- The paper introduces VERM, a GPT-4o-driven framework that optimizes virtual viewpoint selection to enhance 3D robotic manipulation efficiency and accuracy.
- It integrates classic robotics pipelines with a dynamic coarse-to-fine module to deliver precise action predictions using a single, optimized image input.
- Real-world and simulation experiments demonstrate state-of-the-art performance, achieving faster training/inference and robust task success with minimal demonstrations.
VERM: Leveraging Foundation Models for Virtual Viewpoint Selection in 3D Robotic Manipulation
Introduction
Vision-based 3D robotic manipulation relies critically on perceptual representations that capture all task-relevant spatial information while minimizing irrelevant redundancy and occlusion. Traditional paradigms employ multi-camera, large-scale RGB-D fusion or manually selected virtual camera planes, but these approaches introduce excess computational burden and either rely on costly human expertise or fail to generalize across diverse tasks. The VERM (Virtual Eye for Robotic Manipulation) framework melds spatial reasoning capabilities of large multimodal foundation models, specifically GPT-4o, with classic robotic pipeline components to create a language-driven, plug-and-play system for task-adaptive virtual viewpoint generation and efficient manipulation policy learning.
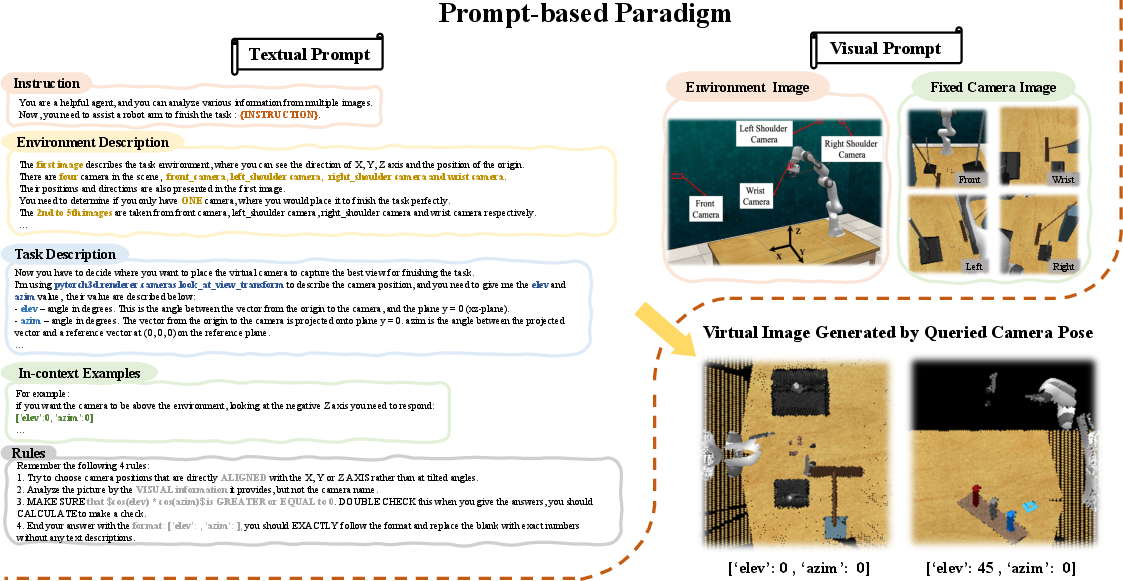
Figure 1: The prompt-based paradigm for querying virtual camera poses using GPT-4o, combining context-aware structured language-visual input for viewpoint generation.
Methodology
Prompt-based Virtual View Selection
VERM introduces a structured prompt system to recontextualize GPT-4o as a spatial reasoning agent for camera pose selection. The paradigm merges environment state (camera placements, axes, and workspace SoM visualizations), task descriptions, in-context view labeling, and formalized selection rules. This text-visual abstraction enables GPT-4o to output grounded virtual camera parameters (elev, azim) optimized for both capturing salient manipulation cues and minimizing occlusion, as shown in Figure 1.
Crucially, this replaces hand-crafted or heuristic view selection with a single, dynamic, model-driven step, eliminating redundant background and revealing occluded, task-relevant geometric details, as compared to prior RVT and PerAct approaches.
Policy Network and Action Generation
Following viewpoint selection, the original multi-camera RGB-D streams are projected into a 3D point cloud, then re-rendered as a single orthographic image at the virtual viewpoint. The policy network, visualized in Figure 2, conditions on this rendered image, robot proprioception, and textual instructions to predict 8-DOF end-effector actions. This includes 3D positional (with learnable depth tokens), 3D rotational (via discretized bins), gripper (open/close), and collision awareness components.
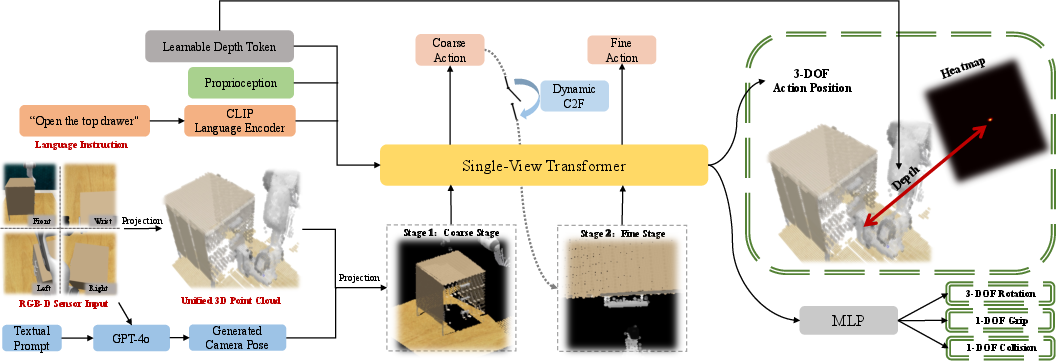
Figure 2: Policy network of the proposed VERM, integrating language, proprioception, and single-view visual features for unified action prediction.
Dynamic Coarse-to-Fine Inference
VERM addresses precision requirements by introducing a dynamic coarse-to-fine (C2F) module. Rather than applying refinement at every step—leading to inefficiency—the system utilizes a learned indicator to trigger refinement only during task-critical phases, such as object insertion or precise placement. Zoom-ins are realized by adaptive re-centering and rescaling in the observation point cloud while preserving camera orientation.
The pipeline thus achieves efficient policy execution, rapidly training and inferring with single-image input while preserving fine-grained accuracy.
Experimental Results
RLBench Benchmark
On the RLBench simulation suite, VERM demonstrates both computational and functional superiority. It achieves a 1.89× reduction in training time and 1.54× improvement in inference speed relative to RVT-2, the most competitive published baseline using the same hardware resources.
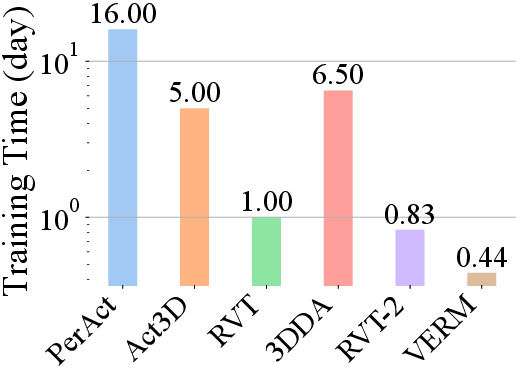
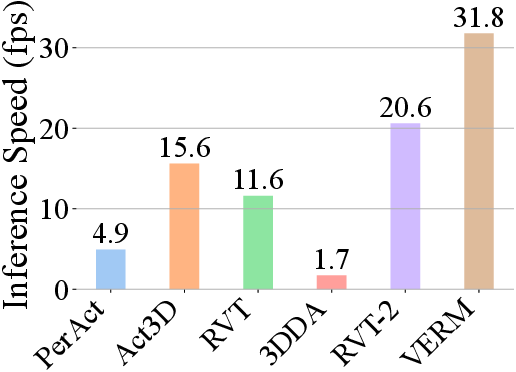
Figure 3: Left: Training time (day) in log scale detailing efficiency gains. Right: Inference speed (fps) demonstrating real-time policy viability.
In terms of task success rate, VERM marginally but consistently outperforms RVT-2 (83.6% vs 82.2% average across 17 tasks), and dominates in 11 out of 17 scenarios, setting new state-of-the-art marks for single-image input architectures.
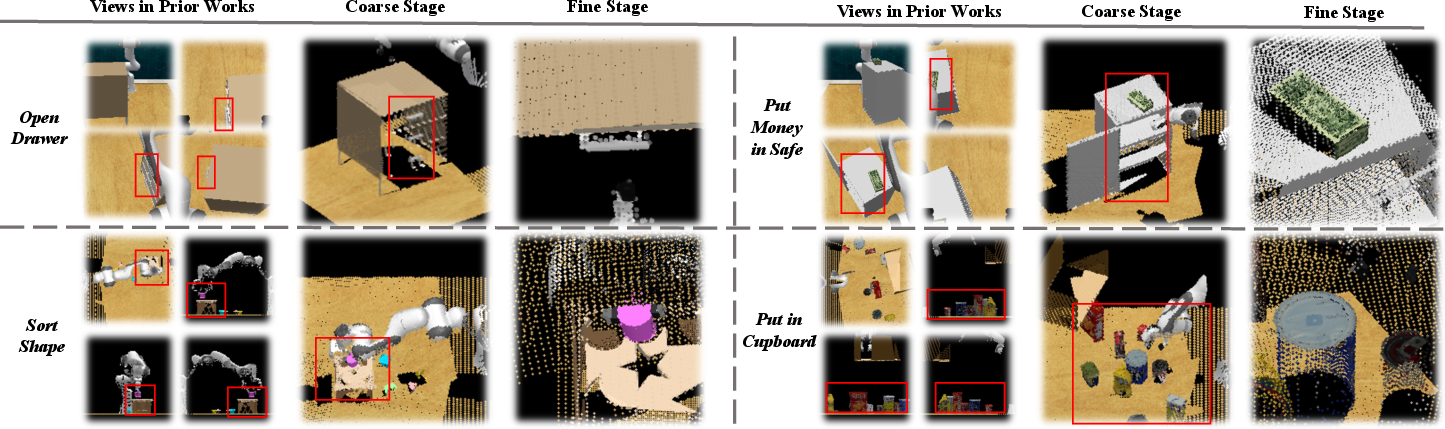
Figure 4: Visualization of action prediction of VERM in RLBench, highlighting effective view selection and precise action generation.
Real-World Evaluation
The real-world Franka Panda experimental platform further validates the practical data-efficiency and generalization of VERM. With only 15 demonstrations, VERM surpasses both RVT and RVT-2 in average success rate; at 100 demonstrations, it achieves near-saturation performance (80%) across eight manipulation tasks, confirming robustness to domain shift, sensor noise, and limited supervision.

Figure 5: Visualization of action prediction of VERM in real-world manipulation tasks, exhibiting robust policy transfer and viewpoint generalization.
Ablation and Generalization Studies
Ablation analysis confirms that the GPT-4o-driven view selection decisively outperforms all fixed-view baselines. The global view adapts fluidly to occlusions and multi-object scenarios where pre-selected camera planes fail. The dynamic C2F module and axis-alignment constraints both contribute significantly to final accuracy. Importantly, generalization trials using Qwen2.5 and Claude 3.5 Sonnet show only minor performance declines (80.3% and 81.2% vs 83.6%), establishing the view selection pipeline as agnostic and plug-and-play for capable foundation models.
Failure Analysis
Primary limitations arise in tasks where no single viewpoint can resolve all relevant spatial relationships (e.g., simultaneous visibility of both an object and a target receptacle with mutual occlusion). One-shot camera selection also leads to missed cues in extended, multi-stage tasks. While a dynamic re-querying strategy mitigates some of these issues, it currently introduces additional computational cost.

Figure 6: Example failure cases, illustrating limitations in expressing non-trivial task geometry or adapting to unforeseen occlusions mid-episode.
Implications and Future Directions
This work represents a formal utilization of foundation models for spatial reasoning over language and multimodal perceptual input in embodied robotics. By encapsulating all multi-camera context into a single, task-optimized observation, VERM achieves both theoretical advances in perception efficiency and practical gains in policy performance and deployability.
Potential future directions include:
(1) Dynamic, time-dependent view selection via continual prompting and history integration,
(2) Extension to contact-rich, deformable, or high-DOF dexterous manipulation settings,
(3) Use of open-vocabulary, unsupervised view selection for zero-shot transfer into entirely novel manipulation domains.
Conclusion
VERM redefines the 3D robotic manipulation pipeline by leveraging the latent spatial reasoning of foundation models for virtual camera selection, achieving state-of-the-art accuracy, data efficiency, and real-time compatibility while rendering prior multi-camera fusion architectures obsolete. Its high generality and empirical performance lay the groundwork for next-generation, foundation-model-centered robotic perception and control systems.

