- The paper’s main contribution is proposing a reflective reasoning framework that aligns LLM agents with their task goals, achieving a 93.3% success rate in ALFWorld.
- It implements a novel POMDP-based methodology that continually assesses internal belief states, reducing hallucinations and error compounding.
- Experimental results across environments show that ReflAct outperforms ReAct, with a 27.7% performance improvement and enhanced strategic reliability.
ReflAct: World-Grounded Decision Making in LLM Agents via Goal-State Reflection
Introduction
ReflAct is an innovative framework designed to improve decision-making in LLM agents by incorporating a reflective reasoning process. Unlike ReAct, which integrates Chain-of-Thought (CoT) prompting for immediate action, ReflAct emphasizes reflecting on the agent's state relative to its goal, thus providing a more coherent and goal-aligned internal context. This paper investigates the limitations of ReAct and proposes ReflAct as an alternative that ensures better strategic reliability in dynamic and partially observable environments.
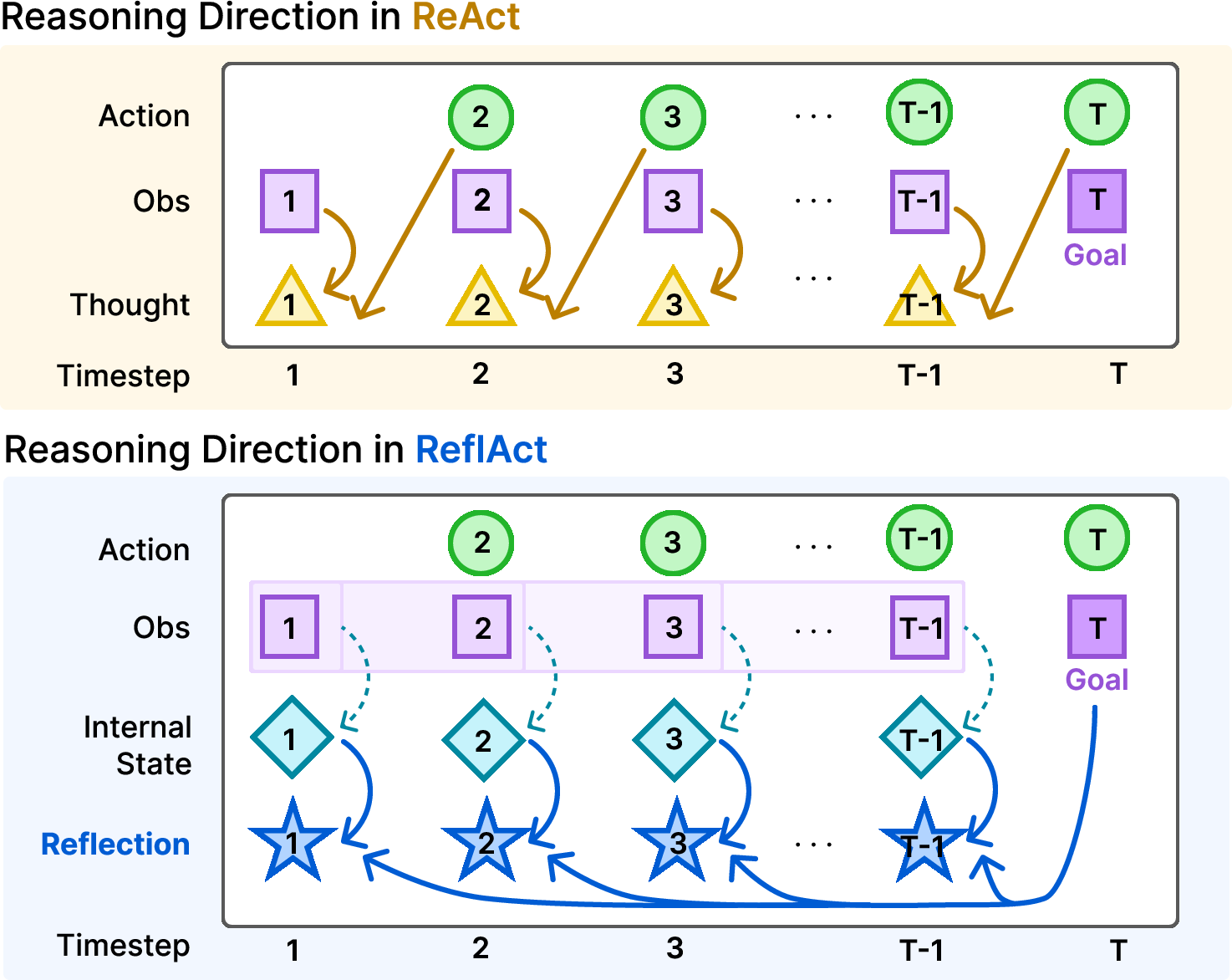
Figure 1: Comparison of reasoning influence in ReflAct and ReAct. While ReAct focuses on the current observation and the next action at each timestep, ReflAct reflects on the internal belief state and the task goal.
Methodology
ReflAct is implemented in a Partially Observable Markov Decision Process (POMDP) framework where decision-making is based on reflections rather than thoughts. Key to ReflAct is a structured reflection space that explicitly encodes both the internal belief state and task goal. The reflection step guides the agent's actions in a way that closely aligns with the overarching mission, minimizing the risk of compounding errors and hallucinations prevalent in ReAct.
The agent is instructed to generate reflections that assess its current state in relation to its goal at each timestep. This process enables the agent to detect potential deviations early and facilitates timely strategy adjustments, leading to more reliable decision-making across a variety of tasks.
Results
The empirical evaluation of ReflAct was conducted using open-source models like Llama-3.1 and proprietary models like GPT-4o, across ALFWorld, ScienceWorld, and Jericho environments. Notably, ReflAct achieved a remarkable 93.3% success rate in ALFWorld, outperforming ReAct by 27.7%. The reliability of ReflAct was demonstrated by its superior performance across various settings, highlighting its potential as a robust backbone for LLM agents.

Figure 2: A comparison of ReAct, ReflAct, and various verbalization strategies (state, goal, state+goal, and state+goal with next-action reasoning), using Llama-3.1-8B-Instruct as the agent model. Bars represent success rate; the red dashed line indicates average reward.
Discussion
ReflAct addresses key limitations in current LLM reasoning frameworks by refocusing on goal-driven reflection over immediate action planning. This grounding process reduces hallucination and enhances consistency, demonstrating clear advantages over ReAct and equivalent strategies. Besides, ReflAct's integration shows that revising the reasoning process is crucial for effective agent performance, especially in complex environments.
Additionally, the combination of ReflAct with enhancement modules like Reflexion and WKM further improves its efficacy, although the core design of ReflAct already inherently mitigates several failure modes intrinsic to other frameworks.
Conclusion
ReflAct offers a promising advancement in the field of LLM-based decision-making by centering reasoning on continuous goal-state reflections. This framework not only strengthens strategic reliability but also reduces the computational cost per decision compared to prediction-heavy methods. Future research may extend ReflAct's applicability to diverse domains, such as mathematics and programming, by adapting its reflection mechanism to better align the current state with domain-specific objectives.

