Enhancing LLM Reasoning with Multi-Path Collaborative Reactive and Reflection agents
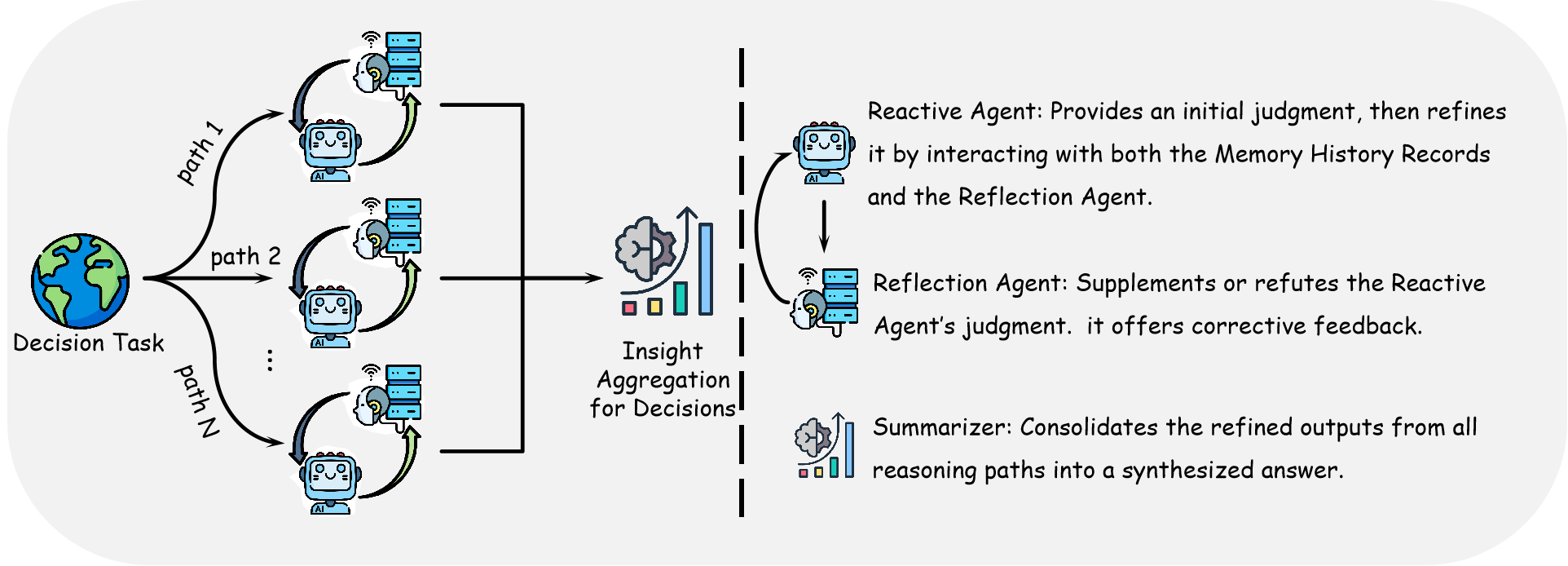
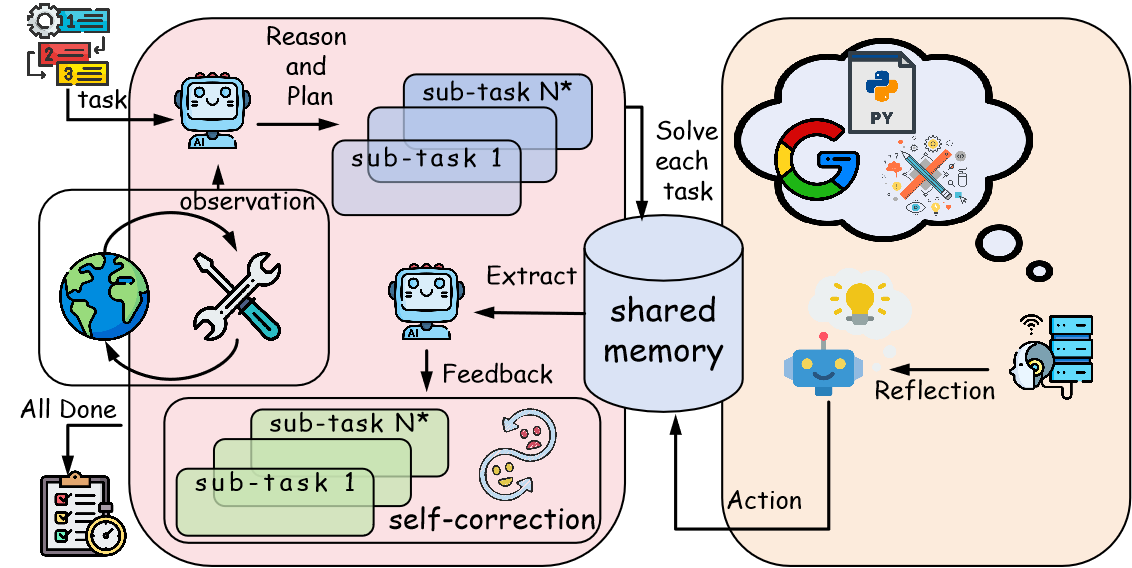
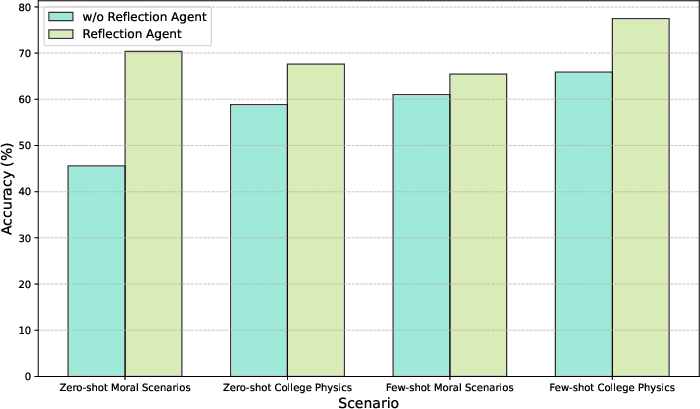
Abstract: Agents have demonstrated their potential in scientific reasoning tasks through LLMs. However, they often face challenges such as insufficient accuracy and degeneration of thought when handling complex reasoning tasks, which impede their performance. To overcome these issues, we propose the Reactive and Reflection agents with Multi-Path Reasoning (RR-MP) Framework, aimed at enhancing the reasoning capabilities of LLMs. Our approach improves scientific reasoning accuracy by employing a multi-path reasoning mechanism where each path consists of a reactive agent and a reflection agent that collaborate to prevent degeneration of thought inherent in single-agent reliance. Additionally, the RR-MP framework does not require additional training; it utilizes multiple dialogue instances for each reasoning path and a separate summarizer to consolidate insights from all paths. This design integrates diverse perspectives and strengthens reasoning across each path. We conducted zero-shot and few-shot evaluations on tasks involving moral scenarios, college-level physics, and mathematics. Experimental results demonstrate that our method outperforms baseline approaches, highlighting the effectiveness and advantages of the RR-MP framework in managing complex scientific reasoning tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and opportunities for future research identified from the paper.
- Compute-matching and fairness: The RR-MP framework uses more LM calls (multiple paths, reflection steps, summarizer) than baselines, but no compute-matched comparisons (equal number of tokens, calls, or wall-clock budget) were reported. How much of the gain remains under strict compute parity with self-consistency or other ensemble methods?
- Missing statistical rigor: No confidence intervals, significance tests, or variance across runs are reported. How robust are results to different random seeds, temperatures, and sampling parameters?
- Unspecified hyperparameters and prompts: Critical details (number of paths, number of reflection iterations, temperatures, stop criteria, exact prompts, sampler settings, summarizer configuration) are not fully documented, limiting reproducibility.
- Path count scaling laws: The paper does not study how performance scales with the number of reasoning paths (beyond a binary single vs multiple). What is the marginal gain per additional path, and where are diminishing returns?
- Iteration depth and stopping: The number of reflection steps, termination criteria, and early-stopping policies are not analyzed. How do depth and stopping rules affect accuracy, cost, and stability?
- Aggregation/summarization mechanism: The “separate summarizer” that consolidates paths is under-specified. Which aggregation strategies (e.g., majority vote, confidence-weighted voting, verifier-guided selection, learned rankers) work best under equal budgets?
- Theory–practice gap: The theoretical analysis assumes i.i.d. samples, consistency, and uses product-form utilities and Chebyshev bounds, but practical paths are correlated (same base model, similar prompts). How does correlation across paths affect the claimed error bounds and asymptotic benefits?
- Notation and assumptions in theory: The formalization includes unclear notation and strong assumptions (e.g., independence, utility consistency). A refined proof that explicitly models correlated paths and aggregator behavior is needed.
- Measuring DoT and hallucination directly: The work claims mitigation but provides no operational metrics for Degeneration-of-Thought, hallucination rates, or diversity of reasoning traces. What measurable indicators best capture DoT reduction?
- Diversity quantification: No metrics assess diversity across paths (e.g., semantic distance of rationales, step novelty). Which prompt/role designs maximize useful diversity without introducing noise?
- Role/prompt engineering dependence: Performance depends on hand-crafted roles and examples. How can roles, prompts, and examples be automatically discovered or adapted (e.g., via programmatic prompt search, meta-controllers, or reinforcement learning)?
- Dynamic role and path allocation: Agents/roles are fixed a priori. Can a controller dynamically select roles, allocate path budgets, and prune unpromising paths based on intermediate signals?
- Shared memory at scale: The shared memory is list-based and not evaluated under long-context limits or many paths. What retrieval strategy, memory compression, and relevance filtering are needed to avoid context overflow and interference?
- Tool and retrieval integration: The paper mentions tools/external knowledge, but experiments do not include tool-augmented reasoning. How much additional benefit arises from calculators, symbolic solvers, retrieval, and verifiers within RR-MP?
- Generalization beyond MMLU MCQ: Evaluations are limited to MMLU subsets with multiple-choice answers. Does RR-MP transfer to open-ended generation, proofs, coding, multi-hop QA, or real-world sequential tasks?
- Model generality: Only GPT-3.5-turbo-0613 is tested. How does the framework perform across stronger closed models (e.g., GPT-4 class), open-source LLMs, and smaller models where reflection may matter more?
- Multilingual and cross-cultural robustness: Moral scenarios are culturally sensitive. How does RR-MP behave across languages and cultural contexts, and does multi-agent collaboration amplify or mitigate biases?
- Safety and bias: No analysis of failure modes where multi-agent debate/collaboration amplifies harmful content or spurious agreement. What mitigation (e.g., safety filters, dissent injection, red-teaming agents) is needed?
- Adversarial robustness: The framework is not tested against prompt attacks, misleading paths, or adversarial reflection. How vulnerable is RR-MP to cooperative failure or collusion?
- Cost, latency, and energy: There is no systematic evaluation of token usage, latency, or monetary/energy cost. What are the cost–accuracy trade-offs, and can adaptive budgeting maintain gains at lower cost?
- Failure analysis: The paper lacks qualitative error taxonomies and path-level analyses (e.g., when collaboration helps vs hurts, when debate helps). What failure patterns persist, and how can they be targeted?
- Baseline breadth: Comparisons exclude strong modern multi-agent and verifier-based baselines (e.g., formal debate frameworks with verifiers, tool-verified self-consistency, AutoGen-like orchestrations). How does RR-MP fare against these under matched budgets?
- Debates vs collaboration mechanisms: The paper reports aggregate trends but not mechanism-level reasons (e.g., when debate induces productive dissent vs cognitive rigidity). Can one predict the better mode per task instance?
- Aggregator reliability when minority is correct: The method claims to recover from majority errors, but lacks a principled confidence calibration or verifier to prefer a correct minority. How can the aggregator reliably choose minority-correct answers?
- Contamination risk: Using MMLU with GPT-3.5 may involve data leakage. Are gains preserved on held-out, freshly collected, or contamination-controlled benchmarks?
- Termination and convergence guarantees: There is no guarantee that iterative reflection converges to a better solution. Under what conditions does RR-MP converge or avoid oscillations?
- Topology comparisons: Linear, network, and hierarchical interactions are introduced, but their configurations and budgets are not fully standardized. How do different topologies compare under equal compute and with ablated components?
- Ethical deployment in moral tasks: No discussion of governance or human oversight when multi-agent systems produce moral judgments. What interfaces and safeguards are needed for responsible use?
Collections
Sign up for free to add this paper to one or more collections.