Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Abstract: Modern LLMs like ChatGPT have shown remarkable performance on general language tasks but still struggle on complex reasoning tasks, which drives the research on cognitive behaviors of LLMs to explore human-like problem-solving strategies. Along this direction, one representative strategy is self-reflection, which asks an LLM to refine the solution with the feedback generated by itself iteratively. However, our study shows that such reflection-style methods suffer from the Degeneration-of-Thought (DoT) problem: once the LLM has established confidence in its solutions, it is unable to generate novel thoughts later through reflection even if its initial stance is incorrect. To address the DoT problem, we propose a Multi-Agent Debate (MAD) framework, in which multiple agents express their arguments in the state of "tit for tat" and a judge manages the debate process to obtain a final solution. Clearly, our MAD framework encourages divergent thinking in LLMs which would be helpful for tasks that require deep levels of contemplation. Experiment results on two challenging datasets, commonsense machine translation and counter-intuitive arithmetic reasoning, demonstrate the effectiveness of our MAD framework. Extensive analyses suggest that the adaptive break of debate and the modest level of "tit for tat" state are required for MAD to obtain good performance. Moreover, we find that LLMs might not be a fair judge if different LLMs are used for agents. Code is available at https://github.com/Skytliang/Multi-Agents-Debate.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at how LLMs like ChatGPT think through complicated problems. The authors notice that these models can get “stuck” on a wrong idea once they feel confident about it. To fix that, they introduce a new way to make LLMs think more broadly: set up a debate between multiple AI “agents,” with a judge that manages the discussion and decides when to stop and what the final answer is. They call this approach Multi-Agent Debate (MAD).
The main questions the paper asks
- Why do LLMs sometimes fail to change their mind even when they’re wrong?
- Can a debate between multiple AI agents help them consider new ideas and avoid getting stuck?
- How should this debate be organized to work best?
- Does MAD actually improve results on tricky tasks compared to other methods?
How the researchers approached the problem
Think of a classroom scenario:
- One student presents an answer (this is like “self-reflection,” where the same student reviews their own work over and over).
- But if that student gets overconfident, they might stop looking for better ideas and just defend the original answer.
- Instead, the teacher invites two students to debate. They take turns arguing for different viewpoints (“tit for tat” means each side responds to the other’s points), while a teacher acts as a judge to keep things fair, stop the debate when a good answer appears, and write down the final solution.
That’s the MAD framework:
- Two AI debaters argue their cases in rounds.
- A judge (also an AI) monitors the debate:
- In “discriminative mode,” the judge decides whether a correct solution has been found and can stop the debate early (adaptive break).
- In “extractive mode,” if the debate reaches its round limit, the judge picks the best final answer from the discussion.
Key idea explained in everyday terms:
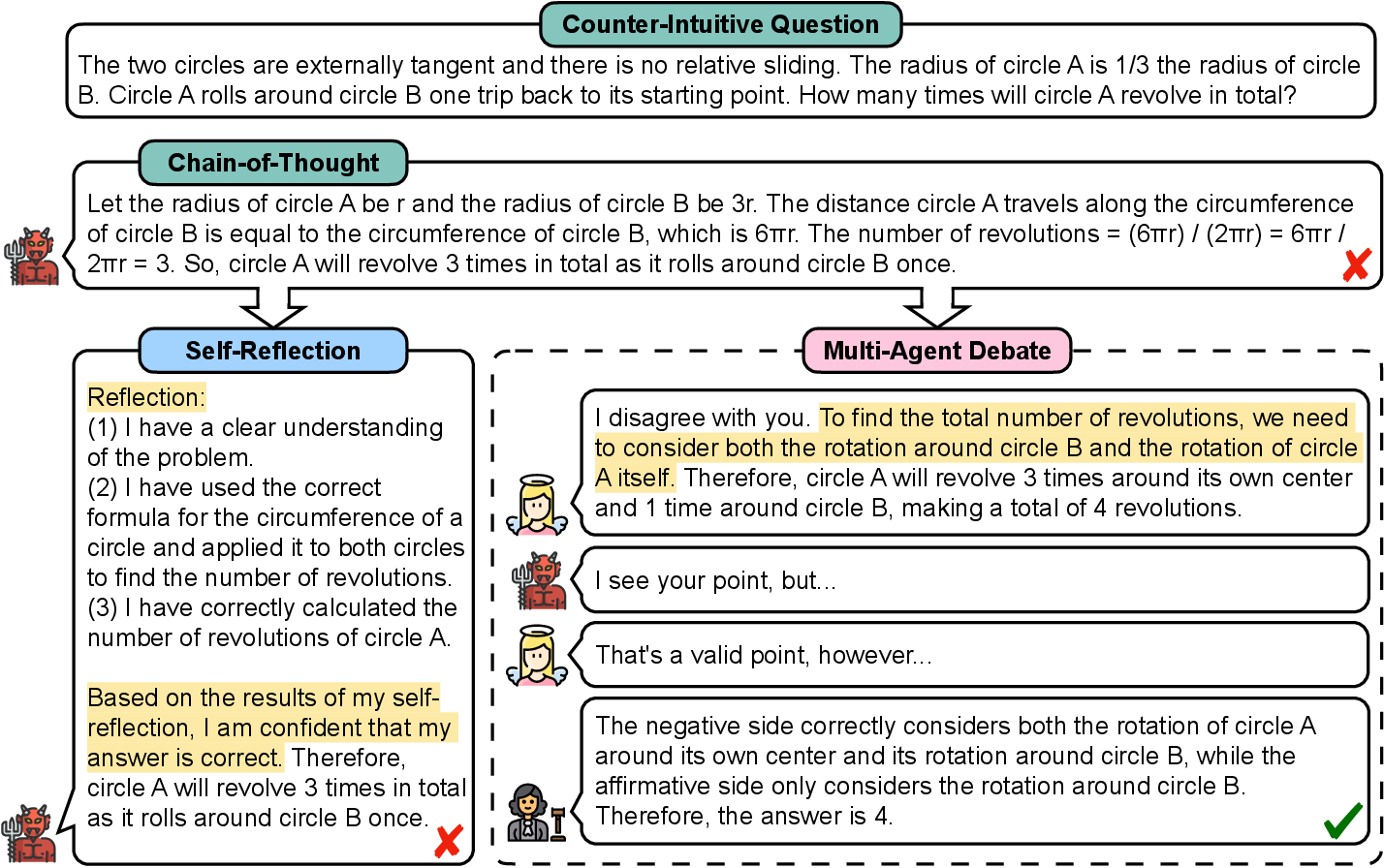
- Degeneration of Thought (DoT): Once the AI feels sure about an answer, it struggles to come up with new ideas later—even if the first answer was wrong. It’s like stubbornly sticking to your first guess in a puzzle.
- MAD fights DoT by having multiple agents challenge each other’s thinking, bringing in “external feedback” that the single thinker lacked.
What tasks they tested:
- Commonsense Machine Translation (Chinese to English): Sentences with tricky words that need context, not literal translation. Example: “吃掉敌人一个师” should be “destroy a division of the enemy,” not “eat up an enemy division.”
- Counter-Intuitive Arithmetic Reasoning: Math word problems that try to trick your intuition. Example: Average speed up and down a hill isn’t the simple average of 1 and 3; the correct average is 1.5 m/s because you have to consider total distance and total time.
How they evaluated results:
- Translation quality with automatic scores (COMET, BLEURT) and human ratings.
- Math with accuracy (percentage of correct answers).
- They compared MAD against:
- Basic GPT-3.5 and GPT-4
- Self-Reflection (the model revises its own answer)
- Chain-of-Thought (CoT): “Let’s think step by step”
- Self-Consistency: Try multiple solutions and vote
- Other translation strategies like Reranking and MAPS (analyze then translate)
What they found and why it matters
Here are the most important takeaways, explained simply:
- MAD encourages “divergent thinking”: It produces new, different lines of thought instead of repeating the same ones. This helps avoid DoT (getting stuck).
- MAD improved performance on both tasks:
- On the translation task, GPT-3.5 with MAD beat GPT-4 on several measures, including human evaluation and accuracy at resolving tricky word meanings.
- On the counter-intuitive math problems, GPT-3.5’s accuracy improved from 20% to 36% with MAD (GPT-4 scored 52%).
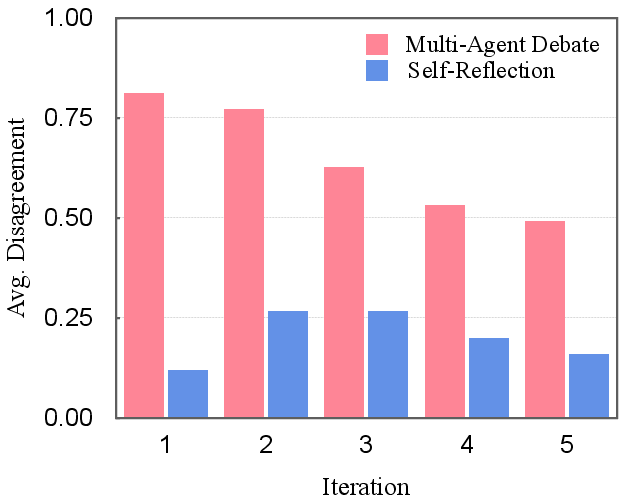
- Self-Reflection often didn’t help: When the model had already formed a strong opinion, it tended to defend it rather than rethink.
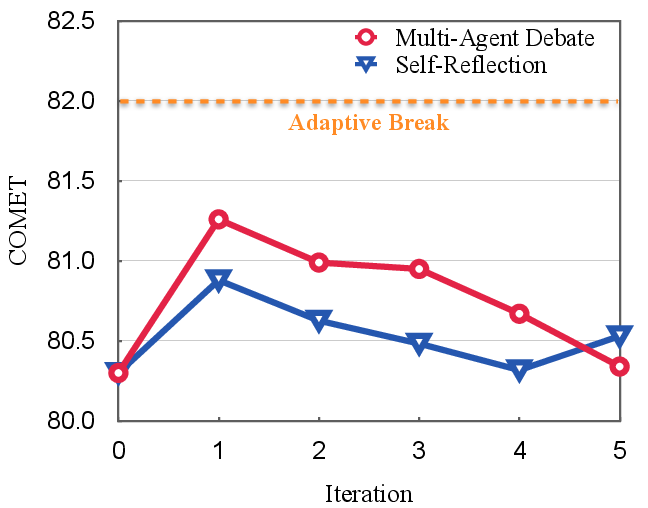
- Stopping at the right time matters: Letting the judge end the debate as soon as a good answer appears (adaptive break) worked better than forcing more rounds.
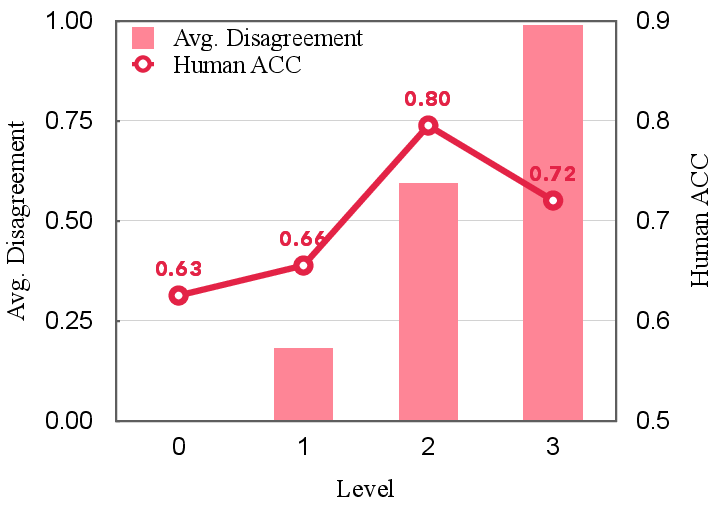
- The best debate style is “modest disagreement”: Asking debaters to consistently challenge each other helps, but demanding they disagree on every single point can lead to endless arguing without progress.
- Judges can be biased: If the judge is built from one model and the debaters are different models, the judge may favor the agent most similar to itself. That’s a fairness concern.
Examples that show the difference:
- Translation: MAD changed “eat up an enemy division” to “eliminate/destroy a division of the enemy” by recognizing military context.
- Math: MAD correctly used average speed = total distance ÷ total time, rather than the misleading “average of speeds,” and got 1.5 m/s.
What this means for the future
- Multi-agent debate is a promising way to make AI think more carefully about hard problems, especially those that trick your gut instincts.
- It could help in areas like translation, math word problems, planning, and decision-making where context and multi-step reasoning are essential.
- Designers of AI systems should include:
- A way for agents to challenge each other constructively.
- An adaptive judge that knows when to stop the debate.
- Awareness that judges can be biased and need careful setup.
- Future ideas include adding more agents, using debate for board games or simulations, and improving AI feedback to make judgments fairer and more reliable.
In short, the paper shows that having AIs debate—like students in a well-run classroom—can lead to better, more thoughtful answers than having a single AI review its own work.
Collections
Sign up for free to add this paper to one or more collections.

