Interleaving Reasoning for Better Text-to-Image Generation
Published 8 Sep 2025 in cs.CV, cs.AI, cs.CL, and cs.LG | (2509.06945v2)
Abstract: Unified multimodal understanding and generation models recently have achieve significant improvement in image generation capability, yet a large gap remains in instruction following and detail preservation compared to systems that tightly couple comprehension with generation such as GPT-4o. Motivated by recent advances in interleaving reasoning, we explore whether such reasoning can further improve Text-to-Image (T2I) generation. We introduce Interleaving Reasoning Generation (IRG), a framework that alternates between text-based thinking and image synthesis: the model first produces a text-based thinking to guide an initial image, then reflects on the result to refine fine-grained details, visual quality, and aesthetics while preserving semantics. To train IRG effectively, we propose Interleaving Reasoning Generation Learning (IRGL), which targets two sub-goals: (1) strengthening the initial think-and-generate stage to establish core content and base quality, and (2) enabling high-quality textual reflection and faithful implementation of those refinements in a subsequent image. We curate IRGL-300K, a dataset organized into six decomposed learning modes that jointly cover learning text-based thinking, and full thinking-image trajectories. Starting from a unified foundation model that natively emits interleaved text-image outputs, our two-stage training first builds robust thinking and reflection, then efficiently tunes the IRG pipeline in the full thinking-image trajectory data. Extensive experiments show SoTA performance, yielding absolute gains of 5-10 points on GenEval, WISE, TIIF, GenAI-Bench, and OneIG-EN, alongside substantial improvements in visual quality and fine-grained fidelity. The code, model weights and datasets will be released in: https://github.com/Osilly/Interleaving-Reasoning-Generation .
The paper introduces IRG, a framework that interleaves text-based reasoning with image generation to improve semantic alignment and visual detail.
It employs a two-stage process with initial reasoning followed by reflection-based refinement, enhancing the quality and fidelity of generated images.
Experimental results demonstrate significant improvements over baselines in compositional accuracy, instruction adherence, and overall visual quality.
Interleaving Reasoning Generation for Enhanced Text-to-Image Synthesis
Introduction
The paper introduces Interleaving Reasoning Generation (IRG), a framework for text-to-image (T2I) synthesis that alternates between text-based reasoning and image generation, followed by iterative reflection and refinement. IRG is motivated by the observation that unified multimodal models, while capable of producing semantically correct images, often struggle with fine-grained detail, visual fidelity, and instruction adherence. By explicitly modeling a multi-turn reasoning process—first generating a reasoning trace, then an image, and subsequently reflecting on and improving the image—IRG aims to bridge the gap between semantic alignment and high-quality visual output.
Figure 1: IRG pipeline: initial text-based reasoning guides image generation, followed by reflection and refinement, yielding improved visual fidelity and detail.
IRG Framework and Training Paradigm
IRG operates in a two-stage process: (1) initial reasoning and image generation, and (2) reflection-based reasoning and image refinement. The model is built atop a unified multimodal transformer (BAGEL), leveraging its native support for interleaved text-image outputs. The IRG pipeline is formalized as a sequence:
where Tin is the prompt, Tout(1) is the initial reasoning, Iout(1) is the initial image, Tout(2) is the reflection reasoning, and Iout(2) is the refined image.
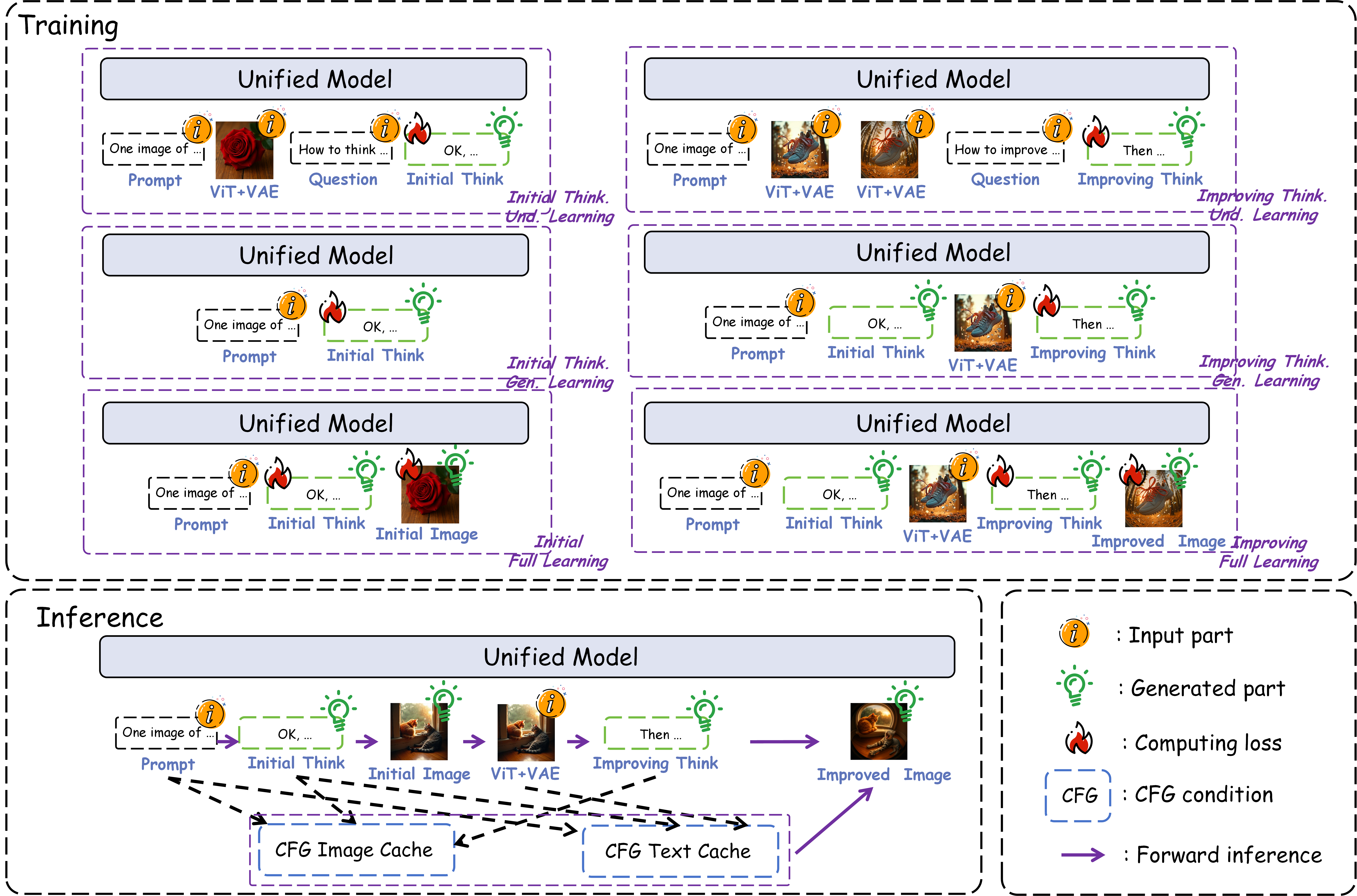
The training paradigm, Interleaving Reasoning Generation Learning (IRGL), decomposes the process into six learning modes, targeting both text-based reasoning and full reasoning-image trajectories. The IRGL-300K dataset is curated to support these modes, combining open-source T2I data, GPT-4o-distilled high-quality images, and reasoning traces generated by large multimodal LLMs (MLLMs).
Figure 2: IRG training and inference pipeline: six decomposed learning modes enable hierarchical optimization of reasoning and image generation.
Data Construction and Inference Strategy
IRGL-300K is constructed via a multi-step pipeline:
Initial reasoning data: prompts paired with images, reasoning traces generated by MLLMs.
Full learning data: high-quality images generated by GPT-4o, paired with reasoning traces.
Improving reasoning data: initial images from the base model, improved images from GPT-4o, and reflection reasoning generated by MLLMs.
During inference, IRG employs a customized classifier-free guidance (CFG) strategy, conditioning on both the initial image and reflection text, with guidance scales tuned for stability and fidelity.
Experimental Results
IRG is evaluated on multiple benchmarks, including GenEval, WISE, TIIF, GenAI-Bench, and OneIG-EN. Across all metrics, IRG demonstrates substantial improvements over prior unified and generation-only models.
GenEval: IRG achieves an overall score of 0.85, outperforming all baselines, with strong gains in compositional attributes such as counting and spatial position.
WISE: IRG attains 0.77 overall, with consistent improvements across cultural, temporal, spatial, biological, physical, and chemical domains.
TIIF: IRG scores 76.00/73.77 (short/long), excelling in advanced instruction-following and compositional reasoning.
GenAI-Bench: IRG achieves 0.84 overall, leading in both basic and advanced compositional prompts.
OneIG-EN: IRG sets a new open-source state of the art with 0.415 overall, ranking second only to GPT-4o.
Figure 3: IRG visualization results at 1024×1024 resolution, demonstrating high-fidelity synthesis across diverse prompts.
Ablation studies confirm that decomposed learning modes and multi-turn reasoning are critical for maximizing performance. Notably, IRG's reflection step yields images with improved fine-grained details and aesthetics, as validated by multiple MLLM-based evaluators.
Figure 4: Visual comparison: IRG outperforms BAGEL and self-CoT variants, with marked improvements in texture, shadow realism, and structural details.
Error Analysis and Limitations
Despite strong results, IRG exhibits several failure modes:
Over-smoothing of micro-structures in repetitive textures during reflection.
Trade-offs between text legibility and stylistic coherence in dense text rendering.
Local-global tension in crowded scenes, where local edits may perturb global layout.
These issues are most pronounced when the reflection reasoning introduces multiple simultaneous edits. Conservative editing policies improve stability but may limit attainable gains.
Theoretical and Practical Implications
IRG demonstrates that explicit multi-turn, interleaved reasoning is a powerful paradigm for T2I generation, enabling models to incrementally refine outputs and achieve superior semantic and visual alignment. The framework is data-efficient, leveraging text-only reasoning supervision to compensate for the scarcity of full reasoning-image trajectory data. IRG's modular design is compatible with a wide range of unified multimodal architectures, suggesting broad applicability.
Practically, IRG advances the state of controllable, instruction-following image synthesis, with implications for creative design, content generation, and interactive AI systems. Theoretically, it motivates further exploration of multi-modal, multi-turn reasoning as a general strategy for complex generative tasks.
Future Directions
Potential avenues for future research include:
Scaling IRG to multi-turn (>2) reasoning for further refinement.
Automated construction of large-scale, high-quality IRG datasets.
Integration with more advanced MLLMs for richer reasoning and reflection.
Extension to other modalities (e.g., video, 3D) and tasks (e.g., editing, composition).
Conclusion
Interleaving Reasoning Generation (IRG) establishes a robust framework for high-fidelity, instruction-following text-to-image synthesis. By alternating between reasoning and generation, and leveraging reflection for iterative improvement, IRG achieves state-of-the-art performance across multiple benchmarks. The approach highlights the value of explicit multi-turn reasoning in multimodal generative models and sets a foundation for future advances in controllable, knowledge-grounded image synthesis.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.