Omni-R1: Towards the Unified Generative Paradigm for Multimodal Reasoning
Abstract: Multimodal LLMs (MLLMs) are making significant progress in multimodal reasoning. Early approaches focus on pure text-based reasoning. More recent studies have incorporated multimodal information into the reasoning steps; however, they often follow a single task-specific reasoning pattern, which limits their generalizability across various multimodal tasks. In fact, there are numerous multimodal tasks requiring diverse reasoning skills, such as zooming in on a specific region or marking an object within an image. To address this, we propose unified generative multimodal reasoning, which unifies diverse multimodal reasoning skills by generating intermediate images during the reasoning process. We instantiate this paradigm with Omni-R1, a two-stage SFT+RL framework featuring perception alignment loss and perception reward, thereby enabling functional image generation. Additionally, we introduce Omni-R1-Zero, which eliminates the need for multimodal annotations by bootstrapping step-wise visualizations from text-only reasoning data. Empirical results show that Omni-R1 achieves unified generative reasoning across a wide range of multimodal tasks, and Omni-R1-Zero can match or even surpass Omni-R1 on average, suggesting a promising direction for generative multimodal reasoning.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
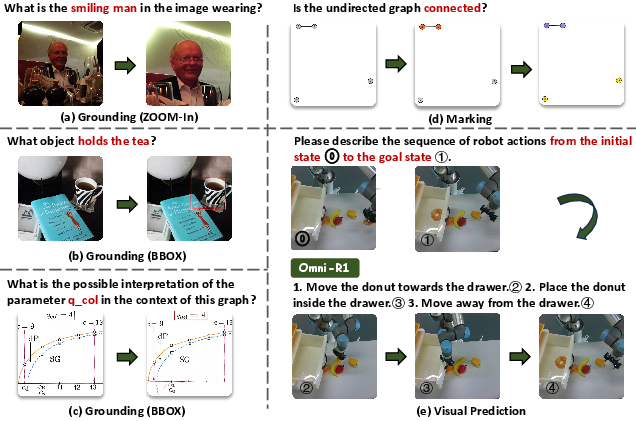
This paper introduces a new way for AI models to “think” using both words and pictures at the same time. The authors call it unified generative multimodal reasoning. Instead of only writing out steps in text, the model also generates helpful intermediate images during its reasoning—like zooming in on a part of a photo, drawing boxes around objects, sketching helper lines on a math diagram, or predicting what a scene will look like next. They build two systems:
- Omni-R1, which learns from a small set of human examples plus reinforcement learning.
- Omni-R1-Zero, which avoids expensive labeling by creating its own simple visual steps from text-only data.
Key Objectives
The paper focuses on three main goals:
- Make one model handle many different visual reasoning skills in a single, unified process.
- Teach the model to create “functional” images while reasoning (for example, images with boxes, arrows, or numbers that clarify the logic).
- Reduce the need for costly human-made, step-by-step multimodal annotations by bootstrapping visuals from text-only reasoning.
Methods and Approach
The core idea: Think by generating pictures
Many tasks become easier if the model can:
- Zoom in on the important region of an image.
- Draw a bounding box to point at a target.
- Add helper lines to a geometry diagram.
- Mark or number objects so it can refer to them clearly.
- Predict the next state of a scene (like a future frame or a game move).
This work trains the model to produce such intermediate images during its reasoning, not just a final answer.
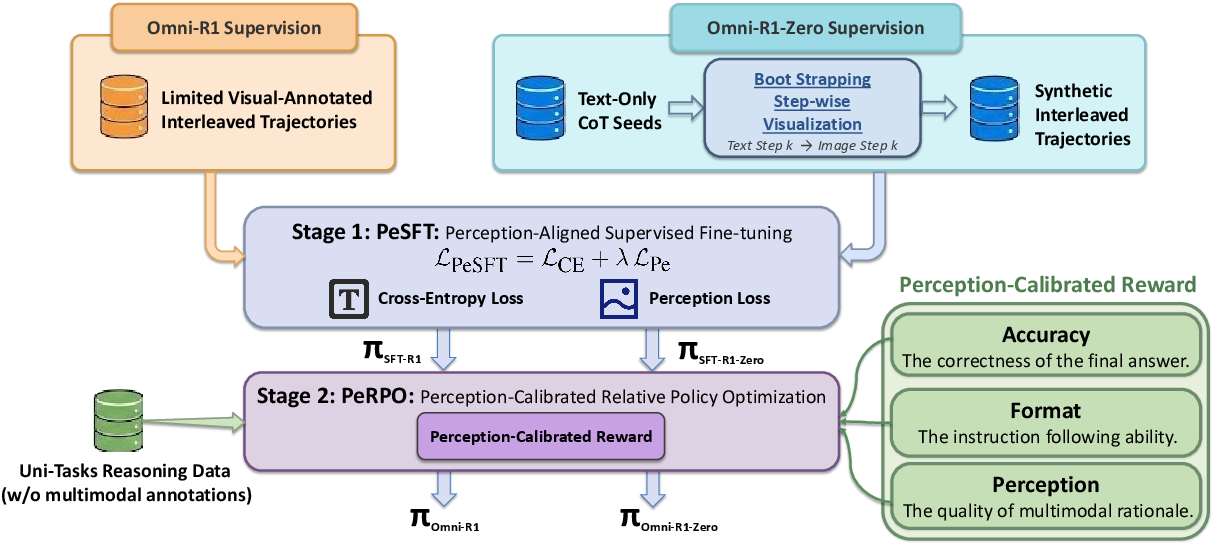
Two-stage training
Both Omni-R1 and Omni-R1-Zero use two stages:
- Supervised Fine-Tuning (PeSFT): Learn the basic format of interleaved text-and-image reasoning.
- Reinforcement Learning (PeRPO): Practice making better decisions using rewards that judge accuracy, formatting, and visual quality.
Stage 1: PeSFT (learn the format and visuals)
- Cross-entropy loss: Think of this as “copying the good examples.” The model practices following the ideal, interleaved steps (text + image) given in training data.
- Perception alignment loss: The model has a visual “codebook” (like a big paint-by-numbers palette). When it generates image tokens, this loss nudges them to match the correct visual codes. This makes the model’s drawings cleaner and more stable, especially for “functional” images that include boxes, labels, or helper lines.
Stage 2: PeRPO (get better with rewards)
The model gets points (rewards) based on three things:
- Accuracy: Is the final answer correct?
- Format: Is the output organized so the answer can be parsed reliably?
- Perception: Are the generated images visually coherent (not messy or noisy)? The paper measures this with a smoothness score (called 2D total variation): cleaner, less jumpy images score higher.
To train efficiently, the model generates multiple candidate solutions, scores them, and learns more from the stronger ones (a “group-relative” PPO approach). You can think of it like a mini-competition per problem: the model compares its different attempts, notices which ones did better, and shifts in that direction.
Omni-R1 vs. Omni-R1-Zero
- Omni-R1 uses a small amount of human-made interleaved examples to start, then improves with reinforcement learning.
- Omni-R1-Zero starts with text-only reasoning steps (no human images). It automatically creates simple “step-wise visualizations” for each text step—like drawing a box where the text says “focus here,” or sketching a helper line for “align these points.” Then it trains with the same two-stage process. This reduces the need for expensive multimodal labels.
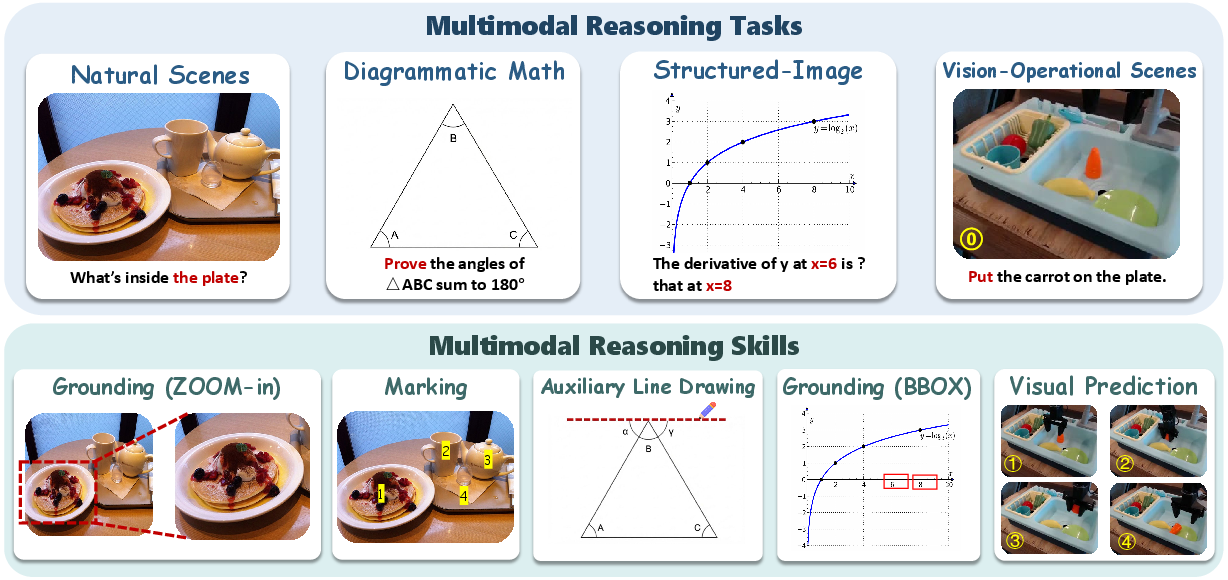
How they evaluated: Omni-Bench and standard tests
The authors built Omni-Bench, a collection of 800 problems across four scenarios:
- Natural-Scene Perception: Find and use evidence in real-world photos.
- Diagrammatic Math: Solve geometry and visual math with diagrams.
- Structured-Image: Read charts, figures, and mixed text-graphics.
- Vision-Operational Scenes: Do complex visual operations, like visual puzzles, planning, or predicting next states.
They also summarized four recurring “Uni-Skills” the model should use:
- Grounding (zoom-in, draw boxes to locate evidence)
- Auxiliary line drawing (helper lines in geometry)
- Marking (highlight or number important items)
- Visual prediction (guess what the scene looks like after one step)
Beyond Omni-Bench, they tested on widely used benchmarks (like MME, MM-Vet, POPE, and more) using public evaluation tools.
Main Findings
- Both Omni-R1 and Omni-R1-Zero beat strong baselines (Anole and Zebra-CoT) across the four Omni-Bench task types.
- The biggest gains happen on vision-operational tasks—where intermediate images (like predicted transitions or sequence steps) really help.
- Omni-R1-Zero (which doesn’t rely on human multimodal labels) often matches or even outperforms Omni-R1 on average. This suggests the bootstrapped visuals plus reinforcement learning are surprisingly powerful.
- On general benchmarks, Omni-R1 tends to shine in perception-heavy tests (better fine-grained visual handling), while Omni-R1-Zero is particularly strong in reasoning-oriented tests and reduces hallucinations (it sticks closer to evidence).
- Ablation studies show:
- Reinforcement learning (PeRPO) is crucial, especially for multi-step, complex visual reasoning.
- The perception reward (judging visual smoothness/coherence) helps stabilize training and improves performance on tasks needing clean, functional images.
Implications and Impact
This research points to a practical and promising direction:
- One model can learn a wide range of visual reasoning skills by generating helpful intermediate images—not just writing text explanations.
- The reasoning becomes more interpretable: you can “see” the model’s thought process as it zooms in, draws boxes, and marks key parts.
- It reduces dependence on expensive labeled multimodal data: Omni-R1-Zero shows that you can bootstrap visuals from text-only steps and still get strong results.
- Potential uses include education (clear step-by-step visual explanations), accessibility (visual highlighting of important parts), robotics and planning (predicting scene changes), and data analysis of charts and figures.
In short, teaching AI to think with images as well as words—inside one unified, generative process—can make it more accurate, more versatile, and easier to understand.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, formulated to be actionable for future research.
- Dataset scope and representativeness: Omni-Bench contains only 800 samples from a limited set of domains; scaling to larger, more diverse, and long-horizon settings (e.g., video, 3D scenes, audio, medical, remote sensing, robotics) remains untested.
- Intermediate visual artifact evaluation: No quantitative metrics for the generated “functional images” (e.g., bounding-box IoU, crop accuracy/coverage, auxiliary line correctness, instance marking precision/recall, visual prediction fidelity); develop task-specific measures to assess whether intermediate images are semantically correct and helpful.
- Reliance on LLM-as-a-judge: Final answer correctness uses an LLM judge and rule-based verifier; robustness, bias, and reliability of this evaluation are not examined (e.g., agreement with human graders, sensitivity to prompt/format, adversarial robustness).
- Semantic adequacy of the perception reward: The 2D Total Variation (TV) reward on codebook embeddings incentivizes smoothness, not semantic alignment; investigate semantic rewards (e.g., CLIP/image-text consistency, detection/grounding scores, segmentation metrics, OCR consistency, differentiable scene graphs).
- Reward weight and sensitivity analysis: The choice and tuning of α, β, γ (reward weights) and τ (TV sensitivity) are not studied; perform systematic ablations/sensitivity analyses to understand stability and performance trade-offs.
- Perception alignment loss design: PeSFT uses L2 alignment to a frozen codebook; compare against alternatives (contrastive/perceptual losses, adversarial objectives, quantization-aware training) and study the impact of the alignment weight λ (set to 1 without ablation).
- Bootstrapped visualization details and fidelity: Omni-R1-Zero’s step-wise image synthesis from text CoT lacks methodological specifics (how images are rendered, controls for grounding/marking); evaluate the faithfulness of synthetic visuals to textual steps and their impact on downstream correctness.
- RL sampling and optimization strategy: Group-relative PPO with mixed-outcome filtering is used, but sample efficiency, convergence behavior, and comparisons to other RLHF/RLAIF variants (e.g., advantage normalization schemes, off-policy corrections, curriculum schedules) are missing.
- Scaling and compute efficiency: The cost of generating many intermediate images during training/inference (latency, memory, throughput, energy) and its scalability to larger backbones or longer trajectories is not quantified.
- Backbone generality: Experiments use Anole; portability of Omni-R1/Omni-R1-Zero to other omni-models or non-native interleaved architectures (e.g., Chameleon, LLaVA-Omni, Gemini-like) is untested.
- Transfer to unseen task families: Generalization to structurally different tasks (e.g., embodied control, interactive GUIs, multi-step environment state transitions) and domain-shift robustness are not characterized.
- Robustness to input perturbations: No tests for resilience to image corruptions (noise/blur), occlusion, adversarial images/prompts, or distractors; design stress tests to assess stability.
- Causal efficacy of visual interleaving: The paper reports gains but does not isolate whether intermediate image generation causally improves reasoning versus text-only baselines under controlled conditions; conduct matched ablations and counterfactual studies.
- Human interpretability and utility: Whether the functional images are comprehensible, trustworthy, and useful for human auditing or collaboration (user studies, error analysis aids) remains unexplored.
- Comparison to tool-based pipelines: The generative “zoom-in” and “grounding” are not compared against external tool use (cropping, detection, segmentation); quantify trade-offs in accuracy, speed, and reliability.
- Visual prediction beyond one step: Vision-operational skills focus on one-step state transitions; multi-step rollouts, physical plausibility constraints, and planning metrics (e.g., success rate in simulated tasks) are missing.
- Data leakage and contamination: No discussion of overlap between training sources and evaluation sets; perform and report contamination checks.
- Template rigidity effects: The format reward enforces a fixed interleaved template; study whether this reduces flexibility/creativity or causes brittleness when templates vary across tasks/datasets.
- Safety, ethics, and privacy: Generating overlays (marks/boxes) on sensitive images and hallucinated visuals pose risks; establish content safety filters and privacy guidelines for intermediary generations.
- Training data quantification: “Small amount” of interleaved annotations for Omni-R1 is not specified; provide exact counts and study how performance scales with annotation volume.
- Reproducibility gaps: Key implementation details are deferred to appendices (not provided here) and hyperparameters (e.g., KL regularization to a reference policy, ε clip ranges) lack thorough reporting; release full configs, seeds, and code for reproducibility.
- Grounding skill validation: Claims of grounding are not backed by standard metrics (IoU/AP against ground-truth boxes/masks, referring expression accuracy); integrate established benchmarks and metrics for grounding/segmentation.
- Generated zoom-in vs. true crop: It’s unclear if “zoom-in via generation” replicates the fidelity of cropping the original image; compare their effects on downstream accuracy and perceptual quality.
- Codebook dependence: Both PeSFT and PeRPO rely on a frozen VQVAE codebook; evaluate robustness across tokenizers/codebooks (e.g., different quantizers, token grid sizes) and study their impact on generation stability and reward guidance.
- Reward hacking risks: TV-based rewards might be gamed by producing uniform or low-frequency code sequences; design anti-hacking checks and mixed semantic constraints to mitigate degenerate solutions.
- Inference-time policy control: The policy’s decision of when to generate visual steps versus text-only reasoning is not analyzed; add mechanisms and metrics for adaptive interleaving frequency and step selection.
- Explaining Omni-R1-Zero’s edge: Omni-R1-Zero sometimes surpasses Omni-R1, but the underlying reasons (exploration vs. supervision trade-offs, distributional breadth) are only qualitatively hinted; perform causal and diagnostic analyses.
- Scheduling and curriculum: How to best schedule SFT vs. RL phases, or interleave rewards/losses for stable training, is left open; investigate curricula and adaptive weighting strategies.
- Cross-modal alignment metrics: Co-reference and consistency between text rationales and generated visuals are not quantitatively measured; introduce alignment scores (e.g., text-to-image grounding consistency, referential coherence).
- Benchmark release clarity: Omni-Bench composition is described but availability, licensing, and detailed annotation schemas for intermediate skills are unclear; formalize and release resources for community evaluation.
Glossary
- Auxiliary line drawing: A visual reasoning skill that adds helper lines to clarify geometric relations. "Auxiliary line drawing draws helper lines to make geometric relations or alignment constraints explicit."
- BBOX: Abbreviation for bounding box annotations used to localize objects in images. "Grounding (BBOX)"
- Bootstrapping step-wise visualization: Synthesizing interleaved multimodal traces by generating one image per reasoning step from text-only rationales. "it introduces a bootstrapping step-wise visualization method to synthesize interleaved-modal reasoning data."
- Chain-of-Thought (CoT): Step-by-step reasoning format, typically textual, used to structure solutions. "Omni-R1-Zero starts from text-only Chain-of-Thought (CoT) seeds"
- Codebook embeddings: Continuous vectors retrieved from a discrete visual codebook for image-token representations. "2D Total Variation (TV) on codebook embeddings."
- Diagrammatic Math: Task category involving diagram-grounded visual arithmetic and geometric reasoning. "Diagrammatic Math involves diagram-grounded visual arithmetic and geometric reasoning."
- Group-relative PPO objective: An RL objective that normalizes rewards within sampled groups to compute advantages for policy updates. "a group-relative PPO objective"
- Grounding: Localizing task-relevant visual evidence, possibly zooming for closer inspection. "Grounding localizes task-relevant evidence and may zoom in for closer inspection when needed."
- Interleaved generation: Producing sequences that mix image and text segments within a single model. "interleaving has been realized within a single omni-model as interleaved generation."
- Interleaved-modal reasoning: Reasoning that incorporates visual information throughout intermediate steps rather than only at the beginning or end. "interleaved-modal reasoning"
- KL regularizer: A penalty term based on Kullback–Leibler divergence to keep the learned policy close to a reference. "maximize a PPO-clip objective with a KL regularizer"
- LLM judge: Using a LLM as an automatic evaluator for answer correctness. "use an LLM judge ... producing a binary correctness decision."
- Multimodal LLMs (MLLMs): LLMs that process and generate across modalities like text and images. "Multimodal LLMs (MLLMs) are making significant progress in multimodal reasoning."
- Natural-Scene Perception: Task slice focused on evidence localization within natural images. "Natural-Scene Perception focuses on natural-scene images and requires evidence localization for answering."
- Omni-Bench: A unified benchmark comprising diverse multimodal tasks and skills for evaluation. "we conduct Omni-Bench"
- Omni-model: A single model capable of native interleaved multimodal generation. "within a single omni-model"
- Perception alignment loss: A training loss that aligns image-token hidden states with a frozen visual codebook to stabilize generation. "perception alignment loss"
- Perception-calibrated reward: A composite RL reward combining accuracy, format, and perceptual coherence of intermediate images. "a perception-calibrated reward to more accurately align RL feedback with the quality of intermediate functional image generations."
- Perception loss: An L2 loss projecting hidden states onto codebook embeddings for image-token segments. "We define the perception loss as:"
- PeRPO (Perception-Calibrated Relative Policy Optimization): The RL stage that refines policy with perception-aware rewards for interleaved multimodal sequences. "Perception-Calibrated Relative Policy Optimization (PeRPO)."
- PeSFT (Perception-Aligned Supervised Fine-Tuning): The supervised stage that learns interleaved format and stabilizes image-token generation via perception loss. "Perception-Aligned Supervised Fine-Tuning (PeSFT)."
- PPO-clip objective: The clipped surrogate loss used in Proximal Policy Optimization for stable policy updates. "maximize a PPO-clip objective with a KL regularizer"
- Quantized image grid: The discrete spatial grid of image tokens produced by a VQVAE quantizer. "quantized image grid in VQVAE of the model"
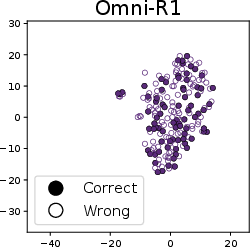
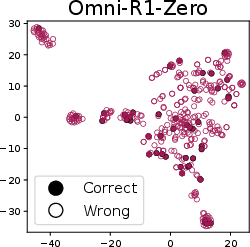
- t-SNE visualization: A dimensionality reduction technique for visualizing clusters in generated images or embeddings. "The t-SNE visualization of generated images from Omni-R1 and Omni-R1-Zero"
- Total Variation (TV): A smoothness measure over neighboring embeddings used to assess perceptual coherence of generated images. "2D Total Variation (TV)"
- Uni-Skills: A set of recurring visual skills (Grounding, Auxiliary line drawing, Marking, Visual prediction) for functional image generation. "We summarize them as four Uni-Skills:"
- Uni-Tasks: Canonical multimodal task slices used in the benchmark (Natural-Scene Perception, Diagrammatic Math, Structured-Image, Vision-Operational Scenes). "Uni-Tasks characterize the multimodal reasoning scenarios included in Omni-Bench."
- VQVAE: Vector-Quantized Variational Autoencoder used to discretize images into codebook indices. "in VQVAE of the model"
- Visual codebook: A fixed table of embeddings for discrete image tokens used during generation and loss alignment. "We utilize a visual codebook "
- Visual prediction: Forecasting the next visual state via one-step transition during reasoning. "Visual prediction anticipates the next visual state by performing a one-step transition."
- VLMEvalKit: An open-source toolkit for evaluating multimodal models across standard benchmarks. "we conducted evaluation using the widely adopted VLMEvalKit"
- VQA (Visual Question Answering): Tasks requiring answering questions about images. "for VQA tasks."
- Zoom-in: A reasoning skill that magnifies critical image regions to aid visual analysis. "skills such as zoom-in and grounding are essential for general VQA tasks"
Practical Applications
Overview
Omni-R1 proposes a unified generative multimodal reasoning paradigm where a single multimodal LLM not only produces text but also generates functional intermediate images (e.g., zoom-ins, bounding boxes, auxiliary lines, markings, one-step visual predictions) as part of its reasoning. It introduces:
- A two-stage training recipe (PeSFT + PeRPO) with perception alignment loss and perception-calibrated rewards to stabilize functional image generation and improve correctness/formatting.
- Omni-R1-Zero, which bootstraps step-wise visualizations from text-only CoT to eliminate the need for scarce interleaved multimodal annotations.
Below are actionable applications derived from the paper’s methods, findings, and innovations. Each item includes sectors, potential tools/products/workflows, and assumptions/dependencies that affect feasibility.
Immediate Applications
These can be prototyped or deployed now with current omni-models that support interleaved image-text generation and moderate engineering effort.
- Chart and figure explainer for analytics and scientific literature
- Sectors: software (BI/analytics), academia, finance, enterprise knowledge management
- What emerges: “Chart Explainer” service that ingests dashboards, reports, or PDFs and outputs grounded explanations with marked regions, callouts, and step-by-step rationale; integration into Tableau/Power BI/Notebooks to auto-annotate trends, outliers, and computed values
- Dependencies/assumptions: access to high-quality rasterized figures; stable VQ codebook for functional markings; domain-specific prompt templates for charts; human review loops for critical decisions
- Grounded visual question answering widgets for websites and products
- Sectors: e-commerce, customer support, media platforms
- What emerges: on-page Q&A that highlights product attributes, zooms relevant areas, and shows bounding boxes to reduce hallucinations (leveraging Omni-R1’s improved POPE scores)
- Dependencies/assumptions: reliable parsing of site images; policy for annotating user-uploaded or copyrighted images; latency budgets for interactive sessions
- Geometry and diagram tutoring with auxiliary lines and markings
- Sectors: education, EdTech
- What emerges: interactive tutor that draws helper lines, enumerates angles/segments, zooms key regions, and narrates reasoning; homework grading with grounded feedback
- Dependencies/assumptions: safe-mode guardrails for academic integrity; curriculum-aligned templates; device-friendly rendering of generated visuals
- Technical documentation and SOP assistants with annotated steps
- Sectors: manufacturing, field service, IT/DevOps, consumer electronics
- What emerges: “step-wise visual guides” that overlay numbered markers, arrows, and zoom-ins on images/screenshots for installation, maintenance, or troubleshooting workflows
- Dependencies/assumptions: clean image capture; UI for overlay rendering; domain prompts per device/system; QA checklists to avoid propagating errors
- Annotation acceleration via synthetic interleaved traces
- Sectors: AI/ML tooling, dataset operations
- What emerges: “Auto-Labeler” pipeline that uses Omni-R1-Zero to synthesize image-text interleaved rationales from text-only CoT, cutting reliance on costly multimodal trace annotations
- Dependencies/assumptions: governance to distinguish synthetic vs. gold labels; reward design (PeRPO) tuned per target task; monitoring for bias or drift in synthetic supervision
- Evidence-grounded enterprise document intake
- Sectors: finance, insurance, legal, procurement
- What emerges: document parsers that highlight and number referenced fields (e.g., invoice totals, fees, clauses) with visual grounding and formatted answers
- Dependencies/assumptions: OCR integration for scanned docs; privacy/compliance controls; auditable output formatting (benefits from Omni-R1’s format reward)
- Accessibility overlays with region references
- Sectors: accessibility (A11y), public sector, education
- What emerges: enriched alt-text and guided descriptions that include bounding boxes/zoom-ins to reference visual evidence for low-vision users
- Dependencies/assumptions: site-level integration and consent; safe rendering layers; careful handling of sensitive imagery
- Manufacturing quality control (QC) pre-screener
- Sectors: manufacturing, logistics
- What emerges: camera-based pre-screeners that mark suspected defects, count items, and point to regions for human verification; offline triage tools
- Dependencies/assumptions: domain-specific fine-tuning on parts/defects; controlled lighting and placement; human-in-the-loop for final decisions
- UI testing and bug reproduction with annotated screenshots
- Sectors: software engineering, QA
- What emerges: “Visual CoT” debugging assistant that produces step-by-step annotated screenshots showing where assumptions fail (missing buttons, misaligned elements), plus a text rationale
- Dependencies/assumptions: CI integration; consistent screenshot capture; privacy redaction for sensitive UIs
- Patent and legal diagram analysis
- Sectors: legal, IP, R&D strategy
- What emerges: tools that mark claim-relevant components in drawings, number references, and align text claims to visual evidence
- Dependencies/assumptions: domain-specific prompts and glossaries; human counsel review; provenance tracking for regulatory defensibility
- Safer multimodal responses with visible evidence
- Sectors: online platforms, search, assistants
- What emerges: assistants that always “show their work” via grounded region highlights, reducing unsupported claims and improving user trust
- Dependencies/assumptions: UX that foregrounds generated evidence; fallback pathways when visual confidence is low (format/accuracy rewards help triage)
Long-Term Applications
These require further research, scaling, domain adaptation, safety validation, or systems integration (e.g., real-time control, regulation).
- Embodied robotics with visual prediction-of-thought
- Sectors: robotics, warehousing, manufacturing, service robots
- What emerges: “Robotics Planner Visualizer” that predicts one-step scene transitions with intermediate images, enabling debugging, plan verification, and eventually closed-loop control with grounded evidence
- Dependencies/assumptions: sim-to-real transfer; latency and reliability in real-time; safety cases; multi-sensor fusion and calibration
- Medical imaging decision support with grounded visual evidence
- Sectors: healthcare
- What emerges: assistive readers that mark suspected regions (lesions, measurements), zoom critical areas, and provide step-wise visual rationale for radiology/pathology review
- Dependencies/assumptions: rigorous clinical validation; FDA/CE approvals; domain-specific codebooks and tuning; data privacy and PHI controls
- ADAS/autonomous driving scenario explanation and foresight
- Sectors: transportation, automotive
- What emerges: driver-assistance explainers that highlight relevant actors/regions and visualize short-horizon predictions (e.g., pedestrian motion), improving interpretability and incident review
- Dependencies/assumptions: multi-camera/LiDAR fusion; embedded inference constraints; safety standards (ISO 26262); robust failure handling
- Regulatory-grade audit trails with standardized visual evidence
- Sectors: policy/regulation, finance, healthcare, public sector
- What emerges: explainability packages where every ML decision includes annotated visual evidence, machine-parseable formats, and verifiable reward-aligned reasoning traces
- Dependencies/assumptions: standards for “evidence localization” and format; third-party verification; secure logging and provenance
- Human-in-the-loop visual reasoning editors
- Sectors: enterprise tooling, UX design, education
- What emerges: collaborative interfaces where users can edit intermediate generated images (e.g., adjust bounding boxes/aux lines) to steer reasoning and improve final outputs
- Dependencies/assumptions: bidirectional grounding between edits and model state; conflict resolution; version control for reasoning trajectories
- Edge/on-device generative multimodal reasoning
- Sectors: mobile, AR/VR, IoT
- What emerges: on-device assistants that perform local zoom/mark/predict steps for privacy-critical scenarios (AR guidance, factory handhelds)
- Dependencies/assumptions: efficient codebooks and quantization; low-latency RL-tuned policies; thermal and power constraints
- Disaster response and urban planning with grounded remote sensing
- Sectors: public sector, civil engineering, insurance
- What emerges: systems that mark flooding, damage extents, encroachments, and infrastructure changes with evidence overlays and step-wise justification
- Dependencies/assumptions: domain-specific satellite/aerial datasets; geospatial registration; human analyst validation; data-sharing agreements
- Large-scale synthetic corpus generation for interleaved training
- Sectors: AI/ML platforms, foundation model labs
- What emerges: pipelines that mass-produce interleaved image-text traces (via Omni-R1-Zero) to unlock new domains (e.g., charts, CAD, electronics schematics)
- Dependencies/assumptions: quality governance and deduplication; curriculum design; scalable RL (PeRPO) infra; bias and safety audits
- AR-guided step-by-step real-world assistance
- Sectors: field service, consumer DIY, education
- What emerges: wearable/AR overlays that number parts, draw arrows/aux-lines on live video, and visualize next-step predictions for hands-on tasks
- Dependencies/assumptions: robust tracking and alignment; on-device or low-latency edge inference; safety disclaimers; user training
- Cross-document scientific claim verification with figure-grounding
- Sectors: academia, R&D, publishing
- What emerges: tools that link textual claims to specific regions in figures/tables across papers, producing a visual trail of supporting/refuting evidence
- Dependencies/assumptions: reliable PDF/figure parsing; domain ontologies; human curator workflows; publisher integrations
Notes on Feasibility and Transfer
- Model prerequisites: an omni-model capable of interleaved generation (e.g., Anole/Chameleon-like backbones), a stable VQ/VAE codebook, and the proposed PeSFT+PeRPO training (or access to Omni-R1(-Zero) checkpoints).
- Data regime: Omni-R1-Zero lowers annotation costs by bootstrapping from text-only CoT, but domain adaptation (e.g., medical, manufacturing) still benefits from curated seeds and tailored rewards.
- Reliability and safety: perception-calibrated rewards and format/accuracy checks improve robustness, but high-stakes deployments require external verifiers, human oversight, and domain audits.
- Tooling integration: practical deployments need rendering layers for overlays, provenance tracking, and APIs that expose intermediate evidence (images + rationale) alongside final answers.
- Governance: adhere to IP/privacy constraints when annotating third-party imagery; implement consent mechanisms and redaction where needed.
Collections
Sign up for free to add this paper to one or more collections.

