MAR:Multi-Agent Reflexion Improves Reasoning Abilities in LLMs
Abstract: LLMs have shown the capacity to improve their performance on reasoning tasks through reflecting on their mistakes, and acting with these reflections in mind. However, continual reflections of the same LLM onto itself exhibit degeneration of thought, where the LLM continues to repeat the same errors again and again even with the knowledge that its wrong. To address this problem, we instead introduce multi-agent with multi-persona debators as the method to generate reflections. Through out extensive experimentation, we've found that the leads to better diversity of in the reflections generated by the LLM agent. We demonstrate an accuracy of 47% EM HotPot QA (question answering) and 82.7% on HumanEval (programming), both performances surpassing reflection with a single LLM.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how to help AI LLMs get better at solving hard problems by learning from their mistakes without retraining them. The authors test a popular method called “Reflexion,” find its weaknesses, and introduce a new approach called “Multi‑Agent Reflexion (MAR)” that uses multiple AI “critics” to give better feedback. MAR helps the main AI avoid repeating the same errors and improves its results on both question answering and coding tasks.
What questions are the researchers trying to answer?
The paper asks three main questions in simple terms:
- Can an AI improve just by reading feedback about its own mistakes, instead of being retrained?
- Why does the original Reflexion method sometimes get stuck, repeating the same wrong ideas?
- Would using multiple different “voices” (personas) to critique the AI’s work lead to better guidance and better results?
How did they do it?
Think of the AI like a student taking practice tests. After each try, the student reads feedback and then tries again.
First, the team re‑runs (“replicates”) the original Reflexion setup:
- Reflexion: The same AI acts, checks itself, and writes advice to itself after it fails.
They find problems: when one AI evaluates and advises itself, it often repeats the same flawed reasoning (like a student convinced their wrong method is right).
So they build Multi‑Agent Reflexion (MAR):
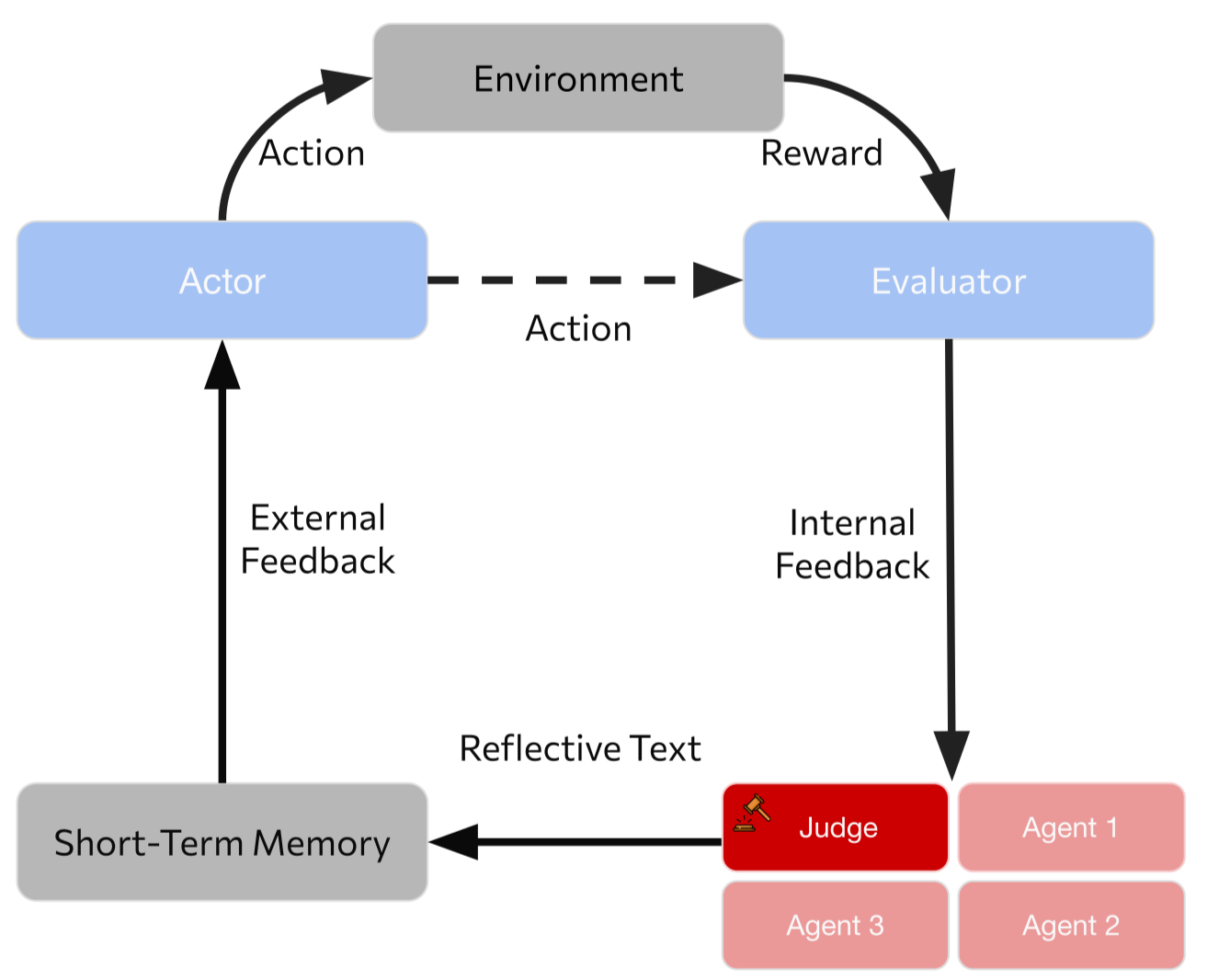
- Imagine the student getting advice from several classmates with different strengths (a Skeptic, a Logician, a Verifier, a Creative thinker), plus a teacher (the Judge) who reads all the advice and writes a clear summary for what to fix next.
Here’s the loop in everyday terms:
- The Actor tries to answer the question or write code.
- The Evaluator checks if the attempt worked (for code, unit tests; for questions, exact match with the right answer).
- If it failed, multiple Critics (each with a different persona) explain what went wrong and suggest fixes.
- The Judge combines their feedback into one helpful “reflection” note.
- The Actor tries again using this note.
They test this on two benchmarks:
- HotPotQA: Answering questions that require finding and combining facts from more than one source.
- HumanEval: Writing small coding functions that must pass hidden tests.
A few technical terms explained simply:
- LLM: An AI that reads and writes text.
- Chain‑of‑Thought (CoT): Asking the AI to show its steps, like “think out loud” before answering.
- ReAct: A style where the AI explains its reasoning and also performs actions (like looking up info), reacting to what it finds.
- Exact Match (EM): The answer must match the official answer text exactly, even small formatting differences can count as wrong.
- pass@1: The AI’s first solution must pass all tests.
What did they find, and why does it matter?
Main results:
- The original single‑agent Reflexion helps, but it often gets stuck repeating the same mistakes due to “confirmation bias” and “mode collapse” (thinking the same way over and over).
- MAR, with multiple critics and a judge, reduces these issues and improves performance:
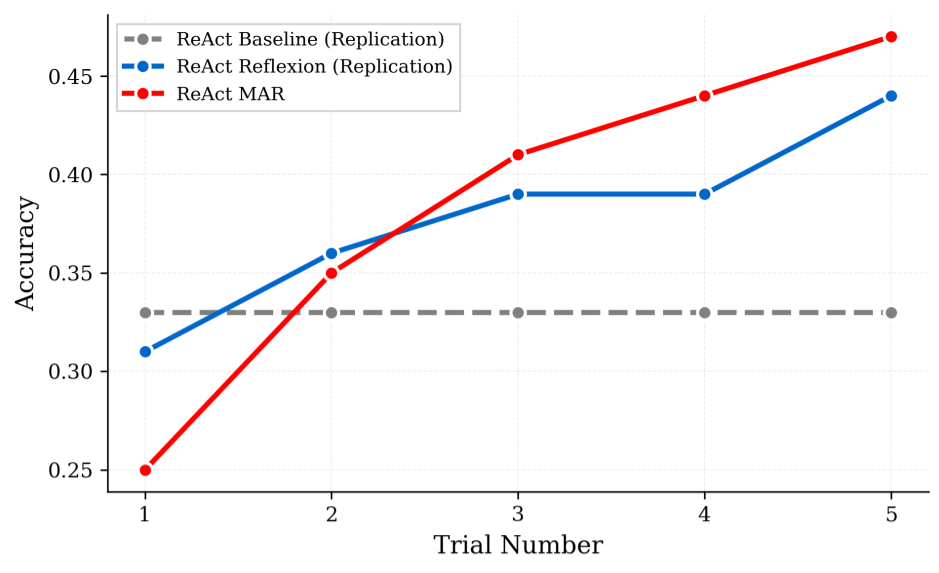
- On HotPotQA, EM accuracy rises from 44% (Reflexion) to 47% (MAR), a 3‑point gain.
- On HumanEval (coding), pass@1 goes from 76.4% (Reflexion with GPT‑3.5) to 82.6% (MAR), a 6.2‑point gain.
- MAR’s debates encourage diverse thinking, spot different kinds of errors, and produce clearer, more actionable feedback. This helps the main AI break out of bad patterns.
Important nuance:
- HotPotQA’s EM is strict: even a correct answer with slightly different wording can be marked wrong. The authors think a more forgiving measure (like checking the meaning) would show even bigger gains.
Trade‑offs:
- MAR costs more compute and time. Multiple critics plus a judge mean about three times more AI calls compared to single‑agent Reflexion.
What is the impact of this work?
In simple terms:
- If you want smarter AI problem‑solvers without expensive retraining, giving them high‑quality, diverse feedback is key.
- MAR shows that “many minds” (multiple personas) beat “one mind” (self‑reflection alone) for fixing tough reasoning mistakes.
- This can make AI more reliable for tasks like research, tutoring, and coding assistance.
However:
- Running multiple critics is more expensive and slower, so real‑world systems need ways to cut costs (for example, fewer debate rounds or only calling critics when needed).
- As AIs become more self‑improving, we need to watch for safety, transparency, and environmental impacts from increased computation.
Overall, the paper’s takeaway is encouraging: structured multi‑agent feedback helps AIs learn from mistakes more effectively, making them better at reasoning and coding without changing their internal parameters.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased as concrete, actionable items for future work.
- Generalization beyond two tasks: Validate MAR across diverse reasoning domains (math word problems, theorem proving, planning, tool-augmented tasks, interactive environments like ALFWorld) to assess task-agnostic benefits.
- Full HotPotQA coverage: Report results on the full HotPotQA dev set (not just a curated 100 “difficult” examples) to avoid selection bias and establish representativeness.
- Cross-model heterogeneity: Test MAR with heterogeneous model families (e.g., mixing GPT-3.5, GPT-4, Claude, Llama) to reduce correlated failure modes and quantify gains vs. single-family setups.
- GPT-4-based MAR: Evaluate MAR using GPT-4 (actor, critics, judge) to determine whether the observed improvements persist or amplify with stronger base models.
- Budget fairness and scaling: Control for and report identical trial budgets across baselines, Reflexion, and MAR (per dataset), including ablation of “number of retries” and “number of debate rounds,” to ensure fair comparisons.
- Statistical rigor: Provide confidence intervals, multiple seeds, and significance testing for reported gains (EM, pass@1) to quantify variability and reliability.
- Degeneration-of-thought quantification: Define and measure a concrete stagnation/degeneration metric across iterations; report effect sizes showing how MAR reduces repeated errors.
- Persona ablations: Systematically ablate persona count, diversity axes (evidence exploitation, exploration, strictness), and prompt content to isolate which dimensions drive improvements.
- Debate protocol design: Compare alternative debate structures (turn-taking, simultaneous critiques, majority vote, weighted aggregation, longer vs. shorter debates) and measure cost-performance trade-offs.
- Judge aggregation strategies: Evaluate different judge prompts, aggregation heuristics (e.g., voting, confidence-weighted synthesis), and model strengths (judge-only GPT-4) to minimize biased or incorrect consensus.
- Round cap justification: Test whether allowing more than two debate rounds materially changes outcomes; report diminishing returns curves and optimal stopping criteria.
- Metric sensitivity in HotPotQA: Re-run HotPotQA with F1, semantic-match, or entailment-based scoring to verify whether EM’s formatting/synonym sensitivity masks true reasoning improvements.
- Evaluation signal robustness: Quantify how noisy or misleading evaluator signals (EM mislabeling, flaky unit tests) affect learning dynamics, and test evaluator improvements (e.g., semantic judges, stricter unit tests).
- Memory mechanism transparency: Specify and test memory storage, retrieval, and pruning policies (e.g., top-k relevant reflections, decay, de-duplication) and measure their impact on performance and context length constraints.
- Memory contamination risk: Investigate how incorrect or low-quality reflections pollute episodic memory; design filters or validators to prevent compounding errors.
- Tool integration: Evaluate MAR with external tools (retrievers, verifiers, linters, type checkers, static analyzers, fact-checkers) to separate rhetorical “debate wins” from verifiable correctness.
- Retrieval behavior analysis in HotPotQA: Log and compare how MAR alters document retrieval choices vs. Reflexion/ReAct (e.g., top-k selection, hop paths) to confirm improvements come from better evidence usage.
- Cost and efficiency optimization: Quantify token usage, latency, and API call counts under various MAR settings; explore dynamic persona selection, early-exit heuristics, and caching to reduce 3× cost overhead.
- Robustness to adversarial or persuasive failures: Test whether debate dynamics favor persuasive but incorrect arguments; introduce truthfulness constraints or fact-grounded scoring to prevent rhetorical drift.
- Safety and alignment audits: Conduct systematic safety evaluations (specification gaming, harmful outputs, biased critiques) for multi-agent dynamics; report mitigation strategies.
- Reproducibility details: Publish full prompts (personas, judge, actor), temperatures/top-p, stop criteria, and dataset selection criteria for the “100 difficult HotPotQA questions” to enable exact replication.
- Baseline breadth: Compare MAR to other self-improvement methods (Self-Refine, MAD variants, CAMEL, Deliberate) under matched budgets to position MAR within the broader landscape.
- Controlled causal tests: Distinguish the effects of “multiple agents” vs. “persona diversity” vs. “separate roles” (actor/evaluator/critic) through targeted experimental controls.
- HumanEval scope: Extend beyond Python HumanEval to multi-language code (e.g., JavaScript, Java) and additional benchmarks (MBPP, HumanEval+), examining generalization of MAR’s programming gains.
- Failure taxonomy: Provide a systematic taxonomy of MAR failure cases (where debate misleads, judge aggregates poorly, memory harms) and quantify their frequency and causes.
- Long-term learning and distillation: Explore distilling debate-derived reflections into model parameters (fine-tuning) or compact memory modules to reduce inference-time cost while retaining gains.
- Dynamic persona generation: Automate persona creation on task-relevant axes (evidence use, exploration, strictness) and evaluate whether learned or adaptive personas outperform hand-crafted ones.
- Fairness of evaluator feedback loops: Examine how incorrect “failure” signals (e.g., EM mislabels) steer agents away from correct solutions over iterations; propose evaluator-side safeguards.
- Variance across runs: Report variance over multiple independent runs (API nondeterminism) and sensitivity to temperature/decoding settings to assess stability of MAR.
- Aggregation transparency: Define how judge resolves non-consensus (tie-breaking rules, evidence weighting), and evaluate its correctness on held-out audit sets.
- Scaling to larger benchmarks: Demonstrate MAR on large-scale settings (full dev/test sets) and report throughput limits, memory usage, and practical deployment considerations.
Practical Applications
Practical Applications of MAR: Immediate and Long-Term
Below are actionable, real-world applications of the paper’s Multi-Agent Reflexion (MAR) framework, organized by deployment horizon and linked to relevant sectors. Each item notes potential tools/products/workflows and key assumptions or dependencies affecting feasibility.
Immediate Applications
These can be deployed today with existing LLM APIs and agent frameworks.
- Software engineering: Multi-Agent Code Reviewer and Auto-Fixer
- Use case: Reduce repeated coding errors by spawning diverse critic personas (e.g., Senior Engineer, QA, Reviewer) when unit tests fail; a judge synthesizes a single patch to retry.
- Tools/products/workflows: IDE plugins (VS Code/JetBrains), CI/CD integrations (GitHub Actions, GitLab CI), sandboxed unit test runners, MAR orchestration with episodic memory.
- Assumptions/dependencies: Reliable unit tests; access to high-quality LLMs; codebase context management; security/privacy for source code; API cost/latency budgets.
- Knowledge management (enterprise search/RAG): MAR QA Assistant
- Use case: Multi-hop question answering across internal documents with persona debate to reduce hallucinations and provide citations.
- Tools/products/workflows: RAG stack (vector DB, retrievers), MAR critique + judge synthesis, answer + evidence packaging.
- Assumptions/dependencies: High-quality retrieval; citation enforcement; data governance; evaluation metrics beyond EM (e.g., semantic match/F1).
- Customer support: Escalation-aware Support Bot
- Use case: Prevent “degeneration-of-thought” in chat flows; personas debate ambiguous cases and trigger escalation or alternative solutions.
- Tools/products/workflows: CRM integration (Zendesk, Salesforce), tool APIs (refunds, order tracking), debate logs for auditability.
- Assumptions/dependencies: Domain-specific evaluators; explicit escalation policies; latency constraints; guardrails for compliance.
- Education: Multi-perspective Tutor for math/programming
- Use case: Personas (Verifier, Skeptic, Logician, Creative) critique student steps, provide structured consensus feedback and next-try guidance.
- Tools/products/workflows: LMS integration, step-by-step solution checking, reflection memory per learner.
- Assumptions/dependencies: Content moderation; pedagogical alignment; affordability at classroom scale; controlling hallucinations.
- Writing and documentation: Multi-agent Proofreader and Factuality Checker
- Use case: Improve logic, clarity, tone, and factual grounding via persona critique; judge outputs tracked edits and rationales.
- Tools/products/workflows: Document editors (Google Docs, MS Word) plugins; citation verification; change tracking.
- Assumptions/dependencies: Access to trusted sources; confidentiality; evaluation criteria for factuality.
- Research workflows: Literature Review Assistant
- Use case: MAR reconciles conflicting studies, surfaces alternative hypotheses, and suggests next experiments; reflections persist across iterations.
- Tools/products/workflows: Scholarly search APIs, MAR personas specialized by domain, memory indexing.
- Assumptions/dependencies: High-quality retrieval; domain-tuned prompts; trust calibration and traceability.
- Model safety and red-teaming: Structured Debate Red-Team
- Use case: Adversarial personas probe model outputs for bias, safety risks, and failure modes; judge summarizes vulnerabilities and fixes.
- Tools/products/workflows: Red-teaming playbooks, risk taxonomies, logging and reporting dashboards.
- Assumptions/dependencies: Clear evaluation criteria; governance processes; reproducibility; audit trails.
- Prompt engineering and agentops: Persona Palette and Reflection Memory Store
- Use case: Drop-in library of personas (varying exploitation/exploration/strictness) and a memory store to reduce repeated agent errors.
- Tools/products/workflows: LangChain/LlamaIndex integration; vector memory; configurable judge; cost monitors.
- Assumptions/dependencies: Access to LLM APIs; prompt/version management; privacy controls for memory.
- Analytics for LLM development: Failure Mode Diagnostics
- Use case: Use MAR debate logs to detect and label confirmation bias, mode collapse, and stagnation; improve prompts/evaluators.
- Tools/products/workflows: Telemetry pipelines, dashboards, log parsers, taxonomy of failure modes.
- Assumptions/dependencies: Comprehensive logging; team workflows to act on insights; controlled experiment design.
- Daily life: Multi-perspective Planner (travel, budgeting, schedules)
- Use case: Personas debate trade-offs (cost, time, preferences) and produce a consensus plan with alternatives and risks.
- Tools/products/workflows: Calendar/booking APIs, budget trackers, judge synthesis with rationale.
- Assumptions/dependencies: Fresh data access; tool API connectivity; user preferences; acceptable latency/cost.
Long-Term Applications
These require additional research, scaling, integration, or regulatory alignment.
- Healthcare: Clinical Decision Support via MAR
- Use case: Personas debate differential diagnoses, evidence, and guidelines; judge outputs cautious recommendations with citations.
- Sector: Healthcare
- Tools/products/workflows: EHR integrations; medical knowledge bases; structured reasoning traces; human-in-the-loop review.
- Assumptions/dependencies: Regulatory approval; medical-grade evaluators; bias mitigation; strict data privacy; formal validation.
- Robotics and embodied AI: Self-correcting Planning and Tool Use
- Use case: MAR guides planning, reduces repeated path-planning errors, and explores alternatives; judge selects safe action sequences.
- Sector: Robotics
- Tools/products/workflows: Simulators; real-time planners; tool APIs; compact models for low latency.
- Assumptions/dependencies: Real-time constraints; safety guarantees; robustness under distribution shift; efficient debate strategies.
- Finance/compliance/audit: Regulatory Analysis and Risk Assessment
- Use case: Multi-agent critique of filings, contracts, and transactions; judge outputs compliance gaps and risk summaries.
- Sector: Finance
- Tools/products/workflows: GRC platforms; audit trails; policy libraries; scenario testing.
- Assumptions/dependencies: Access to proprietary data; rigorous evaluators; explainability; legal review; data residency.
- Autonomous agent ecosystems: MAR-enabled Self-improving Agents
- Use case: Agents that plan, act, reflect with persona diversity and a judge; memory persists across tasks; dynamic persona selection.
- Sector: Software/agent frameworks
- Tools/products/workflows: Agent orchestration layers; tool plugins; memory graphs; policy for when to invoke debate.
- Assumptions/dependencies: Significant cost and latency reduction; robust evaluators; safety alignment; failure containment.
- Distillation and training: Learn from MAR Reflections
- Use case: Use consensus reflections and patches to fine-tune or distill smaller models; incorporate verbal rewards in RLHF.
- Sector: Academia/ML tooling
- Tools/products/workflows: Dataset curation pipelines; supervised/RL training; evaluation suites.
- Assumptions/dependencies: Licensing of reflections; generalization beyond benchmarks; training compute; benchmark design.
- Standards and metrics: Move beyond strict EM to semantic evaluators
- Use case: Adopt semantic equivalence scoring (entailment, F1, citation correctness) to better reward reasoning improvements.
- Sector: Academia/policy
- Tools/products/workflows: Benchmark governance; evaluator libraries; community consensus.
- Assumptions/dependencies: Broad adoption; alignment with task needs; reproducibility and fairness.
- Public-sector governance: Debate-based Oversight and Transparency
- Use case: Use MAR audits to evaluate AI-driven decisions (procurement, benefits eligibility, policy drafting) with traceable reasoning.
- Sector: Policy/public administration
- Tools/products/workflows: Oversight dashboards; audit logs; explainability artifacts; human review workflows.
- Assumptions/dependencies: Legal mandates; stakeholder trust; standardized processes; privacy/security.
- Energy and operations research: Scheduling and Optimization Assistants
- Use case: Persona debate explores alternative schedules and constraints (maintenance, demand, cost); judge outputs balanced plans.
- Sector: Energy/operations
- Tools/products/workflows: Optimization solvers; domain simulators; data pipelines; scenario testing.
- Assumptions/dependencies: Accurate data streams; safety constraints; integration with control systems; validation.
- Education at scale: Debate-centric curricula and auto-graders
- Use case: Class-wide MAR graders that provide multi-perspective feedback; curricula teaching structured disagreement and consensus.
- Sector: Education
- Tools/products/workflows: LMS plugins; rubric-aligned evaluators; student memory stores; analytics.
- Assumptions/dependencies: Fairness and bias checks; cost containment; teacher oversight; privacy for student data.
- Productization: MAR Studio (orchestration platform)
- Use case: End-to-end persona design, debate rounds, judge synthesis, memory indexing, cost/latency controls; marketplace of personas.
- Sector: Software/tools
- Tools/products/workflows: APIs/SDKs; dynamic persona selection; early stopping; retrieval-augmented memory.
- Assumptions/dependencies: Market adoption; operational efficiency; extensibility across domains; cost-performance tradeoffs.
- Privacy-preserving MAR: On-prem and edge deployments
- Use case: Run multi-agent debates on private infrastructure; compress models for local execution.
- Sector: Software/IT
- Tools/products/workflows: Self-hosted LLMs; model compression; secure memory stores; audit controls.
- Assumptions/dependencies: Hardware availability; model quality; maintenance overhead; compliance.
- Safety research: Guardrails for Emergent Multi-agent Behavior
- Use case: Formal monitors for debate dynamics; detect collusion or unsafe consensus; certify outputs.
- Sector: Academia/policy
- Tools/products/workflows: Formal verification, anomaly detection in debates, safety checklists.
- Assumptions/dependencies: Ground truth availability; agreed risk frameworks; evaluation at scale.
Notes on cross-cutting feasibility:
- MAR’s gains depend on model quality, evaluator robustness (unit tests, semantic scoring), and retrieval quality. Strict metrics like EM can under-credit improvements.
- Costs and latency are materially higher (~3x vs. single-agent Reflexion); dynamic persona selection, early stopping, and efficient debate strategies are important for scaling.
- Safety, privacy, and governance are critical in regulated sectors; human-in-the-loop review and transparent debate logs help manage risk.
Glossary
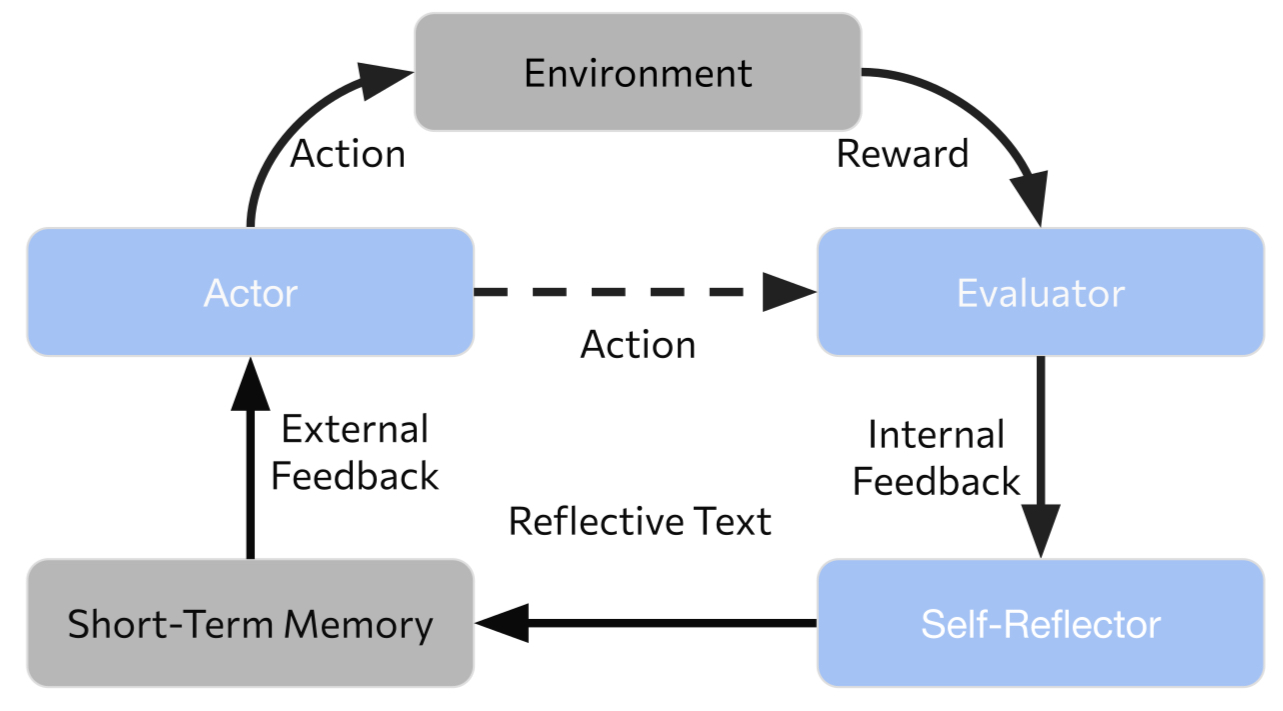
- Actor: The LLM role that acts as the agent’s policy, generating actions, reasoning, and answers. "The Actor is the LLM prompted to behave as the agentâs policy."
- Chain-of-Thought (CoT): A prompting strategy that elicits step-by-step reasoning before answering. "Chain-of-Thought (CoT) \cite{wei2022cot} prompting, which encourages structured step-by-step reasoning."
- Consensus Reflection: A synthesized, actionable summary of multi-agent critiques used to guide the next attempt. "Consensus and Reflection The judge synthesizes the debate into a single, actionable \"Consensus Reflection\""
- Confirmation Bias: A tendency to reinforce initial flawed reasoning instead of correcting it. "which often results in repeated reasoning errors, confirmation bias, and limited corrective feedback."
- Degeneration-of-Thought: A failure mode where an agent repeats the same flawed reasoning across iterations. "Reflexion is vulnerable to degeneration-of-thought \cite{liang2023divergent}"
- Episodic Memory: Stored reflections from past attempts that condition future behavior. "stores them as episodic memory that guides future attempts."
- Evaluator: The component that judges whether an Actor’s trajectory solved the task. "The Evaluator judges whether an Actor trajectory successfully solves the task."
- Exact Match (EM): A strict accuracy metric requiring exact equality to the ground-truth answer. "For HotPotQA, we report Exact Match (EM)"
- Hidden Unit Tests: Secret test cases used to validate code solutions in benchmark evaluation. "a series of hidden unit tests."
- HotPotQA: A dataset evaluating multi-hop question answering over Wikipedia. "HotPotQA evaluates multi-hop question answering over Wikipedia"
- HumanEval: A program synthesis benchmark scored by whether code passes hidden tests. "HumanEval tests program synthesis by checking whether generated functions pass hidden unit tests."
- In-Context Learning: Adapting a model using examples placed directly in the prompt without parameter updates. "In-context learning \cite{brown:20_fewshot}, where an LLM adapts using examples directly in the prompt"
- Judge Model: An aggregator that synthesizes multiple critiques into a unified reflection. "a judge model that synthesizes their critiques into a unified reflection."
- LLMs: High-capacity LLMs capable of advanced reasoning and code generation. "LLMs have shown strong capabilities in reasoning and program synthesis"
- Mode Collapse: Repeatedly producing near-identical solutions across retries despite feedback. "mode collapse, where the Actor reproduces nearly identical solutions across retries despite receiving feedback"
- Multi-Agent Debate: Coordinated critique among multiple agents with diverse personas to reduce shared blind spots. "Multi-agent debate introduces structured disagreement and persona diversity, helping reduce shared blind spots;"
- Multi-Agent Reflexion (MAR): A multi-agent extension of Reflexion using diverse personas and a judge to generate better reflections. "we introduce Multi Agent Reflexion (MAR), a structured multi agent extension that incorporates diverse reasoning personas and a judge model that synthesizes their critiques into a unified reflection."
- Multi-hop Question Answering: Answering questions that require combining evidence across multiple steps or documents. "multi hop question answering"
- Pass@1: The fraction of problems solved by the first sampled solution passing all tests. "improves HumanEval pass@1 from 76.4 to 82.6"
- Persona: A role or reasoning style assigned to an agent to induce diverse critique patterns. "incorporates diverse reasoning personas"
- Program Synthesis: Automatically generating code that satisfies a given specification. "program synthesis"
- ReAct: A prompting method that interleaves reasoning tokens with actions in an environment. "ReAct extends this idea by interleaving reasoning tokens with actions"
- Reflexion: A framework where an agent self-reflects in natural language on failures to guide future attempts without parameter updates. "Reflexion wraps a LLM in a simple loop that turns past failures into natural-language guidance for future attempts."
- Reward Signal: Feedback used to optimize behavior, analogous to reinforcement learning updates. "analogous to how reinforcement learning algorithms use reward signals to update a policy"
- Sandboxed Environment: An isolated runtime used to safely execute and evaluate generated code. "when executed in a sandboxed environment."
- Scratchpad: The agent’s intermediate thoughts used for diagnosis and debate. "The failed thoughts (scratchpad) of the actor are passed to the judge."
- Self-Reflector: The component that converts failures into verbal feedback and strategies for retries. "When the Evaluator indicates failure, the Self-Reflection model converts this outcome into verbal feedback."
- Trajectory: The sequence of actions and reasoning generated during an attempt. "logging of trajectories and reflections."
- Verbal Rewards: Natural-language feedback serving as a lightweight optimization signal. "These ``verbal rewards'' play the role of a lightweight optimization signal."
Collections
Sign up for free to add this paper to one or more collections.

