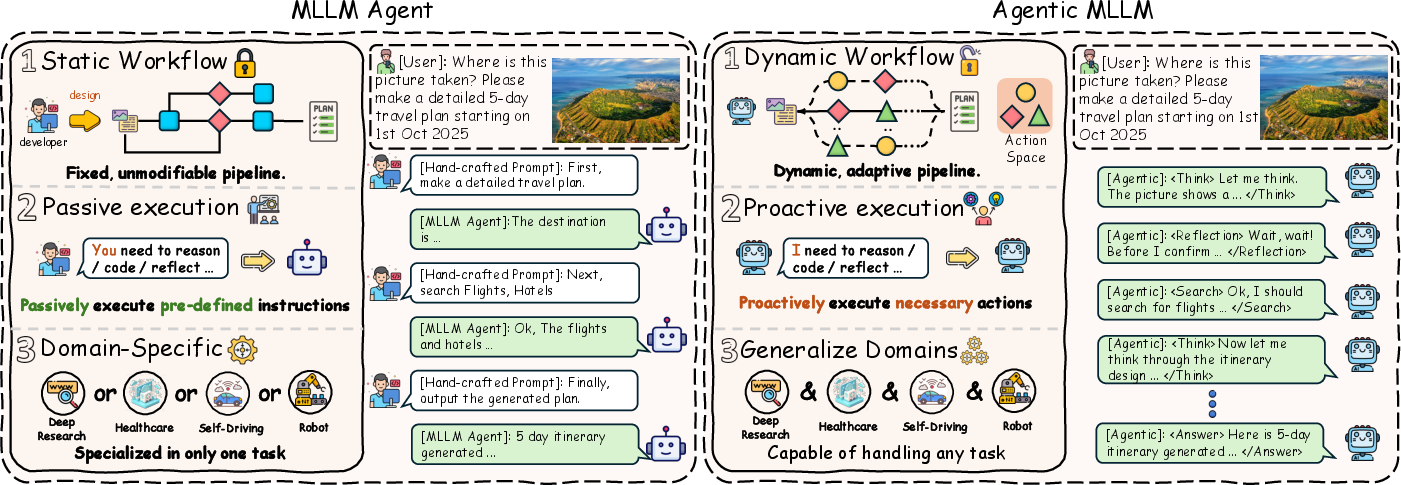
Figure 2: The key differences between Agentic MLLMs and MLLM Agents: dynamic/adaptive workflow, proactive execution, and strong cross-domain generalization.
Taxonomy and Capability Evolution
The survey introduces a threefold taxonomy for agentic MLLMs:
- Internal Intelligence: Reasoning, reflection, and memory mechanisms that enable long-horizon planning and self-improvement.
- External Tool Invocation: Proactive and context-sensitive use of external tools (search, code execution, visual processing) to augment intrinsic model capabilities.
- Environment Interaction: Active engagement with virtual and physical environments, supporting feedback-driven adaptation and goal-directed behavior.
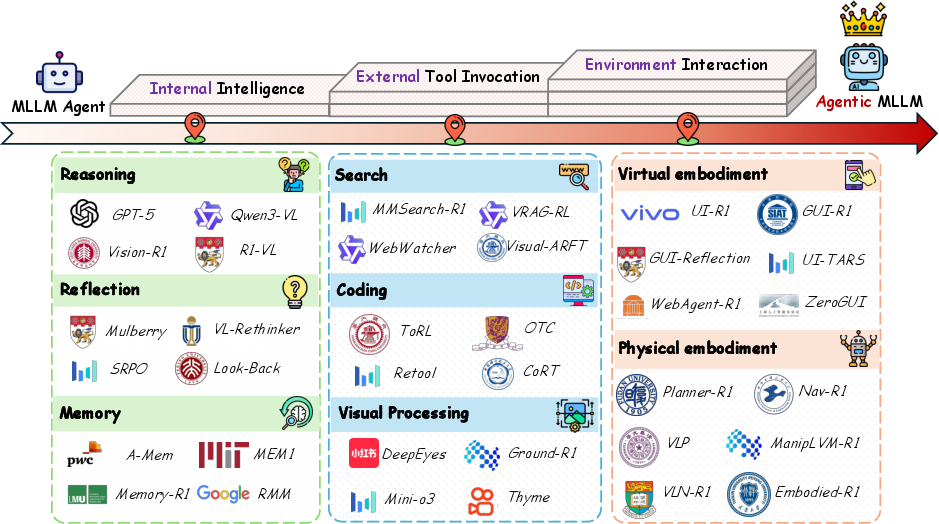
Figure 1: Capability evolution from MLLM Agents to Agentic MLLMs, with representative works across internal intelligence, tool usage, and environment interaction.
Foundations: Architectures, Training, and Evaluation
Foundational Architectures
The survey distinguishes between dense and Mixture-of-Experts (MoE) MLLMs. Dense models (e.g., LLaVA, Qwen2.5-VL) activate all parameters per token, offering stable optimization but limited scalability. MoE models (e.g., Deepseek-VL2, GLM-4.5V, GPT-oss) employ sparse expert activation via gating networks, enabling specialization and efficient scaling to hundreds of billions of parameters. The trend toward MoE is motivated by the need for adaptive reasoning and dynamic tool invocation.
Agentic Action Space
Action spaces are grounded in natural language, with actions specified via special or unified tokens. This enables flexible, interpretable, and extensible action definitions, supporting reasoning, tool use, and environment interaction.
Training Paradigms
- Continual Pre-training (CPT): Integrates new knowledge and planning skills without catastrophic forgetting, using large-scale synthetic corpora and MLE objectives.
- Supervised Fine-tuning (SFT): Provides strong policy priors via high-quality, multi-turn agentic trajectories, often synthesized through reverse engineering or graph-based methods.
- Reinforcement Learning (RL): Refines agentic capabilities via exploration and reward-based feedback, with PPO and GRPO as primary algorithms. Both outcome-based and process-based reward modeling are discussed, with the latter providing finer-grained supervision but increased complexity and susceptibility to reward hacking.
Evaluation
Evaluation is bifurcated into process-level (intermediate reasoning/tool use) and outcome-level (final task success) metrics, reflecting both transparency and effectiveness.
Agentic Internal Intelligence
Reasoning
Prompt-based, SFT-based, and RL-based paradigms are reviewed. RL-based approaches (e.g., DeepSeek-R1, OpenAI o1) have demonstrated significant improvements in long-chain reasoning, with curriculum learning, data augmentation, and process-level rewards further enhancing robustness and coherence.
Reflection
Reflection is induced both implicitly (emergent via RL) and explicitly (response-level and step-level mechanisms). Explicit reflection, as in Mulberry and SRPO, enables iterative refinement and error correction, mitigating the irreversibility of autoregressive generation.
Memory
Memory is categorized as contextual (token compression, window extension) and external (heuristic-driven, reasoning-driven). Recent advances (e.g., Memory-R1, A-Mem) employ RL-based memory management, supporting dynamic, task-driven storage and retrieval. However, multimodal memory remains an open challenge.
Agentic MLLMs autonomously invoke external tools for information retrieval, code execution, and visual processing. RL-based frameworks enable models to decide when and how to use tools, integrating tool outputs into reasoning chains. Notably, agentic search and code execution have been extended to multi-hop, multimodal, and domain-specific scenarios, with process-oriented rewards and hint engineering strategies improving efficiency and reliability.
Agentic Environment Interaction
Virtual Environments
Agentic GUI agents leverage both offline demonstration and online RL-based learning. The transition from reactive actors to deliberative reasoners (e.g., InfiGUI-R1, UI-TARS) is facilitated by explicit spatial reasoning, sub-goal guidance, and iterative self-improvement.
Physical Environments
Embodied AI agents integrate perception, planning, navigation, and manipulation. RL frameworks (e.g., Embodied Planner-R1, OctoNav) enable think-before-act reasoning, long-horizon planning, and robust generalization in real and simulated environments.
Training and Evaluation Resources
The survey compiles open-source frameworks for CPT, SFT, and RL, as well as curated datasets for training and evaluation across all agentic dimensions. The lack of high-quality, multimodal agentic trajectory data and comprehensive evaluation benchmarks for memory and multi-tool coordination is identified as a critical bottleneck.
Applications
Agentic MLLMs are deployed in deep research, embodied AI, healthcare, GUI automation, autonomous driving, and recommender systems. These applications leverage the models' generalization, autonomy, and tool-use capabilities to address complex, real-world tasks that require multi-step reasoning, dynamic adaptation, and cross-modal integration.
Challenges and Future Directions
Key challenges include:
- Richer Action Spaces: Expanding the diversity and compositionality of tool use and environment interaction.
- Efficiency: Reducing computational overhead in multi-turn reasoning and tool invocation to enable real-time and large-scale deployment.
- Long-term Memory: Developing scalable, selective, and persistent multimodal memory architectures.
- Data and Evaluation: Synthesizing high-quality multimodal agentic data and designing robust, process-level evaluation benchmarks.
- Safety: Ensuring reliable, controllable, and aligned agentic behavior, especially in open-ended, multimodal, and tool-augmented settings.
Conclusion
This survey provides a comprehensive technical synthesis of agentic MLLMs, formalizing their conceptual foundations, reviewing architectural and algorithmic advances, and mapping the landscape of applications and open challenges. The transition to agentic MLLMs marks a significant step toward more autonomous, adaptive, and general-purpose AI systems. Future research must address efficiency, memory, safety, and evaluation to realize the full potential of agentic intelligence in multimodal, real-world environments.

