- The paper presents ReMA, a framework that decouples meta-thinking and reasoning processes using multi-agent reinforcement learning to enhance LLM performance.
- It leverages a high-level agent for strategic oversight and a low-level agent for executing detailed reasoning steps, improving adaptation through collaborative learning.
- Experiments on mathematical and reasoning benchmarks show that ReMA outperforms single-agent RL methods, generalizing better to previously unseen challenges.
The paper "ReMA: Learning to Meta-think for LLMs with Multi-Agent Reinforcement Learning" introduces a novel framework, ReMA, which leverages multi-agent reinforcement learning (MARL) to develop metacognitive capabilities in LLMs. This is achieved by decoupling the reasoning process into separate high-level and low-level agents, optimizing both to enhance reasoning efficiency and adaptability.
Introduction
ReMA addresses the inherent limitations in traditional single-agent reinforcement learning (SARL) approaches used for metacognition in LLMs by introducing a multi-agent system. In this system, the high-level agent focuses on strategic oversight, generating meta-thinking instructions, while the low-level agent executes specific reasoning steps based on these instructions. This separation facilitates more effective exploration and role-specific learning during training.
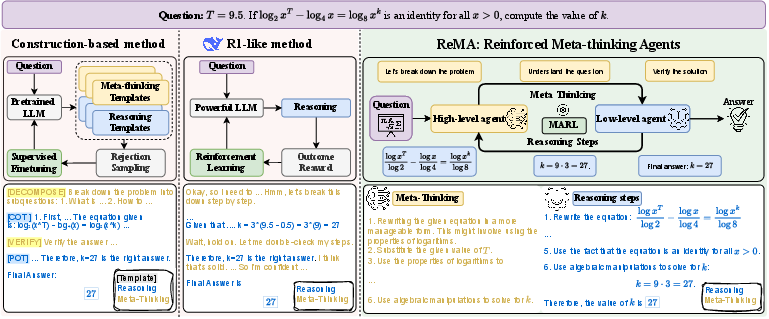
Figure 1: Left: A construction-based method that fine-tunes LLMs using rejection sampling, searching among combinations of pre-defined templates. Middle: RL-from-base method learns to mix meta-thinking and detailed solution steps during training. Right: Our method ReMA separates the meta-thinking and reasoning steps in a multi-agent system, allowing the agents to explore efficiently and learn to collaborate.
Methodology
ReMA frames the problem as a multi-agent policy optimization challenge where two interconnected agents collaboratively work to improve reasoning performance. The high-level agent generates metacognitive instructions, and the low-level agent aims to execute these plans effectively. This iterative learning process is facilitated by a reward mechanism refined through iterative policy optimization cycles, enhancing both agents' abilities to adapt and collaborate effectively.
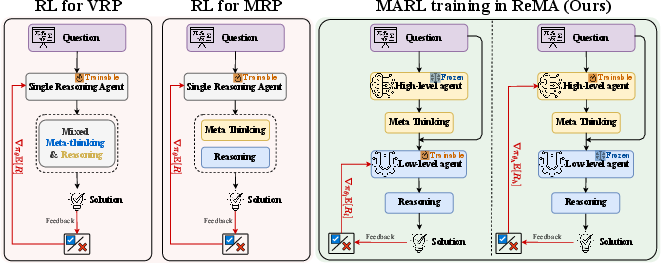
Figure 2: Comparison of Training Pipelines. Left: RL training of VRP and MRP. Right: MARL training in ReMA: the high-level agent is frozen while the low-level agent is trained using generated meta-thinking, execution results, and rewards. The low-level agent is frozen while the high-level agent is trained. This cycle repeats iteratively.
Experiments and Results
Experiments were conducted on complex reasoning benchmarks, including mathematical reasoning tasks and LLM-as-a-Judge evaluations, spanning in-distribution and out-of-distribution datasets. ReMA consistently outperformed single-agent and standard RL approaches, particularly in generalizing to harder, unseen problems.
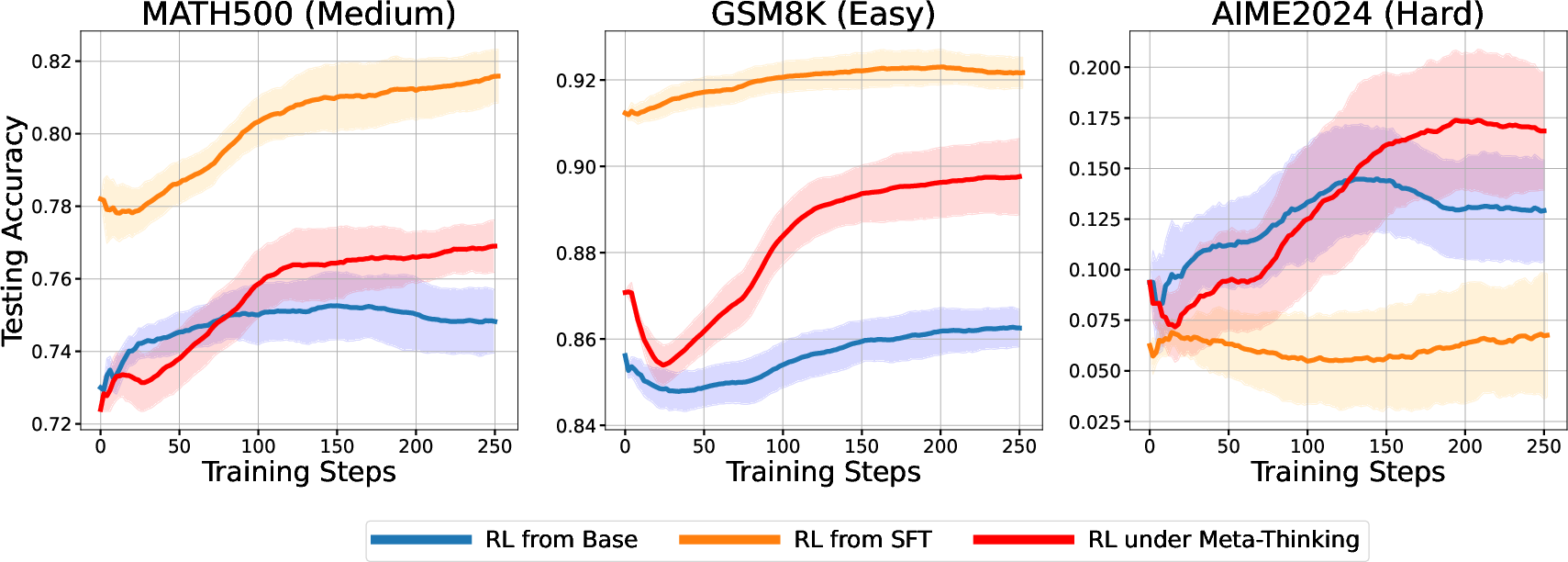
Figure 3: An RL experiment evaluates the performance of Qwen2.5-Math-7B on the MATH500, GSM8K, and AIME24 datasets after training on Level 3-5 MATH questions using different methods. RL from SFT achieves superior performance but struggles to generalize to more challenging problems. In contrast, RL from Base and RL under Meta-thinking demonstrate the ability to solve previously unseen, harder problems, with the latter further enhancing performance.
Analysis and Interpretability
An in-depth analysis of metacognitive strategies revealed that models capable of executing complex metacognitive actions can solve more challenging problems. The evolution of metacognition in high-scale LLMs indicated significant improvements in dynamic adjustment capabilities and reasoning accuracy.
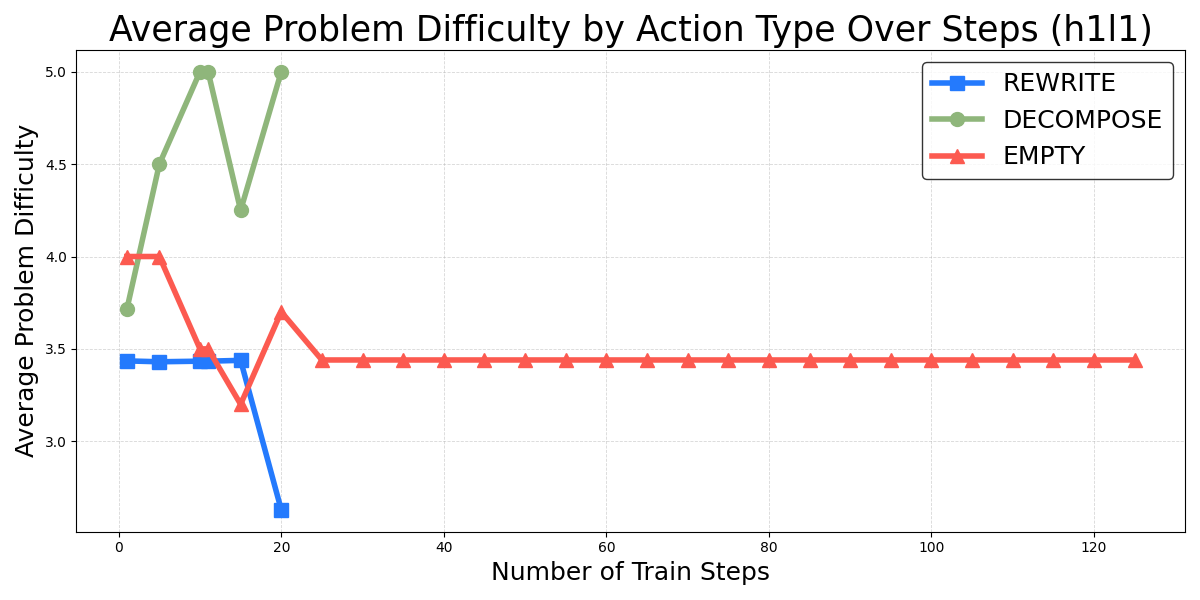
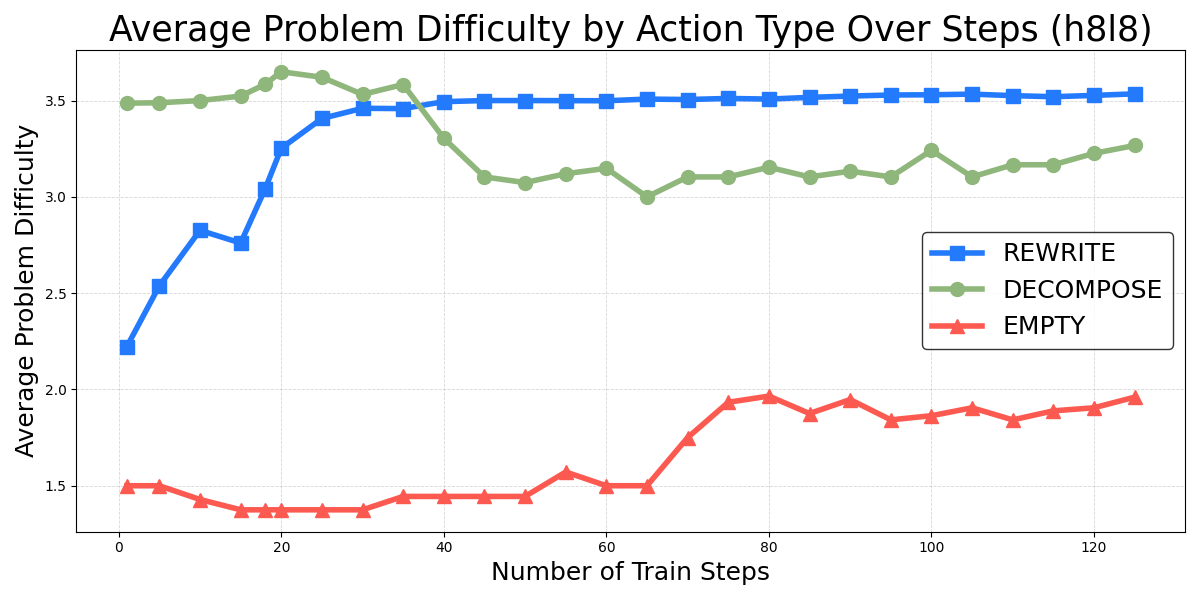
Figure 4: Average problem difficulty of three predefined metacognitive actions during training. Left: After approximately 20 training steps, the 1B LM's outputs collapse to the simplest action, EMPTY, resulting in no data points for "REWRITE" and "DECOMPOSE" in the plot. Right: In contrast, the 8B LM learns to utilize more complex metacognitive actions for solving difficult problems.
Conclusion
ReMA represents a significant advancement in developing metacognitive capabilities in LLMs through the innovative use of MARL. By structurally separating meta-thinking from reasoning, ReMA not only enhances learning dynamics but also facilitates better generalization, adaptability, and robustness in complex problem-solving tasks. Its implications for improving reasoning abilities across diverse AI applications signal a promising direction for future research in LLM development and deployment.

