PhysMaster: Mastering Physical Representation for Video Generation via Reinforcement Learning
Abstract: Video generation models nowadays are capable of generating visually realistic videos, but often fail to adhere to physical laws, limiting their ability to generate physically plausible videos and serve as ''world models''. To address this issue, we propose PhysMaster, which captures physical knowledge as a representation for guiding video generation models to enhance their physics-awareness. Specifically, PhysMaster is based on the image-to-video task where the model is expected to predict physically plausible dynamics from the input image. Since the input image provides physical priors like relative positions and potential interactions of objects in the scenario, we devise PhysEncoder to encode physical information from it as an extra condition to inject physical knowledge into the video generation process. The lack of proper supervision on the model's physical performance beyond mere appearance motivates PhysEncoder to apply reinforcement learning with human feedback to physical representation learning, which leverages feedback from generation models to optimize physical representations with Direct Preference Optimization (DPO) in an end-to-end manner. PhysMaster provides a feasible solution for improving physics-awareness of PhysEncoder and thus of video generation, proving its ability on a simple proxy task and generalizability to wide-ranging physical scenarios. This implies that our PhysMaster, which unifies solutions for various physical processes via representation learning in the reinforcement learning paradigm, can act as a generic and plug-in solution for physics-aware video generation and broader applications.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces PhysMaster, a way to help video-generating AI models follow real-world physics (like gravity, collisions, and fluid motion). Today’s models can make videos that look great, but they often show impossible actions—objects float, bounce strangely, or liquids move like jelly. PhysMaster adds a “physics sense” to these models so the videos look realistic and obey physical laws.
Key Questions
The paper focuses on three simple questions:
- How can we make AI-generated videos obey physics, not just look good?
- How can an AI pick up physics clues from a single starting image (like where objects are, what they’re made of, and how they might move)?
- Since there’s no perfect recipe for “physics features,” how can we train the AI to learn them anyway?
How They Did It (Methods)
The Task: Image-to-Video
The model starts with one image (the first frame) and a short text description, then predicts what should happen next. For example: If the image shows a ball held above the ground, the model should predict that it falls, speeds up, and bounces depending on the material.
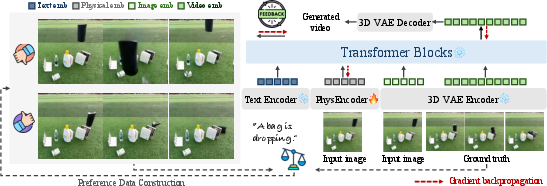
The PhysEncoder: A “Physics Sense” Add-On
PhysMaster creates a plug-in called PhysEncoder. Think of it like a physics-aware lens:
- It looks at the first image and tries to understand physics clues: object positions, materials (metal vs. cloth), and likely interactions (falling, sliding, splashing).
- It turns these clues into an extra “physics feature” that the video model uses alongside normal visual features and the text prompt.
- This helps the model predict motion that makes sense under physical laws.
In simple terms: PhysEncoder is the part that says, “Given this scene, here’s how things should move in the real world.”
Learning with Feedback Instead of Exact Labels
There’s no easy way to label “the correct physics features,” so the authors use a top-down strategy: judge the final video and work backwards.
- The model generates two videos from the same starting image and prompt but with different random seeds.
- Humans compare the two and choose which one follows physics better.
- Using these preferences, the system learns to make “better” videos more likely and “worse” ones less likely.
This is called reinforcement learning with human feedback (RLHF). A specific method named Direct Preference Optimization (DPO) is used: it nudges the model toward the preferred outcomes by using the pairwise choices.
Training in Three Stages
To make everything work smoothly, training happens in three steps:
- Supervised Fine-Tuning (SFT):
- Give the model lots of examples to learn basic image-to-video prediction.
- Train PhysEncoder and the video model together so they “talk” to each other.
- DPO for the Video Model:
- Use human preferences to tune the video model so it favors physically plausible videos.
- DPO for PhysEncoder:
- Freeze the tuned video model.
- Now, train the PhysEncoder alone using the same feedback, so it learns to extract physics clues that truly help the model produce realistic motion.
This three-step plan teaches the model to respect physics and teaches PhysEncoder what kind of information is most helpful.
Datasets and Evaluation
- Proxy Task (Special Case): “Free-fall” videos (objects dropping and colliding) made with a simulator. Good for testing basic physics like gravity and collisions.
- Open-World Physics: A large, varied dataset of real-world events (like pouring water, light reflections, hot/cold changes) across dynamics, thermodynamics, and optics.
- Evaluation:
- For free-fall: measure how close object trajectories and shapes are to ground truth (metrics like L2, Chamfer Distance, IoU).
- For open-world: measure physics commonsense (PC) and semantic adherence (SA), which check whether the video both follows physics and matches the prompt.
What They Found
The results show clear improvements:
- Better “free-fall” physics: Compared to strong baselines (PhysGen and PISA), PhysMaster keeps object shapes more consistent and produces realistic trajectories and collisions.
- Strong generalization: It doesn’t just work for falling objects—it helps across many physics cases (like fluids and light), boosting both physics commonsense and prompt matching.
- Efficient and practical: It produces 5-second videos much faster than some physics-heavy methods, while still improving realism.
- Ablation studies (careful comparisons) show the full three-stage training works best:
- Simply fine-tuning isn’t enough.
- Reinforcement learning with human preferences unlocks PhysEncoder’s ability to learn useful physics features.
- Training the video model first (Stage 2), then the PhysEncoder (Stage 3), gives the strongest and most general results.
Why It Matters
PhysMaster moves video generation closer to being a reliable “world model”—a system that can simulate what would realistically happen next. That’s important because:
- Realistic motion makes videos more believable and useful (for movies, games, education).
- Physics-aware generation can help teach science concepts, simulate experiments, and create safer AI systems that understand cause-and-effect.
- The plug-in design means you can add physics sense to different video models without completely rebuilding them.
Implications and Potential Impact
PhysMaster offers a practical way to inject physics understanding into video AI:
- It helps generative models stop “cheating” on physics and start acting more like the real world.
- It can be used in many areas: science education (visualizing experiments), robotics (predicting object motion), creative tools (film previsualization), and research (testing physical hypotheses).
- While it currently uses human feedback, the authors note that even small amounts (like 500 labeled pairs) already help a lot. As AI judges of physics improve, this approach could scale even further.
In short, PhysMaster is a smart, plug-in assistant that teaches video models to respect physics, leading to more realistic, trustworthy, and widely useful AI-generated videos.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored, formulated to be actionable for future work:
- Definition and interpretability of the “physical representation”
- No formal definition or taxonomy of the learned physical representation (e.g., whether it encodes mass, friction, elasticity, support relations, force fields).
- Lack of interpretability analyses beyond PCA; unclear if factors disentangle known physical variables or scene graph elements (contacts, constraints, material classes).
- No causal tests to show representation invariance/equivariance to nuisance factors (lighting, texture) while being sensitive to physical attributes.
- Scope of physics covered and systematic evaluation
- Proxy task centers on free-fall; rotational dynamics, rolling/sliding with friction, restitution, multi-contact, deformables/cloth, non-Newtonian fluids, soft-body interactions, and long-horizon stability are not systematically quantified.
- Open-world evaluation uses VIDEOPHY’s SA/PC but lacks per-phenomenon/category breakdown, stress tests, or metrics tied to conservation laws (energy/momentum), non-penetration, or contact plausibility.
- No quantitative evaluation under camera motion, occlusion-heavy scenes, dynamic lighting, or long durations beyond 5 seconds.
- Reliance on human preference labels
- Human-in-the-loop DPO is costly and subjective; criteria, rater instructions, inter-rater agreement, and label noise robustness are not reported.
- Positive/negative pair construction uses the same model with different seeds; this can induce selection bias and may not reflect absolute physical correctness.
- Unclear how performance scales with label volume, quality, or domain shifts; sample-efficiency and active learning strategies remain unexplored.
- Limitations of AI or automatic physics feedback
- Paper notes current AI evaluators are unreliable; no exploration of hybrid or self-supervised physics reward models (e.g., contact violation detectors, depth/flow/pose consistency, rigid-body constraints) to reduce human labeling burden.
- No study of reward hacking (model exploiting evaluator weaknesses) or calibration/robustness of any learned reward.
- Training pipeline design choices and ablations
- PhysEncoder training only updates the physical head in Stage III; the effect of unfreezing/fine-tuning the DINOv2 backbone is not studied (capacity bottleneck vs generalization).
- No ablation on where/how to inject physical embeddings (concat vs cross-attention vs FiLM modulation) and how this affects generalization and stability.
- DPO objectives and hyperparameters (β, LoRA rank/placement, sampling temperature, preference curriculum) lack sensitivity analyses and principled tuning guidelines.
- Joint vs staged optimization shows mixed results; the conditions under which joint optimization overfits or generalizes are unclear.
- Generality and portability of the plug-in
- Claimed “plug-in” generality is shown on a single DiT-based I2V backbone; not validated across multiple architectures (flow-based vs diffusion vs flow-matching variants), scales, or text-to-video models.
- Transferability to tasks beyond I2V (T2V, video editing/inpainting, controllable video) and to multi-view/3D-consistent generation remains untested.
- Dependence on prompt engineering (physics prefixes)
- Use of domain-specific prompt prefixes (e.g., “Optic, …”) for open-world data introduces an external cue; unclear how much performance depends on this crutch versus the learned representation.
- Robustness without prefixes or under contradictory/misleading prompts is not evaluated.
- Data coverage and bias
- WISA-80K coverage, label balance, and bias toward certain scenes, materials, or motions are not analyzed; sensitivity to dataset shifts (e.g., rare materials, unusual geometries) remains unknown.
- Kubric synthetic free-fall vs real-world domain gap: no targeted analysis of transfer failures or techniques to bridge them.
- Long-horizon and stability
- Videos are short (~5s); no evaluation of drift, accumulating physical inconsistencies, or trajectory stability over longer horizons.
- No assessment of temporal coherence under re-sampling or auto-regressive rollouts.
- Competing explanations for gains
- Improvements may stem from better geometry/depth priors (Depth Anything initialization) rather than physics understanding; disentangling these factors is not attempted.
- Missing comparisons against simpler conditioning baselines (e.g., explicit depth/normal maps, optical flow, segmentation/contact maps) at equal compute.
- Objective design and multi-objective alignment
- DPO optimizes implicit human-judged “physics plausibility” but does not explicitly balance semantic adherence vs physics; trade-offs and Pareto fronts are not explored.
- No structured multi-objective RL setup (e.g., separate rewards for contact, conservation, goal adherence) or constraints-based training.
- Failure modes and robustness
- No catalog of systematic failure cases (e.g., interpenetration, ground-plane misestimation, floating artifacts, perpetual motion prompts) or stress-test benchmarks.
- Adversarial or counterfactual prompts (violating physics on purpose) and the model’s behavior (refusal vs realistic correction vs compliance) are unstudied.
- Theoretical and optimization questions
- No analysis of convergence or stability of DPO when optimizing a conditioning encoder while keeping the generator mostly fixed.
- Unclear how encoder-induced distribution shifts interact with the pretrained generator’s learned score/velocity field.
- Efficiency and practicality
- Inference is faster than some baselines, but real-time generation is not achieved; training compute and memory footprints for all stages are not fully reported.
- Data-efficient alternatives (e.g., preference distillation, synthetic preference generation, offline RL from curated physics heuristics) are not evaluated.
- Downstream utility as a world model
- Although framed as moving toward “world models,” no experiments show utility for prediction, planning, or control (e.g., counterfactual queries, intervention sensitivity, or physical parameter estimation).
- No tests of generalization to action-conditioned or agent-in-the-loop settings.
- Safety, ethics, and misuse
- No discussion of ethical risks (e.g., realistic but subtly incorrect physics in safety-critical contexts), transparency, or calibrated uncertainty about physical predictions.
These gaps suggest concrete directions: formalizing and interpreting the representation, constructing scalable and reliable physics rewards, broadening physics coverage and benchmarks, validating portability across backbones and tasks, reducing reliance on prompt prefixes and human labels, and probing long-horizon stability and downstream utility in decision-making.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging PhysMaster’s plug-in PhysEncoder, DPO training workflow, and image-to-video diffusion backbones. They assume access to a base I2V model, modest preference-labeling capacity (~500 pairs sufficed in the paper), and standard GPU inference.
- Physically consistent previz and storyboarding for media production
- Sectors: media/entertainment, advertising, game studios, VFX
- What to build: a PhysEncoder plug-in for existing I2V pipelines that reduces “impossible” motion (e.g., interpenetration, non-inertial drift) in previsualization clips and animatics; a “physics-aware mode” in creative tools that conditions on the first frame and a physics-prefixed prompt
- Workflow: import first frame → add physics prefix to prompt (e.g., “Dynamics: …”) → generate 3–10 s clip with PhysEncoder+DiT → iterate on camera/objects
- Assumptions/dependencies: not a numerical simulator; suitable for visual plausibility rather than engineering precision; requires prompt discipline and representative first frames
- Physics-aware content generation for education and science communication
- Sectors: education, edtech, science outreach
- What to build: a lesson authoring assistant that turns a still image of a setup (e.g., ramp, pendulum, prism) plus a short description into videos that respect gravity, collisions, basic optics, and thermal effects; a library of “physics-consistent” explainer clips
- Workflow: teacher provides a photo or diagram → prompt with physics domain tags → generate illustrative videos aligned with VIDEOPHY-style commonsense
- Assumptions/dependencies: visual plausibility only; parameter-controlled demonstrations (exact angles/coefficients) need careful curation or hybridization with simulators
- Synthetic data generation with improved physical plausibility
- Sectors: robotics (perception), autonomous systems, CV research, ML ops
- What to build: a data pipeline that generates I2V clips exhibiting realistic object motion, contacts, and fluids to augment training for depth/flow/segmentation/tracking and physical prediction tasks
- Workflow: curate first frames from real captures or 3D renders → generate multiple plausible rollouts via different seeds → filter by VIDEOPHY-style scorers → feed downstream training
- Assumptions/dependencies: distribution shift risks; physics commonsense ≠ precise dynamics; downstream tasks must be tolerant to residual artifacts
- Physics guardrails for generative video tools
- Sectors: creative software, UGC platforms
- What to build: a “physics-checked generation” toggle that conditions the model with PhysEncoder; a post-hoc filter that regenerates sequences with better physical adherence when violations are detected
- Workflow: run baseline I2V → detect obvious violations (e.g., object passes through table) via heuristics/flow-depth checks → re-run with PhysEncoder conditioning or stronger CFG
- Assumptions/dependencies: detection heuristics needed; adds latency (though ~26 s for 5 s video on A800 suggests practical throughput)
- Rapid prototyping for game and XR motion beats
- Sectors: gaming, XR/AR
- What to build: tools for designers to preview rigid-body and fluid motion beats (drops, splashes, rolling, bouncing) from concept art/greybox screenshots
- Workflow: capture in-engine frame → generate physics-aware motion reference → artists refine or hand-animate over reference
- Assumptions/dependencies: reference quality sufficient for ideation, not final animation fidelity; edge cases (non-Euclidean or stylized physics) may need custom prompts
- Physics-oriented benchmark and model evaluation augmentation
- Sectors: research/academia, foundation model teams
- What to build: an evaluation harness that pairs generative runs with VIDEOPHY/WISA-derived prompts and measures physical commonsense (PC) and semantic adherence (SA) while ablation-testing with/without PhysEncoder
- Workflow: for each model release, run fixed prompt sets → compare PC/SA improvements from the PhysEncoder plug-in → report regressions
- Assumptions/dependencies: coverage of PC metrics still evolving; human validation recommended for ambiguous cases
- Cost-effective RLHF pipeline for physics alignment
- Sectors: AI platform teams, applied ML
- What to build: a lightweight DPO preference-labeling loop (pairwise “more physical vs less physical”) to continually align base I2V models with physics without full simulation
- Workflow: sample seeds per prompt-frame pair → collect 300–1,000 human preference pairs → Stage II (LoRA on DiT) then Stage III (DPO on PhysEncoder) → redeploy
- Assumptions/dependencies: label quality and rater training matter; biases in prompts can steer alignment
- Product demos with realistic motion and fluids
- Sectors: e-commerce, marketing, industrial marketing
- What to build: short I2V promos (e.g., liquid pouring, device falling onto desk, sunlight refracting through glass) that feel physically credible without setting up full simulations
- Workflow: staged product photo → brief prompt → physics-aware short → manual QC
- Assumptions/dependencies: not a substitute for compliance/claims; avoid implying performance specs; legal review for consumer claims
Long-Term Applications
These applications need further research and engineering (e.g., action conditioning, calibrated parameters, scalable evaluators, real-time performance) or broader validation beyond open-world commonsense.
- Action-conditioned world models for robotics and autonomy
- Sectors: robotics, autonomous driving, logistics
- What to build: physics-aware video world models that predict outcomes under actions (push, grasp, steer) using PhysEncoder as a physical prior fused with action tokens
- Potential tools: action-conditioned DiT variants; multi-view fusion; contact-aware training data
- Assumptions/dependencies: requires action-labeling and control interfaces; must meet safety and OOD robustness standards; likely needs hybrid learning + simulation or real data
- Physics-aware video editing and “make it obey physics” repair
- Sectors: creative software, post-production
- What to build: editors that detect and correct physically implausible motion (e.g., adjust timing for gravitational acceleration, fix interpenetrations) by regenerating segments with PhysEncoder guidance
- Potential tools: violation detectors (conservation checks, collision tests), localized I2V inpainting, temporal constraints
- Assumptions/dependencies: reliable automatic detection; fine-grained regional control over video diffusion models
- Domain-specific design exploration (simulation-accelerated ideation)
- Sectors: industrial design, packaging, architecture, urban mobility
- What to build: “early-phase” visual explorers for drop tests, spillage, crowd flow, or light paths to rapidly screen concepts before high-fidelity simulation
- Potential tools: parameter sliders (material, gravity), weak calibration to measured properties, design-space exploration UIs
- Assumptions/dependencies: not a replacement for accredited simulation/FEA; would require calibration datasets and uncertainty quantification
- Physics plausibility scoring and deepfake detection
- Sectors: trust & safety, policy, media platforms
- What to build: a scoring service that flags videos with physically implausible dynamics (e.g., inconsistent accelerations, impossible reflections) to aid moderation or misinformation detection
- Potential tools: train a dedicated reward model (AI evaluator) for physics plausibility to replace/augment human labels; integrate with provenance signals
- Assumptions/dependencies: reducing false positives on stylized content; adversarial robustness; acceptable use policies
- Interactive education and “what-if” labs from a single image
- Sectors: edtech
- What to build: students manipulate materials, gravity, or initial conditions and instantly see resulting videos that obey commonsense physics
- Potential tools: parameter-conditioned PhysEncoder; sliders for environment factors; on-device inference
- Assumptions/dependencies: needs controllable conditioning beyond text; real-time or near-real-time performance on modest hardware
- Multimodal physical inference from a single frame
- Sectors: scientific ML, materials and vision research
- What to build: models that infer latent physical properties (friction, elasticity, density) while generating consistent rollouts, using PhysEncoder as the representation backbone
- Potential tools: joint training on small labeled physics datasets; probabilistic inference over physical parameters
- Assumptions/dependencies: scarcity of labeled ground truth; disentanglement challenges; need for evaluation protocols
- Real-time physics-aware AR overlays
- Sectors: mobile, AR/VR
- What to build: smartphone apps that generate physics-consistent motion previews for virtual objects interacting with the real scene (rolling balls, pouring fluids)
- Potential tools: distillation/quantization of PhysEncoder+DiT; depth/normal estimation; environment mapping
- Assumptions/dependencies: latency constraints; robustness to sensor noise; battery/thermal limits
- Sector-specific training simulators and safety content
- Sectors: industrial training, workplace safety
- What to build: scenario libraries (forklift maneuvers, slips/trips, load shifts) with physically plausible dynamics to enhance retention and hazard recognition
- Potential tools: templated prompts, domain-tuned PhysEncoder, human-in-the-loop validation
- Assumptions/dependencies: scenario accuracy requirements; legal/liability considerations; may require hybridization with deterministic simulators
- Search and retrieval by physical behavior
- Sectors: media asset management, surveillance, research
- What to build: indexing and retrieval using physical-behavior embeddings (rolling vs sliding, bouncing vs sticking, laminar vs turbulent)
- Potential tools: use PhysEncoder as a feature extractor fine-tuned for behavior classification; build a “physics query” API
- Assumptions/dependencies: supervised labeling for behaviors; generalization across scenes and styles
- Platform SDKs and SaaS for physics-aware generation
- Sectors: developer platforms, creative SaaS
- What to build: a hosted “Physics-Aware I2V API” exposing: PhysEncoder conditioning, physics domain prompting, DPO alignment toolkit, and validation reports (PC/SA metrics)
- Assumptions/dependencies: customer data governance; GPU cost management; privacy/compliance for uploaded frames
Cross-cutting dependencies and risks
- Data and label quality: physics preference labels are subjective; rater training and clear guidelines are required.
- Scope of physics: approach captures visual commonsense, not precise numerical simulation; avoid safety-critical claims without calibration.
- Domain shift: extreme scenes, stylized content, or non-Newtonian/quantum-like prompts may degrade performance.
- Compute and latency: while efficient relative to baselines (~26 s for a 5 s clip on an A800), mobile/real-time use cases require distillation and optimization.
- Governance and ethics: tools used for moderation or detection must manage bias, explainability, and due-process concerns.
Glossary
- Ablation study: A systematic experiment where components or training stages are varied to assess their impact. "Ablation study for models from different training stages and strategies on proxy task"
- Classifier-Free Guidance (CFG): A diffusion sampling technique that balances conditional and unconditional scores to control fidelity versus diversity. "set the CFG scale to 7.5 during inference."
- DDIM (Denoising Diffusion Implicit Models): A deterministic or semi-deterministic sampler for diffusion models that reduces steps needed for generation. "we utilize 50 DDIM steps~\citep{song2020denoising}"
- Depth Anything: A pretrained depth estimation framework used here to initialize the semantic encoder for physical representation learning. "Following the structure of Depth Anything~\citep{yang2024depth}, we build PhysEncoder"
- DINOv2: A self-supervised vision transformer producing robust visual features, used as the backbone encoder. "with a DINOv2~\citep{oquab2023dinov2} encoder"
- Direct Preference Optimization (DPO): An RLHF objective that optimizes a model to prefer human-chosen outputs over rejected ones while staying close to a reference. "via Direct Preference Optimization~(DPO)~\citep{rafailov2023direct} in a three-stage training pipeline."
- DiT (Diffusion Transformer) model: A transformer-based diffusion architecture for video generation. "PhysMaster is implemented upon a transformer-based diffusion model~(DiT)~\citep{peebles2023scalable}"
- Flow Matching objective: A training objective for flow-based generative models that learns velocity fields to match target flows. "with the Flow Matching objective~\citep{lipman2022flow}"
- Flow-DPO: A DPO formulation tailored to flow-based diffusion models, aligning predicted velocities with preferred samples. "Flow-DPO objective~\citep{liu2025improving} is then given by:"
- Google Scanned Objects (GSO) dataset: A high-quality collection of 3D scanned household items used for synthetic physics scenes. "The object assets are sourced from the Google Scanned Objects~(GSO) dataset~\citep{downs2022google}."
- Image-to-Video (I2V): A generation task that predicts future frames from an initial image conditioned on text or other signals. "Based on I2V setting, PhysMaster extracts physical representation from the input image"
- KL-divergence: A measure of divergence between probability distributions used as a regularization term in preference optimization. "regularization term~(KL-divergence)"
- Kubric: A scalable synthetic data generator used here to build controlled physics datasets. "use Kubric~\citep{greff2022kubric} to create synthetic datasets of ``free-fall''."
- Latent space: A compressed representation space where videos and frames are encoded for diffusion modeling. "to transform videos and initial frame to latent space"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects trainable low-rank matrices into large models. "we apply LoRA~\citep{hu2021lora} to finetune the DiT model"
- Material Point Method (MPM): A physics simulation approach that models continuum materials using particles, enabling deformable object dynamics. "relies on MPM-based simulation to generate coarse videos"
- Mixture-of-Experts: An architecture that routes inputs to specialized expert modules to improve performance across diverse domains. "uses Mixture-of-Experts for different physics categories."
- PCA (Principal Component Analysis): A dimensionality reduction technique for visualizing and analyzing learned feature structure. "We also visualize the principal component analysis~(PCA) on the physical features"
- PhysEncoder: The proposed physical encoder that extracts physics-aware embeddings from the input image to guide generation. "PhysEncoder encodes its physical feature and concatenates with visual features"
- PhysGen: A rigid-body physics-grounded I2V baseline that infers parameters and simulates dynamics to guide generation. "PhysGen~\citep{liu2024physgen} utilizes rigid-body dynamics simulated with physical parameters inferred by large foundation models."
- PisaBench: An evaluation benchmark for physics-grounded video generation focusing on tasks like free-fall. "PisaBench~\citep{li2025pisa} is introduced to evaluate our model's performance on the proxy task."
- Reinforcement Learning with Human Feedback (RLHF): A paradigm that aligns generative models using human preference signals. "reinforcement learning with human feedback~(RLHF) framework"
- Rigid-body dynamics: The physics governing motion and collisions of non-deformable bodies. "utilizes rigid-body dynamics simulated with physical parameters inferred by large foundation models."
- T5 encoder: A text-to-text transformer used to produce text embeddings conditioning the video generator. "and T5 encoder ~\citep{raffel2020exploring} for text embeddings ."
- Variational Autoencoder (VAE): A probabilistic encoder–decoder model that maps inputs to a latent distribution; here in 3D for videos. "employs 3D Variational Autoencoder~(VAE) to transform videos and initial frame to latent space"
- VIDEOPHY: An evaluation suite assessing physical commonsense and semantic adherence in generated videos. "We utilize VIDEOPHY~\citep{bansal2024videophy} for evaluating physics awareness"
- VideoAlign: A method that uses a learned video reward model and DPO to improve alignment in video generation. "VideoAlign~\citep{liu2025improving} introduces a multi-dimensional video reward model and DPO"
- VideoDPO: A framework adapting DPO to video diffusion generation with omni-preference alignment. "VideoDPO~\citep{liu2024videodpo} pioneers the adaptation of DPO~\citep{rafailov2023direct} to video diffusion models"
- Vision-LLM (VLM): A multimodal model that jointly understands visual and textual inputs; used as an external evaluator in some baselines. "feedback from VLM"
- WISA: A physics-aware video generation approach that injects structured physical information and leverages experts. "WISA~\citep{wang2025wisa} incorporates structured physical information into the generative model and uses Mixture-of-Experts for different physics categories."
- WISA-80K: A large-scale dataset of real-world physical events across multiple physics branches used for training and evaluation. "we utilize WISA-80K~\citep{wang2025wisa} encompassing 17 types of real-world physical events across three major branches of physics~(Dynamics, Thermodynamics, and Optics)."
Collections
Sign up for free to add this paper to one or more collections.