- The paper introduces a unified autoregressive model that decouples visual encoding for generation and understanding.
- It employs a four-stage progressive training curriculum and rigorous reward modeling to ensure high-fidelity outputs.
- Empirical results show competitive performance on benchmarks using only 1.5B activated parameters, enabling commodity deployment.
Skywork UniPic: Unified Autoregressive Modeling for Visual Understanding and Generation
Introduction
Skywork UniPic introduces a unified autoregressive architecture that integrates image understanding, text-to-image (T2I) generation, and image editing within a single, parameter-efficient model. The design addresses the fragmentation and inefficiency of prior multimodal systems, which often rely on separate models or connector modules for different tasks. UniPic leverages a decoupled encoding strategy—using a Masked Autoregressive (MAR) encoder for generation and a SigLIP2 encoder for understanding—both feeding into a shared 1.5B-parameter LLM backbone. This approach enables high-fidelity multimodal integration without the computational overhead of massive models, achieving state-of-the-art results on standard benchmarks while remaining deployable on commodity hardware.
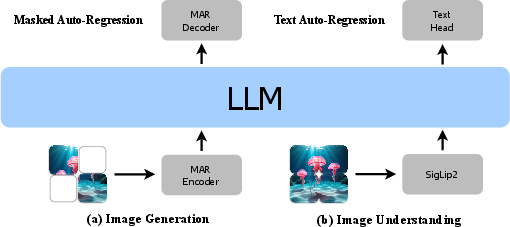
Figure 1: The overall framework of Skywork UniPic. (a) Image generation is achieved through a masked auto-regressive process using the MAR model. (b) Image understanding is performed using a SigLIP2 encoder, both feeding a shared LLM for unified processing.
Architectural Innovations
Decoupled Visual Encoding
UniPic's core innovation is the decoupling of visual encoding for generation and understanding. The MAR encoder-decoder pair is optimized for pixel-level fidelity in generation tasks, while the SigLIP2 encoder is specialized for semantic-rich representations required for understanding. Both encoders project their outputs into the shared embedding space of a Qwen2.5-1.5B-Instruct LLM via dedicated MLPs, enabling bidirectional knowledge transfer and unified instruction following.
This design resolves the semantic-fidelity dichotomy inherent in prior unified models, where a single encoder often leads to suboptimal performance due to conflicting optimization objectives. By allowing each encoder to specialize, UniPic achieves strong performance across all modalities without architectural complexity or reliance on connector modules.
Progressive, Resolution-Aware Training
UniPic employs a four-stage progressive training curriculum:
- MAR Pretraining: Focused on generation, especially face and complex object synthesis.
- MAR-LLM Alignment: Projects MAR outputs to the LLM embedding space with frozen LLM parameters.
- Joint Optimization: Unfreezes the LLM for cross-modal tuning under a multi-task objective, balancing generation and understanding losses.
- Supervised Fine-Tuning: Refines the unified model using reward-filtered, high-quality samples, incorporating editing objectives.
Resolution is scaled from 2562 to 10242 during training, allowing the model to first master low-resolution tasks before adapting to high-resolution synthesis and editing.
Data Curation and Reward Modeling
UniPic's training corpus is constructed from a meticulously curated, 100M-scale dataset, filtered using two specialized reward models:
- Skywork-ImgReward: Assesses visual quality using Group Relative Policy Optimization (GRPO) and a custom ranking function.
- Skywork-EditReward: Evaluates editing accuracy and instruction alignment, trained on high-quality editing datasets.
Samples with reward scores below 0.9 are discarded, and additional quality checks (e.g., VQAScore) are applied to ensure data homogeneity and generalization across diverse visual categories.
Empirical Results
UniPic demonstrates competitive or superior results across multiple benchmarks, despite its compact parameter count:
- GenEval (T2I Generation): 0.86 overall, with strong performance in single object (98.44%) and two-object (92.42%) composition, and robust color/position understanding.
- DPG-Bench (Complex Generation): 85.5 overall, with high scores in global coherence, entity recognition, and relational reasoning.
- GEdit-Bench-EN (Editing): 5.83 overall, with 6.72 in semantic consistency and 6.18 in perceptual quality.
- ImgEdit-Bench: 3.49 overall, with strong results in action, style, and background editing.
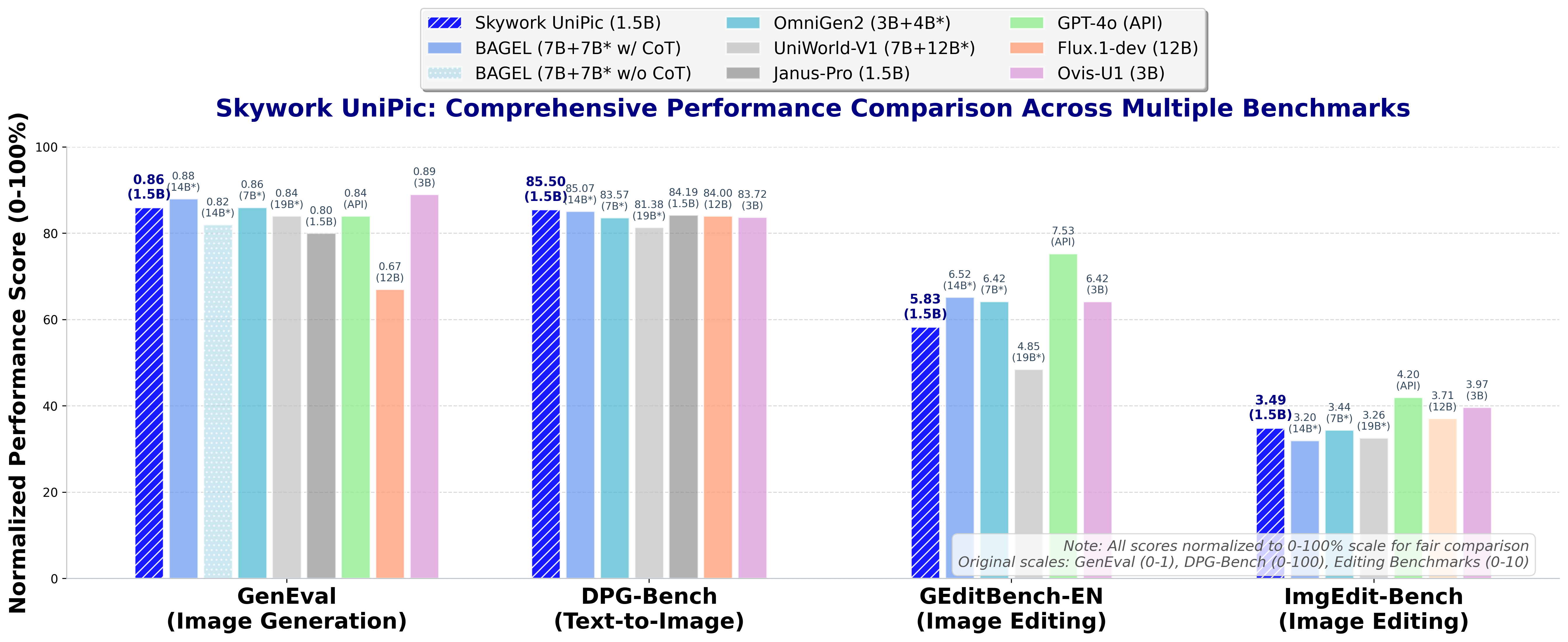
Figure 2: Performance comparison across multiple benchmarks. Skywork UniPic demonstrates competitive performance across understanding, generation, editing, and in-context tasks while maintaining exceptional parameter efficiency with only 1.5B activated parameters.
Qualitative Analysis
UniPic produces high-fidelity images that accurately reflect textual prompts and editing instructions, maintaining visual consistency and semantic alignment even in complex scenarios.

Figure 3: Qualitative comparison of text-to-image generation results. Skywork UniPic produces high-quality images that accurately reflect textual prompts while maintaining competitive visual fidelity compared to both open-source and proprietary models.

Figure 4: Qualitative comparison of image editing results. Skywork UniPic successfully handles diverse editing instructions while preserving image quality and maintaining consistency in unmodified regions, demonstrating the effectiveness of our unified approach.
Failure Modes
Despite strong overall performance, UniPic exhibits limitations in handling highly complex or ambiguous instructions, occasionally failing to adhere to prompts or producing incomplete edits.

Figure 5: Failure cases.
Analysis and Implications
Parameter Efficiency and Scalability
UniPic challenges the prevailing assumption that high-quality multimodal integration requires massive parameter counts and extensive compute. By leveraging architectural decoupling, progressive training, and rigorous data curation, UniPic achieves state-of-the-art results with only 1.5B activated parameters—an order of magnitude smaller than models like BAGEL (14B) or UniWorld-V1 (19B). This efficiency enables deployment on consumer-grade GPUs (e.g., RTX 4090), broadening accessibility for real-world applications.
Emergence of Capabilities
The staged emergence of capabilities—T2I generation appearing early, with editing abilities manifesting only in later training stages—highlights the complexity of instruction-based editing relative to direct generation. Notably, scaling understanding-centric data does not directly enhance generative or editing performance, underscoring the necessity of task-specific training strategies.
Practical and Theoretical Impact
Practically, UniPic's unified architecture simplifies deployment pipelines, reduces inference latency, and enables seamless multi-turn creative workflows. Theoretically, the decoupled encoding strategy provides a blueprint for resolving conflicting task requirements in unified models, and the progressive curriculum demonstrates the value of staged capability development.
Future Directions
Key areas for future research include:
- Enhancing performance on highly compositional or ambiguous instructions.
- Improving fine-grained editing precision, especially in challenging scenarios.
- Extending multilingual and cross-modal generalization.
- Further reducing computational requirements for even broader deployment.
The open-source release of UniPic's code, weights, and datasets is expected to catalyze further research in parameter-efficient, unified multimodal modeling.
Conclusion
Skywork UniPic establishes a new paradigm for unified multimodal AI, demonstrating that high-fidelity visual understanding, generation, and editing can be achieved within a single, compact autoregressive model. Its decoupled encoding strategy, progressive training, and rigorous data curation collectively enable strong empirical results and practical deployability. UniPic's design and open-source resources provide a foundation for future advances in efficient, unified vision-language systems.

