- The paper harnesses reward-weighted regression to overcome modality disconnects and improve text-to-image semantic alignment.
- It introduces the MMGW dataset targeting model failure modes to boost performance on benchmarks, achieving up to a ninefold improvement in text rendering.
- The unified post-training approach automates modality transitions, demonstrating robust gains in alignment, factuality, and compositional reasoning across evaluations.
Unified Text-Image Generation with Weakness-Targeted Post-Training: An Expert Technical Review
Introduction
The research addresses persistent limitations in unified multimodal generative models for text-to-image (T2I) synthesis, specifically the disconnect between text reasoning and visual token generation in state-of-the-art architectures. Current multimodal T2I systems, such as BAGEL, typically employ a staged generation pipeline with manual modality switching, resulting in suboptimal semantic alignment and difficulty in fully automating cross-modal inferencing. The paper proposes a post-training methodology that leverages reward-weighted regression (RWR) over both modalities, optimizes on a targeted synthetic dataset focused on model weaknesses, and introduces a fully unified inference scheme whereby text and image tokens are generated in a single interleaved context.

Figure 1: Post-training enables unified text-image generation, recovering performance on previously failed prompts and achieving fully automatic multimodal output.
Problem Domain and Prior Art
Multimodal generative models have evolved along several architectural paradigms: unified Transformers with diffusion/image-flow modules, fully autoregressive token-based models, and hybrid pipelines that combine discrete language and vision components. While unified autoregressive approaches (e.g., Chameleon, Janus-Pro) provide the technical capacity for interleaved modality generation, practical deployment struggles to achieve true semantic coupling across modalities, largely due to training and reward signal limitations. Previous approaches for improving T2I reasoning have included intermediate text generation, self-consistency selection, or interleaved iterative refinement (e.g., IRG), but have not automated the reasoning-to-image switch in highly competitive settings.
Methodology
Unified Modality-Switching and Reward-Weighted Post-Training
The base architecture, BAGEL (Mixture-of-Transformers, 14B parameters), is augmented by learning to generate a modality-switch token (<|vision_start|>) that signals transition from text reasoning to image synthesis. Training utilizes packed sequences of text and visual tokens, with gradient updates every 50k tokens. The core post-training protocol employs reward-weighted regression (RWR), exponentiating sample-wise rewards and weighting each loss term accordingly for effective credit assignment across modalities:
wRWR(x0,c)=exp(β r(x0,c))
with β=5.0 and normalized QwenVQAScore rewards.
Weakness-Targeted Synthetic Dataset: MMGW
Selecting effective post-training data is critical for driving improvement. The researchers construct the Multi-Modal Generative Weaknesses (MMGW) dataset, comprising prompts known to systematically induce generation failures in vision-LLMs. Five semantic categories (Relative Positions, Object Orientation, Text, Cardinality, Structural Characteristics) are manually curated and then expanded via LLM-based prompt synthesis. Each prompt is sampled 100 times, generating both text traces and images, yielding a high-variance dataset tightly coupled to failure modes.
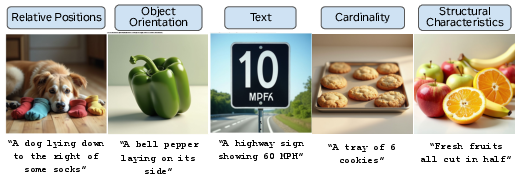
Figure 2: MMGW Dataset: representative prompts and failure generations from five semantics categories reliably challenging unified multimodal models.
Reward Functions for Discriminative Labeling
A suite of reward functions is evaluated for their ability to distinguish successful generations from failures: PickScore, AestheticScore, ImageReward, CLIPScore, JPEGScore, and QwenVQAScore (a VQA model probability-based metric). QwenVQAScore uniquely produces a bimodal global and intra-prompt reward distribution, sharply separating high-quality from low-quality outputs, while others exhibit unimodal distributions with weak discriminative power.
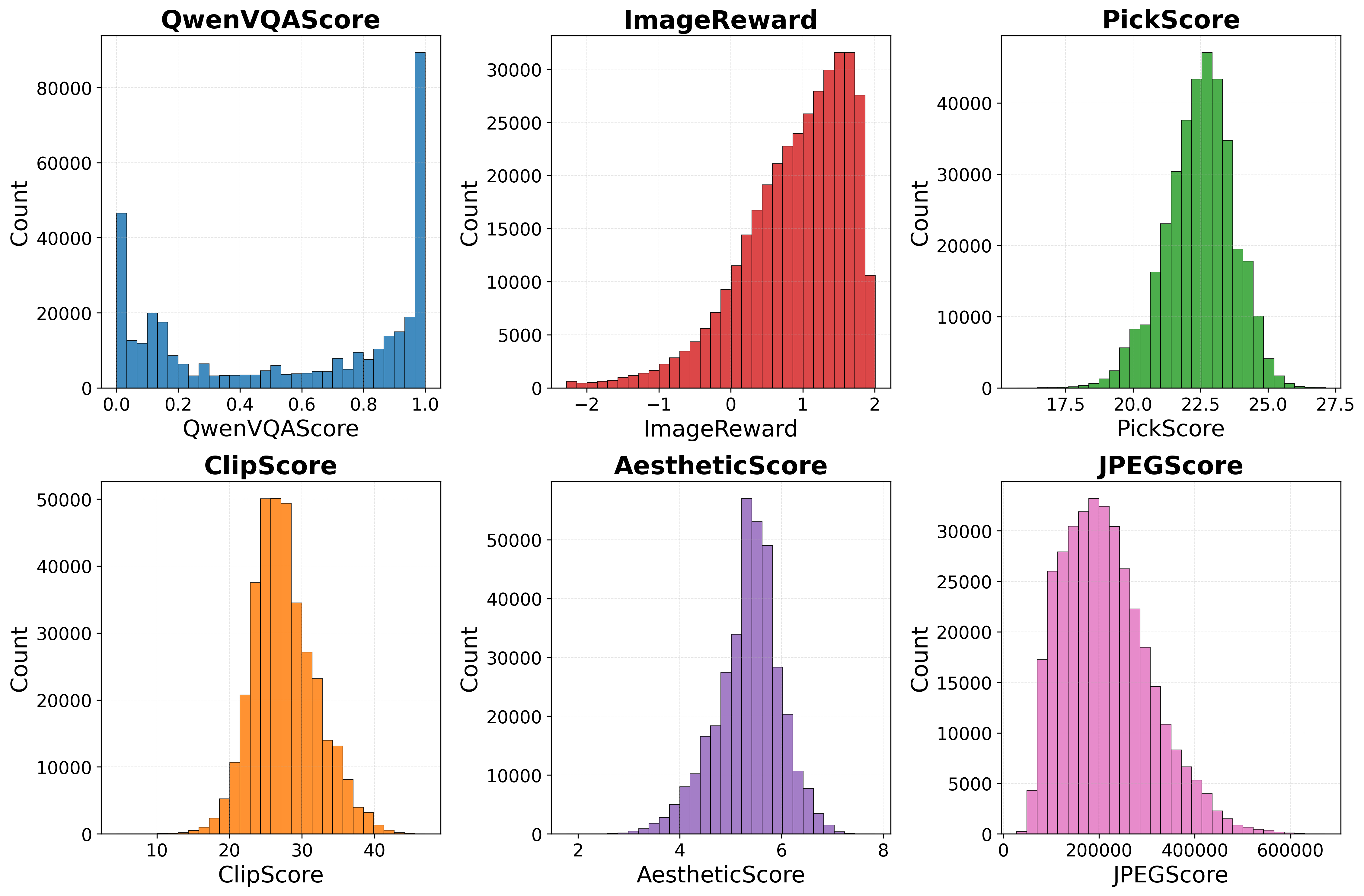
Figure 3: Only QwenVQAScore yields bimodal reward distributions, critical for effective reward-weighted regression; other metrics lack intra-task variance.
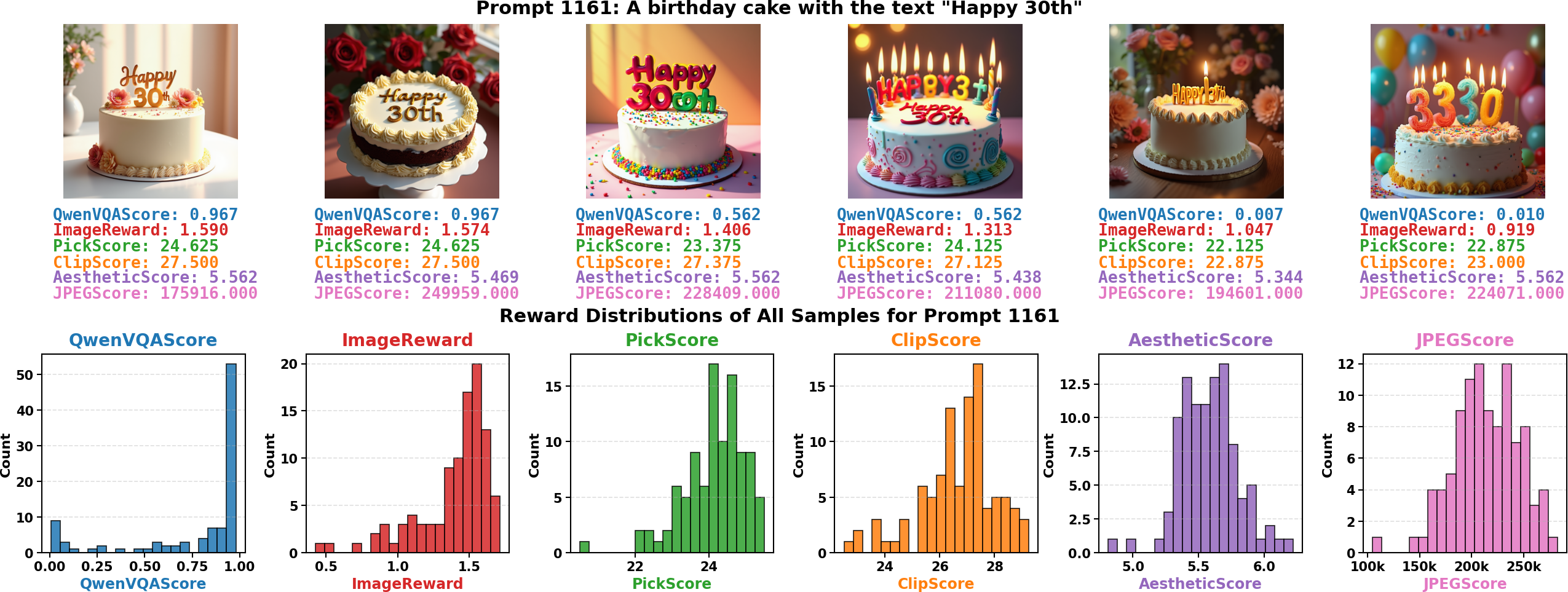
Figure 4: QwenVQAScore intra-prompt reward distributions reveal sharp separability of good and bad samples needed for robust learning.
All experiments subsequently use QwenVQAScore for sample weighting.
Quantitative and Qualitative Results
Joint Modality RWR Optimization
Empirical evaluation across four major benchmarks (GenEval, DPG-Bench, WISE, OneIG-Bench) indicates that multimodal RWR yields the most consistent gains. On GenEval, Multimodal RWR achieves the top overall alignment score and outperforms both image-only and multimodal baselines, with up to 4% gain in object-centric prompt alignment. On WISE, which assesses knowledge-intensive generation, Multimodal RWR delivers superior scores in Chemistry, Physics, and Space, indicating improved compositional and factual grounding. On OneIG-Bench, Multimodal RWR achieves a ninefold increase in text rendering accuracy over the multimodal baseline. DPG-Bench results demonstrate that multimodal post-training closes the performance gap to image-only generation and exceeds all existing multimodal models in several categories.

Figure 5: Visual sample from OneIG-Bench demonstrating superior text rendering by image-only BAGEL, with Multimodal RWR remedies partially closing the gap.
Failure Analysis: Text Rendering in Multimodal Context
Despite improvements, certain tasks (notably text rendering in OneIG-Bench) remain challenging for multimodal models. Conditioning on reasoning traces sometimes degrades performance compared to image-only methods, due to input overload or misalignment in textual-to-visual mappings. While Multimodal RWR substantially narrows this gap (raising the text score from 0.020 to 0.189), image-only approaches still achieve higher clarity.
Data Ablation: Training Strategy Impact
Comparative ablations reveal that the MMGW dataset is decisively stronger than both large-scale image-caption datasets (e.g., Shutterstock) and benchmark-aligned synthetic prompts (e.g., GenEval-generated), delivering robust improvements across all benchmarks except diversity. General-purpose captions degrade performance on knowledge-intensive tasks, confirming the importance of tailoring post-training data to model weaknesses for optimal adaptation.
Practical and Theoretical Implications
This research demonstrates that unified multimodal architectures benefit from targeted post-training procedures that exploit reward-weighted self-generated data focused on failure modes. By tightly coupling reward signals to discriminative metrics (QwenVQAScore), the model can autonomously learn when to transition modalities and improve reliability in joint text-image generation. The approach underscores the inadequacy of standard supervised fine-tuning and suggests reward-driven synthetic bootstrapping as a critical tool for next-generation multimodal foundation models.
The main claims substantiated by numerical results are:
- Reward-weighted regression on both modalities yields consistent improvements on alignment, factuality, and text rendering benchmarks: 4% object alignment gain, 2% knowledge generation gain, ninefold text rendering improvement.
- Weakness-targeted synthetic datasets (MMGW) outperform both general caption corpora and benchmark-aligned prompts, confirming that error-centric data assembly is central for post-training efficacy.
Future Directions
Several open problems remain: unified multimodal generation trails image-only models on text rendering and some fine-grained compositional tasks. Adaptive modality selection, improved reasoning-text integration, and task-aware context modulation are promising avenues. Quantitative analysis of when joint text-image generation is beneficial versus detrimental could further inform architecture refinement. The demonstrated RWR protocol and MMGW-style data curation are generalizable to other modalities and tasks, suggesting broad applicability for model adaptation and robustness.
Conclusion
The study advances unified multimodal generation by integrating reward-weighted post-training with error-focused synthetic datasets, automating the transition from text reasoning to image generation within a single inference call. Analytical and empirical results conclusively favor jointly optimized reward signals and dataset curation rooted in failure analysis. The proposed methods set a new standard for post-training adaptation in multimodal generative models, with implications for future research on modality coupling, error-driven self-improvement, and architecture design for omni-modal foundation models (2601.04339).