MMaDA-Parallel: Multimodal Large Diffusion Language Models for Thinking-Aware Editing and Generation
Abstract: While thinking-aware generation aims to improve performance on complex tasks, we identify a critical failure mode where existing sequential, autoregressive approaches can paradoxically degrade performance due to error propagation. To systematically analyze this issue, we propose ParaBench, a new benchmark designed to evaluate both text and image output modalities. Our analysis using ParaBench reveals that this performance degradation is strongly correlated with poor alignment between the generated reasoning and the final image. To resolve this, we propose a parallel multimodal diffusion framework, MMaDA-Parallel, that enables continuous, bidirectional interaction between text and images throughout the entire denoising trajectory. MMaDA-Parallel is trained with supervised finetuning and then further optimized by Parallel Reinforcement Learning (ParaRL), a novel strategy that applies semantic rewards along the trajectory to enforce cross-modal consistency. Experiments validate that our model significantly improves cross-modal alignment and semantic consistency, achieving a 6.9\% improvement in Output Alignment on ParaBench compared to the state-of-the-art model, Bagel, establishing a more robust paradigm for thinking-aware image synthesis. Our code is open-sourced at https://github.com/tyfeld/MMaDA-Parallel


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
The paper explores how to make AI systems better at editing and creating images based on text instructions when the AI also “thinks out loud” (writes reasoning steps). The authors discovered that the usual approach—think first, then draw—can sometimes make the images worse. To fix this, they built a new way for the AI to think and draw at the same time and a new test to measure how well the thinking matches the final picture.
The main questions the paper asks
- Why does adding a “thinking” step sometimes hurt image quality instead of helping?
- How can we measure not just the final image, but also the reasoning and how well the two match?
- Would generating text and images in parallel (at the same time) keep them in sync and reduce mistakes?
- Can we give the AI step-by-step rewards during generation to improve the match between text and image?
How the researchers approached the problem
A new test: ParaBench
The authors created ParaBench, a benchmark (a standardized test) with 300 challenging tasks:
- 200 image editing tasks (change something in an existing image).
- 100 image generation tasks (create a new image from scratch). ParaBench grades:
- Text: quality and alignment with the instructions.
- Image: quality, alignment with the instructions, and consistency.
- Output alignment: how well the text reasoning and the final image match each other.
Think of it like grading both the AI’s plan and its drawing, and checking whether the plan and the drawing agree.
A new model: MMaDA-Parallel
Instead of first writing all the reasoning and then generating the image, MMaDA-Parallel makes the AI think and draw together, step by step. Here’s the basic idea in everyday language:
- Diffusion generation: Imagine starting with a blurry sketch and gradually making it clearer. That’s what “denoising” means: removing noise step by step.
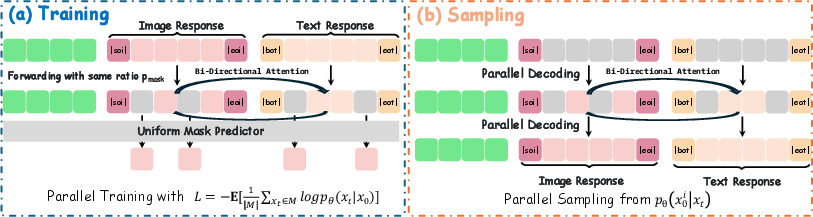
- Parallel multimodal generation: At each step of un-blurring, the AI updates both the text and the image. It can “look” at both drafts, so the words and the picture stay aligned.
- Discrete tokens: Both text and images are broken into small pieces (tokens), like puzzle pieces. The AI learns to fill in the masked (hidden) pieces across both text and image together, so they fit.
Analogy: It’s like two teammates—one writing descriptions, one drawing—working side by side, constantly checking each other’s work at every step, instead of one person finishing their part before the other even starts.
Training the model
- Supervised fine-tuning: The team collected training examples with four parts: input image, instruction, reasoning text, and final output image. They used a strong multimodal model to create the reasoning text when datasets didn’t include it.
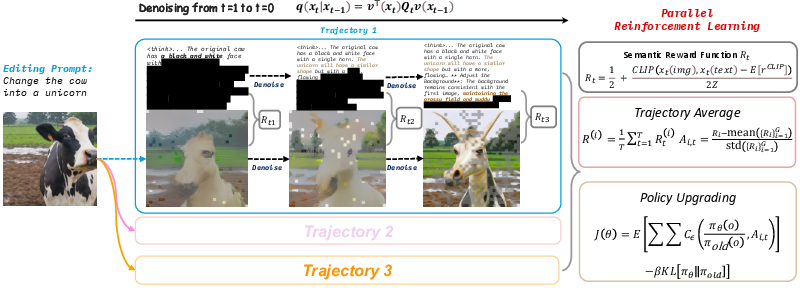
- Parallel Reinforcement Learning (ParaRL): After fine-tuning, they taught the model further by giving small “rewards” during the denoising steps whenever the text and image agreed semantically. This keeps the two in sync as they evolve.
How ParaRL works in simple terms:
- At several steps during generation, the model is checked for how well the words match the picture (using a semantic similarity score, like CLIP).
- If they match better, the model gets a reward. Over time, it learns to keep text and image consistent.
- Scores are normalized so training stays stable and fair.
What they found and why it matters
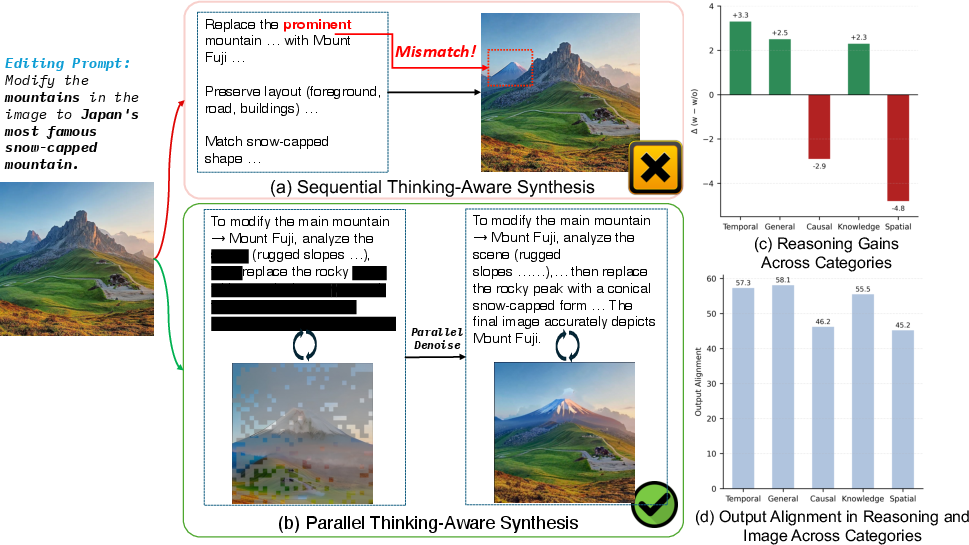
- Thinking-first can backfire: On some tasks—especially complex ones involving spatial changes or causal reasoning—adding a reasoning step before generation made images worse. The reason: weak or vague reasoning led the image generator astray, and errors piled up.
- Alignment is key: Poor performance happened exactly where the match between reasoning and final image was weakest. So the problem wasn’t just the final picture—it was the mismatch between what the AI said and what it drew.
- Parallel wins: MMaDA-Parallel, which thinks and draws together, improved how well text and image matched. On ParaBench, it achieved a 6.9% improvement in Output Alignment compared to a strong prior model called Bagel.
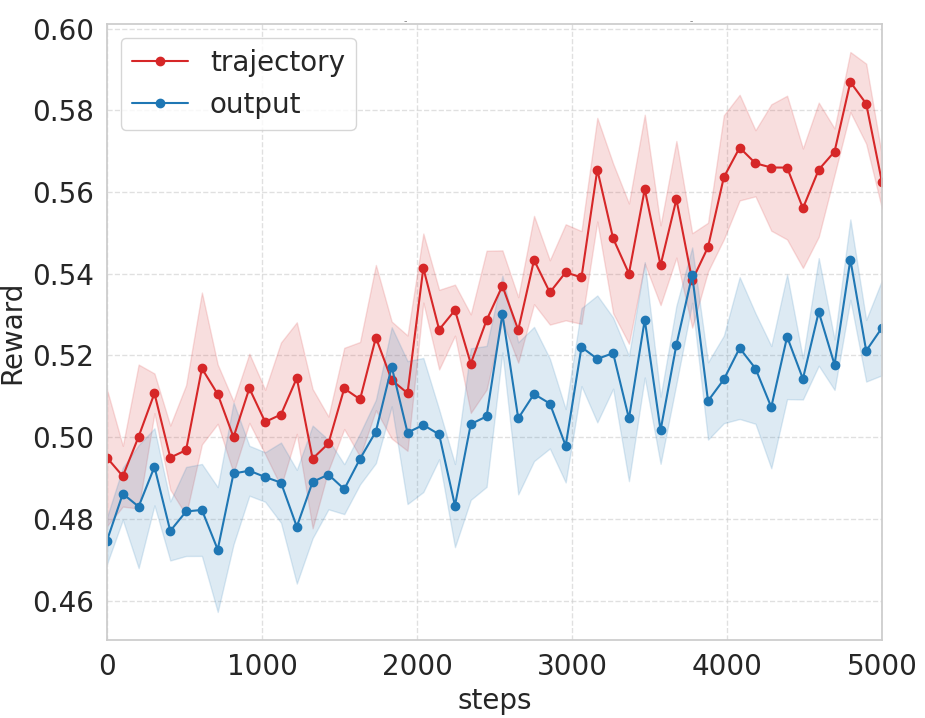
- Step-by-step rewards help: ParaRL further boosted consistency by rewarding alignment during the generation process, not just at the end. This led to more accurate and coherent results, especially on complex instructions.
- Competitive results: Among open-source models, MMaDA-Parallel showed the best text–image alignment while keeping image and text quality strong. It even narrowed the gap with top closed-source systems.
Why this research could be important
- More reliable visual AI: Tools that edit or generate images from instructions could make fewer mistakes and produce outputs that truly reflect the user’s intent.
- Better creative assistants: From photo editors to art tools, a model that keeps its words and pictures in sync at every step can follow complex, multi-part, or tricky instructions more accurately.
- A new paradigm: Instead of thinking first and then drawing, this work suggests the future is “think while drawing.” This reduces error propagation, keeps both sides informed, and produces more faithful, grounded results.
- Stronger evaluation: ParaBench sets a higher standard by measuring both the thinking and the picture—and how well they fit together—leading to better, more honest assessments of multimodal AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces a parallel multimodal diffusion framework (MMaDA-Parallel), a trajectory-level RL approach (ParaRL), and a benchmark (ParaBench) for thinking-aware image synthesis. The following gaps and open questions remain:
- ParaBench scale and coverage: The benchmark comprises only 300 prompts, which may be too small to robustly assess diverse reasoning and editing competencies (e.g., fine-grained spatial relations, long-horizon causal edits, rare-world knowledge, multi-object compositionality, multilingual instructions). What is the performance and reliability as ParaBench scales to thousands of prompts across more domains and languages?
- LLM-as-a-judge validity: Evaluation relies primarily on GPT-4.1 scoring across six dimensions. How dependable are these scores compared to human ratings? What is inter-rater reliability, calibration, and sensitivity to prompt wording? Are judgments consistent across different LLM judges and versions?
- Human evaluation absence: There is no human study validating that improvements in Output Alignment reflect perceptual and semantic gains. Will human evaluations corroborate LLM-judged improvements, especially in nuanced edits (e.g., attribute changes, subtle spatial relations)?
- Causal attribution of performance degradation: The paper infers that sequential autoregression causes error propagation leading to degraded image fidelity, based on correlations between reasoning quality and output alignment. Can controlled experiments (e.g., systematically injecting noisy/ambiguous reasoning, correcting reasoning midstream, or enforcing higher-quality reasoning) establish causal links?
- Trajectory-level reward design details: ParaRL uses CLIP-based alignment as dense rewards on intermediate steps, but specifics of computing CLIP scores for partial text and partially denoised images are under-specified. How robust are intermediate CLIP scores, and do they reliably reflect partial semantic content across steps?
- Reward model alternatives and stability: CLIP-based rewards can be noisy and susceptible to reward hacking. How do alternative process rewards (e.g., PRM trained on step-level alignment, multimodal contrastive objectives, task-specific detectors like counting or attribute recognizers) compare in stability and outcomes? What are the tradeoffs in variance reduction (e.g., baselines, critic/value learning)?
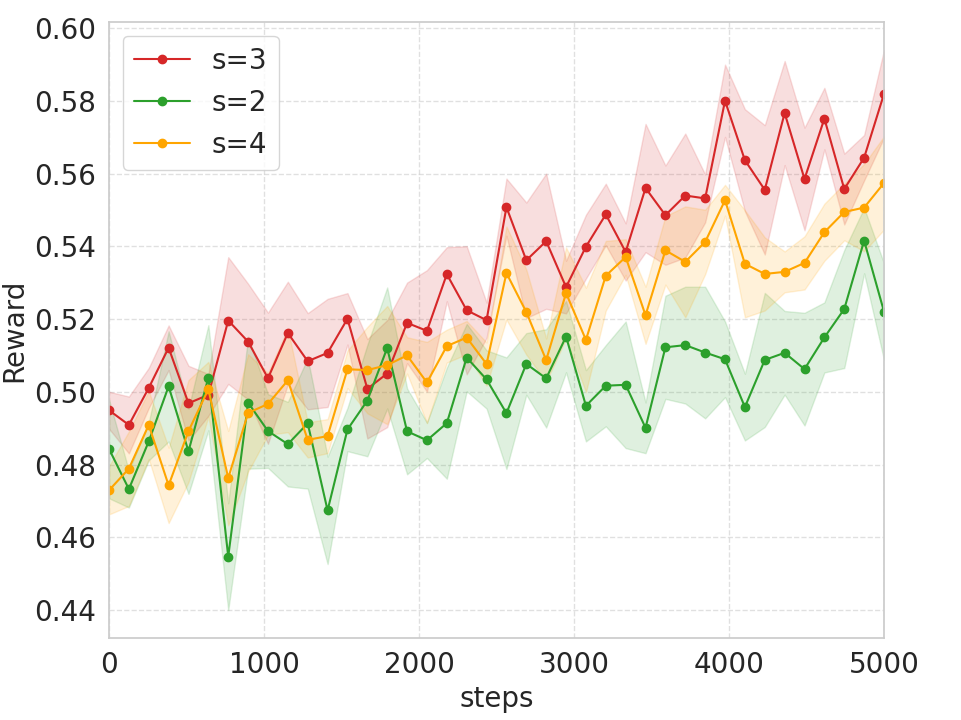
- Sparse step sampling strategy: ParaRL selects a small number of steps s for reward computation. What is the optimal step selection policy (uniform, curriculum, adaptive uncertainty-based)? How do different s values or adaptive schedules impact stability, compute cost, and final alignment?
- RL algorithm choice and generality: The paper adapts GRPO for diffusion but does not compare to other RL formulations (e.g., PPO variants, actor-critic with value functions, off-policy methods, reward-weighted regression). Which RL formulations offer better stability, sample efficiency, and generalization for trajectory-level diffusion training?
- Efficiency and compute transparency: Parallel denoising likely affects memory footprint, latency, and throughput relative to sequential approaches. What are the training and inference costs (FLOPs, GPU-hours), latency per sample, and memory usage for parallel vs. sequential decoding?
- Scheduler and sampling ablations: Dual reveal schedulers (linear for text, cosine for images) and confidence-based sampling choices are fixed. How sensitive are outcomes to scheduler shapes, sampling strategies (greedy vs. stochastic), confidence thresholds, and semi-autoregressive configurations? Are there principled ways to optimize these schedules jointly?
- Architecture design choices: The interleaved sequence with sentinels and task tags, tokenizers (LLaDA for text, MAGVIT-v2 for images), and bidirectional attention are assumed beneficial. Which components are necessary vs. optional? Are there gains from alternative tokenizers (e.g., higher-res VQ, latent diffusion), attention masks (modality-aware), or cross-attention modules?
- Data curation quality and biases: Reasoning traces are generated by Qwen-2.5-VL without reported human validation. What is the error rate and bias in these traces, and how does trace quality impact learning? Can curated or human-reviewed reasoning traces substantially improve alignment and robustness?
- Overfitting and selection bias in RL stage: RL focuses on the “most challenging 10%” of SFT examples. How is difficulty defined, and does this selection bias the policy toward particular categories or prompt types? Does performance degrade on easier or out-of-distribution tasks?
- Generalization to additional modalities and tasks: The approach is demonstrated on text–image editing/generation. How does parallel denoising extend to video, audio, 3D, multimodal story synthesis, or multi-image conditioning? Can trajectory-level rewards be defined for temporal consistency or spatial coherence in video?
- Robustness to adversarial and ambiguous prompts: The paper does not test adversarial instructions, contradictory reasoning, or negations. How robust is MMaDA-Parallel to such inputs, and can ParaRL handle misalignment when one modality is misleading?
- Safety, ethics, and misuse: Thinking-aware editing can enable realistic manipulations (e.g., identity changes, deepfakes) without safeguards. What safety policies, content filters, and auditing mechanisms are needed? How does trajectory-level optimization interact with safety constraints?
- Failure mode characterization: While improvements are shown, detailed error analysis (per-category breakdowns, common misalignments, typical reasoning failures) is limited. What systematic failure patterns remain (e.g., counting errors, fine-grained attribute binding, spatial prepositions), and which training components address them?
- Metrics beyond LLM judgments: The paper omits standardized image evaluation metrics (e.g., FID, CLIPScore variants, semantic segmentation-based alignment) and text metrics (e.g., factuality, coherence). Do these metrics corroborate LLM-based conclusions, and can trajectory-level alignment be measured directly (e.g., stepwise mutual information between modalities)?
- Stepwise alignment measurement: ParaRL assumes intermediate cross-modal alignment can be reinforced, but there is no formal metric to quantify alignment across steps. Can a trajectory-level alignment metric be defined and validated (e.g., stepwise concept emergence synchronization, cross-modal attention alignment, token-level correspondence)?
- Scaling behavior and reproducibility: Claims of scalability are made via a brief post-training experiment on Lumina-DiMOO, but details are sparse. How does performance scale with data size, model size, and RL steps? Are full training recipes (hyperparameters, schedulers, seeds) sufficient to reproduce results across different hardware?
- Closed-source comparisons and consistency: Reported metrics for closed-source models differ between main and appendix tables, raising consistency concerns. Are evaluation settings, prompts, and judge configurations identical across comparisons? How sensitive are results to judge configuration changes?
- Multilingual and cross-domain evaluation: The benchmark and experiments appear to focus on English-language prompts and common domains. How does parallel denoising perform for multilingual instructions, domain-specific jargon, or low-resource languages?
- Interactive editing and multi-turn workflows: Many practical editing tasks require iterative user feedback and refinement. Can MMaDA-Parallel and ParaRL handle multi-turn interaction, corrective feedback, and interactive alignment without collapsing or drifting?
- Uncertainty and calibration: The model’s “thinking” may be overconfident or misleading. Can uncertainty estimation (e.g., confidence in reasoning tokens, entropy-based schedules) improve reliability and guide user-facing safeguards?
- Ground truth for reasoning: There is no notion of “correct” reasoning sequences for edits. Can datasets be constructed with verified, minimal sufficient reasoning, enabling stronger supervision and evaluation of thinking quality?
- Token masking strategy: Training noises only the output segment. Would noising inputs (e.g., instruction tokens, reference image tokens) or joint noising improve robustness and reduce over-dependence on fixed inputs?
- Long-text reasoning effects: The impact of reasoning length, structure (plans vs. step lists), and verbosity on alignment is not analyzed. What are optimal reasoning formats to maximize cross-modal grounding without distracting the image generator?
Practical Applications
Immediate Applications
The following applications can be deployed with current tooling, leveraging the open-source MMaDA-Parallel codebase, ParaBench evaluation pipeline, and ParaRL training regimen. Each item notes sectors, potential tools/workflows, and feasibility assumptions.
- Cross-modal quality assurance for generative workflows
- Sectors: software, media, e-commerce, education
- Tools/workflows: integrate ParaBench-style metrics (Text Quality, Image Quality, Output Alignment) into CI pipelines for image-generation tools; add automated checks that ensure the generated image matches its accompanying reasoning or caption.
- Assumptions/dependencies: access to LLM-as-a-judge or rule-based proxies; CLIP-based semantic similarity; compute availability for batch evaluation.
- Reasoning-aware image editing in creative toolchains
- Sectors: design, advertising, entertainment
- Tools/products: plug-ins for Photoshop/GIMP/Krita that expose the model’s stepwise textual rationale alongside visual edits; “thinking-aware” prompts that co-generate edits and reasoning, improving stakeholder review and iteration.
- Assumptions/dependencies: integration with MAGVIT-v2 tokenizers; GPU inference for parallel diffusion; suitable licensing for commercial use.
- Consistent product listing generation and variant editing
- Sectors: e-commerce, retail
- Tools/workflows: batch generation of product variants (color, style, background) where textual descriptions and images stay aligned; automated A/B creative generation with alignment scoring to reduce miscaptioning and returns.
- Assumptions/dependencies: curated prompts and brand constraints; human-in-the-loop validation for edge cases (e.g., safety-sensitive items).
- Accessibility enhancements via aligned image–text generation
- Sectors: accessibility, education, public sector
- Tools/products: automatic generation of alt text that matches images; visual aids that follow stepwise textual explanations for lessons or guides.
- Assumptions/dependencies: accessibility auditing; guardrails to prevent hallucinations; content filters for sensitive topics.
- Editorial captioning and illustration verification
- Sectors: news media, publishing
- Workflows: generate or edit illustrations with reasoning traces that can be audited; use Output Alignment scoring to catch mismatches between captions and visuals before publication.
- Assumptions/dependencies: editorial guidelines; legal review for synthetic content; standard operating procedures for model auditing.
- Synthetic data creation with built-in labels
- Sectors: AI/ML training, computer vision
- Tools/products: generate synthetic image–text pairs where the reasoning trace serves as weak supervision; increase data diversity while maintaining semantic consistency.
- Assumptions/dependencies: domain adaptation for specialized tasks; careful distribution matching; bias checks on generated datasets.
- UI/UX prototyping with cross-modal constraints
- Sectors: software, product design
- Tools/workflows: co-generate wireframes/screenshots and design rationales in parallel; apply alignment metrics to ensure that visuals adhere to textual spec (e.g., accessibility rules, design tokens).
- Assumptions/dependencies: custom prompt templates; integration into design version control; compute limits for interactive use.
- Content moderation and compliance checks for generative assets
- Sectors: platforms, policy, governance
- Tools/workflows: deploy alignment scoring to spot misleading or non-compliant AI-generated images; flag assets where reasoning contradicts visuals.
- Assumptions/dependencies: policy definitions of misalignment; thresholds calibrated to false positive/negative rates; documented escalation paths.
- Classroom visualizations with stepwise explanations
- Sectors: education
- Tools/products: generate diagrams and simultaneous textual explanations for STEM or humanities topics; support formative assessment by checking consistency between visual aid and explanatory text.
- Assumptions/dependencies: age-appropriate content filters; pedagogy alignment; local deployment in education IT environments.
- Agentic prompt engineering for multimodal pipelines
- Sectors: software, robotics (simulation), research
- Workflows: use parallel text–image generation to avoid error propagation in sequential pipelines; build agents that plan with visuals and rationales interleaved over diffusion steps.
- Assumptions/dependencies: orchestration layers for agents; access to ParaRL for trajectory optimization; monitoring for failure cases.
Long-Term Applications
The following applications require further research, scaling, domain adaptation, or standardization to reach production maturity.
- Safety-critical visual decision support (e.g., medical illustration, CAD for engineering)
- Sectors: healthcare, manufacturing, civil engineering
- Tools/products: co-generate domain-specific visuals and validated reasoning traces for patient education, surgical planning sketches, component design annotations.
- Assumptions/dependencies: expert-curated datasets; rigorous validation against domain ground truths; regulatory approval; strong safety and privacy controls.
- Multimodal tutoring systems and curricula generation
- Sectors: education, edtech
- Tools/products: intelligent tutors that produce stepwise visual aids aligned with textual scaffolding, personalized to learner progress.
- Assumptions/dependencies: pedagogical efficacy studies; safeguards against misconceptions; explainability standards; equitable access.
- Policy and procurement standards for multimodal alignment
- Sectors: public sector, governance, enterprise compliance
- Workflows: adopt ParaBench-like evaluation as procurement criteria; require “reasoning trace + visual output” audits in generative system deployments.
- Assumptions/dependencies: standardization bodies endorse metrics; reproducible evaluation; transparency mandates for generative AI vendors.
- Alignment-as-a-service platforms
- Sectors: software, content platforms, CMS
- Products: APIs that score and remediate cross-modal inconsistency (text-to-image and image-to-text); dashboards for batch audits and trend analysis.
- Assumptions/dependencies: scalable inference; robust reward surrogates beyond CLIP; privacy-preserving evaluation; integration into existing content pipelines.
- Trajectory-level RL generalization to video, 3D, and audio
- Sectors: media production, robotics, AR/VR
- Tools/products: extend ParaRL to multi-frame video generation, 3D asset creation, and audio–visual narration with per-step alignment rewards.
- Assumptions/dependencies: multi-modal tokenizers/quantizers; stable reward shaping; compute-intensive training; new benchmarks for sequential alignment.
- Robust synthetic training for embodied and autonomous systems
- Sectors: robotics, autonomous vehicles
- Workflows: generate step-aligned visual scenes and textual plans to train world models and policies; use trajectory rewards to reduce compounding errors.
- Assumptions/dependencies: domain fidelity in simulation; transfer learning strategies; safety validation in sim-to-real; adherence to standards.
- Enterprise knowledge management with aligned visual–text artifacts
- Sectors: enterprise software, legal, finance
- Tools/products: co-generated visual documentation (e.g., process maps, compliance diagrams) with traceable reasoning suitable for audits and governance.
- Assumptions/dependencies: secure data stores; controlled vocabularies; integration with document management systems; legal approval for AI-generated artifacts.
- Scientific visualization and reproducible research artifacts
- Sectors: academia, R&D
- Workflows: generate figures and textual descriptions in parallel with trajectory-level traceability; enable reviewers to evaluate coherence and reduce misinterpretations.
- Assumptions/dependencies: domain reward models beyond CLIP; dataset transparency; standard operating procedures for AI-assisted publications.
- Misinformation detection and multimodal authenticity checks
- Sectors: platforms, policy, cybersecurity
- Tools/products: use cross-modal alignment gaps as signals for suspect content (e.g., captions that don’t match visuals, altered images with inconsistent reasoning).
- Assumptions/dependencies: robust detectors for adversarial cases; calibrated false-alarm rates; governance for enforcement actions.
- Energy-aware and cost-optimized multimodal generation
- Sectors: cloud computing, sustainability
- Workflows: explore whether parallel diffusion decoding reduces total inference steps or rework versus sequential pipelines; track cost/energy savings with alignment-driven early stopping.
- Assumptions/dependencies: empirical validation of efficiency gains; hardware-specific optimizations; accurate telemetry for energy/cost reporting.
Glossary
- Absorbing-state marginal: In discrete diffusion, the marginal distribution over a token after multiple noising steps where [MASK] is an absorbing state. Example: "the absorbing-state marginal after steps is "
- Autoregressive: A generation paradigm that predicts tokens sequentially, where each token depends on previously generated tokens. Example: "existing sequential, autoregressive approaches can paradoxically degrade performance due to error propagation."
- Behavior policy: In reinforcement learning, the policy used to generate trajectories (rollouts) for training. Example: "the behavior policy for generating rollouts"
- Bidirectional attention: Attention mechanism where tokens can attend to both past and future tokens (across modalities here), enabling mutual conditioning. Example: "an interleaved sequence with bidirectional attention,"
- Chain-of-Thought (CoT): A prompting or modeling strategy that makes intermediate reasoning steps explicit in text. Example: "Chain-of-Thought reasoning"
- CLIP score: A similarity metric from a contrastive text–image model used to measure semantic alignment between text and image. Example: "the naive CLIP score, which serves as our reward source"
- Confidence-based sampling: A decoding strategy that progressively commits higher-confidence token predictions during diffusion. Example: "employ confidence-based sampling to achieve greater global consistency."
- Cosine reveal schedule: A scheduling function that controls the proportion of tokens revealed per step following a cosine curve. Example: "the image schedule follows a cosine reveal schedule with global confidence-based decoding."
- Cross-entropy: A loss function measuring the difference between predicted and true token distributions. Example: "We optimize a timestep-reweighted cross-entropy:"
- Cross-modal alignment: The degree to which generated text and image outputs are semantically consistent with each other. Example: "significantly improves cross-modal alignment and semantic consistency"
- Denoising trajectory: The sequence of steps in diffusion decoding where noise (or masks) is progressively removed to produce outputs. Example: "throughout the entire denoising trajectory."
- Discrete diffusion models: Diffusion models operating over discrete tokens (e.g., text and quantized image tokens) rather than continuous pixels or embeddings. Example: "discrete diffusion models for text or image generation"
- Exposure bias: A training–inference mismatch in sequential models where they are trained on ground truth histories but must generate conditioned on their own predictions. Example: "eliminates the ordering asymmetry and exposure bias introduced by autoregressive cross-modal pipelines."
- GRPO: A reinforcement learning objective (Generalized Reparameterized Policy Optimization) adapted here for diffusion policies. Example: "with a GRPO-based objective"
- Kullback–Leibler (KL) divergence: A measure of dissimilarity between two probability distributions, often used as a regularization penalty. Example: "KL penalty strength"
- LLaDA tokenizer: The text tokenizer used to convert text into discrete tokens within the unified diffusion framework. Example: "we tokenize text using the LLaDA tokenizer"
- LLM-as-a-judge: An evaluation approach where a LLM is prompted to score or judge model outputs. Example: "We employ an LLM-as-a-judge framework (GPT-4.1)"
- MAGVIT-v2: A learned image tokenizer/quantizer that maps images into discrete visual tokens. Example: "MagVIT-v2 image tokenizer"
- Mask predictor: The network head in discrete diffusion that predicts the identity of currently masked tokens. Example: "a single mask predictor shared across modalities"
- Output Alignment: An evaluation metric that measures semantic consistency between generated text and image outputs. Example: "a 6.9\% improvement in Output Alignment on ParaBench"
- ParaBench: A benchmark designed to evaluate thinking-aware multimodal generation, assessing both text and image and their alignment. Example: "we propose ParaBench, a new benchmark"
- Parallel Reinforcement Learning (ParaRL): A trajectory-level RL method that applies stepwise semantic rewards during diffusion to improve text–image consistency. Example: "Parallel Reinforcement Learning (ParaRL), a novel strategy that applies semantic rewards along the trajectory"
- Process reward model (PRM): A model that scores intermediate steps (processes) rather than final outputs; referenced as typically needed for trajectory optimization. Example: "a well-trained process reward model (PRM)"
- Reveal schedule: A policy specifying how many masked tokens to reveal (sample) at each decoding step. Example: "fully linear reveal schedule"
- Rollout: The act of sampling a full or partial trajectory from a policy during RL training. Example: "During each online rollout, we pre-select sampling steps"
- Semi-autoregressive decoding: A decoding scheme that reveals groups of tokens in parallel while retaining some sequential dependencies. Example: "semi-autoregressive confidence-based decoding"
- Semantic drift: Gradual deviation of generated content from the intended meaning or instruction during multi-step generation. Example: "vulnerable to error accumulation and semantic drift."
- Sentinels: Special tokens inserted into sequences to mark boundaries or sections (e.g., modality segments or tasks). Example: "using explicit sentinels and task tags"
- Standardized advantages: Per-step advantage estimates normalized across a batch or group to stabilize RL training. Example: "their corresponding standardized advantages for timesteps ."
- Supervised finetuning (SFT): Post-training a model on labeled pairs to align it with desired behaviors before RL. Example: "We begin with supervised finetuning (SFT)"
- Trajectory-level optimization: Training that uses rewards/signals from intermediate steps along the generation trajectory, not just final outputs. Example: "trajectory-level optimization provides a more granular and effective signal"
- Vision-LLM (VLM): A model that processes and integrates both visual and textual inputs/outputs. Example: "We prompt a powerful VLM"
Collections
Sign up for free to add this paper to one or more collections.