- The paper introduces PhysChoreo, a two-stage framework that reconstructs per-part physical fields to enable controllable physics in video generation.
- It employs segmentation priors, soft assignment, and hierarchical cross-attention for fine-grained material property prediction from images.
- Experimental results show improved material accuracy and physical commonsense, outperforming state-of-the-art methods in visual fidelity and semantic alignment.
PhysChoreo: Physics-Controllable Video Generation with Part-Aware Semantic Grounding
Motivation and Context
Contemporary image-to-video generation frameworks exhibit limitations in explicit physical plausibility and controllability of generated content. Existing approaches are primarily inductive, learning to mimic visible motion patterns from large-scale data but failing to encode causal knowledge of physics, resulting in sequences that lack behavioral realism—especially under nontrivial or counterfactual manipulations. Previous attempts to integrate physical simulation into the generative process either impose coarse predictions lacking part-level granularity or are constrained by insufficiently flexible simulation mechanisms. The PhysChoreo framework is introduced to address these constraints with a unified architecture capable of reconstructing per-part physical fields from images and delivering temporally-instructed, physically grounded, and controllable video generation.
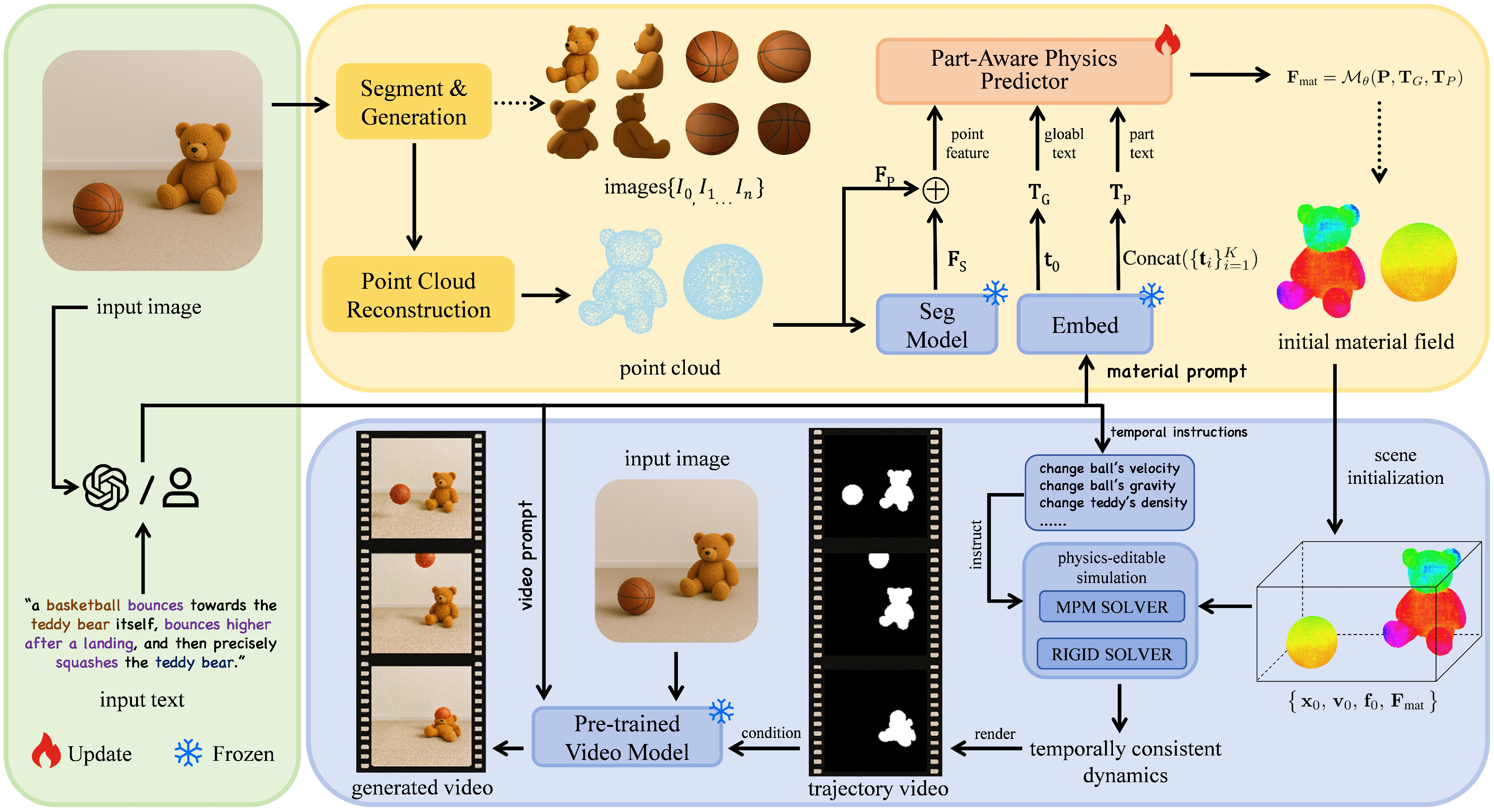
Figure 1: Overview of the PhysChoreo pipeline, illustrating the transition from image and prompt input to trajectory-based conditional generative video synthesis.
Methodology
PhysChoreo is architected as a two-stage pipeline. The first stage performs part-aware physical property reconstruction, while the second stage synthesizes dynamic video sequences via physics-editable simulation guided by temporally-structured user instructions.
Part-Aware Physics Reconstruction
This module infers fine-grained material fields for objects segmented from the input image, leveraging both global and part-level textual prompts. The pipeline utilizes segmentation priors, positional features, and transformer-based encoding to produce interpretable physical properties at point cloud granularity. Information injection proceeds via soft assignment—aligning part text prompts with spatial features—followed by hierarchical cross-attention for coherence across both global and local semantic levels.
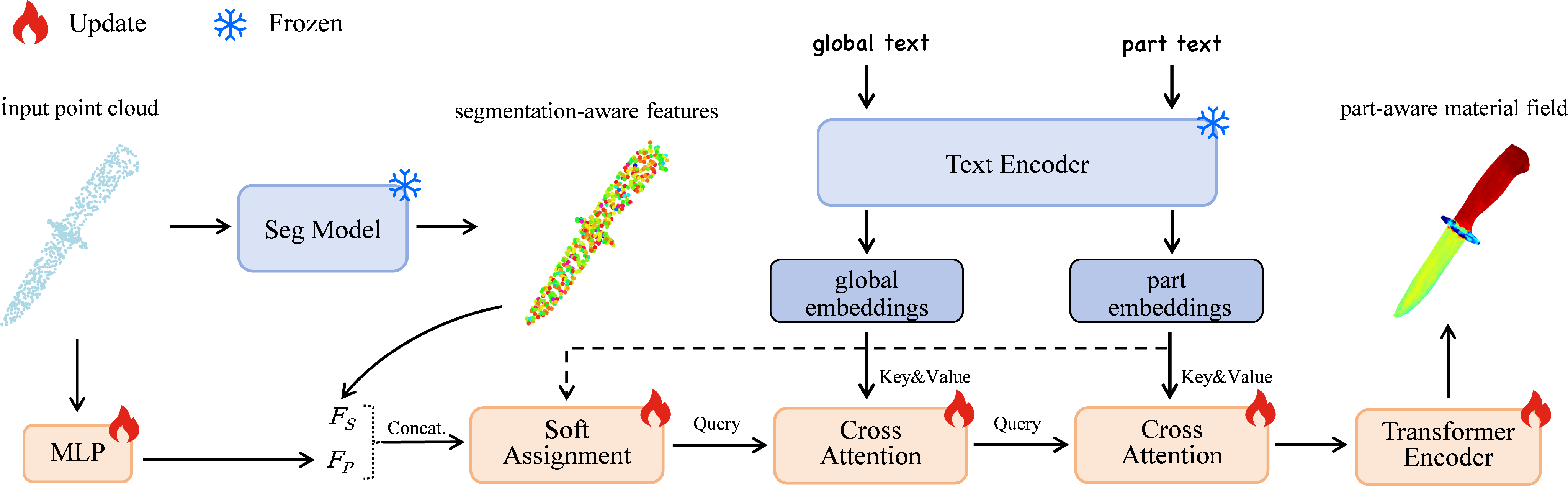
Figure 2: Schematic of the model architecture demonstrating fused feature embedding, soft assignment, cross-attention, and transformer-based part-aware material field prediction.
Multi-component supervision is applied, comprising:
- Point-wise task loss for semantic and continuous parameter regression.
- Wave continuity constraints reflecting spatial smoothness in physically derived velocity fields for both cp and cs.
- Contrastive regularization to enforce part-wise separability in moduli space, optimizing interface behaviors.
- Cross-entropy alignment between soft assignment distributions and ground-truth part labels.
The net effect is robust, interpretable per-point material and dynamic parameter prediction aligned both textually and geometrically.
Physics-Editable Video Generation
The predicted physical fields initialize object states in physics simulators (e.g., MPM, rigid body), allowing temporal control of parameters such as Young's modulus, density, external forces, and constitutive models. Temporal interventions—including transitions like liquefaction, deformation, counter-intuitive motion responses—are directly programmable and propagate through dynamic simulation. This yields physically plausible motion trajectories, subsequently utilized as conditioning for state-of-the-art generative video models.
Volumetric completion is achieved by interior particle generation from surface points, maintaining seamless property propagation via k-NN interpolation. The simulation-generated trajectory serves as the video model’s control input, ensuring semantic and physical congruence in the output videos.

Figure 3: Demonstration of part-level physical property prediction controllable through textual conditions.
Dataset Construction
The authors assembled a large-scale point cloud dataset, coupling hierarchical part segmentation, rich textual annotation, and physically grounded material properties (including modulus, density, Poisson’s ratio). Counterfactual labels were deliberately included to test the model’s ability to infer nonstandard physical semantics, enhancing generalization capability and stress-testing the language-physics interface.
Experimental Results
Physical Property Prediction
Quantitative comparison shows PhysChoreo surpasses NeRF2Physics, PUGS, and Pixie across all evaluation metrics:
- Material model prediction accuracy: 0.789 (Ours) vs. 0.628 (NeRF2Physics)
- logE error: 0.661 (Ours) lowest among baselines
The model demonstrates explicit controllability at the part level using text-based instructions, enabling downstream physically faithful simulations.
Physics-Controllable Video Generation
PhysChoreo’s generated videos are evaluated using Gemini-2.5-Pro and direct user studies, with metrics covering semantic alignment (SA), physical commonsense (PC), and visual quality (VQ). The model achieves the best scores on PC and SA, outperforming methods like PhysGen3D, Wan2.2-5B, CogVideoX-3, and Veo 3.1.

Figure 4: Qualitative comparison between PhysChoreo and other state-of-the-art image-to-video models, illustrating physical plausibility and complex dynamic behaviors.
PhysChoreo supports diverse temporal manipulations and robustly realizes cinematic and counterfactual physical behaviors (e.g., liquefaction, collapse, abnormal bounces) while maintaining visual fidelity and coherence.

Figure 5: PhysChoreo-generated sequences showing high visual quality and physical realism under fine-grained physical property control.
Ablation Studies
Component-level ablations verify the effectiveness of soft assignment, hierarchical cross-attention, and segmentation prior in improving prediction accuracy and learning convergence. Removal of any loss function module (assignment, smoothness, contrast) decreases accuracy and increases error, substantiating their necessity for robust physical field reconstruction and editability.

Figure 6: Qualitative ablation showing differences in control efficacy among alternative trajectory and conditioning strategies.
Implications and Future Directions
PhysChoreo advances the interface between semantic language conditioning and precise physical modeling in generative frameworks, making a decisive step towards causally robust, counterfactually controllable video synthesis. The part-aware semantic grounding introduces new degrees of fine-grained editability and interpretability, with implications for robotics simulation, physics-based animation, and scientific visualization. However, the current restriction to independently behaving objects and limited internal state inference signals opportunities for scaling to larger, multi-object scenes and enhancing interior property modeling. The unification of semantic and physical parameter editing promises scalable extensions to reasoning, planning, and interactive AI agents.
Conclusion
PhysChoreo provides an effective framework for reconstructing part-wise physical fields from images and leveraging them for physics-grounded, controllable video generation. Its explicit integration of physical simulation and textual semantics sets new standards for realism, editability, and alignment in generative visual models. Continued development should focus on scene-scale generalization and internal state estimation to broaden applicability and fidelity.