- The paper introduces Reconstruction Alignment (RecA) as a post-training strategy that employs dense semantic visual embeddings to overcome sparse textual supervision.
- The paper demonstrates RecA’s effectiveness by significantly enhancing image generation and editing performance, outperforming larger models on benchmarks like GenEval and DPGBench.
- The paper shows that RecA achieves robust alignment between visual understanding and generation without degrading core visual comprehension, offering a scalable alternative to supervised fine-tuning.
Reconstruction Alignment for Unified Multimodal Models: Methodology, Empirical Analysis, and Implications
Introduction
Unified Multimodal Models (UMMs) aim to integrate visual understanding and generation within a single architecture, enabling both interpretation and synthesis of visual content conditioned on language. However, the prevailing paradigm of training UMMs on image–text pairs is fundamentally limited by the sparsity and incompleteness of textual supervision, which fails to capture fine-grained visual details such as spatial layout, color, and object attributes. The paper "Reconstruction Alignment Improves Unified Multimodal Models" (2509.07295) introduces Reconstruction Alignment (RecA), a resource-efficient post-training strategy that leverages dense semantic embeddings from visual understanding encoders as "text prompts" for self-supervised image reconstruction. This approach realigns the latent spaces for understanding and generation, yielding substantial improvements in both image generation and editing across diverse UMM architectures.
Motivation and Methodological Framework
The core insight motivating RecA is the recognition that captions, even when verbose, are inherently sparse and omit critical visual information. In contrast, embeddings from visual understanding encoders (e.g., CLIP, SigLIP) encapsulate rich, language-aligned semantic information that is more faithful to the underlying image content. The RecA method conditions a UMM on its own visual understanding embeddings and optimizes it to reconstruct the input image using a self-supervised loss (e.g., diffusion or cross-entropy), thereby providing dense supervision without reliance on captions.
The RecA training objective replaces the conventional text-to-image (T2I) loss with a reconstruction loss:
LRecA=L(fθ(concat(ttemplate,hv)),Igt)
where ttemplate is a prompt template (e.g., "Describe the image in detail."), hv are the visual understanding encoder embeddings, and Igt is the ground-truth image. The total training loss is a weighted sum of RecA, image-to-text (I2T), and (optionally) T2I objectives, but in practice, λt2i is set to zero during RecA post-training.
At inference, the post-trained UMM operates identically to a standard UMM, requiring only text prompts for generation or text+image for editing, with no additional visual embeddings.
RecA demonstrates strong empirical gains across multiple UMM architectures, including autoregressive (Show-o), masked autoregressive (Harmon), AR+Diffusion (OpenUni, BAGEL), and at various parameter scales. Notably, a 1.5B-parameter model post-trained with RecA surpasses much larger models and even private models such as GPT-4o-Image on GenEval and DPGBench benchmarks, despite using only 27 GPU-hours and no distillation or RL data.
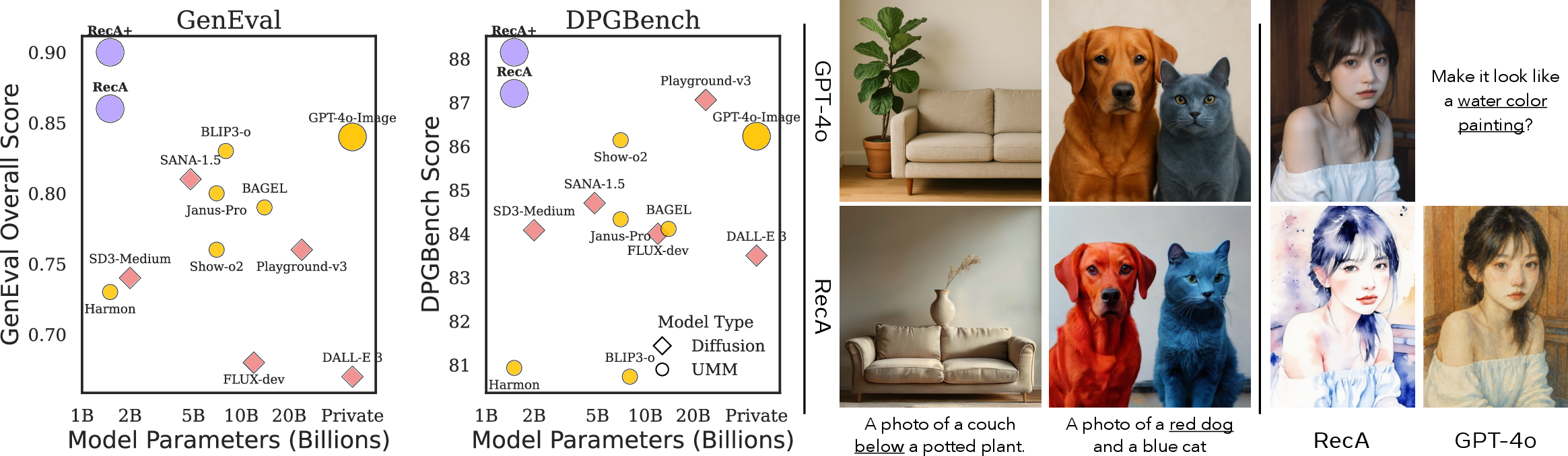
Figure 1: Post-training UMMs with RecA substantially improves image generation and editing, with a 1.5B-parameter model outperforming much larger baselines on GenEval and DPGBench.
Qualitative analysis reveals that RecA post-training enables models to better handle prompts involving multiple objects, complex attributions, and explicit spatial layouts, preserving fine details that are typically missed by baseline models.

Figure 2: RecA post-training enables more accurate generation of multiple objects, complex attributions, and spatial layouts, preserving fine details.
For image editing, RecA consistently improves object addition, replacement, style transfer, and scene modification, outperforming strong baselines such as BAGEL and FLUX-Kontext.

Figure 3: RecA post-training consistently improves image editing tasks, including object addition, replacement, style transfer, and scene modification.
Further, RecA achieves these improvements without degrading visual understanding performance, as measured by benchmarks such as POPE, MME, GQA, MMMU, and SEED.
Analysis of Methodological Choices
Visual Understanding vs. Generation Encoder
Empirical ablation demonstrates that using semantic embeddings from the visual understanding encoder (e.g., ViT, CLIP) as reconstruction prompts yields significantly better results than using generation encoder latents (e.g., VAE). This highlights the importance of high-level conceptual information for effective alignment.
Post-Training Strategy: SFT vs. RecA
Direct comparison between supervised fine-tuning (SFT) and RecA as post-training strategies shows that RecA is more effective, especially when benchmark-specific data is excluded. The optimal training recipe is a two-stage pipeline: SFT for coarse alignment on paired data, followed by RecA for self-supervised, fine-grained refinement. Applying SFT after RecA degrades performance, underscoring the necessity of RecA as the final alignment stage.
Robustness to Benchmark Overfitting
RecA exhibits superior robustness to benchmark-specific overfitting compared to SFT, as evidenced by minimal performance degradation when GenEval template leakage is removed from the training data. This suggests that RecA's self-supervised objective confers greater generalization and universality.
Qualitative Results: Faithfulness and Detail Preservation
Qualitative T2I and editing results further substantiate RecA's effectiveness. The post-trained models generate images that are more faithful to prompt instructions, with improved color, spatial, and attribute alignment, and demonstrate superior identity preservation and background consistency in editing tasks.

Figure 4: Qualitative T2I results at high resolution, showing RecA's ability to generate images faithful to complex prompts.

Figure 5: Qualitative image editing results, with RecA post-trained BAGEL producing more semantically consistent edits.

Figure 6: RecA achieves more faithful instruction following, better identity preservation, and stronger background consistency compared to prior methods.
Uncurated generation results on challenging prompts (e.g., "a white banana and a black banana", "a photo of a yellow broccoli") illustrate RecA's ability to overcome dataset biases and generate atypical concepts that baseline models systematically fail to produce.

Figure 7: RecA enables correct generation of atypical concepts (e.g., white and black bananas) missed by the baseline.
Figure 8: RecA corrects color bias, enabling generation of "yellow broccoli" as prompted.
Limitations and Future Directions
While RecA yields substantial improvements in semantic alignment and visual fidelity, gains on mid-level visual features such as counting remain limited. This is attributed to the difficulty of extracting such features from language-aligned embeddings. Further, RecA's effectiveness is constrained in architectures with limited representational capacity (e.g., Show-o with small codebooks) or models that already incorporate strong reconstruction objectives (e.g., BLIP-3o).
Future research directions include:
- Integrating RecA with reinforcement learning or mixture objectives to improve mid-level feature alignment (e.g., counting).
- Exploring regularization strategies to mitigate overfitting in models with discrete tokenization.
- Extending RecA to video and other modalities, leveraging dense semantic embeddings for unified multimodal alignment.
- Investigating the interplay between RecA and advanced prompt engineering or in-context learning strategies.
Implications for Multimodal AI
RecA establishes a new paradigm for post-training UMMs, demonstrating that dense, self-supervised semantic reconstruction is a more effective and robust alignment strategy than supervised fine-tuning on paired data. This has significant implications for the development of scalable, data-efficient, and generalizable multimodal models. By decoupling generation supervision from the limitations of textual annotation, RecA paves the way for leveraging vast unlabeled image corpora and advances the field toward more faithful, controllable, and semantically aligned visual generation and editing.
Conclusion
Reconstruction Alignment (RecA) is a simple yet effective post-training method that leverages dense semantic embeddings from visual understanding encoders to realign the latent spaces of unified multimodal models. RecA consistently improves image generation and editing fidelity across diverse architectures, surpasses much larger models on standard benchmarks, and exhibits superior robustness to benchmark-specific overfitting. The method's efficiency, generality, and empirical strength position it as a foundational technique for future research in unified multimodal understanding and generation.