- The paper introduces PhyGDPO, achieving physically consistent text-to-video generation through a novel physics-aware direct preference optimization framework.
- It leverages the PhyAugPipe pipeline and groupwise Plackett-Luce modeling to enrich training data and enhance motion coherence.
- The study demonstrates significant empirical improvements and efficiency gains, setting a new baseline for physics-driven video synthesis.
Physics-Aware Groupwise Direct Preference Optimization for Physically Consistent Text-to-Video Generation
Introduction and Motivation
The pursuit of text-to-video (T2V) models that generate videos not only with high visual fidelity but also with strong physical realism remains a challenging open problem. While recent large-scale T2V generators excel in visual quality, they frequently produce videos violating basic physical laws, especially in complex activity categories such as human motion, object-object interaction, and physics phenomena. Prior approaches—including graphics-based simulation and LLM-driven prompt extension—are constrained by poor generalization, impracticality in real-world scenarios, reliance on LLM physics reasoning weaknesses, or limited ability to foster implicit physics understanding. There is also a scarcity of well-curated datasets focusing on physics-rich interactions, impeding further advancement.
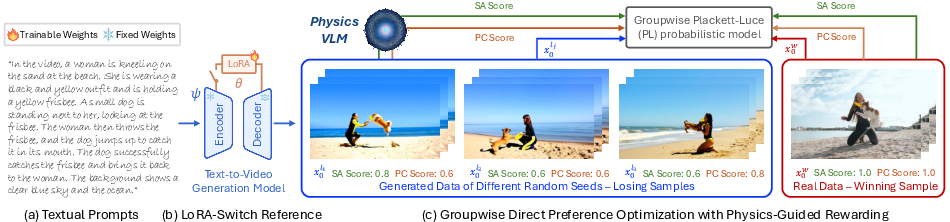
This work introduces PhyGDPO, a comprehensive framework aimed at instilling physical consistency into T2V generators. PhyGDPO is centered on three technical innovations: (1) PhyAugPipe, a VLM-powered pipeline for constructing large-scale physics-rich training data; (2) a novel groupwise direct preference optimization (DPO) method leveraging Plackett-Luce modeling with physics-guided rewards; and (3) LoRA-Switch Reference, a memory- and efficiency-optimized reference model mechanism. Taken together, these enable both improved data coverage and optimization targeted at physics-driven generative fidelity.
Physics-Augmented Data Construction: PhyAugPipe
The data pipeline, PhyAugPipe, is designed to systematically harvest text-video pairs capturing diverse physical interactions and phenomena from large, unstructured corpora. It employs Qwen-2.5-72B-Instruct as a vision-LLM (VLM) with chain-of-thought (CoT) parsing routines for each candidate, decomposing the prompt and frames into objects, materials, actions, and force relationships. This process quantifies physics richness (from 0 to 1), thresholds for sufficient physical complexity, and auto-extends prompts with explicit causal reasoning though not used in PhyGDPO training proper. Semantics-based action clustering over the filtered set ensures diverse coverage across challenging categories; reward-driven sampling, using a specialized physics-aware VLM (VideoCon-Physics), balances the dataset toward actions where the generator struggles, thus maximizing physics learning opportunity.
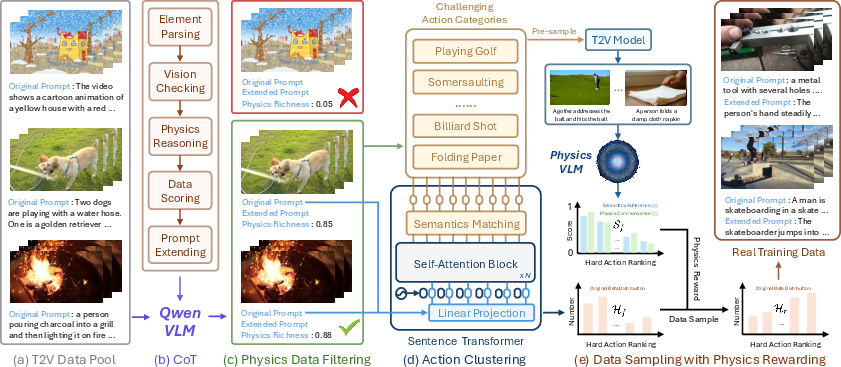
Figure 1: The PhyAugPipe pipeline for constructing a physics-rich text-video dataset via VLM parsing, CoT reasoning, and physics-aware reward-driven sampling.
PhyGDPO Framework: Groupwise Physics-Aligned Preference Optimization
The optimization framework of PhyGDPO leverages several key innovations over standard DPO:
Empirical Results and Comparative Evaluation
Extensive benchmarking is performed on both the VideoPhy2 and PhyGenBench datasets, specifically designed for evaluating physics-grounded generative ability. When applied to the Wan2.1-T2V-14B model, PhyGDPO demonstrates significant quantitative improvements over state-of-the-art open and closed-source alternatives, including OpenAI Sora2 and Google Veo3.1, across physics-centric tasks.
- Hard action (VideoPhy2): PhyGDPO yields 0.0500, compared with Sora2 (0.0389), Veo3.1 (0.0444), and VideoDPO (0.0167), a 4.5× gain over the base model on hard categories.
- Physical phenomena (PhyGenBench): PhyGDPO consistently obtains state-of-the-art or co-leading scores across mechanics, optics, thermal, and material tracks, with a notable advantage in mechanics and thermal.
- Human evaluation: User studies show that videos generated with PhyGDPO are preferred by up to 94.2% (vs. VideoCrafter2) and 89.4% (vs. VideoDPO) of annotators in head-to-head comparison for physical realism.

Figure 3: Qualitative demonstration across a spectrum of challenging action-driven video categories, showing enhanced physical plausibility and realistic interactions via PhyGDPO.

Figure 4: Outputs on gymnastics and polo; PhyGDPO enforces deformation-free dynamics and realistic contact interactions, surpassing prior models.

Figure 5: Generalization to arbitrary user-input actions; physically accurate racket-ball and body coordination are observed.

Figure 6: Successful modeling of complex phenomena (e.g., light refraction, flame propagation) not captured by baseline generative models.
Component and Ablation Analysis
Through systematic ablation, each subsystem of PhyGDPO is validated:
- PhyAugPipe stages: Removing CoT, clustering, or physics-driven sampling diminishes performance, demonstrating the need for each to acquire challenging and informative data.
- Core PhyGDPO mechanisms: The replacement of groupwise modeling or PGR with standard DPO or without LoRA-SR leads to substantial drops in particularly hard physical tracks.
- LoRA-SR impact: Achieves up to 44% less GPU memory usage and 60× storage compression, with consistent or superior numerical scores and visual results, compared to vanilla full-model reference approaches.

Figure 7: Visual progression as LoRA-SR, groupwise loss, and physics-guided rewarding are engaged, with notable improvements in adherence to physics, coherence of body pose, and object-object contact accuracy.
Theoretical and Practical Implications
PhyGDPO sets forth a scalable solution for aligning video foundation models with physical laws via explicit reward guidance and preference supervision at scale. The introduction of groupwise preference modeling marks a theoretically well-motivated improvement over the ubiquitous pairwise schemes. PGR demonstrates the advantages of integrating physics-aware rewarders, suggesting a pathway towards broader behavioral alignment (beyond aesthetic preference) in generative models. LoRA-SR unlocks practical, efficient DPO post-training for extremely large models.
Practically, the framework enables physics-grounded video synthesis relevant to simulation, gaming, autonomous systems, robotics, and scientific visualization. The dataset construction strategy, allied with preference-based optimization, admits extensions towards new physical phenomena, further encompassing real-world complexity.
Conclusion
PhyGDPO represents an integrated framework for post-training T2V generators to adhere to physical realism, leveraging curated physics-rich data, groupwise preference models, and dynamic physics-guided rewards, all undergirded by efficient memory management. Its strong empirical performance in both automated and human assessments establishes new baselines in physically consistent video generation. Future directions include expansion to causal intervention tasks, actor-conditioned simulation, and real-time generative agents tightly integrated with downstream physical reasoning engines.