- The paper introduces UAE, an auto-encoder framework that unifies image-to-text and text-to-image tasks via a bidirectional reinforcement learning process.
- It employs a three-stage RL procedure that alternately optimizes the encoder and decoder to maximize semantic reconstruction fidelity using CLIP-based similarity rewards.
- Results demonstrate that UAE achieves superior unified scores (e.g., 86.09 on Unified-Bench) and excels in precise caption-to-image reconstructions compared to dedicated baselines.
Unified Multimodal Understanding and Generation via Auto-Encoder Paradigm: An Analysis of UAE
Introduction
The dichotomy between multimodal understanding (e.g., image-to-text) and generation (e.g., text-to-image) has historically impeded the development of unified multimodal models (UMMs) that can leverage mutual benefits across both tasks. The paper "Can Understanding and Generation Truly Benefit Together -- or Just Coexist?" (2509.09666) introduces a principled approach to this challenge by recasting the unification problem through the lens of auto-encoding. The proposed Unified Auto-Encoder (UAE) framework enforces a closed-loop, bidirectional information flow between understanding and generation, using reconstruction fidelity as a unified training and evaluation objective. This essay provides a technical analysis of the UAE framework, its reinforcement learning-based optimization (Unified-GRPO), empirical results, and implications for future multimodal AI systems.
Auto-Encoder Perspective for Multimodal Unification
The central insight of UAE is to treat multimodal understanding as encoding (image-to-text, I2T) and generation as decoding (text-to-image, T2I), binding them under a single, measurable objective: the semantic similarity between the input image and its reconstruction via the I2T→T2I loop.
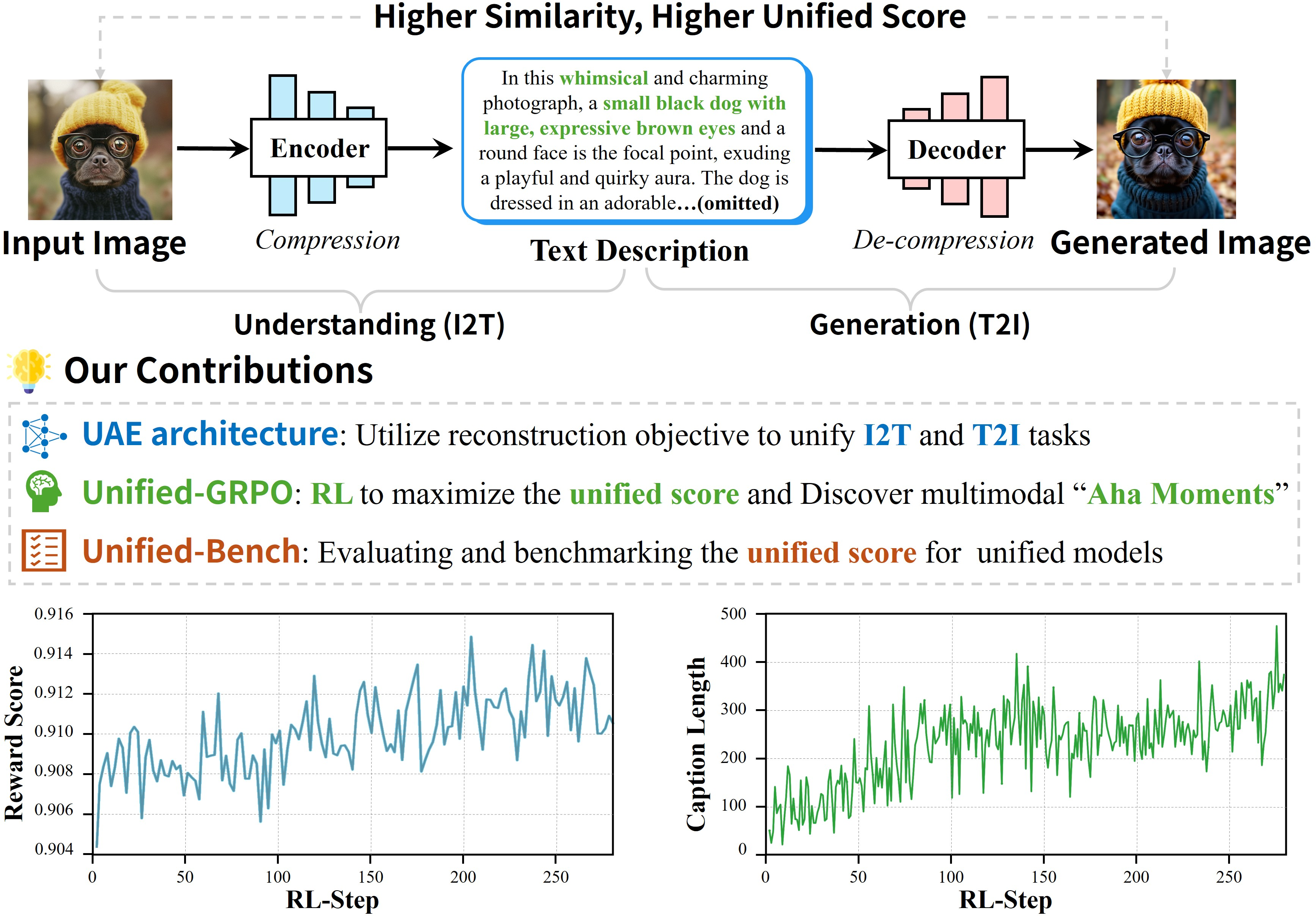
Figure 1: Illustration of the UAE auto-encoder paradigm, where the encoder produces a detailed caption and the decoder reconstructs the image, with reconstruction similarity serving as the unified score.
This paradigm compels the encoder to produce captions that are maximally informative for reconstruction, while the decoder is forced to leverage all semantic details in the caption. The result is a system in which improvements in one direction (e.g., more descriptive captions) directly benefit the other (e.g., more faithful image generation), and vice versa.
Unified-GRPO: Reinforcement Learning for Bidirectional Optimization
The UAE framework operationalizes this auto-encoder principle via a three-stage reinforcement learning procedure, Unified-GRPO, which alternately optimizes the encoder and decoder to maximize the unified reconstruction reward.
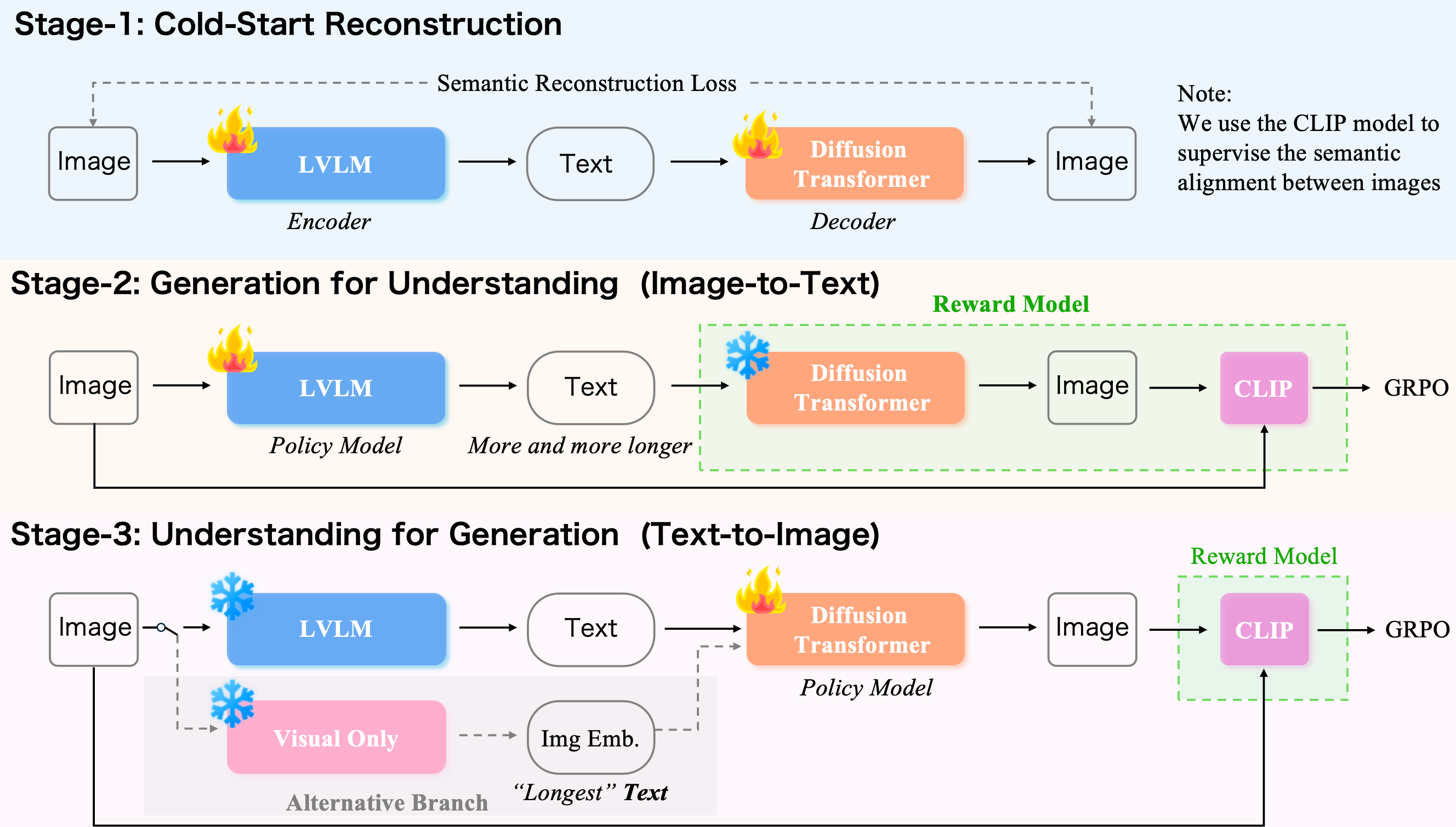
Figure 2: The Unified-GRPO workflow, comprising cold-start reconstruction, generation for understanding, and understanding for generation.
- Stage 1 (Cold-start Reconstruction): Both encoder (LVLM) and decoder (diffusion model) are initialized with a semantic reconstruction loss, ensuring basic alignment in the I2T→T2I loop.
- Stage 2 (Generation for Understanding): The encoder is optimized (decoder frozen) to produce captions that maximize the decoder's reconstruction quality, using a CLIP-based similarity reward.
- Stage 3 (Understanding for Generation): The decoder is optimized (encoder frozen) to reconstruct images from the encoder's captions, again maximizing the unified reward.
The GRPO algorithm is used to provide stable RL optimization, with group-based advantage estimation and KL regularization to prevent policy collapse. The reward is defined as the cosine similarity between CLIP embeddings of the original and reconstructed images, ensuring that the unified score reflects both semantic and perceptual fidelity.
Model Architecture and Data
UAE employs a modular architecture:
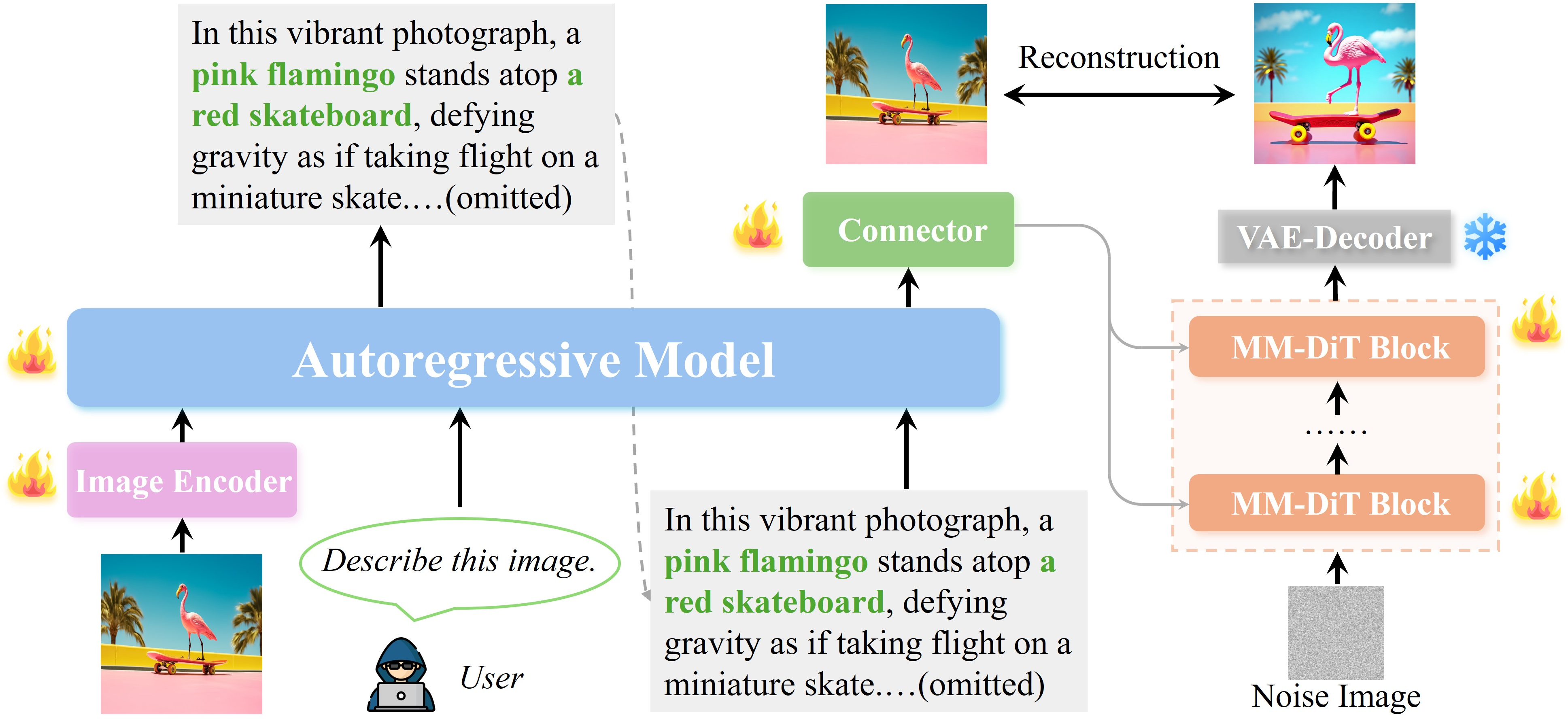
Figure 4: The UAE framework: an autoregressive LVLM encodes the image, a connector projects the representation, and a diffusion decoder reconstructs the image.
- Encoder: Qwen-2.5-VL 3B LVLM, which processes images and outputs a high-dimensional semantic representation.
- Connector: A lightweight MLP projects the LVLM's final hidden state into the decoder's conditioning space.
- Decoder: SD3.5-large diffusion model, adapted with a minimal projector head for conditioning.
Training leverages a 700K long-context image-caption dataset (captions >250 words, 1024px resolution), 50K GPT-4o-distilled samples for high-fidelity captioning, and 1K high-quality images for RL-based reconstruction optimization.
Empirical Results
Unified Evaluation
UAE achieves the highest overall unified score (86.09) on Unified-Bench, outperforming both dedicated and unified baselines, including GPT-4o-Image. Notably, UAE leads on CLIP, DINO-v2, and DINO-v3 backbones, indicating robust preservation of both layout and fine-grained semantics in the I2T→T2I loop.
Text-to-Image Generation
On GenEval, GenEval++, and DPG-Bench, UAE demonstrates strong compositional and instruction-following capabilities, particularly in multi-entity, multi-attribute, and spatially constrained scenarios.

Figure 3: Qualitative results from GenEval++, showing UAE's ability to generate images that accurately reflect complex, multi-entity captions.
UAE's performance is especially pronounced in categories requiring precise attribute binding, counting, and spatial arrangement, with leading or second-best scores across most sub-tasks.
Emergent Properties and Qualitative Analysis
A key empirical observation is the emergence of "aha moments" during RL: as the unified reward increases, the encoder's captions become longer and more detailed, and the decoder's reconstructions become more faithful.

Figure 5: As RL progresses, the encoder produces increasingly detailed captions, and the decoder generates more accurate reconstructions, evidencing bidirectional improvement.
This co-evolution is visualized in both quantitative trends (caption length, unified reward) and qualitative outputs, where UAE consistently outperforms baselines in capturing and rendering fine-grained semantics.
Discussion
On the Equivalence of Long-Text and Image Embedding Conditioning
The study finds that, after sufficient RL on long-text captions, conditioning the decoder on dense image embeddings yields only marginal gains. This suggests a practical equivalence between highly descriptive textual and visual embeddings for the purposes of reconstruction, provided the text is sufficiently comprehensive.
Implications for Editing and Text Rendering
The auto-encoder paradigm naturally extends to image editing by incorporating VAE latents for pixel-level preservation. However, text rendering remains a limitation due to insufficient text-rich training data and lack of OCR-based RL rewards. Future work should integrate OCR supervision and masked reconstruction losses to address these challenges.
Architectural and Data Considerations
The minimal encoder-connector-decoder design facilitates modularity and scalability. However, further improvements could be realized by refining the connector (e.g., structured adapters, multi-scale alignment) and scaling the long-text dataset. The results also highlight the critical role of long-context supervision in aligning vision and language representations for unified multimodal tasks.
Conclusion
The UAE framework demonstrates that true unification of multimodal understanding and generation is achievable via an auto-encoder-inspired, reconstruction-driven objective. The Unified-GRPO RL procedure enforces bidirectional improvement, as evidenced by both quantitative unified scores and qualitative outputs. The findings challenge the prevailing view that joint optimization of understanding and generation is inherently brittle, providing a concrete recipe for building UMMs with explicit, measurable mutual benefit. Future research should focus on scaling long-text supervision, refining architectural interfaces, and extending the unified objective to additional modalities and tasks.

