UniCorn: Towards Self-Improving Unified Multimodal Models through Self-Generated Supervision
Abstract: While Unified Multimodal Models (UMMs) have achieved remarkable success in cross-modal comprehension, a significant gap persists in their ability to leverage such internal knowledge for high-quality generation. We formalize this discrepancy as Conduction Aphasia, a phenomenon where models accurately interpret multimodal inputs but struggle to translate that understanding into faithful and controllable synthesis. To address this, we propose UniCorn, a simple yet elegant self-improvement framework that eliminates the need for external data or teacher supervision. By partitioning a single UMM into three collaborative roles: Proposer, Solver, and Judge, UniCorn generates high-quality interactions via self-play and employs cognitive pattern reconstruction to distill latent understanding into explicit generative signals. To validate the restoration of multimodal coherence, we introduce UniCycle, a cycle-consistency benchmark based on a Text to Image to Text reconstruction loop. Extensive experiments demonstrate that UniCorn achieves comprehensive and substantial improvements over the base model across six general image generation benchmarks. Notably, it achieves SOTA performance on TIIF(73.8), DPG(86.8), CompBench(88.5), and UniCycle while further delivering substantial gains of +5.0 on WISE and +6.5 on OneIG. These results highlight that our method significantly enhances T2I generation while maintaining robust comprehension, demonstrating the scalability of fully self-supervised refinement for unified multimodal intelligence.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces UniCorn, a way to help smart AI models that understand both pictures and text become better at creating images that match what people ask for. The idea is simple: these models already “get” images and text very well, but they don’t always turn that understanding into the right kind of image. UniCorn teaches the model to improve itself using its own feedback, without needing extra data or a “teacher” model.
Goals and Questions
The paper focuses on a central problem:
- Why do Unified Multimodal Models (UMMs)—AI systems that work with both images and text—understand things well but struggle to generate images that follow instructions precisely?
- Can we use the model’s own strong understanding to guide and improve its image generation?
- How do we check if understanding and generation are truly working together and staying consistent?
Methods and Approach (in everyday language)
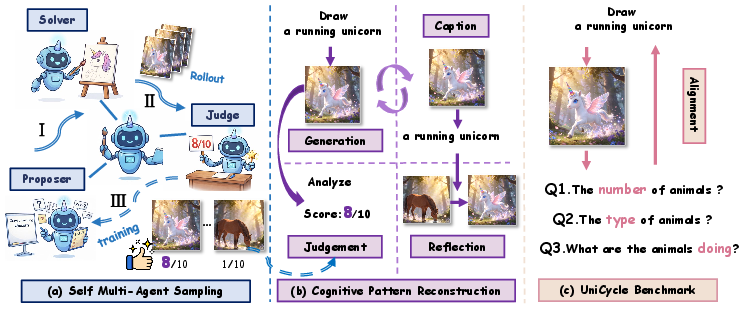
Think of the AI model as a single “brain” that can take on three different jobs to teach itself:
- Proposer (idea maker): It creates lots of varied and challenging text prompts, like “a red balloon floating above a snowy mountain at sunset.”
- Solver (builder): It tries to draw images based on those prompts—several versions each time—to explore different possibilities.
- Judge (inspector): It looks at the images and decides how well they match the prompt, giving scores (0–10) and explaining what’s good or bad.
After this self-play, UniCorn turns the raw attempts and feedback into clean training material using something called Cognitive Pattern Reconstruction. You can think of this like organized study notes that help the model learn better:
- Caption: The model practices describing its own best images in words. This connects visual features to the exact concepts in the prompt (image-to-text).
- Judgment: It learns to predict scores and reasoning for how well an image fits a prompt. This improves its “taste” and standards.
- Reflection: It compares a weaker image and a stronger image (both from the same prompt) and learns how to fix the mistakes that led to the weaker one.
Finally, the model is fine-tuned using these self-made examples and lessons. Importantly, it doesn’t need outside data or a teacher model—everything comes from the model itself.
To check whether understanding and generation really match, the paper introduces a test called UniCycle:
- Text → Image → Text: The model first creates an image from a sentence, then must describe that image back in words. If the final description preserves the important details from the original sentence, the model is consistent and aligned.
Main Findings and Why They Matter
The authors ran many experiments and found that UniCorn:
- Strongly improves image generation across several benchmarks (tests for how well the model follows instructions and produces good images).
- Achieves top (state-of-the-art) results on:
- TIIF: 73.8 (better instruction-following),
- DPG: 86.8 (high-quality visual reasoning),
- CompBench: 88.5 (strong compositional and spatial reasoning),
- UniCycle: 46.5 (best cycle-consistency—meaning understanding and generation stay aligned).
- Delivers big gains on other tests:
- WISE: +5.0 (better knowledge-intensive generation),
- OneIG: +6.5 (better nuanced text and alignment),
- Geneval: +4.0.
In simpler terms: the model not only makes prettier images, but it better follows instructions, handles numbers and 3D spatial setups, and keeps its “story” consistent when switching between text and images.
Impact and Implications
UniCorn shows a promising path for building smarter, more unified AI systems that both understand and create. Because it teaches itself—by proposing ideas, building images, judging results, and learning from mistakes—it can improve without huge datasets or expensive teacher models. This could lead to:
- More reliable creative tools (design, art, animation) where the AI follows your instructions closely.
- Better educational and scientific visuals (diagrams that correctly show math or physics ideas).
- Stronger foundations for AI that feels “balanced,” with understanding and generation working in sync—an important step toward more general, flexible intelligence.
The authors also note current limits: the method mainly helps generation (not much change in understanding scores yet), and the self-play process adds computing cost. Still, UniCorn’s self-improving approach is scalable, practical, and a meaningful step toward AI that can both think clearly and express its ideas faithfully.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps that remain unresolved and could guide future research:
- Validity of self-judging: No quantitative alignment between the model-as-judge scores and human judgments is reported; measure agreement (e.g., Kendall’s tau/Spearman), calibration curves, and judge failure modes across categories.
- Bias and self-confirmation risk: Using the same model for Proposer, Solver, and Judge may reinforce internal biases and reward hacking; investigate cross-model judging, ensemble judges, and adversarial audits to detect self-reinforcement loops.
- Rubric design transparency: Task-specific rubrics are mentioned but not fully specified; clarify rubric construction, consistency across categories, and normalization of the 0–10 scoring scale, and study the sensitivity of outcomes to rubric choices.
- Reliability of discrete 0–10 rewards: No analysis of score calibration, inter-prompt comparability, or robustness to prompt rephrasings; evaluate stability under small perturbations and introduce score normalization or variance-aware training.
- Human evaluation of generation: Aesthetics and realism claims rely on automatic metrics and external LLM judges; add blinded human preferences and rating studies to validate perceived quality and controllability.
- Generalization beyond T2I/I2T: The framework is evaluated only on image-text; it remains unknown how it extends to video, audio, 3D, or multimodal tool-use tasks and whether CPR patterns need modality-specific adaptations.
- Iterative/multi-round self-improvement: The current pipeline is single-turn; study multi-round bootstrapping (self-play → retrain → re-sample) to test monotonic gains, convergence, and risks of self-amplified artifacts.
- Understanding gains stagnation: Authors note limited improvements in understanding; investigate CPR/task weighting schedules, auxiliary losses, or joint objectives that explicitly boost I2T comprehension without hurting T2I.
- Computational cost and efficiency: The added cost of 8 rollouts per prompt and judging is not quantified; characterize wall-clock, GPU hours, and energy per point improvement; explore early-stopping, adaptive sampling, and low-cost judges.
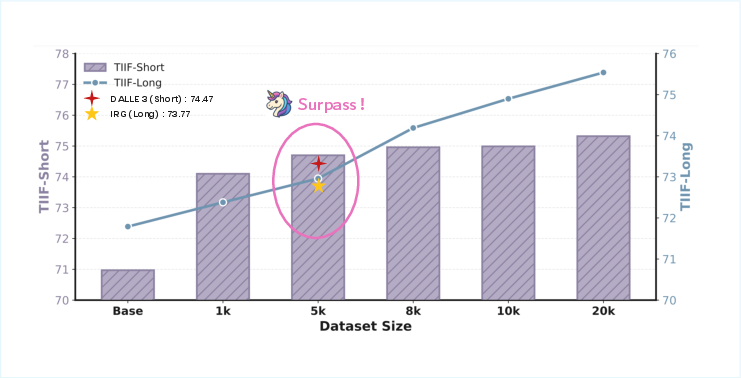
- Scaling beyond 20k samples: Demonstrated gains up to ~20k samples; open whether returns saturate or degrade at larger scales, and how data diversity, rollout count, or judge accuracy interact with scale.
- Active curriculum and coverage: Proposer prompts are category-ruled and dynamic-seeded, but there is no analysis of coverage or targeting of weak skills; develop diagnostics to identify capability gaps and adapt the prompt curriculum accordingly.
- Diversity vs. quality trade-offs: Rejection sampling may reduce diversity; add explicit diversity measurements (e.g., LPIPS/CLIP diversity, entropy) and mechanisms to prevent mode seeking.
- Reflection mechanism utilization at inference: Reflection is trained (I_lose → I*), but no inference-time procedure leverages it; test iterative self-correction loops or solver-with-critic decoding for further gains.
- Objective details for reflection: The loss for the reflection pattern (especially for diffusion vs autoregressive image generation) is under-specified; detail tokenization, loss formulation, and how supervision targets are constructed.
- Stability and catastrophic forgetting: Ablations show severe collapse when training without CPR; analyze training dynamics, catastrophic forgetting risks under different mixing ratios, and propose principled curricula or regularizers.
- Mixing/weighting of CPR signals: The contribution of caption, judgment, reflection, and generation losses is not systematically tuned; ablate mixing ratios, schedules, and their effects on understanding vs. generation trade-offs.
- UniCycle benchmark limitations: UniCycle covers 1,401 T→I→T items with an external judge; expand size, task diversity, and include reverse and multi-cycle variants (I→T→I, longer cycles) to assess deeper cognitive symmetry.
- Judge dependence in UniCycle: Results hinge on a single external judge (Qwen3-235B); test multiple judges, report cross-judge variance, and include human spot-checks to reduce evaluation bias.
- Robustness to adversarial/underspecified prompts: No stress tests for ambiguous, adversarial, or compositional edge cases; add adversarial prompt suites and measure failure rates with and without CPR.
- OOD generalization claims: The paper asserts stability under OOD conditions without a dedicated OOD protocol; define explicit OOD splits (domain, style, long-tail concepts) and quantify performance drop.
- Safety and alignment: Self-play can generate unsafe or biased prompts/outputs; document filtering policies, measure on safety benchmarks, and study whether CPR reduces or amplifies harmful content.
- Fairness across demographics: No fairness analysis; evaluate demographic parity in adherence and quality, and assess whether self-judging encodes or amplifies demographic biases.
- Data contamination risks: Using internal prompting and public benchmarks raises potential leakage; verify decontamination of prompts and evaluate on held-out, private, or newly curated test sets.
- Comparison with external-teacher pipelines: UniCorn* shows mixed outcomes, but cost–benefit is not quantified; systematically compare compute, data entropy, and gains vs. teacher strength to justify pure self-play.
- Architectural generality: Shown on BAGEL and Janus-Pro; unclear how CPR integrates with pure diffusion or other hybrid systems; provide recipes and tests on diverse families (e.g., Stable Diffusion, FLUX) and tokenization schemes.
- Theoretical claims vs. empirical proxies: Mutual information/Bayes justification is not empirically validated; estimate MI proxies, analyze representation alignment pre/post-CPR, and link to measurable performance deltas.
- Statistical significance and variance: No confidence intervals or seed variance reported; run multi-seed experiments and present significance tests to substantiate improvements.
- Reproducibility details: Some key implementation choices (e.g., rubric texts, prompt rules, sampling policies) are relegated to the appendix; provide full configs and ablation-ready scripts for faithful reproduction.
Practical Applications
Immediate Applications
The following applications can be deployed with current models and tooling, using the UniCorn self-play pipeline (Proposer–Solver–Judge) and the UniCycle T→I→T evaluation, as described in the paper.
- Creative production pipelines (media, advertising, design)
- What: Automated “diverge–converge” content generation—generate diverse prompt variants, produce multiple images per prompt, then internally judge/select/refine top candidates.
- Tools/products/workflows: Propose–Solve–Judge Studio; “Auto-Refine” button in creative apps; batch ideation with rejection sampling and rubric-based scoring.
- Dependencies/assumptions: Availability of a base Unified Multimodal Model with strong I2T comprehension; compute for multi-rollouts (e.g., 8 per prompt); domain-specific rubrics for Judge; brand/safety filters to avoid reward hacking or biased selections.
- E‑commerce catalog imaging and QA (retail)
- What: Generate product images from short specs and auto-verify attribute fidelity (color, material, count, 3D spatial layout) using the Judge; flag or auto-regenerate low-fidelity images.
- Tools/products/workflows: “Catalog Image QA + Generator”; attribute-check rubrics; closed-loop regeneration using Reflection (learn to fix recurring errors).
- Dependencies/assumptions: Accurate, attribute-specific rubrics; policy/safety constraints (e.g., no IP-infringing logos); traceability for audit.
- Internal model evaluation and release gating (MLOps, software)
- What: Adopt UniCycle as a training-free, unified coherence metric to continuously monitor T2I→I2T consistency, detect drift, and gate model releases.
- Tools/products/workflows: Cycle-Consistency Dashboard; regression tests on prompts spanning multiple categories; hard/soft scoring aggregation.
- Dependencies/assumptions: Choice and calibration of external or internal judge for scoring; integration with CI/CD; acceptance thresholds correlated with human judgment.
- Synthetic data generation with built-in labels (ML engineering)
- What: Produce prompt–image pairs with captions, judgments, and reflection trajectories for downstream training (e.g., better captioners, reward models, retrieval).
- Tools/products/workflows: “Self-Generated Dataset Pack” containing (Caption, Judgment, Reflection) triplets; balanced prompt libraries from the Proposer.
- Dependencies/assumptions: Data governance for self-generated assets; safety filtering; diversity controls to avoid mode collapse or narrow distributions.
- Safer generative endpoints via LLM-as-a-judge filtering (trust & safety)
- What: Pre-deployment filtering of generated images for policy compliance (nudity, violence, hate symbols) using Judge rubrics and reasoning traces; auto-reject or re-roll.
- Tools/products/workflows: Policy rubrics; risk-tiered reviewer queues; on-demand regeneration pipeline.
- Dependencies/assumptions: High-fidelity, bias-tested rubrics; logging of Judge rationales; human-in-the-loop oversight for edge cases.
- Brand/style compliance checkers (marketing)
- What: Enforce brand colors, logo placement, and composition rules prior to delivery; Judge verifies adherence; Reflection trains fixes (e.g., scale logo correctly).
- Tools/products/workflows: “Brand Guard” rubrics; templated prompt seeders; automatic escalation when adherence fails.
- Dependencies/assumptions: Robust brand rubrics; assets/licenses; periodic calibration to new brand guidelines.
- Education and explainable visualization (education)
- What: Generate visuals for problems (numeracy, 3D spatial) and provide explainable captions and judgments that articulate why the output fits the prompt.
- Tools/products/workflows: “Explain My Image” tutor mode; teacher dashboards using UniCycle to assess concept retention across prompts.
- Dependencies/assumptions: Age-appropriate safety filters; alignment of Judge rationales with curricular objectives; accessibility requirements.
- Better consumer T2I experiences (consumer software)
- What: Improved short-prompt fidelity and automatic self-critique/regeneration reduce prompt engineering burden in consumer apps.
- Tools/products/workflows: Auto-iterate and select best candidates; slider for “diversity vs fidelity.”
- Dependencies/assumptions: Compute budgets for rollouts; privacy handling when judging user-provided images.
- Academic benchmarking and replication (academia)
- What: Use UniCycle as a holistic multimodal coherence benchmark; reproduce CPR ablations to study comprehension–generation coupling.
- Tools/products/workflows: Benchmark suites; standardized Judge prompts; open-source training scaffolds.
- Dependencies/assumptions: Reuse of released code/models; clear reporting of judge prompts and seeds for replicability.
Long-Term Applications
The following applications are plausible extensions that require further research, scaling, or domain adaptation.
- Generalized multimodal self-improvement beyond images (software, media)
- What: Extend self-play + CPR to video, audio, and 3D generation with T→Video→Text or T→Audio→Text cycles; multi-turn Reflection for temporal coherence.
- Tools/products/workflows: Video UniCycle; timeline-aware rubrics; multi-frame rollouts and judgments.
- Dependencies/assumptions: Strong base UMMs for video/audio I2T; higher compute; temporal safety and IP compliance.
- Embodied agents and simulation-based self-improvement (robotics)
- What: Proposer generates tasks/scenes; Solver acts in simulator; Judge evaluates goal completion and safety; Reflection learns corrections—closing the “understand–act” gap.
- Tools/products/workflows: Task rubric editors; sim-to-real transfer with cycle checks (Instruction→Action→Explanation).
- Dependencies/assumptions: Reliable simulators; safety constraints; transfer learning; evaluation of long-horizon reasoning.
- Clinically governed synthetic imaging (healthcare)
- What: Use Judge rubrics co-designed with clinicians to generate and validate synthetic medical images for augmentation and education (with strict fidelity and privacy controls).
- Tools/products/workflows: Domain rubrics (anatomical landmarks, modality-specific features); audit trails; human verification loops.
- Dependencies/assumptions: Regulatory approval; clinical validation; domain-pretrained UMMs; strong safety and de-identification guarantees.
- Procurement and audit standards for generative AI (policy, governance)
- What: Establish cycle-consistency thresholds and rubric transparency as procurement criteria; require T→I→T scores for model certification and ongoing monitoring.
- Tools/products/workflows: Standardized UniCycle variants per sector; third-party audit frameworks; reporting templates.
- Dependencies/assumptions: Consensus on acceptable metrics; bias and fairness audits of LLM-as-a-judge; versioned rubrics.
- Personalized creative directors (marketing, product)
- What: Persistent Judge modules tuned to brand/user preferences guiding generation and reflection over time; memory-backed Proposer seeds.
- Tools/products/workflows: Preference learning for Judge; “style book” rubrics; lifecycle analytics of adherence.
- Dependencies/assumptions: Data privacy; drift detection; continuous alignment to evolving preferences.
- On-device or edge self-improvement loops (mobile, AR/VR)
- What: Lightweight self-play with small rollouts for personalization and privacy-preserving refinement.
- Tools/products/workflows: Distilled Judges; adaptive rollout counts; energy-aware scheduling.
- Dependencies/assumptions: Efficient UMMs; hardware acceleration; careful telemetry and guardrails.
- Cross-modal retrieval and search with self-consistency constraints (search)
- What: Use CPR signals (Caption, Judgment) to improve retrieval relevance and debias cross-modal embeddings via cycle-consistency training.
- Tools/products/workflows: Retrieval training that penalizes T→I→T drift; multi-task objectives with Judgments as soft labels.
- Dependencies/assumptions: Scalable indexing; calibrated judges; evaluation datasets with human preference alignment.
- Robust safety and jailbreak resistance via reflective training (trust & safety)
- What: Use Judgment + Reflection to learn to avoid policy-violating generations and to self-correct evasive prompts.
- Tools/products/workflows: Safety-focused rubrics; red-team Proposer modules; iterative hard-negative mining.
- Dependencies/assumptions: Continual red-teaming; measurable alignment gains; avoidance of overfitting to rubric idiosyncrasies.
- Marketplaces for domain rubrics and Judge plug-ins (ecosystem)
- What: Third-party, auditable rubric packs (e.g., architectural visualization, fashion, automotive) that can be plugged into UniCorn training or inference-time filtering.
- Tools/products/workflows: Rubric package format and SDK; provenance and versioning; conformance tests.
- Dependencies/assumptions: IP/licensing standards; quality assurance; security review of plug-ins.
- Multi-turn co-evolution of understanding and generation (research)
- What: Iterative self-play where comprehension metrics also rise (addressing the paper’s limitation); curriculum across difficulty levels and domains.
- Tools/products/workflows: Self-paced Proposer; difficulty-aware rubrics; theoretical analyses linking mutual information gains to NLL reductions.
- Dependencies/assumptions: Stabilized training objectives; compute budgets; comprehensive ablations.
Notes on overarching feasibility
- Core dependency: a base UMM with solid I2T understanding (Judge quality determines ceiling).
- Compute: multi-rollout generation and self-play cycles increase training/inference cost; requires budget-aware rollout strategies.
- Safety and bias: LLM-as-a-judge can encode biases; rubrics and rationales should be audited and monitored; human oversight for high-stakes use.
- Legal/ethical: respect dataset/model licenses; ensure IP, privacy, and regulatory compliance in domain deployments.
- Generalization: domain-specific rubrics and few-shot seeds are critical to avoid reward hacking and to maintain out-of-distribution robustness.
Glossary
- Autoregressive models: Generative models that predict the next token in a sequence, enabling joint text–vision token generation. "pure autoregressive models that jointly predict text and visual tokens over interleaved sequences"
- Bayes' theorem: A probabilistic rule relating prior, likelihood, and posterior; used to justify training objectives. "we justify this approach using Mutual Information and Bayes' theorem, demonstrating that our task decomposition effectively minimizes Negative Log Likelihood (NLL)."
- Cognitive Pattern Reconstruction (CPR): A post-processing stage that converts internal interactions into structured training signals (caption, judgement, reflection). "Then, the CPR stage reconstructs these raw interactions into three training patterns: caption, judgement, and reflection"
- Cognitive symmetry: The bidirectional alignment between internal concepts and external expressions in intelligent systems. "cognitive symmetry~\cite{blanco2018unconscious} enables a bidirectional mapping between internal concepts and external expressions."
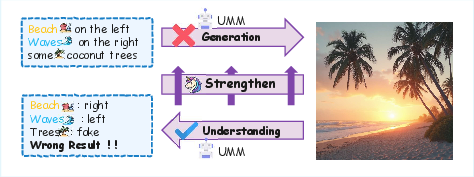
- Conduction Aphasia: The mismatch where a model understands inputs but fails to generate correspondingly accurate outputs. "We formalize this discrepancy as Conduction Aphasia, a phenomenon where models accurately interpret multimodal inputs but struggle to translate that understanding into faithful and controllable synthesis."
- Cycle-consistency benchmark: An evaluation that tests whether information is preserved across a generation–understanding loop. "we introduce {UniCycle}, a cycle-consistency benchmark based on a reconstruction loop."
- Diffusion-based image synthesis: A generative approach that iteratively denoises to produce images from text or latent representations. "hybrid models that combine autoregressive language modeling with diffusion-based image synthesis"
- Diffusion Forcing: A guidance scheme for diffusion models that influences generation dynamics. "with related guidance schemes such as Diffusion Forcing~\cite{chen2024diffusion}."
- Generation reward model: A learned evaluator that assigns scores to generative outputs to guide improvement. "we transfer generation reward models~\cite{deepseek-grm}, which have demonstrated strong potential in LLMs, to T2I evaluation."
- In-context learning (ICL): The ability of models to learn behaviors from examples provided in the prompt without gradient updates. "Leveraging the strong in-context learning (ICL) capabilities of LLMs~\cite{dong2024survey}, the initial example serves as a few-shot demonstration to guide the generation of subsequent prompts."
- Interleaved multimodal sequence: A format where text and image tokens are mixed within a single input or output stream. "to an interleaved multimodal output sequence ."
- Metacognitive theory: A framework emphasizing monitoring, evaluation, and regulation for robust learning. "we draw inspiration from metacognitive theory~\cite{dunlosky2008metacognition}, which identifies monitoring, evaluation, and regulation as the pillars of robust learning."
- Mode collapse: A failure mode where a generative model produces limited diversity, ignoring parts of the target distribution. "directly optimizing this cross-domain alignment remains stochastic and inefficient, often leading to mode collapse~\cite{chen2025t2i,wang2024div}."
- Mutual Information: An information-theoretic measure of shared information between variables, used to analyze objectives. "we justify this approach using Mutual Information and Bayes' theorem, demonstrating that our task decomposition effectively minimizes Negative Log Likelihood (NLL)."
- Negative Log Likelihood (NLL): A standard loss measuring how improbable the observed data is under the model; minimizing NLL improves fit. "we justify this approach using Mutual Information and Bayes' theorem, demonstrating that our task decomposition effectively minimizes Negative Log Likelihood (NLL)."
- Out-of-distribution (OOD): Data or conditions not seen during training; robustness here indicates generalization. "remains stable under out-of-distribution (OOD) conditions."
- Policy πθ: The parameterized mapping from multimodal inputs to outputs in a unified model. "A UMM is formulated as a policy that maps a multimodal input sequence"
- Rejection sampling: A selection process that discards low-scoring samples based on a judge to curate training data. "which are then used for rejection sampling during training."
- Reward model: A model component that scores outputs to reflect alignment with desired criteria. "when serving as a reward model for Text-to-Image (T2I) generation, the UMM exhibits a sophisticated grasp of cross-modal semantics."
- Rollout: Multiple sampled generations per prompt to explore output diversity and quality. "we perform 8 rollouts per prompt to strike a favorable trade-off between sample quality, diversity, and computational efficiency."
- Self multi-agent framework: A setup where one model assumes specialized internal roles (Proposer, Solver, Judge) to improve itself. "{UniCorn} operates through a self multi-agent framework that functionalizes the UMM into three distinct internal roles."
- Self-play: A training approach where the model generates its own tasks and feedback to learn without external supervision. "{UniCorn} generates high-quality interactions via self-play"
- Self-supervised refinement: Improving model capabilities using internally generated signals rather than labeled external data. "demonstrating the scalability of fully self-supervised refinement for unified multimodal intelligence."
- Sparse experts: Specialized components activated selectively within a mixture-of-experts architecture for efficiency and modularity. "via modular routing and sparse experts~\cite{shi2024lmfusion,liang2024mixture,deng2025emerging})"
- Text-to-Image-to-Text (T2I2T): A generation-and-reconstruction protocol that tests whether a model can recover prompt semantics from its own images. "extending the original TIIF benchmark from the T2I setting to the Text-to-Image-to-Text (T2I2T) setting."
- Unified Multimodal Models (UMMs): Models that jointly handle understanding and generation across modalities within a single architecture. "While Unified Multimodal Models (UMMs) have achieved remarkable success in cross-modal comprehension, a significant gap persists in their ability to leverage such internal knowledge for high-quality generation."
Collections
Sign up for free to add this paper to one or more collections.

