- The paper introduces a novel reflection learning approach that iteratively enhances small LLM reasoning by self-training through generated reflections.
- It leverages a new dataset, ReflectEvo-460k, and employs both one-stage and two-stage supervised fine tuning alongside direct preference optimization for effective error correction.
- Experimental results show significant accuracy improvements, with Llama-3 performance increasing from 52.4% to 71.2%, indicating the approach's robust impact on model introspection.
ReflectEvo presents a pioneering framework aimed at enhancing the reasoning abilities of Small LLMs (SLMs) through an innovative process termed reflection learning. This approach iteratively generates self-reflection data for self-training, creating a continuous learning loop that fosters self-improvement without the need for superior models or extensive human annotations.
ReflectEvo Pipeline and Dataset
Generation Scheme
The ReflectEvo pipeline utilizes a novel dataset, ReflectEvo-460k, containing self-generated reflection samples derived from multiple domains. The key idea is to leverage SLMs to generate their reflections via self-training on these diverse tasks and instructions. This process is orchestrated in three steps:
- Instruction Collection: Designing specialized instructions tailored to three core stages of reflection: verifying initial reasoning, locating errors, and outlining correction strategies.
- Data Generation: Utilizing a base LLM as both a generator (G) to produce initial answers and a reflector (R) to refine these answers through self-generated reflection.
- Reflection Curation: Filtering and enhancing self-generated reflections by selecting those that led to correct solutions using GPT-4o for sophisticated annotation.
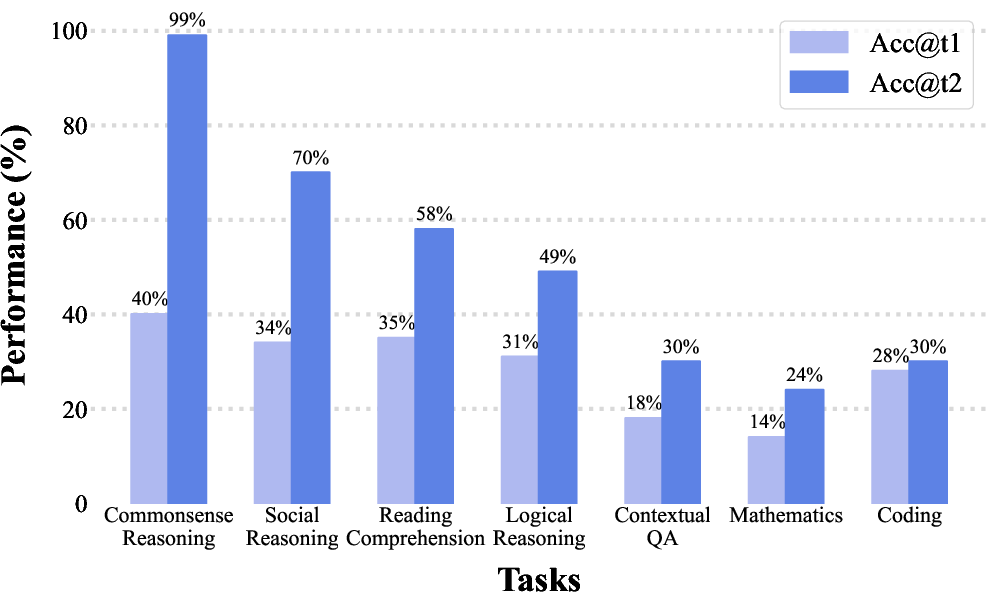
Figure 1: Performance training with ReflectEvo across different tasks on Llama-3-8B.
Dataset Statistics
The dataset spans 10 tasks and includes 460,000 reflection samples which encompass logical reasoning, mathematics, coding, contextual QA, and others. Extensive analysis shows that reflections meaningfully improve task performance by correcting identified errors, with significant gains observed in LLM accuracy.

Figure 2: Qualitative examples from the MATH. False to True'' and aFalse to False'' stand for successful and failed correction in the second turn respectively. The key snippets highlighted in green, red and yellow indicate correct, erroneous thought and reflection respectively.
Reflection Learning Methods
Reflection learning is achieved via two main approaches: Supervised Fine Tuning (SFT) and Direct Preference Optimization (DPO), carried out in different configurations:
- One-stage SFT where both self-reflection and correction are learned jointly.
- Two-stage SFT that separates the learning of self-reflection and self-correction.
The DPO method utilizes pairwise data to teach models to discern between high-quality and suboptimal reflections, applying preference learning for distinction.
Experimental Results
Experiments conducted with the ReflectEvo framework demonstrate marked improvements in accuracy from multiple model architectures, notably lifting the Llama-3 performance from 52.4% to 71.2% and Mistral’s from 44.4% to 71.1% on various benchmarks. ReflectEvo shows strong generalizability across tasks, outperforming three leading open-source models on the BIG-bench test suite, validating that self-reflection can rival or even surpass the efficacy of models trained with traditional distillation or human annotations.
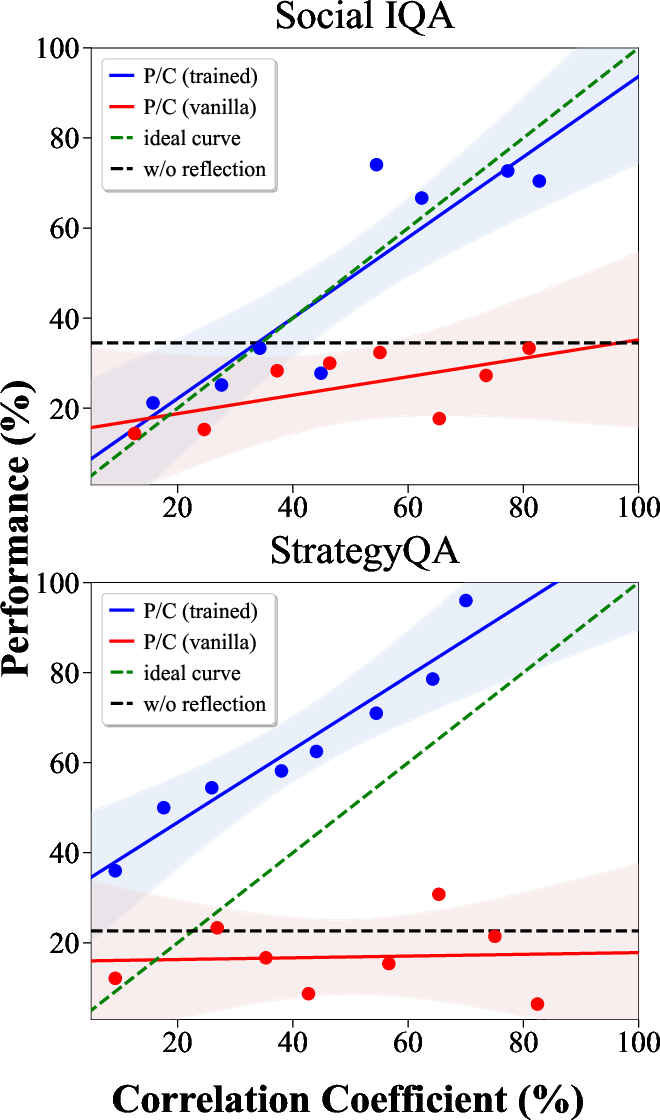
Figure 3: Task performance (Acc@t2) versus the correlation between reflection and the second-turn thought.
Error Type Analysis
Error analysis reveals that logical and reasoning errors are predominant, with significant portions attributed to mathematical or contextual misinterpretations. The pipeline's self-generated reflections effectively pinpoint these errors, suggesting robust potential for further enhancement of LLM reasoning capabilities.
Implications and Future Work
ReflectEvo offers substantial insights into SLM enhancement via self-reflection, proving that iterative learning from self-generated data opens new avenues for improving reasoning in LLMs. Future work might explore optimizing verifiers and integrating more sophisticated feedback mechanisms, particularly in complex domains like coding, where nuanced corrections are beneficial.
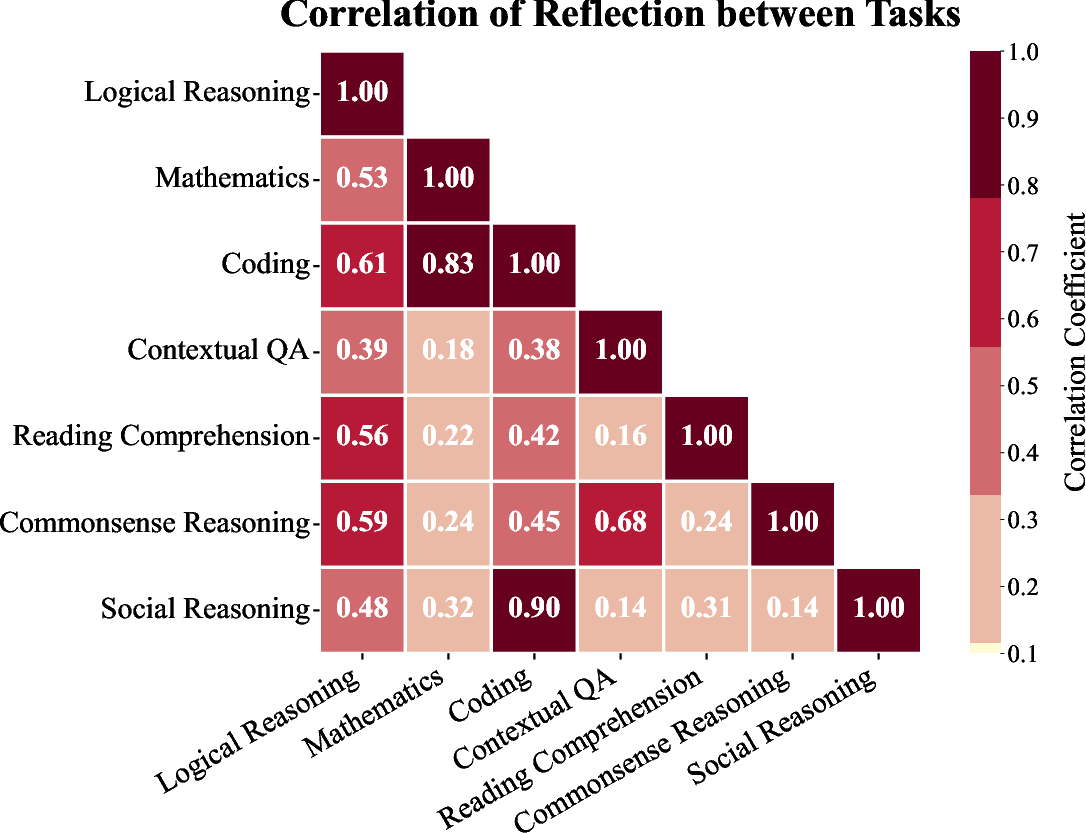
Figure 4: Correlation of reflection between each pair of tasks.
Conclusion
ReflectEvo establishes a sustainable and efficient approach for advancing SLM reasoning capabilities through reflection learning. This method not only elevates performance without extensive supervision but also sets the groundwork for future exploration into more autonomous, self-improving AI systems. The broad applicability and promising results underscore its potential as a critical tool in the ongoing development of more capable and intelligent LLMs.

