- The paper introduces DPSDP, a novel reinforcement learning algorithm that leverages multi-agent reflection to iteratively enhance LLM reasoning.
- It models the iterative refinement as an MDP with an actor-critic framework and applies direct preference learning using self-generated data.
- Empirical evaluations show significant accuracy improvements on in-distribution and out-of-distribution tasks, validated through majority voting over multiple refinements.
"Reinforce LLM Reasoning through Multi-Agent Reflection" (2506.08379)
Introduction
The paper proposes a novel reinforcement learning (RL) algorithm, DPSDP (Direct Policy Search by Dynamic Programming), to enhance the reasoning capabilities of LLMs by leveraging multi-agent collaboration. The approach models the iterative refinement process as a Markov Decision Process (MDP), allowing LLMs to dynamically improve their responses through preference learning based on self-generated data. The algorithm specifically targets limitations in existing paradigms, such as restricted feedback spaces and lack of coordinated training. Empirical results on various benchmarks demonstrate the algorithm's efficacy in improving in-distribution and out-of-distribution performance.
Methodology
DPSDP Framework
The proposed DPSDP algorithm is built upon the verify-and-improve paradigm but extends it by a training framework that models the multi-turn refinement process as an MDP. The MDP consists of states representing conversation history, actions corresponding to responses by the actor or critic, and a reward function encouraging correct answers. DPSDP employs a direct policy search approach facilitated by dynamic programming to iteratively optimize policy and leverage a KL-regularized objective.
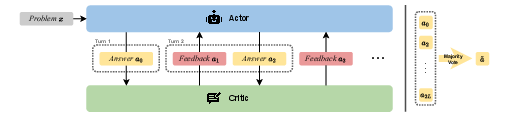
Figure 1: Inference time. Given a problem x, the actor generates an initial response a0. The critic then provides feedback a1, identifying potential errors in a0. The actor iteratively refines its response based on the feedback, continuing this process for L rounds. Finally, majority voting is applied to all generated answers to determine the final response a~.
The algorithm includes two main components:
- Iterative Refinement Process: Involving an actor-critic setup where the actor proposes an initial response and the critic offers feedback, prompting iterative improvements. This iterative process continues until a stopping criterion is met.
- Direct Preference Learning: Utilizing self-generated data, the algorithm performs preference learning to select actions that maximize expected return. This involves sampling various candidate responses and estimating their Q-values, then refining them based on the critic's feedback.
Theoretical Soundness
DPSDP's performance is capable of matching any policy within the training distribution under theoretical constraints such as single-policy concentrability and bounded in-distribution generalization error. The RL algorithm is designed to optimize horizon-fixed returns in a multi-agent framework effectively.
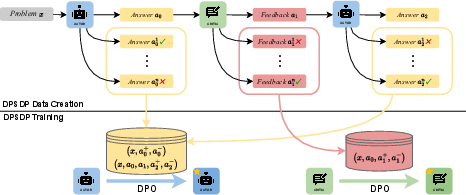
Figure 2: Model training. DPSDP first samples a complete trajectory τ=(x,a0,a1,a2) from the reference policy πref. At each state along this trajectory, it generates n responses to explore possible answers and feedback. Q-values of these n candidate responses are then estimated and used for DPO training.
Implementation Strategy
Algorithm Development
The DPSDP approach is divided into systematic stages: data collection, where model-generated responses are gathered; Q-value estimation, which predicts potential outcomes for candidate actions; and iterative refinement, wherein the model updates its policy based on dynamic programming.
Key considerations include using a reduced context for simplicity and generalization, leading to a compact model capable of handling a dynamic number of refinement turns at inference time.
Practical Considerations
In practice, DPSDP involves rolling out responses, estimating Q-values with the help of reference policy πref, and iterating through a policy preference optimization framework. Estimation accuracy and efficient implementation mechanisms are crucial for deploying DPSDP models effectively.
Empirical Evaluation
Extensive experiments highlight DPSDP's capacity to enhance LLM reasoning abilities, with experimental evaluations conducted across mathematical problem-solving tasks from benchmarks like MATH 500. Data indicates substantial performance uplift in reasoning accuracy, notably while adapting to unseen data, demonstrating its robustness. Specifically, in test cases, majority voting over multiple refinement steps significantly improved initial accuracy—a testament to DPSDP's iterative, feedback-informed learning process.
Conclusion
The introduction of DPSDP signifies progress in multi-agent collaboration for LLMs, directly addressing the bottlenecks of confined feedback loops and non-collaborative training in existing methods. While it brings theoretical advancements, it also excels practically by augmenting LLM reasoning proficiency across diverse applications. Future exploration may pivot towards adaptive, online training algorithms and refining policies to embody mixed generation objectives, maximizing transfer learning potential across reasoning and feedback tasks.

