PhysRVG: Physics-Aware Unified Reinforcement Learning for Video Generative Models
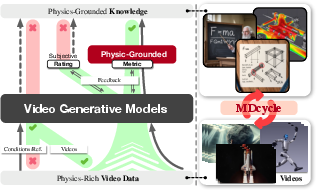
Abstract: Physical principles are fundamental to realistic visual simulation, but remain a significant oversight in transformer-based video generation. This gap highlights a critical limitation in rendering rigid body motion, a core tenet of classical mechanics. While computer graphics and physics-based simulators can easily model such collisions using Newton formulas, modern pretrain-finetune paradigms discard the concept of object rigidity during pixel-level global denoising. Even perfectly correct mathematical constraints are treated as suboptimal solutions (i.e., conditions) during model optimization in post-training, fundamentally limiting the physical realism of generated videos. Motivated by these considerations, we introduce, for the first time, a physics-aware reinforcement learning paradigm for video generation models that enforces physical collision rules directly in high-dimensional spaces, ensuring the physics knowledge is strictly applied rather than treated as conditions. Subsequently, we extend this paradigm to a unified framework, termed Mimicry-Discovery Cycle (MDcycle), which allows substantial fine-tuning while fully preserving the model's ability to leverage physics-grounded feedback. To validate our approach, we construct new benchmark PhysRVGBench and perform extensive qualitative and quantitative experiments to thoroughly assess its effectiveness.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces PhysRVG, a way to teach video-generating AI models to follow real-world physics, especially how solid objects move and collide. The goal is to make AI-made videos look and behave more like reality—for example, balls should bounce correctly, dominoes should collide and fall in believable ways, and objects shouldn’t pass through each other.
What questions did the researchers ask?
The researchers focused on a few simple but important questions:
- How can we make AI-generated videos obey real physical rules, not just look pretty?
- Can we measure, in a clear and objective way, whether the motion in a video follows physics (like gravity and collisions)?
- Can we train video models to improve their “physics sense” using rewards, like how you might train with points in a game?
How did they study it?
To make the explanation accessible, here are the main ideas broken down into everyday terms:
The problem with current video AIs
Modern video AIs (often called “transformers”) mostly learn from lots of video data. They get very good at making videos that look realistic, but they don’t truly understand the rules of physics. That’s why you might see:
- Objects moving in weird, shaky paths
- Unrealistic collisions (objects overlap or stick together)
- Motions that don’t stay consistent over time
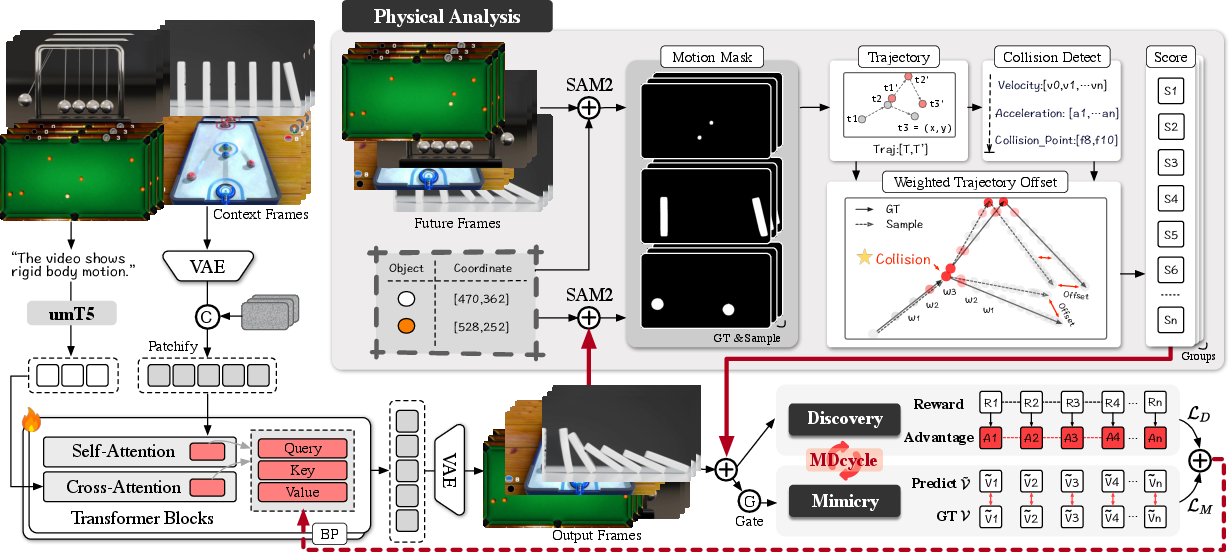
A physics-grounded “reward” system
The team designed a reward system that checks whether the motion in a generated video makes sense physically. It uses two main parts:
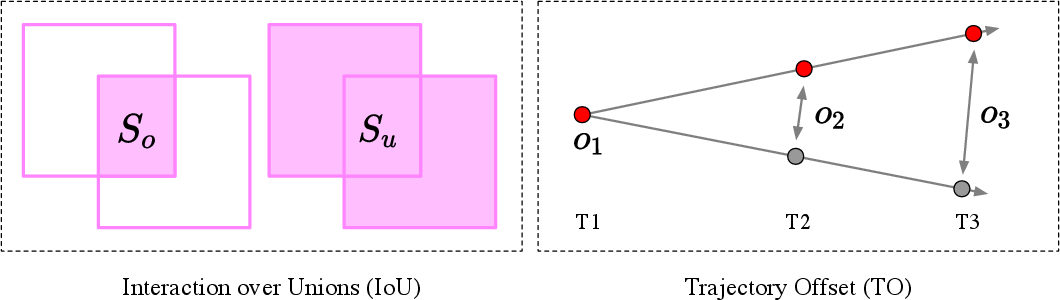
- Trajectory Offset (TO): This measures how far the object’s path in the AI-made video is from the real (ground-truth) path. Think of it like tracing a ball’s center in each frame and comparing the AI’s path to the real path. Smaller TO means more accurate motion.
- Collision Awareness: Collisions are special moments where forces change suddenly. The model gets extra attention (more weight) on frames near collisions so it learns those “critical moments” better. This prevents the model from “cheating” by avoiding complex interactions.
To find the object in each frame, they use a tool (SAM2) that can “mask” the moving object so its center can be tracked easily.
Reinforcement learning: rewarding good physics
They use a type of reinforcement learning (RL) so the model learns by getting better rewards when it follows physics well. In simple terms:
- The model generates several versions of a video from the same input.
- The versions are scored using the physics rules (like TO and collision handling).
- The better versions get rewarded more, and the model adjusts itself to make more of those.
A specific RL technique called GRPO helps by comparing a group of generated samples to each other and rewarding the ones that are more physically correct.
The Mimicry–Discovery Cycle (MD Cycle)
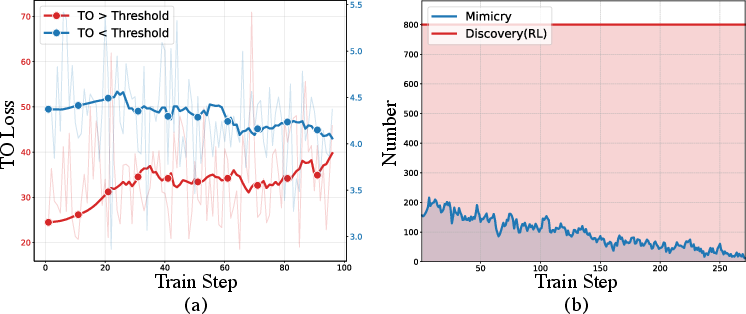
Just using RL can be unstable at the start (the model might not know how to improve yet). So they alternate between two phases:
- Mimicry: The model “copies” the real video at a detailed, pixel level (this stabilizes learning early on).
- Discovery: The model explores and learns physics rules using rewards (this teaches real physical behavior).
They switch between these phases automatically based on how well the model is doing: if it’s far off, do more Mimicry; if it’s close enough, do more Discovery.
A new benchmark to test physics in videos
They built a new test set of about 700 short videos that show four types of motion you see in everyday life:
- Collision
- Pendulum (swinging)
- Free fall (dropping)
- Rolling
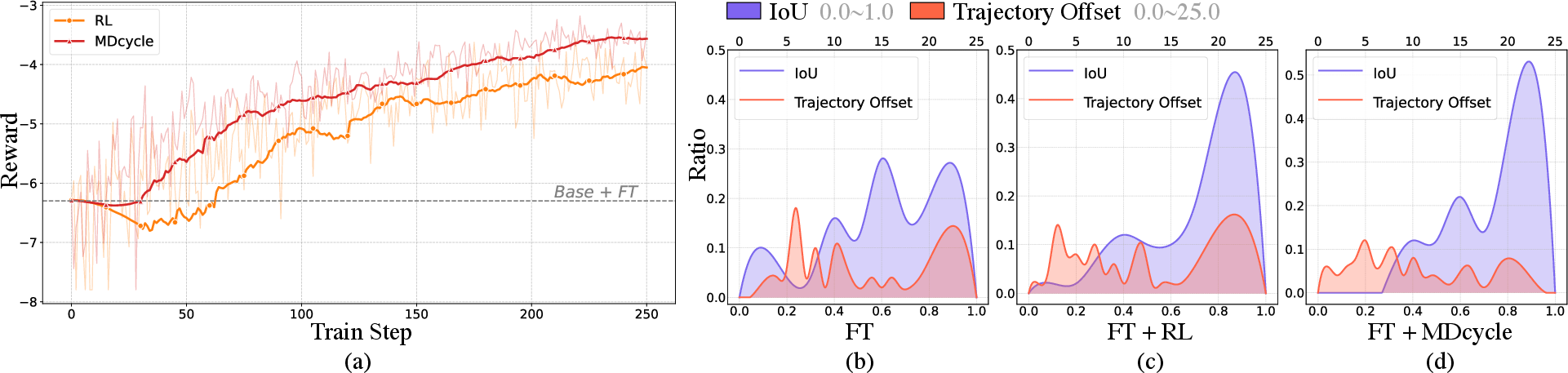
For each video, they track the object and compare the AI’s results to the real motion using two metrics:
- IoU (Intersection over Union): Measures how well the AI’s object area overlaps the real object area in frames.
- TO (Trajectory Offset): Measures how closely the AI’s object follows the real path.
What did they find?
The method improved both the visual quality and the physical correctness of generated videos. Key takeaways:
- PhysRVG produced more realistic rigid-body motion than popular baselines.
- It reduced trajectory mistakes (lower TO) and increased overlap with real motion (higher IoU).
- Video-to-video models (which take a short input clip and extend it) generally learned physics better than text-to-video models (which start from words), and PhysRVG made them even stronger.
- The Mimicry–Discovery Cycle made training more stable and helped the model learn complex events like collisions without “cheating.”
In short, the videos looked good and moved right.
Why does this matter?
When AI-generated videos follow physics, they become more trustworthy and useful. This can help:
- Filmmakers and animators create realistic scenes faster
- Game developers simulate believable interactions
- Educators and researchers build accurate demonstrations and experiments
- Robots or simulation tools learn from videos that reflect the real world
Better physics means fewer “glitches,” more believable motion, and more reliable AI systems overall.
Summary of the main ideas
Here are the most important points:
- PhysRVG teaches video models to obey physics using rewards that measure real motion quality.
- It tracks object paths and focuses learning around collisions.
- It alternates between “copying” real videos for stability and “discovering” physics rules for learning.
- It comes with a new benchmark to fairly test physics in generated videos.
- Results show stronger physics understanding and better motion, not just prettier frames.
This makes AI-made videos both nicer to watch and closer to how the real world actually works.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, uncertainties, and unexplored directions that future work could concretely address.
- Scope restricted to rigid-body motion; no treatment of soft-body dynamics, articulated bodies (e.g., humans), fluids, or deformable contacts.
- Reward captures only 2D center trajectories; orientation, angular velocity, spin, torque, and rotational dynamics are ignored.
- Collision modeling lacks physics parameters (e.g., coefficient of restitution, friction, mass) and cannot distinguish elastic vs. inelastic outcomes.
- Physics-grounded reward relies on ground-truth trajectories, limiting applicability to text-to-video or open-ended generation without reference videos; methods for self-supervised or constraint-based rewards are not provided.
- Collision detection via acceleration spikes is unspecified (thresholds, smoothing, robustness) and may be brittle under noise, occlusion, or camera motion; detailed algorithmic criteria are missing.
- SAM2-based motion masks and first-frame manual annotation are central to reward/evaluation, but failure modes (drift, occlusion, appearance change, small objects) are not quantified; alternative trackers or uncertainty-aware masks are not explored.
- IoU and TO are derived from 2D masks with no camera calibration or metric scaling; physical units, perspective effects, frame-rate normalization, and depth are not incorporated, potentially misaligning measured “physical” error.
- Evaluation ignores camera motion; object trajectories are measured in image coordinates rather than a stabilized or world-referenced frame.
- Reward shaping focuses on collisions only; domain-specific constraints for pendulum periodicity, energy conservation, rolling with friction, or free-fall under gravity (e.g., near-constant acceleration) are not modeled.
- No mechanism to infer or estimate latent physical properties (mass, friction, restitution) from video and use them in rewards or generation.
- MD-cycle thresholding is hand-tuned; there is no adaptive or principled scheduler for switching between Mimicry (FM loss) and Discovery (RL), nor analysis of sensitivity to group size G and credit assignment.
- Temporal credit assignment in RL is episode-level (video-level reward); step-wise or segment-level rewards and algorithms (e.g., TempFlowGRPO) are not integrated for better learning under sparse signals.
- KL regularization details (reference policy choice, coefficient schedule) are under-specified; impact on stability and distributional shift is not analyzed.
- Theoretical justification for the chosen SDE window (e.g., 75–100%) and noise intensity σ is empirical; no analysis of variance, bias, or convergence behavior under different exploration regimes.
- Benchmark is small (≈700 videos; ≈50 for evaluation), with mixed sources (games, online, in-house) that may introduce domain bias; larger, more diverse, and physically annotated datasets are needed.
- Evaluation lacks per-motion-type breakdowns, cross-domain generalization studies (e.g., synthetic-to-real), and correlation analyses between IoU/TO and human or physics expert judgments.
- Scalability to multi-object many-body interactions (e.g., chains of collisions, crowd-like scenes) is untested; N>2 performance and combinatorial contact events are not evaluated.
- Sample efficiency and compute cost of GRPO for video generation (group size, steps, GPU-hours) are not reported; comparisons to PPO or other RL variants are missing.
- Architecture-level physical inductive biases (e.g., equivariance, dynamics modules) are not explored; the approach relies solely on reward shaping without structural grounding.
- Generalization beyond V2V (context-conditioned generation) to T2V/I2V is not demonstrated; methods to enforce physics without ground truth (e.g., via depth/flow estimation, simulator-in-the-loop checks) are absent.
- Long-horizon stability and compounding error analysis are missing; how rewards and MD-cycle behave with longer sequences, multiple collisions, or variable frame rates is unexplored.
- Robustness to segmentation errors in evaluation is not addressed; alternative evaluation protocols (manual annotations, 3D tracking, calibrated setups) are not provided.
- Ethical implications and potential misuse (e.g., generating realistic harmful scenarios) are deferred to the Appendix; concrete safeguards and deployment guidelines are not discussed.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can be implemented now by leveraging the paper’s methods (physics-grounded reward with Trajectory Offset and collision weighting, GRPO-based RL for flow models, and the Mimicry–Discovery Cycle), along with the benchmark and evaluation metrics.
- Physics-consistency QA for video generators
- Sectors: software/AI labs, media, advertising, VFX, academia
- What: Integrate the Physics-Grounded Metric (Trajectory Offset + IoU with SAM2 masks and collision-aware weighting) into continuous evaluation to detect regressions in rigid-body realism across model updates.
- Tools/Workflows: Add an automated “physics check” stage to CI/CD for video models using the provided benchmark and metric computation pipeline.
- Assumptions/Dependencies: Availability of annotated first-frame coordinates and reliable SAM2 masks; evaluation is strongest on rigid-body motions; compute for batched metric computation.
- Post-training recipe for physics-aware V2V generation
- Sectors: media/VFX, game studios, social media content tools, research labs
- What: Fine-tune existing DiT-based video generators on curated rigid-body clips using the Mimicry–Discovery Cycle with GRPO rewards to stabilize training and enforce collisions, rolling, pendulum, and free-fall realism.
- Tools/Workflows: Wrap PhysRVG as a training “recipe” that alternates Flow Matching with GRPO; use hybrid SDE–ODE sampling and collision-weighted rewards.
- Assumptions/Dependencies: Access to motion-rich training clips (or in-domain captures), GPU budget, and prompt/context frames; reward quality hinges on SAM2 segmentation and precise initial point annotation.
- Physics-grounded benchmark adoption for research and benchmarking services
- Sectors: academia, AI benchmarking providers, open-source communities
- What: Use the paper’s benchmark (with IoU/TO) as a standard suite for rigid-body realism comparisons across models and training strategies.
- Tools/Workflows: Publish leaderboards; include the new metrics beside VBench/VideoPhy-2; run ablations on reward weights and SDE intervals as described.
- Assumptions/Dependencies: Benchmark is tailored to rigid bodies; out-of-distribution motions (e.g., deformable/fluids) not covered.
- Safer content filters for physically implausible generations
- Sectors: social platforms, creative tools, enterprise content platforms
- What: Flag or deprioritize videos with excessive trajectory errors (high TO) or inconsistent collision dynamics as low-trust outputs, improving user trust and brand safety.
- Tools/Workflows: A moderation microservice that scores generated clips using the Physics-Grounded Metric and surfaces low-physics outputs for manual review.
- Assumptions/Dependencies: False positives possible when motions are stylized or intentionally non-physical; threshold tuning per domain.
- Educational physics content generation and grading aids
- Sectors: education/EdTech
- What: Generate exemplar clips of rigid-body phenomena (e.g., pendulum, elastic/inelastic collisions) and auto-grade student video experiments via TO and collision-consistency checks.
- Tools/Workflows: Teacher dashboard that synthesizes “ideal” clips and compares student uploads against ground truth trajectories for feedback.
- Assumptions/Dependencies: Cameras and setups must allow robust segmentation and center tracking; grading is most reliable for rigid bodies with clear silhouettes.
- Data augmentation for perception tasks requiring physically plausible motion
- Sectors: robotics, AR/VR, sports analytics, retail logistics (object tracking)
- What: Generate V2V augmentations (future-frame synthesis) that preserve rigid-body kinematics for training trackers, segmenters, and motion predictors.
- Tools/Workflows: Physics-aware augmentation module that expands limited collision/rolling/free-fall data with realistic variants.
- Assumptions/Dependencies: Augmentations are 2D video without interactive forces; translation to 3D or force-grounded labels requires additional modeling.
Long-Term Applications
These use cases are promising but need further research, scaling, or product engineering—e.g., expanding beyond rigid bodies, improving controllability/latency, or integrating with interactive simulators and 3D assets.
- General-purpose physics-grounded video generation (beyond rigid bodies)
- Sectors: media/VFX, gaming, scientific visualization
- What: Extend reward design to soft bodies, fluids, cloth, and multi-body constraints; enforce broader physical laws in generative video.
- Tools/Workflows: New physics-grounded rewards and automatic mask/mesh trackers for deformables; expanded benchmarks.
- Assumptions/Dependencies: Robust segmentation/meshing; reliable verifiable metrics for non-rigid dynamics; greater compute and data diversity.
- Physics-consistent foresight for robotics and autonomous systems
- Sectors: robotics, autonomous driving, warehouse automation
- What: Use physics-aware video forecasters to predict scene evolution under interactions (collisions, drops) to inform planning/safety.
- Tools/Workflows: Closed-loop perception–prediction modules trained with GRPO-like verifiable rewards; integration into simulation and policy stacks.
- Assumptions/Dependencies: Real-time constraints; bridging from 2D video to 3D state and controllable actions; rigorous safety validation.
- Interactive AR/VR editors that “snap” generative edits to physical laws
- Sectors: AR/VR, creative software, mobile devices
- What: Real-time object insertions/edits that auto-adjust trajectories and collisions to remain physically plausible during user manipulation.
- Tools/Workflows: On-device fast V2V with lightweight reward priors or distilled physics filters; UI affordances for constraints (e.g., mass, coefficient of restitution).
- Assumptions/Dependencies: Latency/compute on edge devices; robust real-time tracking and scene understanding; intuitive controls.
- Procedural content generation for games with physics guarantees
- Sectors: gaming
- What: Generate cutscenes, replays, or environmental events where the motion adheres to Newtonian constraints, reducing hand-authoring.
- Tools/Workflows: Engine plugins that condition V2V/T2V on game states and validate outputs via physics-aware rewards; authoring tools that expose physical parameters.
- Assumptions/Dependencies: Tight coupling with engine physics; control interfaces to map game state to generative conditions; certification of consistency.
- Physics-based authenticity checks for forensic analysis and policy compliance
- Sectors: policy/regulation, media forensics, insurance
- What: Use physics-consistency scores to assist deepfake detection and claims validation (e.g., implausible crash dynamics, impossible trajectories).
- Tools/Workflows: Forensic toolkits that score clips via TO/collision signals and produce explainable diagnostics (e.g., acceleration spikes without contact).
- Assumptions/Dependencies: Adversarial robustness; court-admissible methodologies; domain calibration for camera artifacts and scene geometry.
- Digital twins and industrial monitoring from video
- Sectors: manufacturing, energy, logistics
- What: Synthesize or validate video of component motions (rollers, ball bearings, pendulums in meters) to detect anomalies vs. physics-consistent baselines.
- Tools/Workflows: Monitoring dashboards using physics-aware generative “what-if” scenarios and deviation scoring.
- Assumptions/Dependencies: Mapping 2D trajectories to 3D states; accurate calibration; integration with sensor data; safety-critical certification.
- Biomechanics and clinical motion analysis with physics priors
- Sectors: healthcare, sports medicine, rehabilitation
- What: Physics-aware video synthesis and evaluation to support gait/posture analysis, fall-risk simulations, or therapy feedback with realistic kinematics.
- Tools/Workflows: Clinics use physics-scored video assessments; synthetic exemplars for patient education and model training.
- Assumptions/Dependencies: Human bodies are not rigid; requires domain-specific rewards and anatomical constraints; privacy and regulatory compliance.
- Insurance and finance risk analytics from video evidence
- Sectors: finance/insurance
- What: Triage claims using physics-consistency scoring for collisions, drops, and impacts to prioritize investigations.
- Tools/Workflows: Claims intake systems with automated physics plausibility checks and explainable reports; integration with adjuster workflows.
- Assumptions/Dependencies: Domain adaptation to varied capture conditions; explainability; legal standards; careful handling of uncertainty.
- Physics-aware video editing assistants
- Sectors: creator economy, marketing
- What: Tools that suggest corrections to edited motion (e.g., fixing a thrown object’s trajectory) or generate B-roll with consistent dynamics.
- Tools/Workflows: Editor plugins that apply a “physics pass” using Mimicry–Discovery-trained models and display per-frame deviation overlays.
- Assumptions/Dependencies: UX design for non-expert users; controllability for artistic intent vs. realism trade-offs; compute cost on desktops.
- Standards and audits for generative model safety
- Sectors: policy, standards bodies, enterprise AI governance
- What: Define physics-realism minimums for certain applications (e.g., educational content, safety demos) and audit models with verifiable rewards rather than subjective ratings.
- Tools/Workflows: Compliance checklists and audited test suites based on the paper’s metrics and benchmark; reporting of IoU/TO thresholds.
- Assumptions/Dependencies: Community consensus on thresholds; extension beyond rigid bodies; periodic updates as models and metrics evolve.
In all cases, feasibility hinges on several cross-cutting dependencies: reliable object segmentation and tracking (SAM2 or successors), availability of motion annotations (at least first-frame centers), suitability of rigid-body assumptions to the target domain, compute resources for RL fine-tuning, and careful tuning of reward weights and SDE–ODE sampling for stability.
Glossary
- Advantage: An RL signal estimating how much better a sample performs relative to others under the same condition. "GRPO estimates the advantage value for each sample by comparing it against other samples within the same group."
- Brownian motion: A stochastic process modeling random motion, used as the noise term in SDE formulations. "and w represents standard Brownian motion."
- Collision detection: Identifying collision events in motion to guide training and evaluation. "We then compute object trajectories P and perform collision detection."
- Conditional alignment: Aligning generated outputs with conditioning inputs (e.g., text, context frames) during training. "discard essential spatio-temporal physical cues during conditional alignment and feature extraction"
- Credit assignment: The RL challenge of attributing rewards to specific actions or timesteps. "leverage the intrinsic temporal structure of flow-based models and address uneven credit assignment under sparse rewards."
- DiT (Diffusion Transformer): A transformer-based architecture for diffusion-style generative modeling. "DiT-based video generative models reconstruct noisy videos in latent space using Flow Matching loss"
- Exploration noise: Stochastic perturbations added during sampling to encourage exploration. "converting ODE sampling into equivalent SDE sampling and adding tunable exploration noise."
- Flow Matching: A training objective that predicts a velocity field to transform noise into data via linear interpolation. "Flow Matching treats generation as a denoising process from noise to data."
- GRPO (Group Relative Policy Optimization): An RL algorithm that uses group-relative advantages and avoids training a separate value model. "Compared to PPO, GRPO is more efficient because it does not require training a separate value model."
- Hybrid ODE–SDE sampling: A strategy that mixes deterministic ODE steps with stochastic SDE steps to balance stability and exploration. "MixGRPO proposes a hybrid ODE-SDE strategy."
- Importance sampling ratio: A likelihood ratio used to correct policy evaluation bias when using samples from an older policy. "serves as an importance sampling ratio, correcting for the bias of evaluating the current policy using data generated by an older one."
- Intersection over Union (IoU): A spatial overlap metric between predicted and ground-truth masks. "we compute two key evaluation metrics, Intersection over Union (IoU) and Trajectory Offset (TO)"
- I2V (Image-to-Video): A generation paradigm that synthesizes videos from a single image input. "I2V models"
- Kullback–Leibler divergence (KL): An information-theoretic measure used as a regularizer in policy optimization. "The D_{KL} term acts as a regularizer to promote training stability."
- Latent space: A compressed representation space where models perform denoising and reconstruction. "reconstruct noisy videos in latent space using Flow Matching loss"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method using low-rank adapters. "PEFT such as LoRA"
- Markov Decision Process (MDP): A formal model for sequential decision-making with states, actions, transitions, and rewards. "formulates the denoising process as a Markov Decision Process(MDP)."
- Mimicry–Discovery Cycle: A training framework alternating supervised mimicry with RL-based discovery to stabilize and improve physics-aware learning. "Mimicry-Discovery Cycle ()"
- Motion mask: A segmentation mask sequence capturing the moving object across frames. "derive motion masks M by prompting SAM2"
- ODE (Ordinary Differential Equation): A deterministic differential equation used to describe denoising trajectories. "the ODE governing the Flow Matching denoising trajectory"
- PEFT (Parameter-Efficient Fine-Tuning): Techniques that fine-tune models by updating a small subset of parameters. "PEFT such as LoRA"
- PPO (Proximal Policy Optimization): A policy-gradient RL algorithm with a clipped objective for stable updates. "optimizes the model with Proximal Policy Optimization(PPO)"
- RLHF (Reinforcement Learning from Human Feedback): Training paradigm using human rankings/preferences as feedback signals. "RLHF uses human ranking and preferences as feedback"
- Reward hacking: Exploiting a reward function to achieve high scores while failing the intended behavior. "Optimizing the model only with the offset ... causes reward hacking, where it favors simple linear motions and avoids complex collisions"
- Rigid body motion: Motion of non-deforming objects governed by Newtonian mechanics. "we focus on Rigid Body Motion as the core representation of physical behavior."
- SAM2 (Segment Anything Model 2): An interactive segmentation model used to obtain motion masks. "by prompting SAM2 with object coordinates p_1 from the first frame"
- SDE (Stochastic Differential Equation): A differential equation incorporating stochastic noise for sampling/exploration. "the ODE governing the Flow Matching denoising trajectory can be convert to SDE while preserving the same marginal distributions"
- Temporal weight: Per-frame weighting used to emphasize critical moments such as collisions in the reward. "a temporal weight w_t is assigned to each frame t"
- Trajectory Offset (TO): A metric measuring average deviation between generated and ground-truth object trajectories. "Intersection over Union (IoU) and Trajectory Offset (TO)"
- V2V (Video-to-Video): A generation paradigm that conditions on past frames to synthesize future frames. "adapt it to V2V in the first stage."
- Velocity field: A vector field defining the velocity at each point, predicted by the model in Flow Matching. "A generative model is trained to predict the velocity field v = x_1 - x_0."
- VBench: A benchmark suite evaluating visual fidelity of video generative models. "We adopt VBench to evaluate visual fidelity"
- VideoPhy-2: A benchmark focusing on physical realism and action-centric dynamics in generated videos. "VideoPhy-2 to evaluate physical realism in generated videos."
- Weighted trajectory offset: The trajectory offset reweighted by temporal collision signals, used as the reward. "Finally, the weighted trajectory offset is expressed as:"
Collections
Sign up for free to add this paper to one or more collections.