Inference-time Physics Alignment of Video Generative Models with Latent World Models
Abstract: State-of-the-art video generative models produce promising visual content yet often violate basic physics principles, limiting their utility. While some attribute this deficiency to insufficient physics understanding from pre-training, we find that the shortfall in physics plausibility also stems from suboptimal inference strategies. We therefore introduce WMReward and treat improving physics plausibility of video generation as an inference-time alignment problem. In particular, we leverage the strong physics prior of a latent world model (here, VJEPA-2) as a reward to search and steer multiple candidate denoising trajectories, enabling scaling test-time compute for better generation performance. Empirically, our approach substantially improves physics plausibility across image-conditioned, multiframe-conditioned, and text-conditioned generation settings, with validation from human preference study. Notably, in the ICCV 2025 Perception Test PhysicsIQ Challenge, we achieve a final score of 62.64%, winning first place and outperforming the previous state of the art by 7.42%. Our work demonstrates the viability of using latent world models to improve physics plausibility of video generation, beyond this specific instantiation or parameterization.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
The paper tackles a common problem in AI-made videos: they often look cool but break basic rules of physics (things pass through each other, move weirdly, liquids act wrong, etc.). The authors show a way to fix this without retraining the big video model. Instead, they add a smart “judge” during video creation that rewards videos that behave more like the real world. This makes the final videos follow physics better.
What questions did the researchers ask?
They focused on three easy-to-understand questions:
- Can we make AI-generated videos obey physics more by changing how we generate them (at “inference time”), instead of retraining the whole model?
- Is a “world model” that predicts what happens next in a video a good judge of whether a video follows physics?
- If we try more options and pick the best (or gently nudge the model as it draws), do we get videos that look more physically correct?
How did they do it?
Think of video generation like drawing a whole video from random noise, one step at a time. The team adds a judge that checks whether each candidate video makes physical sense.
The judge: a world model that predicts the future
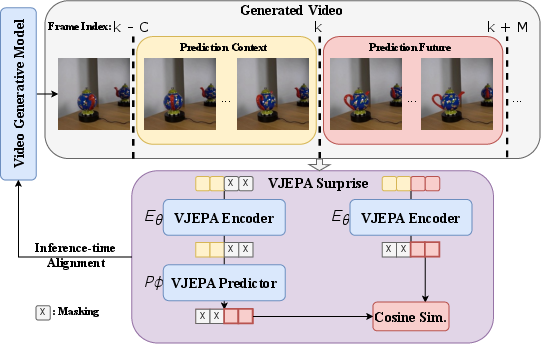
- They use a model called VJEPA-2 (you can think of it as a “world model”) that watches a few frames and predicts what the next frames should look like.
- It doesn’t care about tiny pixel details; it works with a compact “summary” of the video (a latent representation), which helps it focus on motion, objects, and cause-and-effect.
The score: “How surprising is this future?”
- Slide a window across the generated video:
- Feed the judge some context frames (what it has seen).
- Ask it to predict the next few frames (what should happen next).
- Compare the judge’s prediction to what the video model actually generated.
- If the judge’s prediction and the generated future are close, the video likely follows physics; if they’re very different, the video is suspicious.
- This comparison becomes a “surprise score” (low surprise = good physics). The paper flips that into a reward so higher is better.
Two simple ways to use the score
To make use of the judge’s reward, the authors try two practical strategies:
- Best-of-N (try a bunch, pick the best):
- Generate N different videos (by changing random seeds).
- Score them with the judge.
- Keep the one with the best physics score.
- Analogy: take many photos and keep the sharpest one.
- Guidance (gently nudge while drawing):
- As the video is being generated step by step, use the judge’s score to nudge the process toward futures that make more physical sense.
- Analogy: a coach giving small hints during a performance.
- Combo: Guidance + Best-of-N
- Use guidance to make each candidate better, then still pick the best among several candidates.
These methods don’t change the original video model’s weights; they only change how you sample and select at generation time.
What did they find, and why is it important?
Here are the main takeaways:
- Big jump in physics realism:
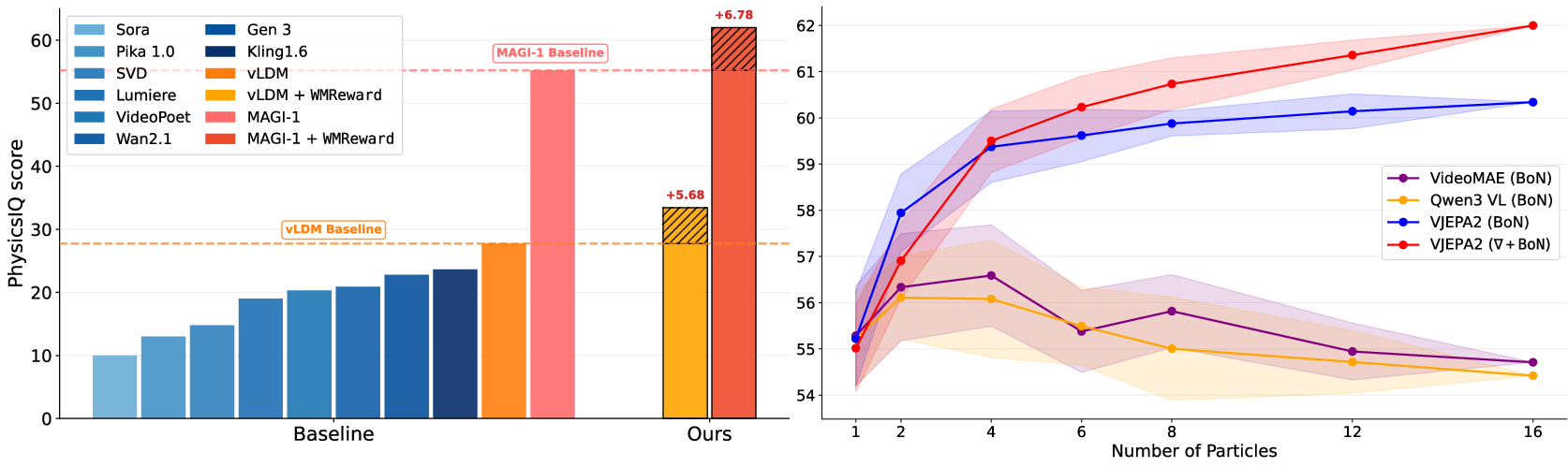
- On a tough benchmark called PhysicsIQ (tests video continuations with real-world motion), their method reached about 62.6%—good enough for first place—and beat the prior best by roughly 7 percentage points.
- On another test (VideoPhy for text-to-video), they improved “physics consistency” while keeping overall quality solid.
- People preferred the results:
- In careful human studies, viewers chose the new method’s videos more often for physics realism, and often for visual quality too, with double-digit gains in some settings.
- World-model judge beats other judges:
- Using the VJEPA-2 “future predictor” as a judge worked better than using a vision-LLM (VLM) or a pixel-reconstruction model as the reward. Predicting the future in a compact representation seems better at spotting physics violations.
- More tries = better results:
- Trying more candidates (larger N) and/or adding guidance steadily improved scores. In other words, spending more compute at test time pays off.
- Quality stays good (and sometimes improves):
- Automatic metrics for visual quality (like smooth motion, consistency, and aesthetics) stayed the same or got a bit better. Making physics more consistent often makes videos feel more natural and less glitchy.
- Trade-offs:
- This approach uses extra compute at generation time. Best-of-N grows roughly linearly with how many candidates you try. Guidance adds some memory and time (because it needs gradients). But you can dial the budget up or down depending on how good you want the result to be.
What this could mean for the future
- Better videos without retraining: You can add physics sense to existing video generators just by changing how you generate, not by rebuilding the model from scratch.
- World models as reliable judges: Models that learn to predict the future (not just label images) are promising “referees” for physical realism, which could help in robotics, simulations, education, and autonomous systems.
- Scales with compute: If you can afford to try more candidates or add guidance, you can likely keep pushing physics quality higher.
- Next steps:
- Stronger judges: train world models that understand more physics (like friction, material weight, or complex fluids).
- Smarter search: make the “try and nudge” process more efficient.
- Physics + meaning: combine the physics judge with a text-aware judge so the video both follows the laws of physics and matches the prompt perfectly.
In short, the paper shows a practical recipe: give your video generator a physics-savvy coach at generation time, try a few options, nudge the process in the right direction, and pick the best. The result is videos that look not just pretty—but believable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, written to be concrete and actionable for future work.
- Reward model coverage: VJEPA-2’s physics understanding is limited for material properties (e.g., mass, friction, stiffness), leading to failures in contact-rich scenes; develop or fine-tune latent world models to encode such parameters and test on targeted benchmarks.
- Text-agnostic reward: The surprise-based reward ignores prompt semantics, causing drops in semantic adherence in T2V; design compositional rewards that jointly enforce physics and text alignment (e.g., conditional predictors, text-conditioned latent world models).
- Long-horizon dynamics: The sliding-window reward uses short prediction horizons; study larger horizons and hierarchical forecasting to penalize violations accumulating over longer videos (e.g., >10–30 seconds).
- Camera motion and occlusions: Robustness to strong camera motion, occlusion patterns, and rapid viewpoint changes is not characterized; evaluate and adapt the reward to handle these (e.g., invariant encoders, motion-debiased predictors).
- Domain shift: Generalization to out-of-distribution content (e.g., unusual materials, non-terrestrial physics, stylized or synthetic worlds) is untested; measure performance under domain shift and train reward models with diverse physics data.
- Reward-model choice: The approach is centered on VJEPA-2; systematically compare different latent world models and architectures (beyond ViT-huge/giant) and identify properties that predict reward effectiveness.
- Reward hacking risk: Generators could exploit latent “feature matching” without truly obeying physics; devise adversarial tests and countermeasures (e.g., multi-reward ensembles, causal probes, out-of-sample prediction checks).
- Theoretical guarantees: Guidance relies on approximations (e.g., Tweedie’s estimate for x0|t and E[e{λr(x0)}|xt] ≈ e{λr(E[x0|xt])}); quantify approximation error and derive bounds or improved estimators (e.g., conditional MC, variance-reduced estimators).
- Early-step noise: Reward estimates early in denoising are unreliable due to blurry x0|t; explore dynamic guidance schedules, late-stage-only guidance, and confidence-weighted reward injection.
- Compute–performance tradeoffs: Scaling with particles N improves scores but increases cost linearly; develop compute-optimal strategies (adaptive N, early-stopping, bandit selection, progressive widening).
- Memory constraints: Guidance increases memory footprint ×2–4; engineer memory-efficient reward computation (e.g., gradient checkpointing, low-rank adapters, distilling smaller reward proxies).
- Search algorithms: SMC/SVDD underperform BoN+guidance; investigate hybrids (e.g., stage-wise resampling with guided proposals), better importance weights, and parallelizable resampling without trajectory collapse.
- Reward scheduling: No principled method to choose λ, window size, stride, and FPS; create auto-tuning schemes that set these per prompt/model under a compute budget.
- Multi-object interactions: Performance in complex multi-body scenes (stacking, sliding, rolling, deformables) is not dissected; design fine-grained tests and per-phenomenon metrics.
- Fluid dynamics fidelity: Improvements are reported, but physical fidelity (e.g., viscosity, incompressibility, splash statistics) is not quantitatively validated; add physics-based diagnostics beyond VLM scoring.
- 3D geometry and metric consistency: The reward operates in 2D latent space; assess 3D consistency (depth, metric stability) and extend rewards with 3D predictors or multi-view latent world models.
- Integration with training: Only inference-time alignment is explored; test training-time alignment (RL/fine-tuning) using the reward to reduce compute at inference and improve base model physics.
- Cross-model generalization: Results are for MAGI-1 and vLDM; evaluate across more architectures (transformer decoders, autoregressive diffusers, flow-matching) and model scales/resolutions.
- Benchmark breadth: PhysicsIQ and VideoPhy capture limited phenomena; expand to standardized suites (e.g., rigid body collisions, elasticity, granular flows, articulated motion) with ground-truth physical measurements.
- Evaluation reliability: VideoPhy relies on VLM scoring; validate with human studies at larger scale, inter-rater agreement, and physics engine-derived references to reduce evaluator bias.
- Human preferences: Studies involve five annotators and modest sample sizes; report statistical significance, rater consistency, and analyze failure modes to strengthen conclusions.
- Failure taxonomy: Provide systematic categorization (e.g., non-conservation, interpenetration, trajectory discontinuity, implausible acceleration) to guide targeted improvements.
- Reward locality: Surprise is averaged over windows uniformly; study spatial/temporal weighting to focus on physically critical events (contacts, impacts, phase changes).
- Temporal chunking mismatch: MAGI-1 generates chunk-by-chunk; assess how chunk boundaries affect reward reliability and introduce cross-chunk continuity penalties.
- Real-time constraints: High overhead (e.g., ×N time) limits deployment; explore lightweight reward surrogates, early-exit strategies, or distillation to a fast critic.
- Adaptive inference: Static search budgets may be wasteful; implement prompt-conditioned or online adaptive budgets that stop when confidence thresholds are met.
- Safety and misuse: No discussion of safety implications (e.g., producing misleading physically plausible yet semantically incorrect videos); define safeguards and auditing protocols.
- Compositional controls: It is unclear how to balance physics plausibility with other desiderata (style, narrative, action pacing); design multi-objective alignment with user-tunable trade-offs.
- Robust hyperparameters: Although some robustness is shown, sensitivity to stride, FPS, and window size across datasets/prompts is incomplete; provide principled defaults and sensitivity curves.
- Longer videos and continuity: Experiments focus on ~5 s continuations; test performance for long videos with multi-scene transitions and memory of past events.
- Audio-visual coupling: Physics plausibility in audio (impacts, splashes) is ignored; extend rewards to multimodal predictors to align sound with physical events.
- Open-source reproducibility: Details for exact implementations (e.g., VJEPA-2 configs, feature normalization, guidance schedules) should be released to facilitate replication and ablation.
Glossary
- Autoregressive video generative model: A sequence model that produces video frames step-by-step conditioned on previously generated content. "MAGI-1~\citep{magi1}, a large-scale autoregressive video generative model which generates videos chunk-by-chunk,"
- Best-of-N (BoN): A search strategy that generates N candidates and selects the one with the highest reward or score. "as a Best-of- (BoN) selector and as a guidance signal during generation to improve the physics of videos."
- Conditional flow matching: A training approach that learns to transform noise into data by matching conditional flows between distributions. "or conditional flow matching \cite{lipman2023flow}."
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "compute the cosine similarity between its embedding and the latent world model prediction, referred to as surprise score."
- Cumulative distribution function (CDF): The function that gives the probability a random variable is less than or equal to a value. "where is the cumulative distribution function (CDF) of under "
- Denoising score matching: A method to learn the gradient of the log-density (score) by training a denoiser on noisy inputs. "This score is learned using either denoising score matching \cite{vincent2011connection}"
- Denoising trajectories: The sequences of intermediate states during sampling as noise is progressively removed. "search and steer multiple candidate denoising trajectories, enabling scaling test-time compute for better generation performance."
- DiT backbone: A Diffusion Transformer architecture used as the core network for diffusion-based generation. "vLDM is a latent video diffusion model that utilizes a DiT backbone and jointly models spatial and temporal components at once."
- Exponentially-moving-averaged (EMA) encoder: A target network updated by exponential moving average of parameters for stable representation learning. "The target is computed using an exponentially-moving-averaged (EMA) encoder applied to the full video."
- Guidance (∇): A gradient-based steering method that modifies the sampling score using a differentiable reward. "Guidance () uses "
- Joint-Embedding-Predictive-Architecture (JEPA): A self-supervised framework that learns representations by predicting embeddings of masked regions. "video SSL approaches based on the Joint-Embedding-Predictive-Architecture (JEPA)~\citep{bardes2024vjepa,vjepa2} exhibit the highest performance among predictive methods."
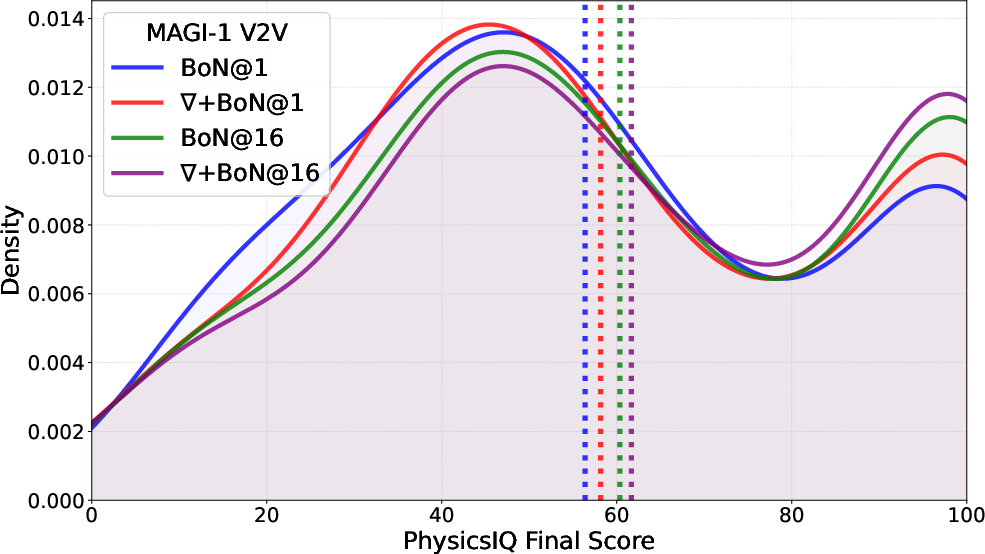
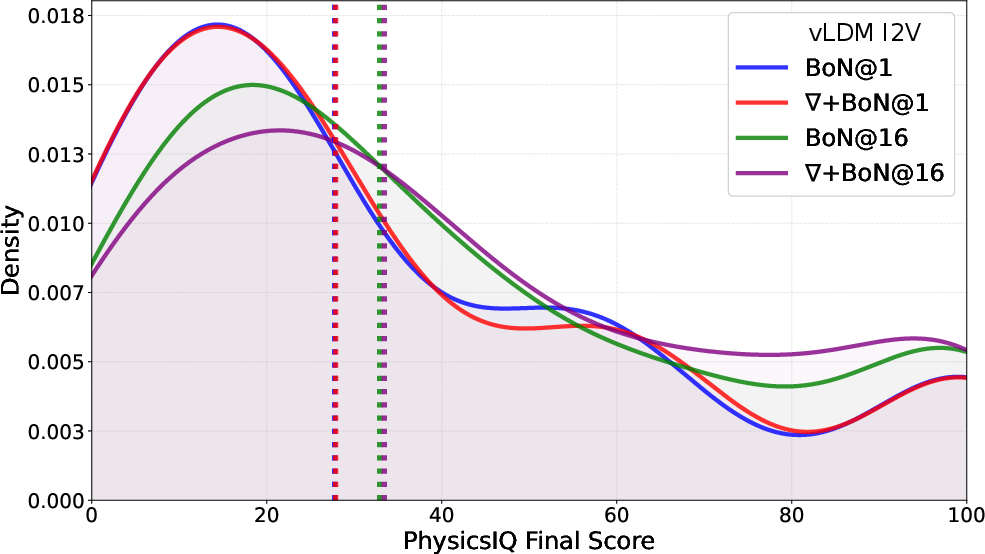
- Kernel density estimate (KDE): A nonparametric technique to estimate the probability density function of a random variable. "Visualization of PhysicsIQ score distributions with a Gaussian KDE"
- Latent video diffusion model (vLDM): A diffusion model that generates videos in a compressed latent space rather than pixel space. "vLDM is a latent video diffusion model that utilizes a DiT backbone and jointly models spatial and temporal components at once."
- Latent world model: A predictive model that encodes observations into latent representations and learns transitions to forecast future states. "A latent world model is a predictive model that encodes high-dimensional observations (e.g., videos) into compact latent representations"
- Manifold: The learned high-dimensional space of plausible data configurations produced by a generative model. "physically plausible videos may be found in the manifold learned by the generative model"
- Masked predictive objective: A training objective where parts of the input are masked and the model predicts their representations. "trained on Internet-scale data with a masked predictive objective in the representation space."
- Ordinary differential equation (ODE): A continuous-time equation used to define the deterministic sampling path in diffusion models. "we can construct an SDE or ODE whose marginals depend only on , , and the learned score."
- PhysicsIQ benchmark: An evaluation suite measuring physics plausibility and accuracy of video continuations. "we achieve a new state of the art on the challenging PhysicsIQ benchmark"
- Predictor network: The component that reconstructs target latent representations from context in predictive models. "The architecture comprises a context encoder that embeds video frames, and a predictor network that reconstructs target representations from partial observations."
- Reward model: A model that assigns a scalar score indicating desirability (e.g., physics plausibility) to guide generation. "they are ideally suited to serve as reward models for physics plausibility."
- Score function: The gradient of the log-probability density used to define the reverse-time dynamics in diffusion. "score functions "
- Self-supervised learning: Training without labeled data by solving pretext tasks derived from the input itself. "One approach for training such models relies on self-supervised learning;"
- Sequential Monte Carlo (SMC): A particle-based inference method that maintains weighted samples and resamples based on importance. "SMC-based approaches~\citep{singhal2025smc,wu2023practical} assign importance weights to multiple denoising trajectories and perform resampling during generation."
- Sliding window approach: A method that processes sequences by moving a fixed-size window over time to define context and prediction segments. "During generation, we apply a sliding window approach and split the generative model's output into sets of context and future frames."
- Stochastic differential equation (SDE): A continuous-time stochastic equation defining the noisy sampling path in diffusion models. "we can construct an SDE or ODE whose marginals depend only on , , and the learned score."
- Stop-gradient: An operation that prevents gradients from flowing through a computation path during training. "where denotes the stop-gradient operation, preventing gradients from flowing through the target."
- Surprise score: A measure of mismatch between predicted latent future and generated future used as a reward for physics plausibility. "compute the cosine similarity between its embedding and the latent world model prediction, referred to as surprise score."
- SVDD: A value-based importance-sampling method that steers a single trajectory by local reward-driven resampling. "Value-based importance sampling methods, such as SVDD~\citep{li2024svdd}, steer a single trajectory by resampling according to the local step reward."
- Tilted distribution: A reweighted target distribution that biases sampling toward high-reward regions. "sampling from a reward-weighted tilted distribution:"
- Tweedie’s formula: An identity linking posterior means to noisy observations and score functions, used to approximate guided sampling. "and using Tweedie's formula"
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs for tasks like understanding and generation. "two contributions relying on vision-LLMs (VLMs) to rewrite prompts"
- VJEPA-2: A specific video JEPA latent world model known for strong physics understanding. "VJEPA-2~\citep{vjepa2} is a latent world model"
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating the paper’s inference-time physics alignment (WMReward) into existing video-generation workflows, with compute-aware trade-offs via Best-of-N (BoN) search and optional gradient guidance.
- Production video generation with a “physics slider”
- Sectors: Media/entertainment, advertising, social/UGC, gaming
- What: Add WMReward(BoN) and optional guidance to current text-to-video (T2V), image-to-video (I2V), and video-to-video (V2V) pipelines to reduce physics errors (e.g., object permanence, collision handling, fluid behavior), improving viewer trust and satisfaction.
- Workflow/tools: Inference-time plugin/SDK wrapping MAGI-1/vLDM or similar; expose a “Physics” control (λ, N) in the UI; autoscale N for complex prompts; default to BoN for cost-efficiency, enable guidance for premium outputs.
- Assumptions/dependencies: Access to a latent world model (e.g., VJEPA-2 weights); added GPU time/memory; licensing/compliance for the reward model; base model must contain plausible trajectories in its manifold.
- Automated physics-quality gate and reranking
- Sectors: Media platforms, creative studios, enterprise content operations
- What: Use WMReward to score candidate videos and rerank/select the most plausible output; reject or resample videos below a physics threshold.
- Workflow/tools: Batch BoN reranking service; acceptance thresholds tuned with PhysicsIQ/VideoPhy; dashboards for QC; human-in-the-loop override.
- Assumptions/dependencies: Thresholds require domain calibration; higher compute for multiple candidates; trade-off with prompt adherence.
- Previsualization and VFX shot planning
- Sectors: Film/TV, advertising, interactive experiences
- What: Generate more believable pre-viz clips for complex motion, crowds, liquids, and object interactions.
- Workflow/tools: N=8–16 BoN for explorations; targeted guidance on key shots; integrate with existing DCC tools (e.g., as a Houdini/Nuke/Unreal plugin).
- Assumptions/dependencies: Not a substitute for physics solvers in final shots; guidance gradients can be noisy early in denoising—use later-stage guidance or BoN.
- Synthetic data generation for perception tasks
- Sectors: Robotics, autonomous systems, surveillance, industrial inspection
- What: Produce more physically plausible synthetic videos to pretrain or augment perception models (object tracking, motion segmentation, collision cues).
- Workflow/tools: WMReward(BoN) to filter generations; optional VBench/PhysicsIQ as additional validators; seed-archiving for reproducibility.
- Assumptions/dependencies: Domain gap persists; not a simulator; validate downstream impact with ablations; avoid using for policy training directly.
- Rare-event scenario generation for perception evaluation
- Sectors: Autonomous driving, drones, warehouse robotics
- What: Create physically plausible corner cases (e.g., occlusions, sudden stops) for stress-testing perception stacks.
- Workflow/tools: Prompt libraries + BoN; scenario-specific acceptance gates; metadata logging of reward and seeds.
- Assumptions/dependencies: Do not use as an engineering-grade simulator; complement, not replace, validated simulators.
- Physics-aware educational content and micro-labs
- Sectors: Education/EdTech
- What: Generate videos that illustrate physics principles (ballistic motion, conservation of mass/continuity, elastic/inelastic collisions) with fewer visual fallacies.
- Workflow/tools: Teacher-facing generator with preset λ/N profiles; human review loop; tagging for curriculum alignment.
- Assumptions/dependencies: Reward covers intuitive, not domain-specific, physics; human vetting recommended for classroom use.
- Product demos and explainer videos with plausible motion
- Sectors: E-commerce, marketing
- What: Demonstrate plausible material behavior (fabric drape, liquid pour, basic impacts) to reduce uncanny artifacts.
- Workflow/tools: Batch BoN generation for shotlists; QC gates; export presets per platform (TikTok/Instagram/YouTube).
- Assumptions/dependencies: Not engineering accurate (e.g., stress/strain, CFD); include disclaimers where physical performance matters.
- Content moderation and misinformation triage
- Sectors: Online platforms, trust & safety
- What: Triage videos exhibiting strong physics implausibility (via surprise scores) for review.
- Workflow/tools: Threshold-based flags; combine with other detectors (faces, watermarks, provenance); triage dashboards.
- Assumptions/dependencies: Fantasy/animation domains will trigger false positives; domain-aware thresholds and whitelisting needed.
- Developer tooling for compute-aware inference
- Sectors: Software platforms, MLOps
- What: Auto-tune N and λ by prompt difficulty; schedule BoN/guidance runs to stay within GPU SLOs; cache reward computations across frames/windows.
- Workflow/tools: Orchestrators that expand search for hard prompts; microservice for reward scoring; mixed-precision/backprop scheduling.
- Assumptions/dependencies: Effective resource management; reward cost scales with number of windows and guidance steps.
- Post-hoc repair of legacy generations
- Sectors: Creative studios, archival content owners
- What: Re-generate from stored seeds/latents and rerank with WMReward to replace physics-implausible outputs.
- Workflow/tools: Seed catalog + BoN; A/B visual diff and human approval; versioning and audit logs.
- Assumptions/dependencies: Requires stored seeds/latents or reproducible runs; compute availability for reprocessing.
- Research benchmarking and reproducibility
- Sectors: Academia, industrial research
- What: Use WMReward to study inference-time alignment, search scaling laws, and fairness/robustness in physics-aware generation.
- Workflow/tools: PhysicsIQ/VideoPhy evaluation; open recipes with BoN and guidance; ablations over window sizes, horizons, strides.
- Assumptions/dependencies: Access to evaluation datasets; consistent hardware for time/memory comparisons.
Long-Term Applications
These opportunities require further research (e.g., improved reward models, tighter coupling with semantics, efficiency gains) and/or scaling.
- Physics-guided, real-time generation for AR/VR and interactive tools
- Sectors: AR/VR, gaming, design tools
- What: Low-latency physics-aware video/scene synthesis for interactive previews or prototyping.
- Dependencies: Efficient/distilled reward models; on-device or edge inference; streaming guidance; better early-step gradient estimates.
- Closed-loop robot learning with video world-model rewards
- Sectors: Robotics, embodied AI
- What: Use WMReward-like signals for video rollouts to shape policy learning or planning under uncertain dynamics.
- Dependencies: Stronger domain-specific world models; safety guarantees; coupling with real robot feedback; beyond perception-only data.
- Safety-critical simulation and digital twins
- Sectors: Healthcare (surgical training), manufacturing, aerospace
- What: Physics-aligned generation as a visualization front-end to validated simulators, improving training and communication.
- Dependencies: Verified, domain-calibrated reward models (biomechanics, fluid/structural dynamics); formal validation; regulatory approvals.
- Platform-scale misinformation detection via physics anomaly scoring
- Sectors: Policy, trust & safety, public sector
- What: Use physics surprise at scale to rank content for fact-checking and policy enforcement (e.g., disaster deepfakes).
- Dependencies: Domain calibration across genres; minimizing bias; governance for appeals and transparency; robust adversarial resistance.
- Standards and audits for AI-generated video plausibility
- Sectors: Policy/regulation, media compliance, advertising standards
- What: Define audit trails (λ, N, reward distributions), minimum physics plausibility thresholds for labeled “realistic” claims, procurement guidelines.
- Dependencies: Multi-stakeholder consensus; benchmarks covering domain diversity; watermarking/provenance integration.
- Compositional multi-reward guidance (physics + semantics + safety)
- Sectors: General video AI platforms
- What: Orchestrate multiple differentiable rewards (physics, prompt adherence, content safety, aesthetics) at inference time.
- Dependencies: Stable multi-objective optimization; text-conditioned physics rewards; conflict resolution and tuning tools.
- Physics-aware video editing and inpainting
- Sectors: Creative tooling, post-production, mobile apps
- What: Edit trajectories (object motion, fluid additions) with constraints that preserve global physical coherence.
- Dependencies: Fine-grained, localized reward gradients; temporally consistent editors; user-in-the-loop interfaces.
- Web-scale data curation and pretraining filters
- Sectors: Foundation model training
- What: Filter or reweight large video corpora by physics plausibility to improve pretraining distributions.
- Dependencies: Efficient scoring at scale; bias analysis (e.g., against stylized or animated content); correlation with downstream gains.
- Scientific visualization assistants
- Sectors: Climate, energy, materials science
- What: Early-stage illustrative videos that respect core physical intuitions for communicating hypotheses.
- Dependencies: Domain-augmented reward models; strict disclaimers (not predictive or engineering-grade).
- Personalized STEM tutoring with on-the-fly micro-simulations
- Sectors: Education/EdTech
- What: Tutor agents generate tailored, physically coherent demonstrations tied to lesson objectives and student inputs.
- Dependencies: Text-conditioned physics rewards; guardrails for correctness; teacher oversight; accessibility and cost control.
- On-device/edge deployment and adaptive compute
- Sectors: Mobile, embedded, creator hardware
- What: Partial, adaptive guidance (e.g., late-stage only) under tight compute budgets for consumer devices.
- Dependencies: Model compression/distillation; memory-aware BoN; quantization; efficient latent world models.
- Multi-sensor, cross-modal world models as rewards
- Sectors: Autonomous systems, smart cities, industrial IoT
- What: Extend rewards to incorporate audio, inertial, or depth cues, enforcing cross-modal physical consistency.
- Dependencies: Training multi-modal world models; synchronized datasets; new evaluation suites.
General assumptions/dependencies across applications
- Reward coverage: Current latent world models emphasize intuitive dynamics; material properties (weight, friction), complex fluids, and domain-specific physics remain limited.
- Compute budget: Performance scales with test-time compute (N, guidance steps); production use needs scheduling and cost controls.
- Base model manifold: Method finds plausible trajectories already learnable by the generator; poor base models limit gains.
- Trade-offs: Increased physics plausibility can slightly reduce prompt adherence if rewards are text-agnostic; multi-reward strategies help.
- Licensing and access: Availability and terms for VJEPA-like models; integration constraints in enterprise environments.
- Evaluation and governance: Human review for sensitive uses; domain calibration of thresholds; transparent audit trails and user disclosures.
Collections
Sign up for free to add this paper to one or more collections.