- The paper introduces Neural Newtonian Dynamics (NND) to integrate physical laws with data-driven video synthesis, ensuring visually realistic and physically plausible motion.
- The framework employs a two-stage approach where NND predicts latent physical states that are converted into pixel-level motion control for precise parameter regulation.
- NewtonGen achieves state-of-the-art physical consistency measured by the Physical Invariance Score (PIS) across diverse motion types and supports precise user-specified parameter control.
Physics-Consistent and Controllable Text-to-Video Generation via Neural Newtonian Dynamics
Motivation and Problem Statement
Text-to-video generation models have achieved substantial progress in visual realism, yet they consistently fail to produce physically plausible dynamic sequences. Common failures include objects violating basic Newtonian laws (e.g., falling upward, abrupt velocity changes) and an inability to control motion parameters such as initial velocity, angle, or object size. These deficiencies stem from the fact that current models learn motion distributions solely from appearance data, lacking explicit modeling of underlying physical dynamics. NewtonGen addresses this gap by integrating data-driven synthesis with learnable physical principles, enabling both physical consistency and precise parameter control in generated videos.

Figure 1: NewtonGen generates physically-consistent videos from text prompts, with diverse dynamic perception (a), and precise parameter control (b).
Framework Overview
NewtonGen is a two-stage framework. The first stage introduces Neural Newtonian Dynamics (NND), a physics-informed neural ODE model trained on physics-clean video data to learn and predict diverse Newtonian motions. The second stage leverages the learned NND to guide a motion-controlled video generator, producing videos that are both visually realistic and physically plausible.
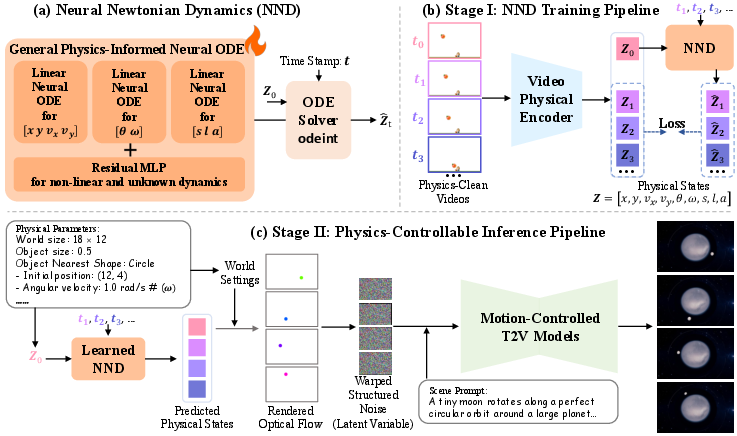
Figure 2: The overall framework of NewtonGen. a) NND employs physics-informed linear neural ODEs with an MLP for general dynamics learning. b) NND is trained on physics-clean data. c) The learned NND and a data-driven motion-controlled model generate physically plausible, controllable videos.
Neural Newtonian Dynamics (NND)
NND models the evolution of a 9-dimensional latent physical state vector Z=[x,y,vx,vy,θ,ω,s,l,a], capturing translation, rotation, deformation, and size changes. The dynamics are governed by a set of second-order autonomous ODEs:
azz¨+bzz˙+czz+dz+MLP(Z)=0
where z is an element of Z, and az,bz,cz,dz are learnable parameters. The linear ODEs capture dominant physical laws, while the residual MLP models nonlinear and unknown effects, enabling generalization across diverse motion types.
Training and Data
NND is trained in latent space using physics-clean videos generated by a custom simulator, which supports multi-parameter control (initial position, velocity, orientation, friction, damping, object properties). Physical states are extracted via segmentation (SAM2) and morphological analysis. The encoder-only architecture optimizes the prediction of future physical states, significantly reducing computational cost.
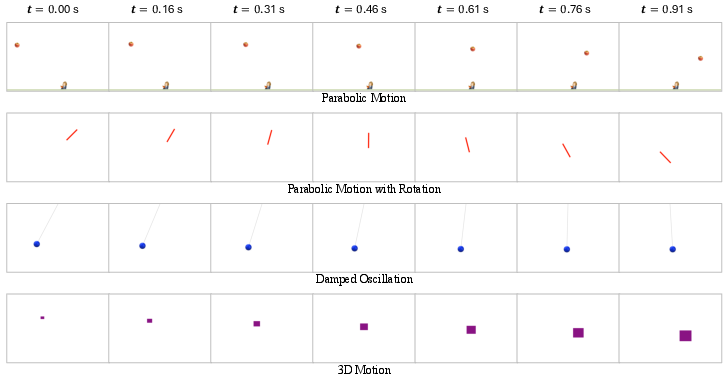
Figure 3: Sample physics-clean videos generated by the simulator.
Inference and Video Generation
During inference, user-specified physical parameters are parsed into initial states and time stamps, which are fed into NND to predict future states. These are converted into pixel-level optical flow and injected into a motion-controlled video generator (Go-with-the-Flow), which warps latent noise according to the predicted flow, ensuring temporal consistency and physical plausibility. This approach supports complex motions, including deformation and rotation, which are challenging for trajectory- or bounding-box-based controllers.
Empirical Evaluation
Physical Consistency and Controllability
NewtonGen is evaluated on twelve fundamental motion types: uniform velocity, acceleration, deceleration, parabolic, 3D, slope sliding, circular, rotation, parabolic with rotation, damped oscillation, size changing, and deformation. The Physical Invariance Score (PIS) quantifies physical plausibility by measuring the invariance of key physical quantities (e.g., velocity, acceleration, angular speed) over time.
NewtonGen consistently achieves the highest PIS across all motion types compared to SORA, Veo3, CogVideoX-5B, Wan2.2, and PhysT2V. For example, in uniform motion, NewtonGen attains a PIS of 0.9830, outperforming all baselines. In parabolic motion, both horizontal velocity and vertical acceleration invariants are preserved with high fidelity.

Figure 4: Visual comparisons of different text-to-video generation methods across diverse physical dynamics, where NewtonGen consistently shows strong physical consistency.
Parameter Control
NewtonGen demonstrates precise control over initial physical parameters, including position, velocity, angle, shape, and size. Generated videos accurately reflect user-specified conditions, with trajectories and velocities adhering to physical laws.
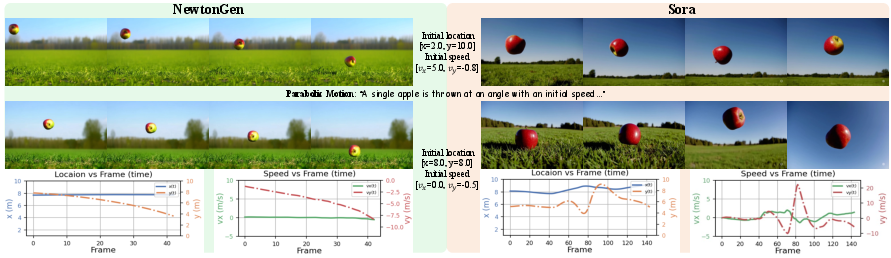
Figure 5: NewtonGen generates videos that accurately reflect user-specified initial physical parameters.
NND Prediction Accuracy
The trained NND model closely matches ground truth physical states across all tested motion types, including uniform, accelerated, parabolic, 3D, slope sliding, circular, rotation, parabolic with rotation, damped oscillation, size changing, and deformation.
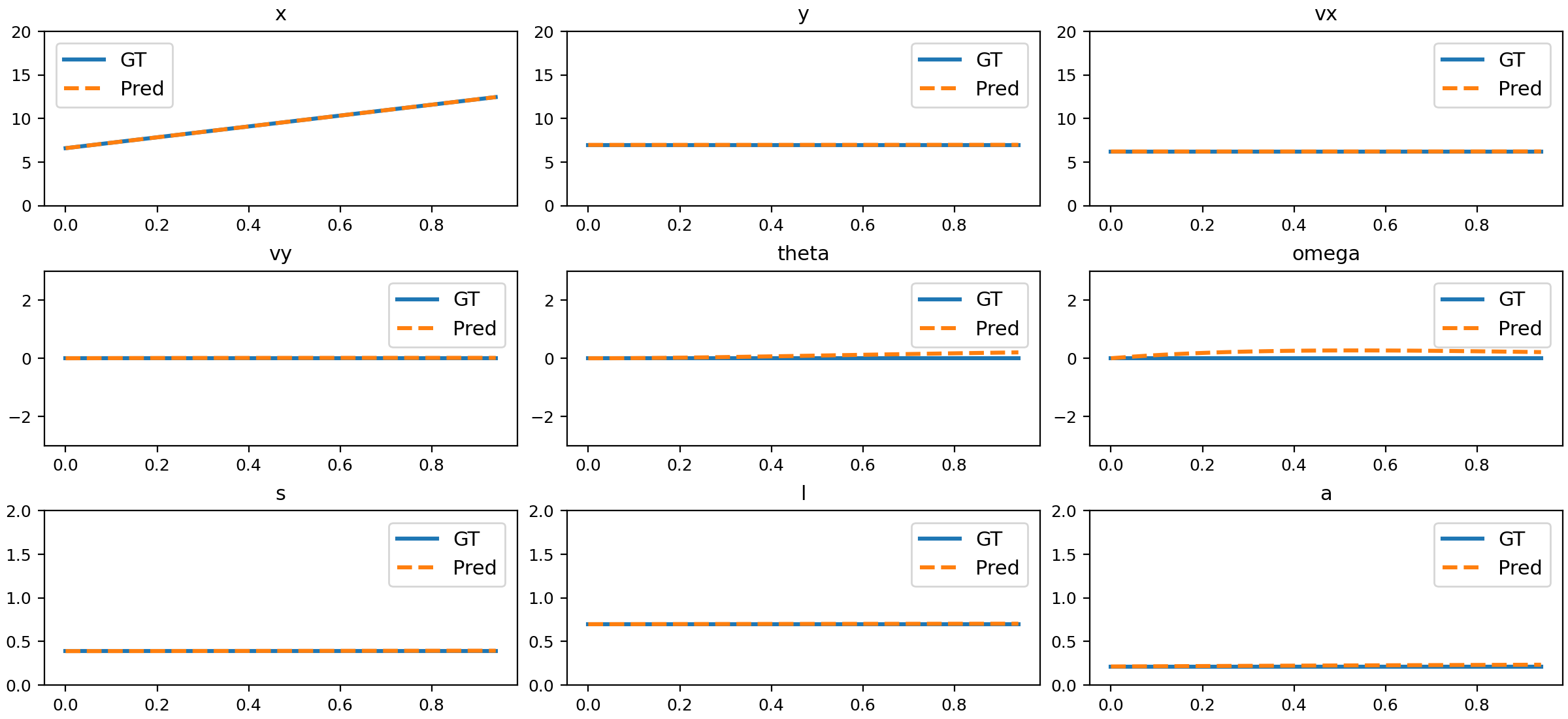
Figure 6: Comparison of NND predictions and ground truth for uniform motion.
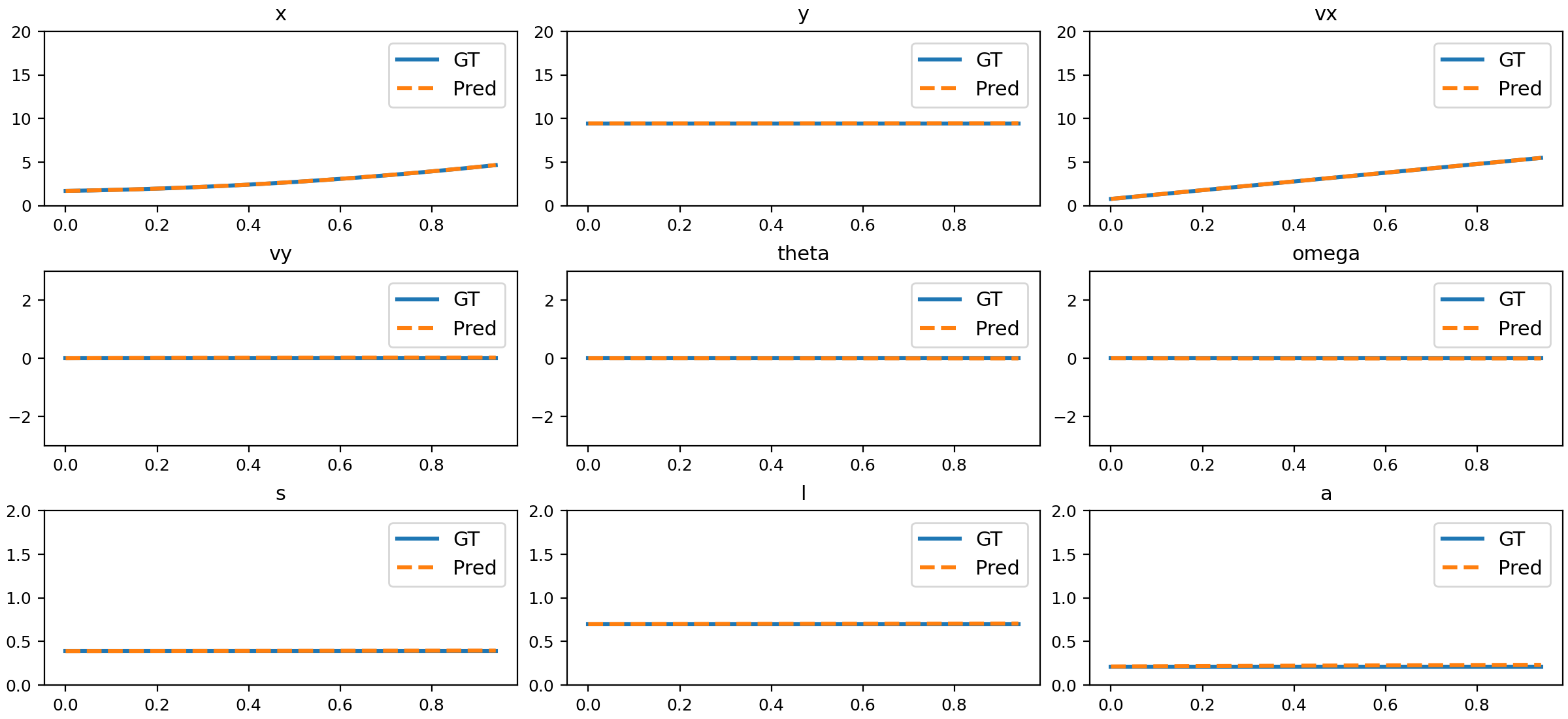
Figure 7: Comparison of NND predictions and ground truth for acceleration.
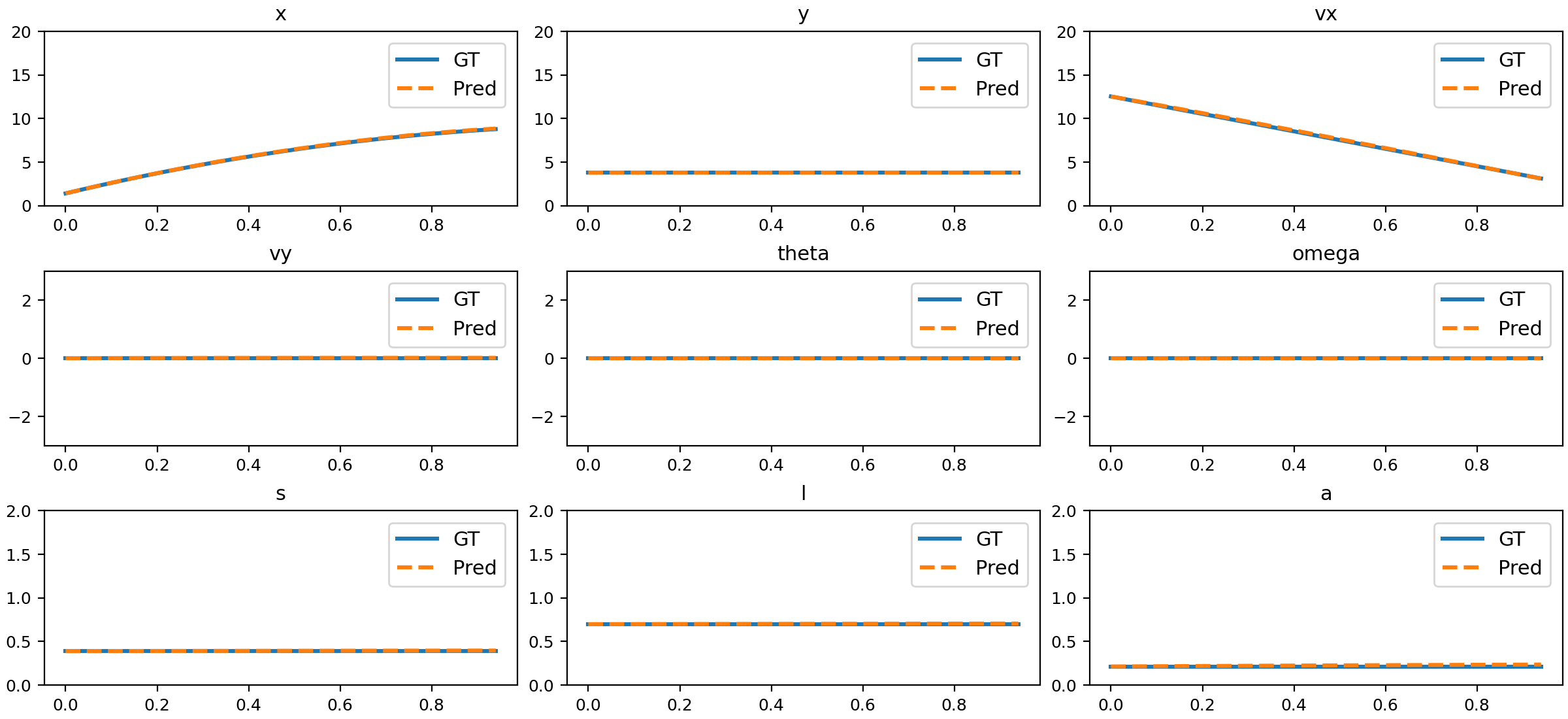
Figure 8: Comparison of NND predictions and ground truth for deceleration.
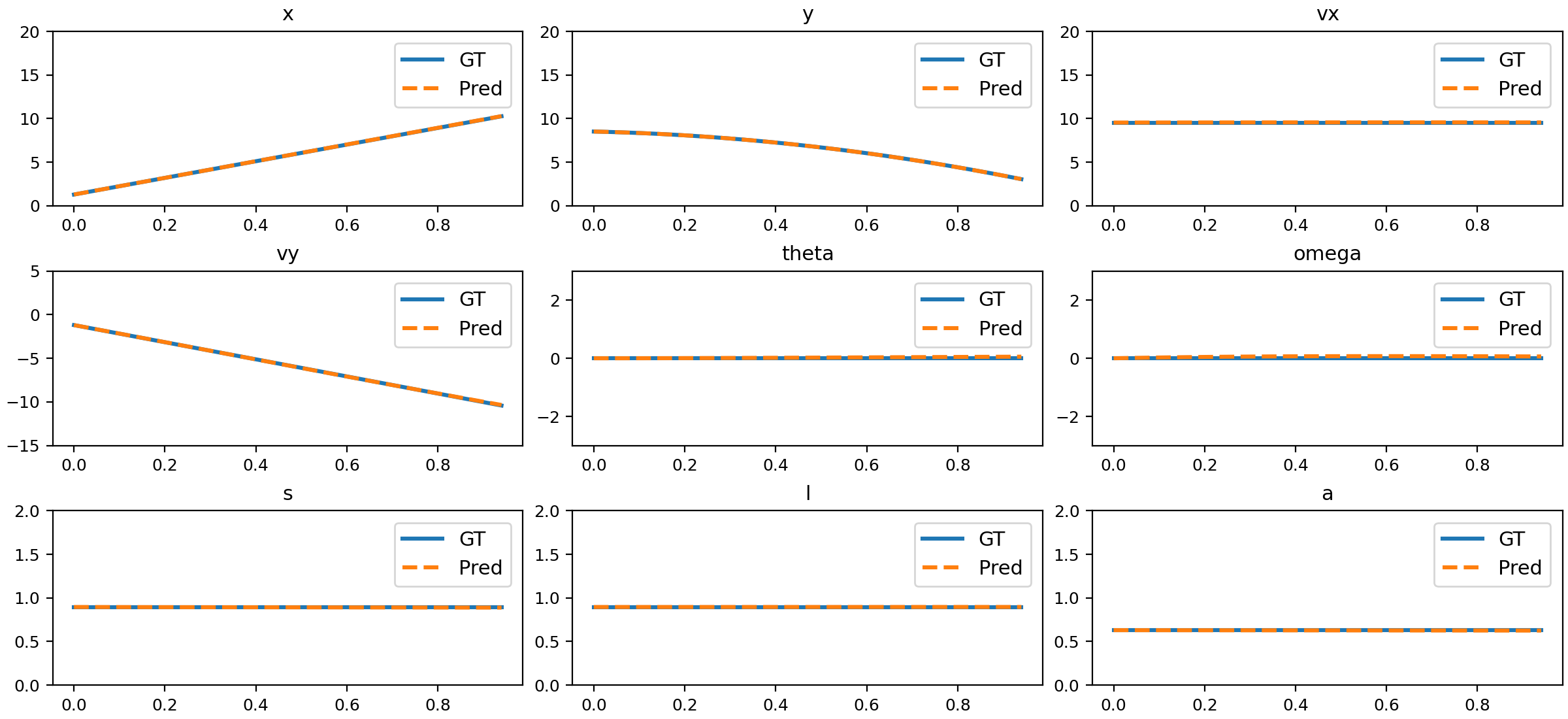
Figure 9: Comparison of NND predictions and ground truth for parabolic motion.
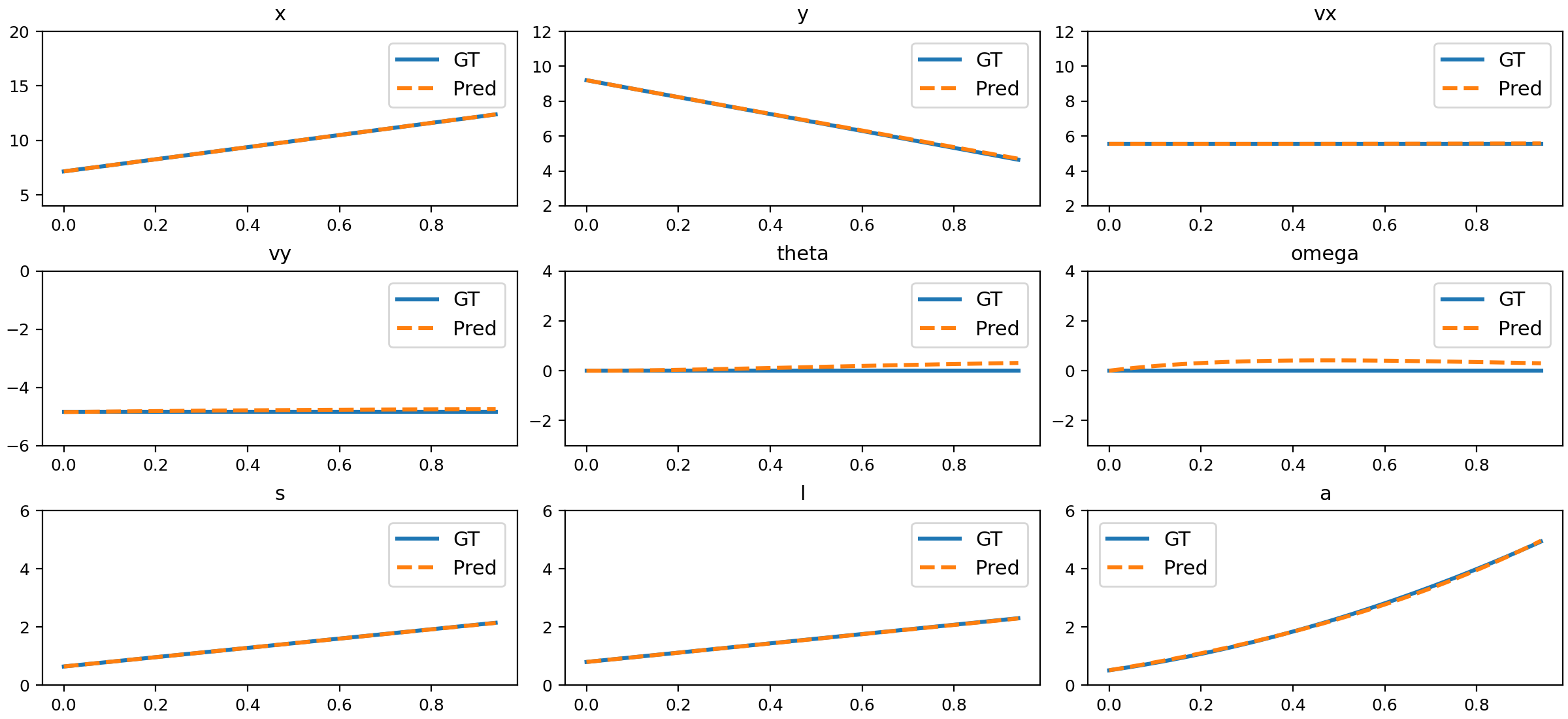
Figure 10: Comparison of NND predictions and ground truth for 3D motion.
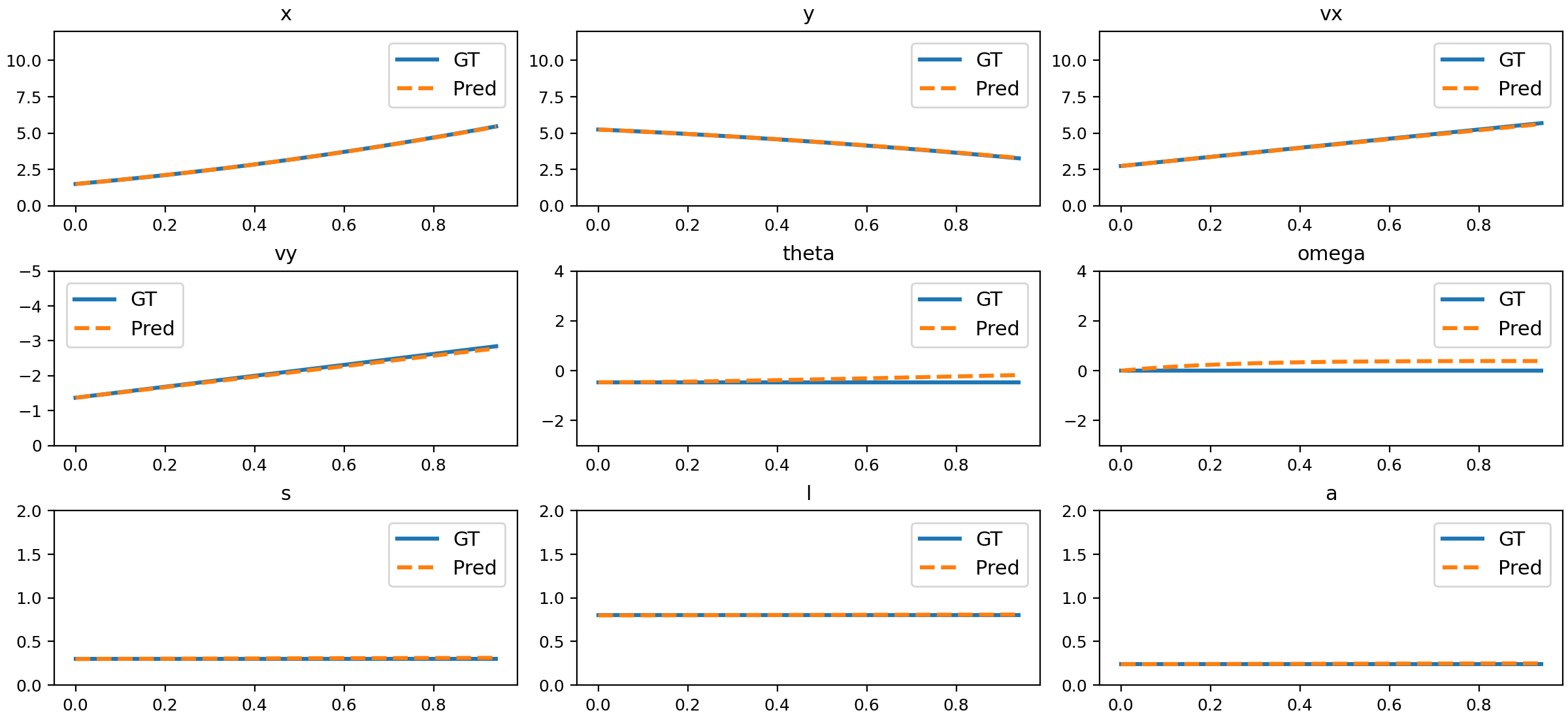
Figure 11: Comparison of NND predictions and ground truth for slope sliding.
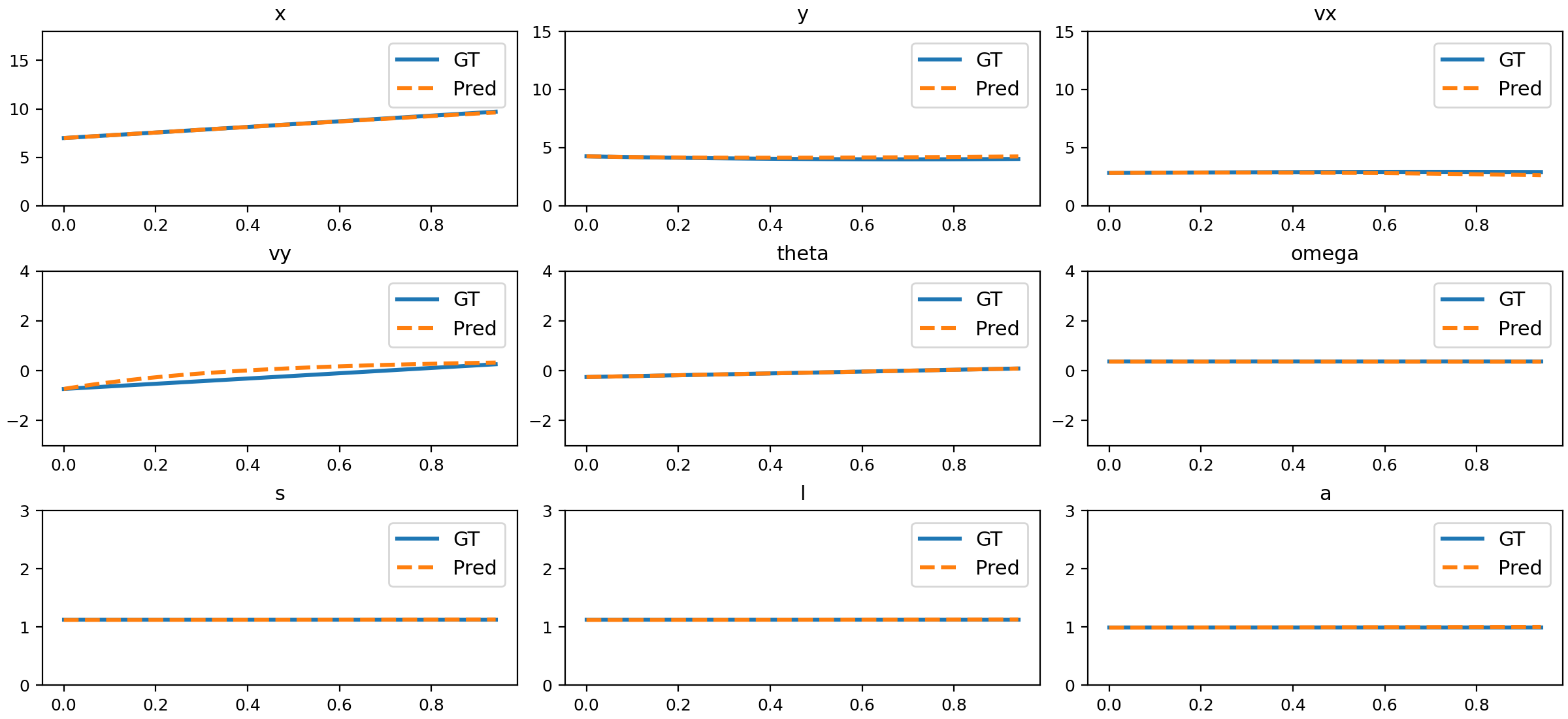
Figure 12: Comparison of NND predictions and ground truth for circular motion.
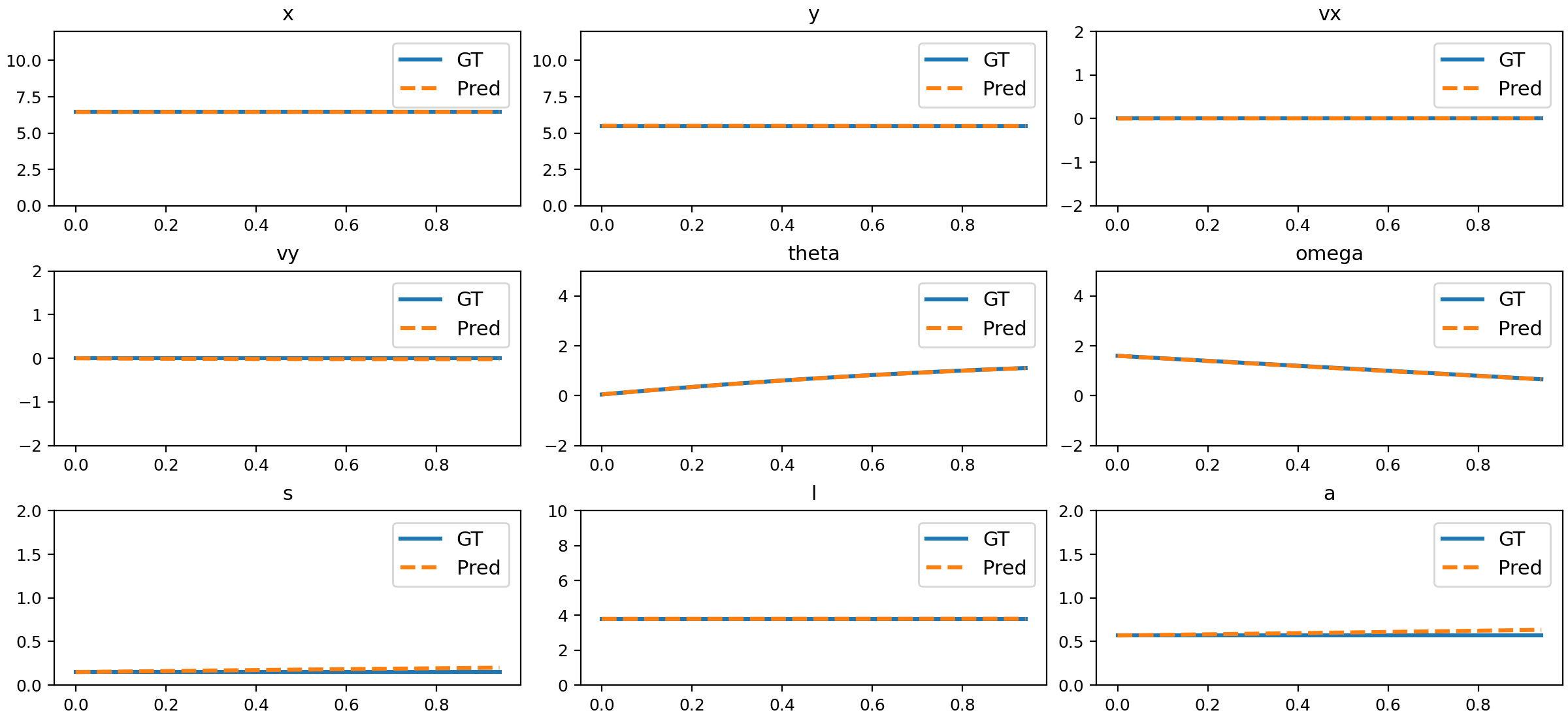
Figure 13: Comparison of NND predictions and ground truth for rotation.
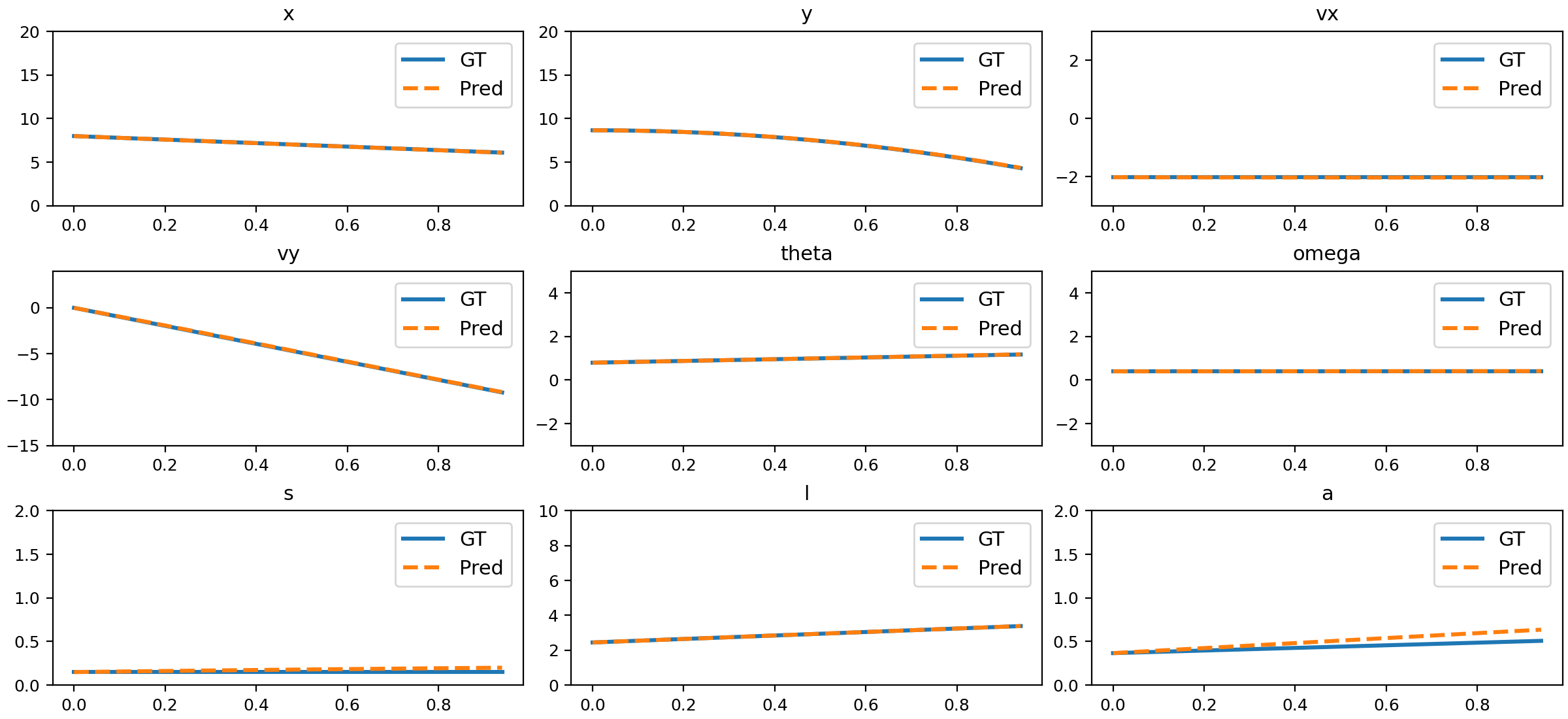
Figure 14: Comparison of NND predictions and ground truth for parabolic motion with rotation.
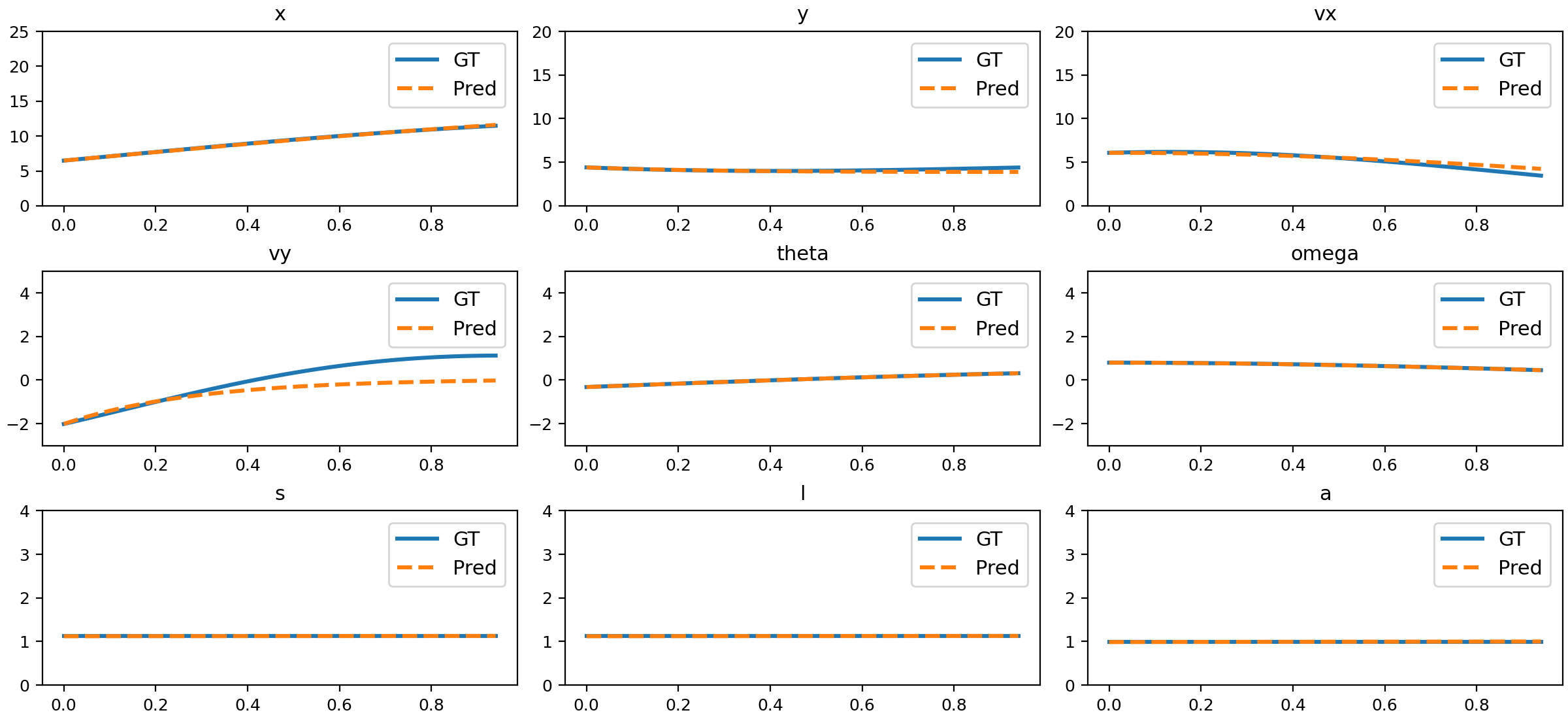
Figure 15: Comparison of NND predictions and ground truth for damped oscillation.
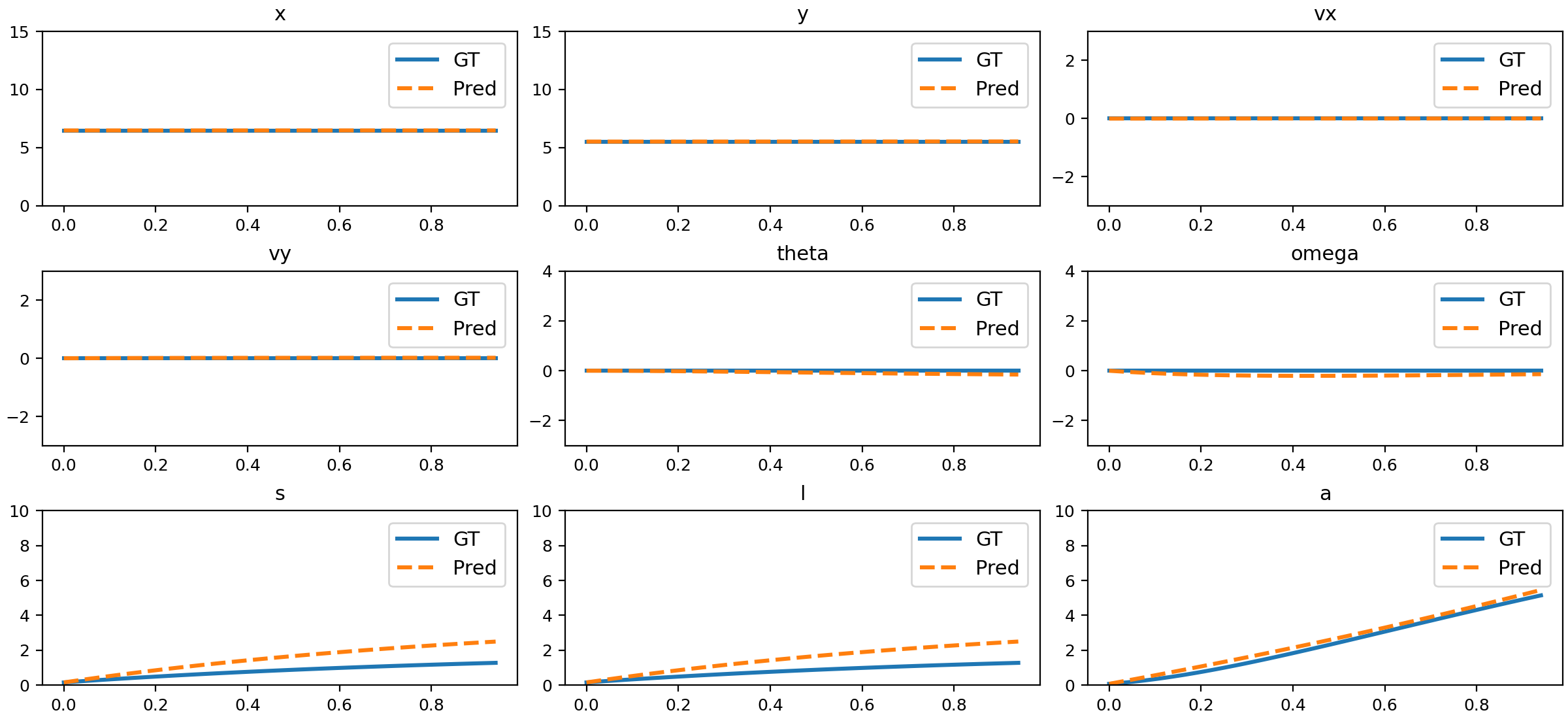
Figure 16: Comparison of NND predictions and ground truth for size changing.
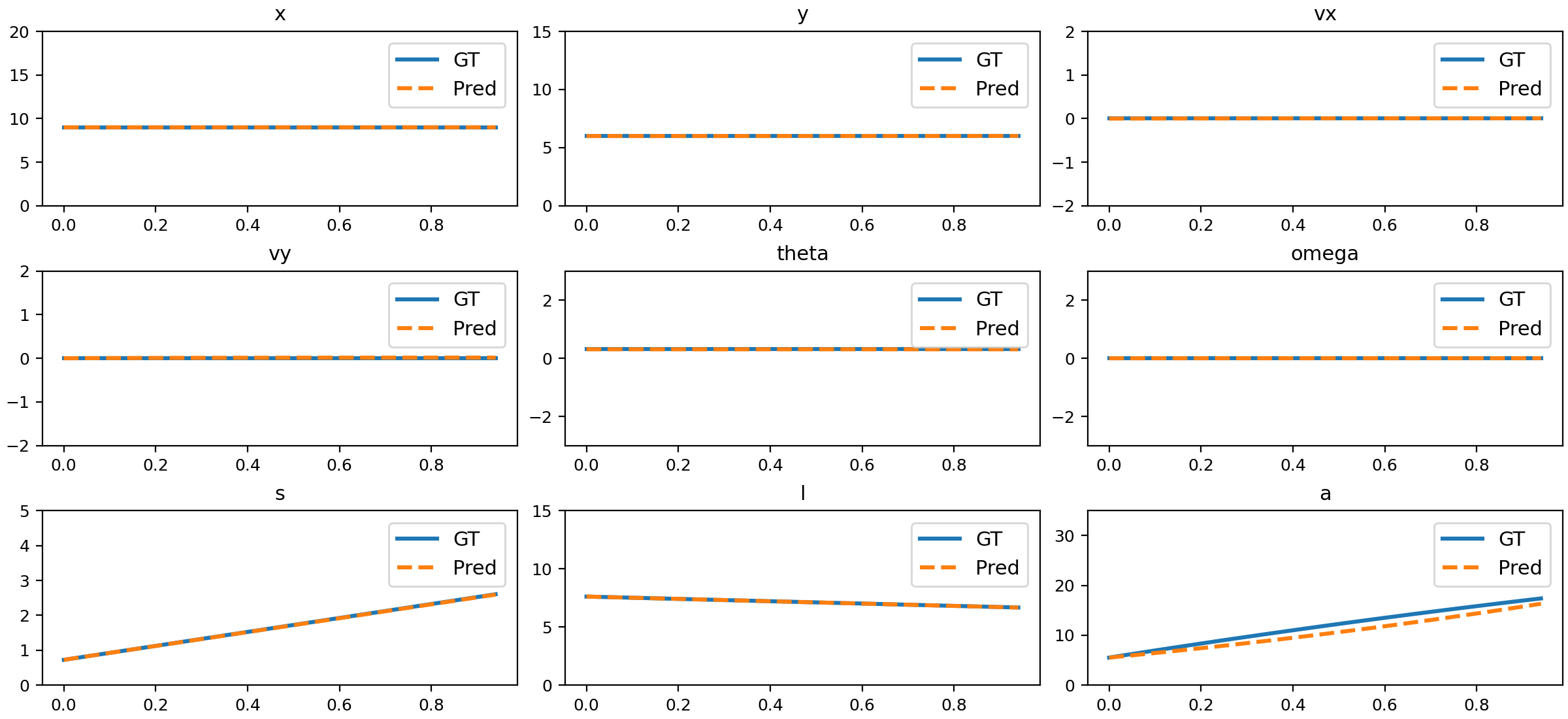
Figure 17: Comparison of NND predictions and ground truth for deformation.
Ablation Study
Ablation experiments show that the residual MLP in NND is critical for modeling nonlinear dynamics and noisy data. Increasing the training dataset size beyond 100 samples yields diminishing returns, indicating that NND can infer system dynamics from limited physics-clean data.
Implementation Considerations
- Computational Efficiency: NND is lightweight, trained in latent space, and inference is real-time or faster.
- Data Requirements: Physics-clean data is essential; the simulator provides precise control over initial conditions and world settings.
- Generalization: The hybrid approach enables out-of-distribution generalization, outperforming purely data-driven or simulation-based methods.
- Limitations: NewtonGen is restricted to continuous dynamics and does not handle discrete events (collisions, explosions) or multi-object interactions without further architectural extensions.
Implications and Future Directions
NewtonGen demonstrates that explicit integration of physical laws into generative models is essential for bridging the gap between visual realism and physical plausibility. The framework enables interpretable, white-box control over generated motion, supporting applications in scientific visualization, education, robotics simulation, and digital content creation. Future work should address multi-object interactions, event-based dynamics, and integration with more complex physical systems.
Conclusion
NewtonGen introduces a physics-consistent and controllable text-to-video generation paradigm by integrating Neural Newtonian Dynamics with data-driven synthesis. The approach achieves state-of-the-art physical consistency and parameter controllability across a wide range of motion types, validated by strong quantitative and qualitative results. This work advances the field toward generative models that are not only visually compelling but also physically grounded, with broad implications for AI systems interacting with the real world.

