Video Generation Models Are Good Latent Reward Models
Abstract: Reward feedback learning (ReFL) has proven effective for aligning image generation with human preferences. However, its extension to video generation faces significant challenges. Existing video reward models rely on vision-LLMs designed for pixel-space inputs, confining ReFL optimization to near-complete denoising steps after computationally expensive VAE decoding. This pixel-space approach incurs substantial memory overhead and increased training time, and its late-stage optimization lacks early-stage supervision, refining only visual quality rather than fundamental motion dynamics and structural coherence. In this work, we show that pre-trained video generation models are naturally suited for reward modeling in the noisy latent space, as they are explicitly designed to process noisy latent representations at arbitrary timesteps and inherently preserve temporal information through their sequential modeling capabilities. Accordingly, we propose Process Reward Feedback Learning~(PRFL), a framework that conducts preference optimization entirely in latent space, enabling efficient gradient backpropagation throughout the full denoising chain without VAE decoding. Extensive experiments demonstrate that PRFL significantly improves alignment with human preferences, while achieving substantial reductions in memory consumption and training time compared to RGB ReFL.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Video Generation Models Are Good Latent Reward Models” for a 14-year-old
Overview: What is this paper about?
This paper is about making AI-created videos look and move more naturally, the way people prefer. The authors build a new training method called PRFL (Process Reward Feedback Learning) that teaches video-making AIs to improve motion (how things move), body shapes (like hands and faces), and overall quality. The key idea is to let the AI “judge” its own work while it’s still in the middle of making a video, not only at the end. This makes training faster and more effective.
Objectives: What questions are they trying to answer?
The paper tackles three simple questions:
- How can we teach video AIs to follow human preferences (like smooth movement and realistic people) more reliably?
- Can we avoid slow and memory-heavy steps when training these models?
- Instead of judging only the final video, can we judge the AI’s work at each step while it’s creating the video?
Methods: How did they do it?
Think of making a video like baking a cake: you don’t just check it at the end—you check the batter, the oven temperature, and the cake as it rises. The authors do something similar for video AIs.
Here are the main ideas, explained simply:
- Video Generation Model (VGM): This is the AI that creates the video. It builds the video step by step, starting from random noise and turning it into a clear video. These steps are called “timesteps.”
- Latent space: Instead of working directly with pixels (the colorful dots you see in a video), the model works in a smaller “secret code” version of the video called the latent space. It’s like a compressed blueprint—much faster to process and easier to train on.
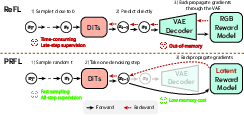
- Reward model: A “judge” that scores how good a video is (e.g., is the motion smooth? are the people’s bodies shaped correctly?). Most old methods judged only the final video by decoding it into pixels, which is slow and uses a lot of memory.
The paper introduces two key tools:
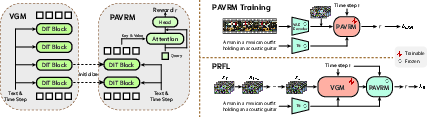
- PAVRM (Process-Aware Video Reward Model): A judge that can score the video’s quality directly in the latent space at any step of the process. It doesn’t need to decode the video into pixels. It uses attention (a way to focus on important parts) to summarize the whole video into a small, meaningful signal.
- PRFL (Process Reward Feedback Learning): A training method that uses the PAVRM judge to give feedback during the video-making process. It randomly picks a step, checks the quality, and nudges the video-making AI to improve—without doing slow pixel decoding. It also balances training with a regular “stay on track” loss so the AI doesn’t over-optimize just one thing.
Why this helps:
- It’s faster because it skips expensive decoding.
- It uses less GPU memory.
- It guides the model during early steps where motion and structure are formed, not just at the end.
Findings: What did they discover and why does it matter?
The authors ran lots of tests on different video tasks (text-to-video and image-to-video) and resolutions (480p and 720p). They compared PRFL to other methods like SFT (supervised fine-tuning), RWR (reward-weighted regression), and RGB ReFL (a reward method that uses pixel decoding).
Main results:
- Better motion: PRFL significantly improved “dynamic degree,” a measure of how well things move. Improvements were huge, up to +56.00 points at 720p.
- More realistic people: PRFL improved “human anatomy” scores (fewer distorted faces/hands) by up to +21.52 points.
- Fast and efficient: Training was at least about 1.4× faster than a popular baseline and could handle full multi-frame videos without running out of memory, while the pixel-based method struggled.
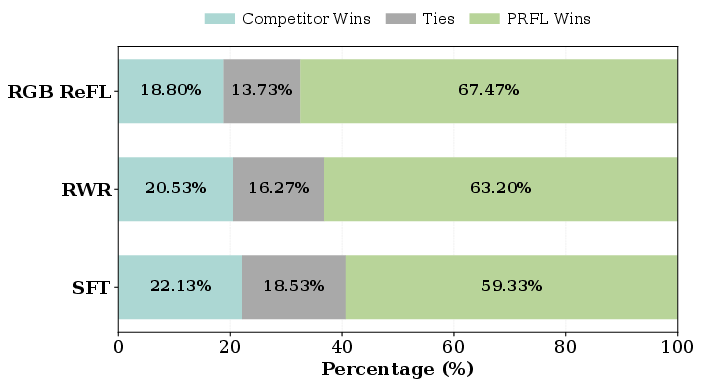
- Human preference: In user studies, people preferred PRFL videos over other methods overall.
Why this matters:
- Videos look more natural and move better.
- Training becomes practical and scalable (faster and uses less memory).
- The approach aligns AI video generation more closely with what humans actually like.
Implications: What could this lead to?
This research shows that video AIs can learn better by judging their own process, not just their final output. That could lead to:
- More realistic, smoother AI-generated videos in films, games, and social media.
- Faster training for big video models, making them easier and cheaper to improve.
- Extensions beyond motion, like better style, story following, and safety checks.
- Better tools for video editing and control, since the model understands quality throughout the process.
In short, PRFL and PAVRM help video-making AIs learn smarter and faster, producing videos people like more—without the heavy cost of judging everything in pixel space.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open problems left unresolved by the paper that can guide future research:
- Scope of preference dimensions:
- The approach is optimized primarily for motion quality; it does not jointly model other crucial axes (aesthetics, prompt following/semantics, temporal consistency beyond motion, physical plausibility, cinematography).
- How to build multi-aspect, disentangled reward heads (e.g., motion, anatomy, coherence, aesthetics) and balance them during training remains open.
- Reward signal design and calibration:
- PAVRM uses binary (qualified/unqualified) labels; the granularity is coarse. It is unclear how performance changes with pairwise preferences, continuous scores, or multi-label criteria.
- Reward scores are used directly in PRFL without timestep-specific calibration; cross-timestep comparability and normalization (e.g., monotonicity or scale consistency across ) are not addressed.
- No uncertainty estimation or ensemble-based rewards to mitigate reward over-optimization; how to quantify and use reward epistemic uncertainty is unexplored.
- The paper assumes final-output preference labels propagate to intermediate noisy states; this assumption is untested and may be invalid for certain artifacts or structures formed late in denoising.
- Dataset coverage and bias:
- The reward model is trained mainly on human-centric/portrait videos; generalization to non-human, multi-object, cluttered scenes, complex camera motion, and domain-shifted content is not systematically evaluated.
- “Partially qualified” samples are discarded, losing informative supervision; learning from ambiguous/partial labels or weak preferences is an open direction.
- Training the reward on the generator’s own outputs risks overfitting to its artifact distribution; cross-model generalization (out-of-distribution artifacts) is not shown.
- Evaluation methodology:
- The paper uses PAVRM itself to compute an internal “qualified ratio” metric for generation evaluation, introducing potential circularity and metric bias.
- Human evaluation is limited in size (2,250 pairwise judgments across 25 prompts); larger-scale, controlled studies and inter-rater reliability analysis are missing.
- Motion quality improvements are emphasized, but prompt adherence and semantic fidelity are not carefully quantified; physics/causality metrics are also absent.
- Generalization across architectures and paradigms:
- PRFL and PAVRM are demonstrated on rectified flow VGMs (Wan2.1). It is unclear how well the approach transfers to other families (score-based diffusion with different schedules, autoregressive video, latent consistency, VAEs without rectified flow).
- Cross-model reward transfer (train PAVRM on model A, use it to align model B) and cross-vae/latent-space compatibility are not studied.
- Process-level optimization design:
- PRFL applies a single gradient-enabled step at a randomly sampled timestep; the trade-off between credit assignment and compute (multi-step gradients, truncated horizons, curriculum over ) is unexplored.
- No analysis of how the PRFL/SFT mixing ratio, λ scaling, gradient norms, and timestep sampling strategies affect stability, convergence, and diversity.
- Advantage shaping/baselines are not used; whether variance or instability emerges for different distributions and rewards is unknown.
- Reward model architecture and capacity:
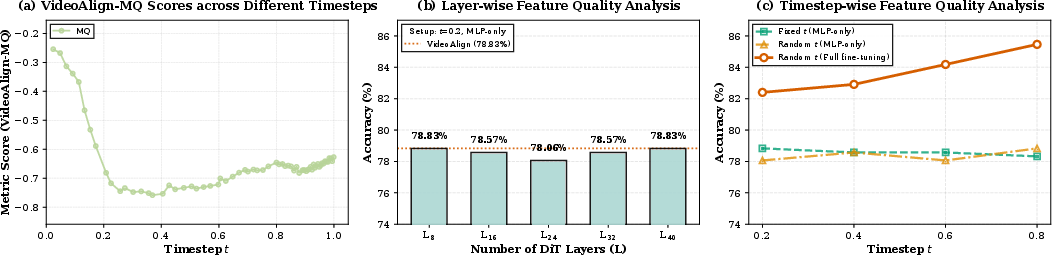
- Only the first eight DiT blocks are used with a single learnable query for aggregation. The benefits of multi-query/multi-head aggregation, cross-scale features, or temporal transformers are not examined.
- Ablations on which backbone layers to use, partial vs full fine-tuning of the VGM, and parameter-efficient adapters (LoRA, IA3) are limited.
- Scalability and efficiency:
- Despite avoiding VAE decoding, PRFL still requires ~67 GB VRAM; strategies for reducing memory (activation checkpointing, offloading, 8-bit training, gradient rematerialization) are not discussed.
- Scaling to longer durations, higher frame rates, or 4K+ resolutions and the associated memory/latency trade-offs remain open.
- The impact of inference-time guidance (e.g., using PAVRM as a plug-in at test time) is not explored; only train-time optimization is considered.
- Theoretical understanding:
- There is no formal analysis connecting improvements at intermediate timesteps to final sample quality in rectified flow, nor guarantees of monotone policy improvement under PRFL updates.
- How the latent reward interacts with the flow-matching objective at different (e.g., as implicit constraints or shaping terms) is not theoretically characterized.
- Robustness and safety:
- Reward hacking is only heuristically addressed via SFT regularization; failure modes (e.g., artifacts that fool PAVRM) and adversarial robustness are not measured.
- Safety constraints (e.g., content moderation, bias amplification, fairness across demographics) are not integrated into the reward or training.
- Task and control coverage:
- The method is not validated on controllable generation (e.g., depth/pose/optical flow guidance), long-horizon story videos, streaming/online generation, or video editing tasks; adaptation to these settings is an open problem.
- Reproducibility and resources:
- Details about dataset release, annotation guidelines, and code/models are limited; lack of public assets impedes replication.
- The approach’s practicality outside large-GPU clusters is unclear; guidance for resource-constrained training is missing.
- Metric development:
- Current automated metrics (VBench/VBench2) insufficiently capture nuanced motion and physical plausibility; standardized, open, multi-aspect motion metrics and curated benchmarks remain needed.
- Language and multimodality:
- Although text conditioning is used, multilingual robustness, complex compositional prompts, and multimodal conditioning (audio, sketches, trajectories) are not evaluated or rewarded; how to extend PAVRM to multi-modal preferences is open.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, drawing on the paper’s findings and methods. Each item notes relevant sectors, potential tools/products/workflows, and key assumptions or dependencies.
- Improving commercial video generation quality and efficiency
- Sector: software, media/entertainment, advertising
- Application: Integrate PRFL to fine-tune existing text-to-video and image-to-video models (e.g., Wan, HunyuanVideo, Seedance) for better motion dynamics and anatomically correct humans, with lower training costs and faster turnaround (≥1.4× speedup vs. RGB ReFL; reduced VRAM OOM risk).
- Tools/products/workflows: “PRFL Trainer” module for rectified-flow VGMs; “PAVRM Scoring API” for motion quality; alternating PRFL+SFT training pipelines; quality dashboards tracking dynamic degree, human anatomy, MS/SC.
- Assumptions/dependencies: Access to a pre-trained rectified-flow VGM with DiT-like blocks and a VAE encoder; preference-labeled data (even small, domain-specific sets); high-memory GPUs (peak ~67 GB for 81 frames).
- Automated quality assurance for generative video pipelines
- Sector: software, media/entertainment
- Application: Use PAVRM as a fast, latent-space QA gate to rank, filter, or flag outputs for artifact risks (e.g., distortions, implausible motion) before final rendering/decoding.
- Tools/products/workflows: Batch scoring of intermediate latents; “Motion-Guard” plugin to prioritize or discard generation trajectories; early termination if PAVRM score trends downward.
- Assumptions/dependencies: VGM access to latents/timesteps; threshold calibration using internal preference labels; distribution shift monitoring (portrait-heavy training may bias scoring).
- Style and brand preference alignment in creative studios
- Sector: advertising, media/VFX, gaming
- Application: Fine-tune house models to brand-specific motion styles (e.g., camera panning rules, action smoothness), increasing consistency across campaigns while cutting compute costs.
- Tools/products/workflows: Lightweight preference datasets; query-based aggregation configuration per style; full-stage timestep sampling for balanced motion and structure quality.
- Assumptions/dependencies: Legal/ethical data governance for preference labels; enough representative style examples; prompt and content diversity to avoid reward over-optimization.
- Content moderation assist for generative platforms
- Sector: platform safety, media
- Application: Deploy PAVRM to detect anatomically implausible or deceptive motion early in generation, supporting human moderators and automated filters.
- Tools/products/workflows: Latent scoring service with risk categories; escalations for human review; integration with existing moderation queues.
- Assumptions/dependencies: Calibrated thresholds; policies distinguishing “low quality” vs. “harmful” content; avoid false positives from distribution shifts.
- Data curation and training set cleaning
- Sector: software (MLops), media
- Application: Use PAVRM to score and curate synthetic or mixed datasets by motion plausibility, removing artifact-laden examples to improve SFT and downstream training.
- Tools/products/workflows: “Quality-aware Data Curator” pipeline; per-timestep sampling to catch early-stage issues; dataset reports tracking quality distributions.
- Assumptions/dependencies: Access to latents or quick encoding; decisions about how strict to filter without reducing diversity.
- Cost and energy savings in model post-training
- Sector: energy/sustainability, finance/ops
- Application: Adopt PRFL’s latent-space optimization to reduce training-step time and avoid decoding costs, cutting cloud spend and energy consumption for alignment cycles.
- Tools/products/workflows: Update training orchestration to remove pixel-space reward passes; VRAM-aware scheduling; reporting on cost/energy KPIs.
- Assumptions/dependencies: Compatible VGM architectures; ops buy-in for workflow changes; monitoring to confirm savings.
- Academic experimentation on process-level rewards
- Sector: academia (ML, vision)
- Application: Reproduce PRFL/PAVRM to study denoising-stage effects; evaluate early/middle/late timestep curricula on motion vs. anatomy trade-offs; publish benchmarks and ablations.
- Tools/products/workflows: Open-sourced training scripts; integration with JAX/PyTorch Diffusers; VBench and VBench2 evaluations.
- Assumptions/dependencies: Compute resources; access to preference labels or public proxies; reproducibility practices.
- Creator tools for higher-quality social videos
- Sector: daily life, creator economy
- Application: Offer a “Quality Boost” mode in consumer generative apps with PRFL-tuned backends, reducing common artifacts in dance/movement-heavy clips.
- Tools/products/workflows: Cloud-backed generation with PRFL-tuned models; minimal UX changes; on/off toggles per prompt.
- Assumptions/dependencies: Vendor access to PRFL-tuned models; consented data collection for preference adaptation; cost-effective hosting.
- Early-stage trajectory steering during sampling (lite version)
- Sector: software
- Application: Use PAVRM to score a sparse subset of timesteps and adjust scheduler parameters (e.g., step size, guidance scale) if scores degrade, reducing wasted compute.
- Tools/products/workflows: “Quality-aware Sampler” heuristics; sampling hooks to query PAVRM; logs for timestep score curves.
- Assumptions/dependencies: Minimal inference-time overhead; careful coupling to avoid instability; heuristic tuning per model/resolution.
- Corporate training and educational content generation
- Sector: education
- Application: Generate motion-centric training animations (assembly, safety demos) with improved physical plausibility and subject consistency.
- Tools/products/workflows: Internal preference sets; PRFL fine-tunes for domain motions; QA scoring to batch-validate outputs.
- Assumptions/dependencies: Limited domain shifts (non-human machinery motions may need separate labels); safety review of content accuracy.
Long-Term Applications
The following use cases are promising but need further research, scaling, or development (e.g., broader reward signals, robustness, policy integration).
- Multi-aspect RLHF for video (beyond motion)
- Sector: software, media
- Application: Extend PAVRM to multi-head rewards (aesthetics, semantics, safety) and combine with online RL (e.g., PPO/GRPO variants for flow models) for comprehensive alignment.
- Tools/products/workflows: Multi-reward orchestration, weight scheduling; active learning loops for diverse human feedback.
- Assumptions/dependencies: Large, diverse preference datasets; mitigations against reward hacking; fairness and bias audits.
- Real-time inference-time steering via latent rewards
- Sector: software
- Application: Use process-aware scoring every few steps to steer generation in real time, dynamically modulating velocity fields/schedulers to avoid artifacts and accelerate convergence.
- Tools/products/workflows: “Quality-aware Scheduler” integrated with samplers; caching and low-latency scoring; adaptive timestep policies.
- Assumptions/dependencies: Efficient per-step scoring; stability analyses; hardware acceleration support.
- Cross-modal generative alignment (audio-video, motion capture)
- Sector: media, robotics (simulation/telepresence)
- Application: Apply process-level latent rewards to jointly align audio-visual generation or synthesized human motion trajectories for more coherent multimodal outputs.
- Tools/products/workflows: Multimodal latent fusion; cross-modal reward heads; synchronized timestep curricula.
- Assumptions/dependencies: Shared latent spaces; synchronized training signals; comprehensive multimodal preference datasets.
- Safety, compliance, and platform standards for generative video
- Sector: policy/regulation, platform safety
- Application: Develop industry standards for physical plausibility, artifact detection, and misinformative motion, using PAVRM-like checks as part of compliance audits.
- Tools/products/workflows: Standardized scoring protocols; certification processes; transparency reports for generative platforms.
- Assumptions/dependencies: Cross-industry coordination; clear definitions and thresholds; governance for model updates.
- Domain-specific healthcare content (with rigorous validation)
- Sector: healthcare, education
- Application: Use PRFL-tuned models to produce patient education or procedural training animations with improved anatomical plausibility; pair with expert verification.
- Tools/products/workflows: Medical preference datasets; clinician-in-the-loop QA and sign-off; deployment in CME/e-learning platforms.
- Assumptions/dependencies: Strict validation to avoid inaccuracies; regulatory compliance; domain shift handling (anatomy ≠ clinical correctness).
- Production-scale cloud services for “Alignment-as-a-Service”
- Sector: software, finance/ops
- Application: Offer managed services that run PRFL alignment jobs on customer models, with SLAs for quality metrics and cost/energy efficiency.
- Tools/products/workflows: Multi-tenant training orchestration; cost/energy dashboards; private data ingest for preferences.
- Assumptions/dependencies: Security/privacy guarantees; workload isolation; robust monitoring.
- Bias, fairness, and representational auditing for reward models
- Sector: academia, policy
- Application: Systematically evaluate whether PAVRM-trained on portrait-heavy datasets exhibits demographic or motion-style biases; publish audit toolkits and mitigations.
- Tools/products/workflows: Bias probes across identities and motion types; counterfactual data augmentation; governance frameworks.
- Assumptions/dependencies: Accessible, representative datasets; ethical review; shared benchmarks.
- On-device or edge alignment for creative hardware
- Sector: software/hardware, energy
- Application: Explore compressed PAVRM/PRFL variants for small form-factor devices (e.g., creator laptops, edge GPUs) to enable local fine-tuning for privacy-sensitive users.
- Tools/products/workflows: Model distillation; mixed-precision training; memory-aware schedulers.
- Assumptions/dependencies: Aggressive optimization; performance trade-offs; local datasets.
- Generative training curriculum design tools
- Sector: software, academia
- Application: Build tools that automatically choose timestep sampling strategies (early/middle/late/full) to optimize specific metrics (e.g., dynamics vs. anatomy) per domain.
- Tools/products/workflows: “Curriculum Composer” service that maps target KPIs to timestep schedules; continuous evaluation loops.
- Assumptions/dependencies: Reliable KPI–timestep mappings; domain-specific tuning; generalization across models/resolutions.
- Standardized benchmarks and datasets for process-level video rewards
- Sector: academia, policy
- Application: Create open, diverse, multi-aspect reward datasets and benchmark protocols to evaluate latent reward models (PAVRM-like) across tasks and content types.
- Tools/products/workflows: Public datasets with high-quality annotations; VBench/VBench2 extensions; community leaderboards.
- Assumptions/dependencies: Funding and data-sharing agreements; annotation quality controls; privacy-aware collection.
Notes on Assumptions and Dependencies (Cross-cutting)
- Architectural compatibility: PRFL/PAVRM are designed for rectified flow VGMs with DiT blocks and noisy latent processing; adapting to other families may need engineering changes.
- Data requirements: Preference labels (especially beyond motion) are necessary; current paper used ~24k generated portrait videos—expect biases unless broadened.
- Compute: While more efficient than RGB ReFL, PRFL still benefits from high-memory GPUs; consumer devices may require distillation/quantization.
- Evaluation: Reliance on VBench/VBench2 and internal QA metrics; continued validation with human studies is recommended to avoid overfitting to automatic metrics.
- Safety and governance: Reward hacking is possible; alternating SFT regularization and multi-signal rewards help but do not eliminate risks; policy frameworks and audits are advisable.
Glossary
- AdamW optimizer: A variant of Adam that decouples weight decay from the gradient update to improve generalization. "We employ the AdamW optimizer~\cite{loshchilov2017decoupled} with learning rates of 1e-5 for query attention and head of PAVRM, 1e-6 for the feature extraction of PAVRM, and 5e-6 for PRFL."
- Artifact awareness: The model’s sensitivity to detecting and accounting for visual artifacts during generation. "keep artifact awareness throughout the denoising process based on pre-trained video models."
- Denoising rollouts: Forward simulations of the generative process across timesteps without gradients to reach a target intermediate state. "we perform gradient-free denoising rollouts from to "
- Denoising trajectory: The sequence of intermediate states from noise to data through which a diffusion/flow model generates outputs. "process-level supervision throughout the denoising trajectory."
- DiT blocks: Diffusion Transformer blocks used as the backbone network in modern diffusion-based video generators. "A neural network (usually several DiT blocks) parameterized by predicts the velocity field at each timestep"
- Flow matching objective: A training objective for rectified flow models that matches predicted velocities to the true data-to-noise transport. "trained via the flow matching objective, which also as supervised fine-tuning~(SFT) loss:"
- Gradient stopping: A training technique that prevents gradients from propagating through certain parts of a computation, used to control optimization depth. "distribute gradient updates via gradient stopping or trajectory shortcuts"
- Latent space: The compressed representation space (often VAE latents) in which training and reward modeling can be performed efficiently. "reward modeling in the noisy latent space"
- Noise-aware latent reward model: A reward model that evaluates quality directly on noisy latent representations across timesteps. "LPO~\cite{zhang2025diffusion} pioneered using diffusion models as noise-aware latent reward models for image generation"
- Outcome-based reward models: Reward models that assess only final (near-clean) outputs rather than intermediate states. "Typical ReFL approaches rely on outcome-based reward models built upon Vision-LLMs (VLMs)"
- Process-Aware Video Reward Model (PAVRM): A reward model that evaluates video quality from noisy latents at arbitrary timesteps using spatiotemporal aggregation. "First, we propose a {Process-Aware Video Reward Model (PAVRM)}, which repurposes video generation models to evaluate quality directly from noisy latent representations at arbitrary timesteps."
- Process Reward Feedback Learning (PRFL): A framework that performs preference optimization in latent space with timestep-aware rewards. "Accordingly, we propose Process Reward Feedback Learning~(PRFL), a framework that conducts preference optimization entirely in latent space"
- Query attention: An attention mechanism using a learnable query to aggregate variable-length spatiotemporal features into a fixed-size representation. "we employ a query attention as query-based spatiotemporal aggregation that adaptively compresses spatiotemporal information into a fixed-size embedding."
- Rectified flow: A continuous transport framework connecting data and noise distributions, enabling velocity-based training. "video generation models~\cite{kong2024hunyuanvideo,wan2025,gao2025seedance} operate in rectified flow"
- Reinforcement Learning from Human Feedback (RLHF): Training paradigms that use human preference signals to guide model behavior via reward models. "Reward models for RLHF~\cite{ouyang2022training} are typically trained on human preferences"
- Reward feedback learning (ReFL): A method that backpropagates differentiable reward signals through generative timesteps to align outputs with preferences. "Reward feedback learning (ReFL)~\cite{xu2023imagereward,prabhudesai2023aligning,clarkdirectly2024} has emerged as a promising way for preference alignment in image generation."
- Reward weighted regression (RWR): An offline post-training method that weights supervised regression by reward estimates to improve outputs. "reward weighted regression~(RWR)~\cite{liu2025improving}"
- Spatiotemporal aggregation: The compression of spatial and temporal features into a unified embedding for quality assessment. "query-based spatiotemporal aggregation"
- Supervised Fine-Tuning (SFT): Additional training using labeled or curated data to regularize or improve generator behavior. "trained via the flow matching objective, which also as supervised fine-tuning~(SFT) loss:"
- Trajectory-preserving shortcuts: Techniques that modify or approximate the denoising path to make training more efficient without deviating from the intended trajectory. "distribute gradient updates via gradient stopping or trajectory shortcuts"
- UniPCMultistepScheduler: A multi-step scheduler for sampling/solving the generative process efficiently during training or inference. "We utilize UniPCMultistepScheduler~\cite{zhao2023unipc} with 1,000 training steps and 40 inference steps."
- VAE decoder: The component of a variational autoencoder that maps latent representations back to pixel space (RGB). "backpropagation through the VAE decoder for all video frames frequently causes GPU memory overflow."
- VAE encoder: The component that maps input videos into latent representations for efficient processing. "We freeze the VAE encoder while jointly optimizing the DiT blocks, query vector , and MLP parameters."
- VBench: An open-source benchmark suite for evaluating video generation quality across multiple dimensions. "We also incorporated the existing open-source benchmark VBench~\cite{huang2023vbench}"
- VBench2: A follow-up benchmark focusing on additional aspects such as human anatomy for video evaluation. "and VBench2~\cite{zheng2025vbench2}"
- Velocity field: The time-dependent vector field predicted by rectified flow models indicating transport direction from data to noise. "predicts the velocity field at each timestep"
- Video Generation Model (VGM): A diffusion/flow-based generative model that produces videos by denoising latent states across timesteps. "Overview of our process-aware video generation alignment framework. Left: Architecture of the Video Generation Model (VGM) and Process-Aware Video Reward Model (PAVRM)."
- Vision-LLMs (VLMs): Models that jointly process visual and textual inputs to assess or generate content. "Typical ReFL approaches rely on outcome-based reward models built upon Vision-LLMs (VLMs)"
Collections
Sign up for free to add this paper to one or more collections.

