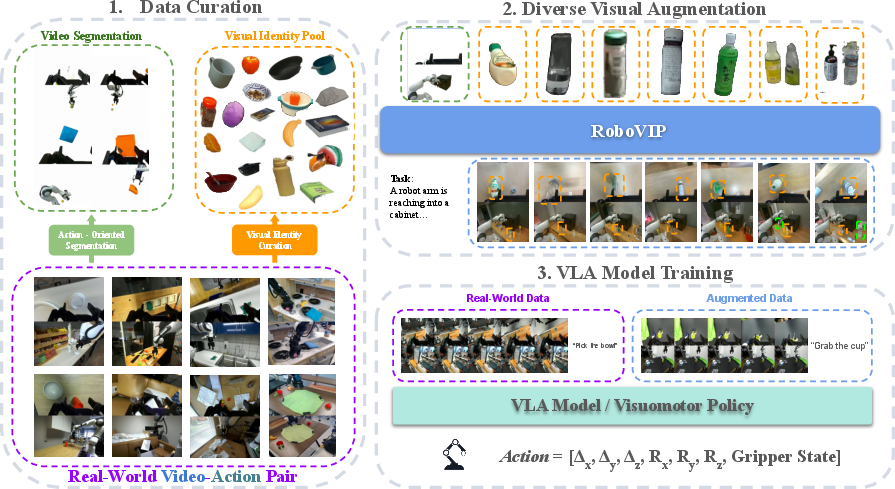
RoboVIP: Multi-View Video Generation with Visual Identity Prompting Augments Robot Manipulation
Abstract: The diversity, quantity, and quality of manipulation data are critical for training effective robot policies. However, due to hardware and physical setup constraints, collecting large-scale real-world manipulation data remains difficult to scale across diverse environments. Recent work uses text-prompt conditioned image diffusion models to augment manipulation data by altering the backgrounds and tabletop objects in the visual observations. However, these approaches often overlook the practical need for multi-view and temporally coherent observations required by state-of-the-art policy models. Further, text prompts alone cannot reliably specify the scene setup. To provide the diffusion model with explicit visual guidance, we introduce visual identity prompting, which supplies exemplar images as conditioning inputs to guide the generation of the desired scene setup. To this end, we also build a scalable pipeline to curate a visual identity pool from large robotics datasets. Using our augmented manipulation data to train downstream vision-language-action and visuomotor policy models yields consistent performance gains in both simulation and real-robot settings.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
Robots learn to do tasks (like picking up objects) by watching lots of videos and matching those videos to the actions they should take. But gathering big, varied, high-quality robot videos in real life is slow and expensive. This paper introduces RoboVIP, a tool that can automatically create new, realistic, multi-camera videos from existing robot recordings. It changes only the scene (like the table and background) while keeping the robot and its actions the same. The goal is to give robots more diverse, time-consistent training data so they perform better in real and simulated environments.
What questions does the paper try to answer?
- How can we quickly create lots of varied, high-quality robot training videos without filming everything in the real world?
- How do we make these videos work across multiple camera angles and stay believable over time (not just single pictures)?
- How can we guide video generation beyond vague text prompts like “a messy desk” so the scene looks specific and realistic?
- Does training robots with these generated videos actually improve their success in tasks?
How does RoboVIP work?
Think of RoboVIP as a smart video editor and scene designer that keeps the robot’s actions untouched but creatively changes the surroundings. Here’s the approach, explained with everyday terms:
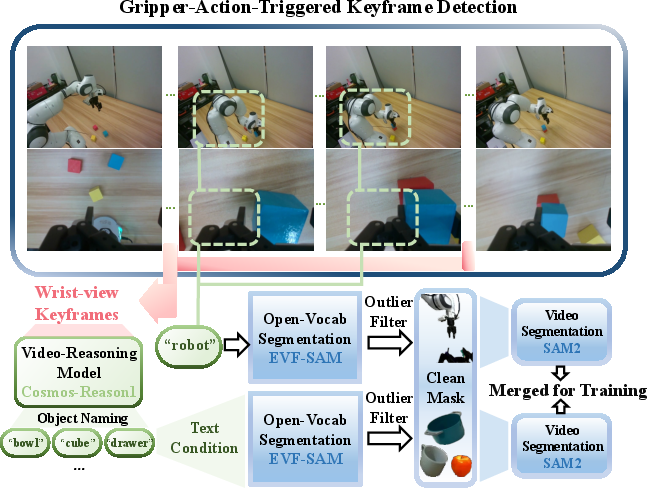
- Step 1: Find and keep the important parts (the robot and the object it’s interacting with).
- The system looks at the robot’s gripper signal (when the claw opens/closes) to pinpoint the moments when the robot is really manipulating an object.
- It uses AI tools to identify and track both the robot and the target object across frames and camera views.
- These areas are “protected” so they won’t be altered.
- Step 2: Fill in and redesign everything else (the background and tabletop).
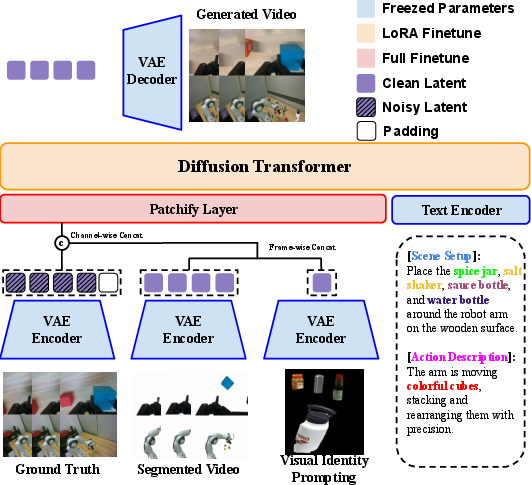
- Inpainting: Imagine parts of the video are blanked out except the robot and object. RoboVIP fills in those blank areas with new, realistic content.
- Multi-view and temporal consistency: The system works with several camera angles at once and makes sure each frame smoothly connects to the next, like a movie rather than a random set of photos.
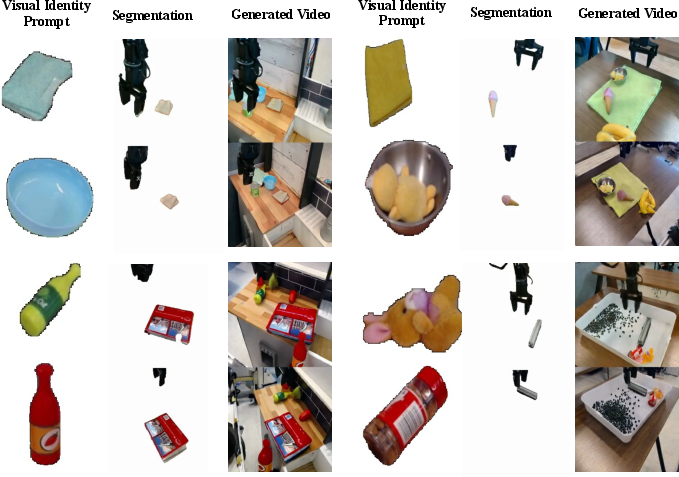
- Step 3: Give the system “visual identities” to copy from (not just text).
- Visual identity prompting: Instead of just telling the model “make a kitchen scene,” it shows the model example pictures of specific objects (like plates, cups, plants) pulled from huge robot datasets.
- The model uses these example images as a guide to place believable items on the table or in the background—with the right look and details.
- Step 4: Use a powerful video generator, fine-tuned efficiently.
- Diffusion model: Think of “diffusion” as adding grainy noise to a video and then teaching the model to remove the noise step by step until a clean, realistic video appears.
- LoRA: A small “add-on” that teaches the big model new skills without retraining everything from scratch, saving time and memory.
- The model is trained to take in masked multi-view videos, text descriptions, and identity images, and then generate complete, consistent multi-camera video clips.
- Step 5: Train robot policies on the original actions plus the new videos.
- The robot action labels (what the robot did) are reused from the original data.
- The new videos give the robot more varied visual experiences while its learned actions stay aligned.
What did they find?
Here are the main results, explained simply:
- Better video quality and consistency:
- Compared to other methods that edit single images or rely only on edges/depth, RoboVIP produced videos that looked more realistic frame-by-frame and stayed consistent across multiple views.
- It scored better on common video quality tests that measure how natural and stable videos look over time.
- Improved robot performance in simulation:
- Two popular robot models (Octo and π₀) were trained with RoboVIP-augmented data.
- In a variety of simulated tasks (like placing items or stacking cubes), success rates went up. For example:
- Octo’s overall success improved compared to both using no extra training and fine-tuning only on real data.
- π₀ reached about 29% overall success with RoboVIP’s text-only videos, beating a standard fine-tune baseline (~17%) and other augmentation methods.
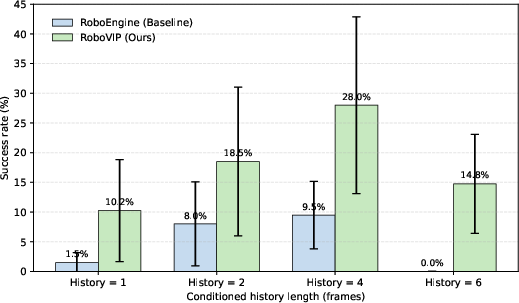
- Using visual identity prompting (example images) helped the models handle more clutter and object diversity.
- Strong results on a real robot:
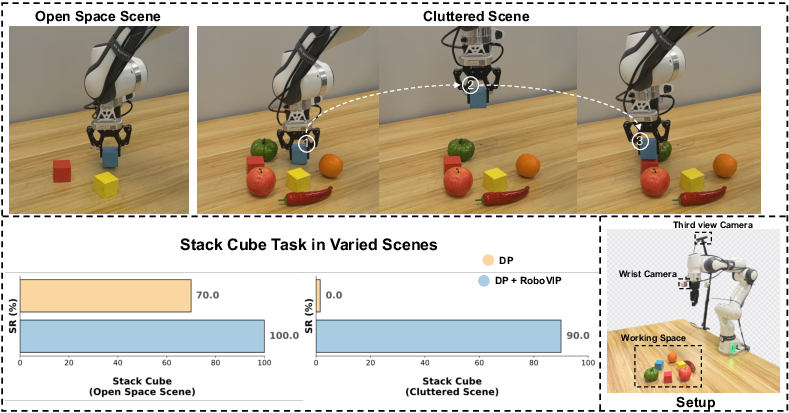
- In a real cube-stacking task with a 7-DoF arm, the basic policy struggled in a cluttered scene (0/10 success).
- The policy trained with RoboVIP data stayed robust (9/10 success) even with distractor objects around.
- This shows the augmented videos teach robots to ignore background noise and focus on the task.
Why is this important?
- Scales robot training without endless filming: Instead of setting up lots of new physical scenes, teams can generate realistic, multi-view, time-consistent videos from existing recordings.
- Makes robots more robust to real-world messiness: By adding believable clutter and varied backgrounds, robots learn not to get confused by extra objects.
- Matches modern robot models: Today’s best policies often need multiple camera views and longer video histories. RoboVIP is designed for that.
- Practical gains: The paper shows consistent improvements in both simulation and real hardware—meaning this isn’t just a cool demo; it actually helps robots succeed.
Final thoughts and future impact
RoboVIP brings a “plug-and-play” way to create rich, realistic training videos for robots using example images and smart video generation. This can speed up research, reduce the cost of data collection, and help robots perform better in messy, real-world environments. While current tools for object tracking and captioning aren’t perfect and can sometimes make mistakes, the overall approach points toward a future where high-quality, multi-view, time-stable video augmentation becomes a standard part of training strong robot policies.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address:
- Multi-view geometric consistency: Despite improvements, the paper acknowledges that none of the methods (including RoboVIP) achieve true multi-view consistent generation. How can camera calibration, epipolar constraints, or explicit 3D scene priors (e.g., NeRF/SDF, multi-plane images) be integrated to enforce cross-view geometry and depth consistency?
- 3D-aware supervision: The current training treats multi-view via vertical stitching without using intrinsics/extrinsics. Would adding calibrated multi-view supervision, multiview photometric consistency, or differentiable rendering improve spatial alignment across views?
- Physical plausibility under action reuse: The approach reuses original actions after inpainting new backgrounds/objects. What fraction of augmented frames introduce action-scene mismatches (e.g., added obstacles, altered affordances) that violate the original kinematics? Can automatic physics checks or affordance validators filter out implausible augmentations?
- Long-horizon temporal coherence: Training and generation are limited to ≤49 frames. How does performance scale for long-horizon tasks that require hundreds of frames, multiple subgoals, or persistent memory?
- Non-grasp interactions: The action-guided segmentation relies heavily on gripper-state changes. How does the pipeline generalize to tasks with no gripper closure (push, turn, slide, wipe), multiple interaction phases, or soft-contact/continuous interactions where gripper signals are uninformative?
- Robustness of the segmentation pipeline: The paper notes failures in VLM object naming, open-vocabulary segmentation, and SAM2 flicker. What is the quantitative error rate per module and cumulative failure rate? How do segmentation errors propagate to policy performance?
- Multi-object interactions and occlusions: The pipeline segments a single “interacted object.” How does the system handle simultaneous interactions with multiple objects, severe occlusions, thin/transparent/reflective objects, deformables, or tool use?
- Identity prompting selection strategy: Visual identities are sampled randomly from a large pool. When do identity prompts help versus hurt (e.g., the Text-only variant sometimes outperforms Text+ID)? Can learned or task-aware identity selection (or curriculum over clutter) yield better policies?
- Identity pool quality and bias: The pool is curated from Bridge/DROID via panoptic segmentation and CLIP scoring. What biases (category, texture, color, size) are present? Is there semantic or visual leakage between training/evaluation splits? How does deduplication or domain diversification affect outcomes?
- View-ambiguity in identity prompting: To avoid cross-view ambiguity, identities are sampled from a single view during training. Can multi-view-consistent identity conditioning be designed (e.g., 3D identity anchors or cross-view canonicalization) to reduce ambiguity while leveraging all views?
- Metrics for multi-view alignment: MV-Match counts feature correspondences, but does not verify metric correctness or reprojected consistency. Can stronger metrics (e.g., calibrated epipolar errors, cross-view PnP reprojection, multi-view depth consistency) better capture true geometric alignment?
- Language grounding after augmentation: Videos are re-captioned before augmentation, but the augmented scenes might diverge from captions or instructions. What is the mismatch rate between post-augmentation visuals and language? Can closed-loop instruction validation or LLM-based consistency checks ensure language-visual-action alignment?
- Distribution shift control: Identity prompting increases clutter and distractors, but the optimal difficulty schedule is unknown. What curricula over clutter level, object semantics, or background complexity maximize policy gains without inducing overfit to synthetic artifacts?
- Failure mode analysis: Which augmentation patterns most often cause downstream failures (e.g., occluders placed near the target, high-frequency textures, repeated patterns that confuse keypoint extractors)? Can generative constraints prevent such patterns?
- Camera egomotion and rolling shutter: Wrist-camera motion is challenging. How robust is generation to fast egomotion, motion blur, rolling shutter artifacts, or abrupt viewpoint changes? Can motion-aware conditioning (optical flow, gyroscope) improve temporal stability?
- Cross-robot and cross-sensor generalization: Results are shown on WidowX in SimplerEnv and a Franka FR3 real robot. How does augmentation transfer across different robot morphologies, grippers, lens models, resolutions, fisheye/depth cameras, and lighting conditions?
- Simulation gap: SimplerEnv only supports single-view inputs, limiting evaluation of the multi-view benefits emphasized by RoboVIP. Can a multi-view simulation benchmark (with calibrated cameras and synchronized streams) be built to systematically test cross-view consistency and policy gains?
- Scalability and compute constraints: Training used very large-memory GPUs (e.g., 144 GB per GPU) and a 14B-parameter backbone with LoRA. What is the minimal compute footprint (via distillation, parameter-efficient adapters, pruning, or smaller backbones) that preserves policy benefits?
- High-resolution generation: The model operates at 256×256 (Bridge) or 320×416 (Droid) per view, below the 720p pretraining regime after stitching. How do higher resolutions impact temporal stability, multi-view consistency, and downstream policy performance?
- Action-label fidelity audits: There is no reported audit of how often augmented frames inadvertently change the target’s pose, size, or contact state relative to the preserved actions. Can automated pose trackers verify label fidelity post-augmentation?
- Ablations on conditioning: The paper briefly notes patchification fine-tuning helps. A deeper ablation is missing on text vs. identity vs. masks vs. number of identities, LoRA rank/placement, temporal injection schedules, and vertical-stitch vs. alternative multi-view encodings.
- Comparison breadth: Baselines exclude 3D sim-to-real augmentation, CAD-based scene composition, or controllable video generation with explicit geometry. How does RoboVIP compare against 3D-aware or physics-grounded augmentation pipelines?
- Generalization to diverse materials: Transparent, glossy, metallic, deformable, and thin objects often break segmentation and generation. Can material-aware augmentations or relighting models improve realism and policy robustness on these challenging categories?
- Safety and spurious correlations: Augmented data could introduce shortcuts (e.g., specific colors/textures correlating with actions). Are there diagnostics to detect spurious correlations and interventions (e.g., counterfactual augmentations) to mitigate them?
- Identity injection at inference: Identity tokens are injected at each diffusion timestep. Does this create training–inference drift or stability issues at different sampler settings? What is the optimal injection schedule or noise-conditioning strategy?
- Multi-interaction episodes: Many tasks involve multiple sequential interactions with different objects. How would the action-guided segmentation, naming, and identity conditioning scale to multi-target, branching, or partially observed task graphs?
- Data release and reproducibility: The paper references a homepage, but it’s unclear whether the identity pool, segmentation annotations, and trained LoRA weights are released. Without these, reproducibility and fair comparison remain difficult.
- Evaluation under sensor noise: Real-world deployments face sensor noise, exposure changes, HDR scenes, and lens contamination. How robust is RoboVIP-augmented training to these factors compared to traditional domain randomization?
- Policy transfer to language-rich tasks: VLAs rely on nuanced language grounding (negation, spatial prepositions). Does identity prompting help or hinder language-sensitive control? Dedicated evaluations on instruction sensitivity are missing.
- Ethical/data-governance concerns: Large-scale curation from public datasets raises questions about license compliance and potential sensitive content. Is the identity curation pipeline auditable for licensing, privacy, and harmful content filtering?
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now, leveraging the paper’s methods (multi-view inpainting video diffusion, visual identity prompting, action-guided segmentation) and validated improvements on Octo, π₀, and Diffusion Policy in both simulation and real robots.
- Robust visual data augmentation for robot manipulation training — Robotics, Manufacturing, Logistics, Retail automation
- Use case: Expand and diversify training data for pick-and-place, stacking, kitting, bin-picking, and light assembly using existing multi-view logs to improve robustness to clutter and background changes.
- Tools/products/workflows: “RoboVIP Data Augmenter” service integrated into policy training stacks (Octo, π₀, Diffusion Policy), with automated action-guided segmentation and multi-view video generation; identity-prompt packs per customer environment (SKUs, fixtures).
- Assumptions/dependencies: Multi-camera recordings or at least one camera; access to segmentation/VLM backbones (SAM2, EVF-SAM, Qwen2.5-VL); GPU capacity for LoRA fine-tuning/inference; licensing of base generative model.
- Rapid adaptation to new SKUs or workcells with minimal demos — Manufacturing, 3PL/warehouses
- Use case: Fine-tune existing policies to new products or layouts by augmenting 50–200 demo episodes into thousands of visually diverse, multi-view sequences reflecting new packaging, labels, bins, and backgrounds.
- Tools/products/workflows: SKU-driven visual identity prompt packs curated via panoptic segmentation; MLOps pipeline that ingests new demo logs, generates augmented episodes, retrains, and validates.
- Assumptions/dependencies: Visual identity pool must include representative SKU appearances; grasped object masks must be accurate to avoid physically implausible edits.
- Stress testing and QA of robot policies via controlled visual perturbations — Robotics, Software/MLOps
- Use case: Create standardized test suites with controlled distractors/clutter to detect regressions in robustness (e.g., background color, texture, object decoys) before deployment.
- Tools/products/workflows: “CI for Policies” that auto-generates multi-view stress scenarios using identity prompts; regression dashboards tracking grasp/put success across visual shifts.
- Assumptions/dependencies: Policy must support multi-frame or single-frame conditioning consistent with training; correctness of segmentation to preserve robot/object pixels.
- Privacy-preserving dataset sharing — Robotics vendors, Integrators, Academia
- Use case: Replace sensitive lab or factory backgrounds while preserving task semantics to enable cross-partner data sharing and collaborative model training.
- Tools/products/workflows: Background inpainting with identity prompting to produce synthetic-but-faithful scenes; automated redaction pipelines for multi-view recordings.
- Assumptions/dependencies: Inpainting must avoid altering interacted objects or robot geometry; alignment to privacy/legal constraints.
- Bootstrapping low-data training in small labs and education — Education, Maker communities
- Use case: Train reasonable policies from ~100 demos by expanding to diverse multi-view datasets, improving generalization to clutter (validated with Franka cube stacking, 9/10 success under clutter).
- Tools/products/workflows: “RoboVIP Lite” with default identity pools; tutorials for ROS/MoveIt and student-friendly training presets for Octo/π₀/DP.
- Assumptions/dependencies: At least one camera stream; moderate GPU access; acceptance of prebuilt identity pools if curation resources are limited.
- Simulation domain randomization upgrade with photoreal video augmentation — Simulation/Digital twins, Software
- Use case: Replace uniform domain randomization with identity-prompted, multi-view, temporally consistent augmentation that better matches real distribution shifts.
- Tools/products/workflows: Plug-in for SimplerEnv/Isaac Sim/Unity-based pipelines that generates multi-view video sequences to train or evaluate policies.
- Assumptions/dependencies: Alignment between sim camera rigs and real multi-view setups; current frame-length limits (≈49 frames) for many VLA stacks.
- Dataset curation and enrichment for open-source communities — Academia, Open data initiatives
- Use case: Construct and share vetted visual identity pools (tabletop and background elements) and augmented sequences to standardize multi-view benchmarks.
- Tools/products/workflows: Scripts for panoptic segmentation-based identity curation with quality filters (CLIP score, sharpness, resolution); community identity packs per domain (kitchen, warehouse).
- Assumptions/dependencies: Licensing clarity for identity assets; reproducibility of curation heuristics across datasets.
- Visual regression testing for HRI interfaces and signage recognition — Human–robot interaction, Facilities
- Use case: Validate robustness to signage, UI panels, and safety markers by injecting identity-prompted variants across multi-view histories (e.g., different button panels or indicator lights).
- Tools/products/workflows: Identity packs for common control panels; QA suites that couple gripper-state windows to focus edits near interaction.
- Assumptions/dependencies: Accurate action-guided temporal localization to avoid corrupting causal cues (pre/post-interaction frames).
Long-Term Applications
These applications likely require additional research, scaling, or productization (e.g., longer horizons, lower compute, stronger tool reliability, standardized benchmarks).
- Scalable training of generalist robot policies with synthetic–real co-training — Robotics, Manufacturing, Consumer robots
- Use case: Train foundation VLA/visuomotor models at scale by mixing millions of augmented, multi-view, identity-rich sequences with real data across sites and vendors.
- Tools/products/workflows: “RoboVIP Studio” SaaS with identity marketplace per industry; auto-curated, deduplicated identity pools; curriculum schedulers for clutter difficulty.
- Assumptions/dependencies: Improved segmentation/VLM reliability; cost-effective multi-GPU/accelerator inference; long-horizon sequence support.
- Certification-grade robustness benchmarks for procurement and regulation — Policy, Standards bodies, Enterprise governance
- Use case: Standardize visual robustness tests (clutter, lighting, novel objects) as part of safety/certification for general-purpose robots and co-bots.
- Tools/products/workflows: Public benchmark suites with identity class taxonomies; audit trails tying identity prompts to pass/fail metrics; procurement RFP templates referencing these benchmarks.
- Assumptions/dependencies: Industry consensus on protocols; versioning/governance of identity pools; public hosting and reproducibility guarantees.
- Digital twin orchestration with synthetic video-in-the-loop — Software, Industrial IoT
- Use case: Couple physics simulators with identity-prompted video generation to synthesize camera streams for plant-wide validation, orchestrating multi-robot and multi-view policies.
- Tools/products/workflows: Hybrid pipelines linking CAD + sim + video diffusion; automated camera rig calibration; streaming interfaces to policy learners/testers.
- Assumptions/dependencies: Tight synchronization between sim states and generated frames; fast, stable video generation at plant scale.
- Cross-domain adoption for specialized robotics — Healthcare, Agriculture, Inspection/maintenance
- Use case: Data augmentation for sterile environments (hospitals), crop variability (agriculture), or reflective/complex backgrounds (inspection), where real data collection is scarce or sensitive.
- Tools/products/workflows: Domain-specific identity packs (surgical tools, crops, turbines); safety-aware edit constraints (no changes near critical anatomy/targets).
- Assumptions/dependencies: High-fidelity segmentation of delicate tools/targets; stricter compliance and validation; expert-in-the-loop review.
- Data privacy and compliance infrastructure via synthetic redaction — Enterprise data platforms
- Use case: Enable cross-site, cross-vendor model training by anonymizing proprietary environments with identity-consistent inpainting while preserving manipulation semantics and multi-view consistency.
- Tools/products/workflows: Policy-driven redaction pipelines; “shareable twin” data products; audit logs showing protected regions and edits.
- Assumptions/dependencies: Clear privacy policies; measurable guarantees that edits do not degrade task-relevant cues.
- Continual-learning CI/CD with automatic drift surveillance — MLOps for robotics
- Use case: Detect visual distribution shifts in production and auto-generate targeted augmentations (new fixtures, seasonal packaging) to retrain and redeploy policies.
- Tools/products/workflows: Drift detectors feeding identity curation; closed-loop training pipelines; gated rollout with robustness gates.
- Assumptions/dependencies: Reliable shift detection; careful monitoring to avoid catastrophic forgetting; governance over synthetic-real data balance.
- Multimodal identity prompting beyond vision — Software, AR/VR, Media production
- Use case: Multi-camera, temporally coherent editing for film/AR with identity references (props, textures) to maintain continuity across angles; synthetic data for multi-camera perception models.
- Tools/products/workflows: Editors that pack multiple identity references; shot-level continuity validators; plugins for NLE/DCC tools.
- Assumptions/dependencies: Extension to higher resolutions and longer shots; rights management for identity assets; consistent color/lighting across views.
- Knowledge transfer via student–teacher compression — Edge robotics
- Use case: Use augmented multi-view datasets to train compact student policies that retain robustness for edge deployment (AMRs, cobots).
- Tools/products/workflows: Distillation pipelines where teachers train on augmented corpora; automated selection of identity prompts that maximize student generalization.
- Assumptions/dependencies: Effective distillation recipes; on-device inference constraints; careful curation to avoid shortcut learning.
Notes on Key Dependencies and Risks
- Tool reliability: The pipeline depends on VLM captioning, panoptic/open-vocabulary segmentation, and video object tracking; errors can propagate. The action-guided gripper cue mitigates but does not eliminate failures.
- Compute and latency: Training/inference with large I2V models and multi-view sequences is GPU-intensive; LoRA helps but productionization may require model distillation or accelerators.
- Temporal and view constraints: Many current VLA stacks accept short histories (≈49 frames) and may use limited views; long-horizon and more cameras will need further model development.
- Identity pool bias: Pools curated from Bridge/DROID may under-represent certain environments (e.g., heavy industry); domain-specific expansion and quality filters are necessary.
- Physical plausibility and safety: Inpainting must not alter interacted objects or robot kinematics; downstream validation in the loop (sim and real) remains essential.
Glossary
- Agentic curation: An automated, self-directed pipeline that selects and filters data at scale without human intervention. "agentic curation and filtering pipeline"
- Cartesian end-effector delta pose: The 6-DoF change in a robot’s tool/gripper position and orientation expressed in Cartesian coordinates. "6-DoF Cartesian end-effector delta pose"
- Causal VAE encoder: A variational autoencoder encoder with causal (time-aware) structure used to turn frames into latents for diffusion. "shared causal VAE encoder"
- Channel-wise concatenation: Combining tensors by stacking along the channel dimension to feed multi-condition inputs into a model. "channel-wise concatenation of the full video sequence"
- CLIP-based text–image scoring: Using CLIP embeddings to measure semantic alignment between a label/text and an image. "CLIP-based textâimage scoring"
- Cross-view spatial consistency: Agreement of generated content across multiple camera views in geometry and appearance. "cross-view spatial consistency and correspondence"
- Diffusion Transformer: A Transformer-based backbone used in diffusion models to generate images or videos. "Diffusion Transformer"
- End-effector: The robot’s tool or gripper that interacts with objects. "end-effector state"
- Frame-wise concatenation: Concatenating inputs along the temporal frame dimension to condition generation. "frame-wise concatenation strategy"
- Fréchet Inception Distance (FID): A metric comparing distributions of generated and real images using Inception features. "Fréchet Inception Distance"
- Fréchet Video Distance (FVD): A video-level metric comparing distributions of generated and real videos using spatiotemporal features. "Fréchet Video Distance"
- Inpainting: Synthesizing content to fill masked regions of an image or video. "inpainting-based video diffusion model"
- K-means sampling: Selecting representative points via K-means clustering, e.g., to seed mask tracking. "k-means sampling on the masks"
- Learned Perceptual Image Patch Similarity (LPIPS): A perceptual similarity metric between images based on deep features rather than pixels. "Learned Perceptual Image Patch Similarity"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that inserts low-rank adapters into weight matrices. "Low-Rank Adaptation"
- Median blurring: A noise-reduction filter replacing each pixel with the median of its neighborhood. "followed by median blurring to filter out outlier pixels"
- Multi-view vertical stitching: Assembling frames from multiple cameras vertically into one composite for conditioning or captioning. "multi-view vertical stitching strategy"
- MV-Mat.: A metric counting matched feature points between generated views to assess multi-view correspondence. "(MV-Mat.)"
- Open-vocabulary segmentation: Segmentation that can identify categories beyond a fixed label set using text prompts. "open-vocabulary segmentation model"
- Panoptic segmentation: Unified segmentation that assigns both semantic and instance labels to every pixel. "Panoptic segmentation"
- Patchification layer: A layer (often convolutional) that converts images into patch tokens for Transformer processing. "patchification layerâimplemented as a convolutional layer that transforms latent images into patches"
- Pixel-aligned conditions: Conditioning signals aligned to pixels (e.g., edges, depth, segmentation) used to guide generation. "pixel-aligned conditions, like edges, depth, and segmentation"
- Real-to-real generation: Editing or transforming real inputs into other realistic outputs while staying in the real domain. "real-to-real generation"
- Supervised Fine-Tuning (SFT): Training a pretrained model on labeled data to adapt it to a target task. "Supervised Fine-Tuning (SFT) on BridgeDataV2"
- Temporal coherence: Consistency of generated content across time in a video sequence. "temporally coherent"
- Video-to-video models: Generative models that transform an input clip into another consistent sequence under conditioning. "Video-to-video models"
- Visual identity prompting: Conditioning generation on exemplar images to enforce specific visual attributes and low-level details. "visual identity prompting"
- Vision-Language-Action (VLA): Models that jointly encode vision, language, and action for robot control. "VLA systems"
- Visuomotor policy: A policy that maps visual observations directly to motor actions. "visuomotor policy"
- Zero-shot: Deploying or evaluating a model on a task without any task-specific fine-tuning. "Zero-shot"
Collections
Sign up for free to add this paper to one or more collections.

