PRInTS: Reward Modeling for Long-Horizon Information Seeking
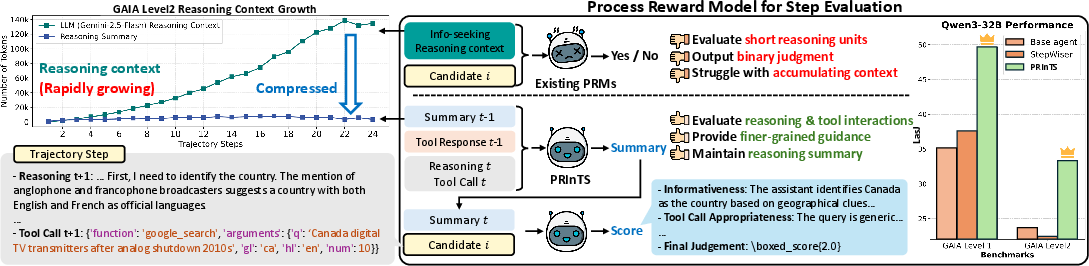
Abstract: Information-seeking is a core capability for AI agents, requiring them to gather and reason over tool-generated information across long trajectories. However, such multi-step information-seeking tasks remain challenging for agents backed by LLMs. While process reward models (PRMs) can guide agents by ranking candidate steps at test-time, existing PRMs, designed for short reasoning with binary judgment, cannot capture richer dimensions of information-seeking steps, such as tool interactions and reasoning over tool outputs, nor handle the rapidly growing context in long-horizon tasks. To address these limitations, we introduce PRInTS, a generative PRM trained with dual capabilities: (1) dense scoring based on the PRM's reasoning across multiple step quality dimensions (e.g., interpretation of tool outputs, tool call informativeness) and (2) trajectory summarization that compresses the growing context while preserving essential information for step evaluation. Extensive evaluations across FRAMES, GAIA (levels 1-3), and WebWalkerQA (easy-hard) benchmarks on multiple models, along with ablations, reveal that best-of-n sampling with PRInTS enhances information-seeking abilities of open-source models as well as specialized agents, matching or surpassing the performance of frontier models with a much smaller backbone agent and outperforming other strong reward modeling baselines.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces a new AI helper called PRInTS. It’s designed to guide other AI agents when they search for information online over many steps, like reading webpages, running code, or using search tools. The goal is to help these agents make smarter moves at each step and not get lost in tons of text.
The main problem and purpose
Many AI agents try to solve complex problems by thinking step-by-step and using tools (like search engines). But:
- Older “judges” that score each step usually only check short, simple reasoning (like quick math or logic).
- They don’t consider tool use (did the search help? did the agent understand the results?).
- The agent’s notes get very long over time, which makes judging each step harder.
PRInTS fixes this by:
- Scoring each full step (the agent’s reasoning plus any tool actions).
- Summarizing the growing history into short, useful notes so it stays manageable.
Key questions the paper asks
This paper tries to answer three simple questions:
- How can we judge each move an AI agent makes in a long problem so it picks better next steps?
- Can we measure how much a step actually helps move toward the right answer?
- Can we compress long histories into short summaries without losing important information?
How PRInTS works (in everyday language)
Think of the AI agent like a student solving a big research project:
- It thinks about what to do next.
- It uses tools (searches the web, reads pages, runs code).
- It learns something and moves on to the next step.
PRInTS is like a smart teacher that does two jobs at once:
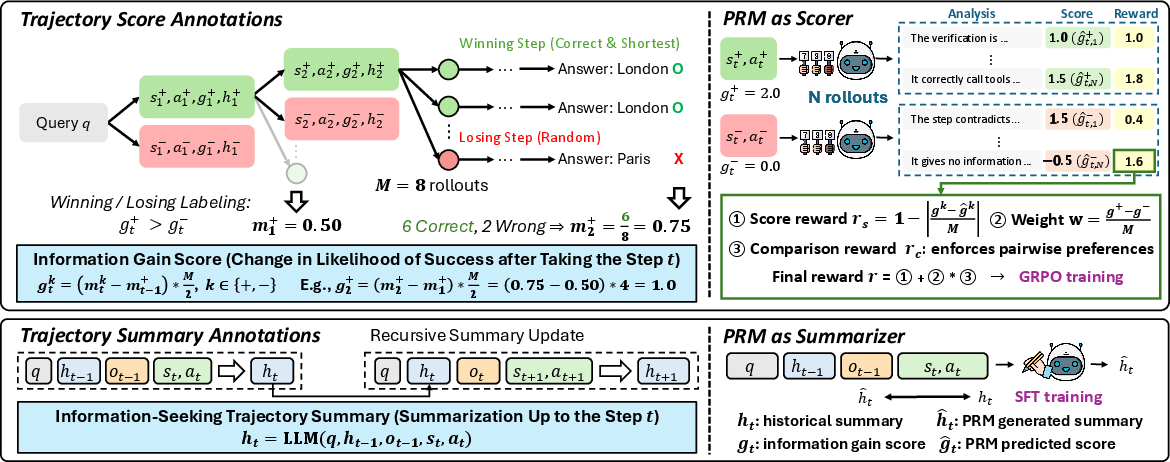
1) Scoring each step with “information gain”
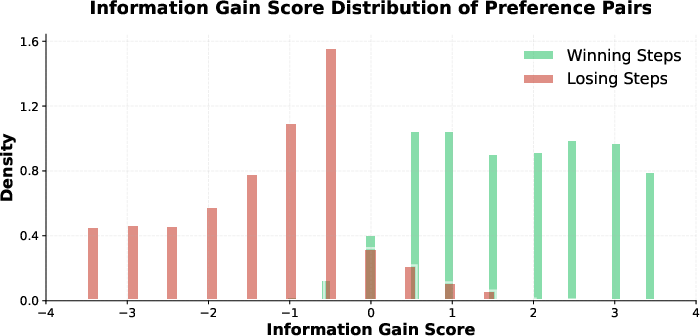
PRInTS estimates how much a step helps you get closer to the correct answer. This is called “information gain.” You can imagine it like a progress bar: after the step, did the bar move forward or backward?
To calculate this, PRInTS uses a simple idea:
- Try several possible futures from this step (like playing out different paths in a game) and see how often they lead to the right answer.
- Compare that to the success rate before the step.
- The difference is the “information gain” score. Higher means the step was helpful.
PRInTS looks at several parts of a step to judge it well. For example:
- How well did the agent interpret tool outputs (did it read the page correctly)?
- Was the tool call informative (did the search help, or was it off-topic)?
- Does the plan for the next action make sense?
Then PRInTS compares pairs of steps (like “Step A vs. Step B”) to learn preferences: which one was better and why? It trains itself using rewards when its scores match the true “better step.” This helps PRInTS become a strong, fair judge.
2) Summarizing long histories
Long problems can create huge, messy notes. PRInTS keeps a short, updated summary that captures only the key facts and the plan so far. At every step, it updates the summary with:
- The original question
- The previous summary
- The latest tool output
- The current reasoning and action
This compact summary helps PRInTS judge next steps more accurately without getting overwhelmed.
A helpful test-time trick: best-of-n
When the agent proposes several possible next moves, PRInTS scores them and picks the best one. This is like trying multiple “what should I do next?” ideas and choosing the most promising.
Main findings and why they matter
The authors tested PRInTS on three tough benchmarks where agents need to search, read, and reason:
- FRAMES (factual and multi-step reasoning),
- GAIA (general assistant tasks, Levels 1–3),
- WebWalkerQA (gather evidence by browsing websites, Easy–Hard).
They tried PRInTS with different agents/models:
- Qwen3-32B (open-source model),
- DeepResearch-30B-A3B (a specialized information-seeking agent),
- Gemini-2.5-Flash (frontier closed-source model).
Key results include:
- PRInTS boosted performance for Qwen3-32B by about 9.3 percentage points on average, and consistently beat other reward models.
- PRInTS improved the specialized DeepResearch-30B-A3B by 3.9 points, pushing it close to much larger “frontier” systems on GAIA.
- PRInTS also helped Gemini-2.5-Flash by 4.0 points, showing it generalizes across different models.
- Summaries were crucial: feeding the judge a compact summary worked better than feeding raw, long histories.
- Combining two kinds of training rewards (one for accurate scoring, one for choosing better steps in pairs) worked best, especially with smart weighting to reduce noise.
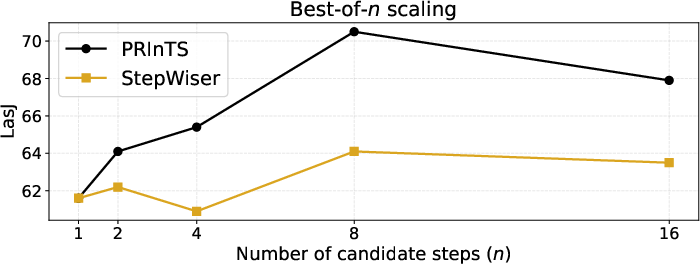
- Trying more candidate steps at test-time (best-of-n) improved results up to a point (best around n=8), showing PRInTS scales with extra compute.
Why this matters:
- It shows that a small, smart judge (PRInTS is ~4B parameters) can meaningfully improve big agents without retraining them.
- It makes long, tool-heavy tasks more reliable by guiding each step.
- It addresses a real pain point: handling long, messy histories.
Simple conclusion: what could this change?
PRInTS helps AI agents:
- Make better decisions step-by-step when searching and reasoning over long tasks.
- Stay focused using compact summaries rather than drowning in text.
- Get smarter without needing costly retraining of the main agent.
Potential impact:
- Better AI assistants for research, software help, and complex problem-solving.
- More dependable tool use (search, browsing, code) with fewer wasted steps.
- A general plug-in “judge” that can improve many different agents and models.
In short, PRInTS is like a coach that both tracks your progress carefully and keeps tidy notes, so you choose the most helpful next move—even in long, complicated quests for information.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be concrete and actionable for future research.
- Information gain formulation
- Validate the proxy for information gain (): quantify its bias/variance, calibration to true success probabilities, and sensitivity to rollout count ; compare against alternative estimators (e.g., Bayesian belief updates, log-odds changes, entropy/mutual information reductions, value-to-go).
- Provide confidence intervals or uncertainty estimates for and use them in step selection (risk-aware decision-making).
- Preference pair construction and ranking loss
- Test the assumption that “shortest successful trajectory = best next step”; compare against hard-negative mining, diversity-aware sampling, listwise ranking, and tournament-based pair generation.
- Replace/augment the current adaptive weighting with principled noisy-label methods (e.g., robust loss, margin-based calibration, or learned weighting) and report theoretical/empirical justification.
- Explore learning-to-rank objectives beyond GRPO (pairwise/listwise), and analyze their impact on stability and performance.
- Training data scale and provenance
- Assess performance scaling with dataset size (beyond ~2k pairs): learning curves, diminishing returns, and sample efficiency.
- Evaluate cross-model/data provenance bias: the dataset and annotations are generated by Qwen3-32B; measure how annotation-model choice impacts PRM generalization to other agents and domains.
- Release and audit the annotation pipeline and datasets (including summaries) to enable reproducibility and bias analysis.
- Summarization fidelity and design
- Quantify summary faithfulness and information retention (e.g., coverage/F1 against ground-truth facts and plans); analyze how summary errors propagate into scoring.
- Explore alternatives to SFT-only summarization (RL from utility, retrieval-augmented memory, edit-based updates, structured state representations, or citation-linked summaries to tool outputs).
- Investigate length/format constraints: how summary length, structure, and compression rate affect scoring accuracy and latency.
- Context and compute trade-offs
- Provide a formal complexity and latency analysis for PRInTS (summarization + scoring) vs raw-history PRMs; report wall-clock overheads, GPU memory, and energy.
- Study dynamic context policies: when to summarize, how often, and how to adapt compression to trajectory length/noise.
- Test-time scaling and termination
- Address over-exploration at large (e.g., ): design termination criteria, “answer-ready” detection, or explicit stopping rewards to balance exploration/exploitation.
- Investigate adaptive based on score confidence/entropy and dynamic step budgets.
- Evaluation methodology and reliability
- Replace or triangulate LLM-as-Judge (GPT-5) with human adjudication, rule-based checks, or multi-judge consensus; report inter-rater reliability and judge calibration.
- Include statistical significance tests for reported gains; quantify variance over seeds/runs and present confidence intervals.
- Breadth of generalization
- Extend evaluation beyond FRAMES/GAIA/WebWalkerQA to domains with different tool types (APIs, databases), noisy/adversarial web content, code execution, math verification, and data analysis.
- Test robustness under domain shift and adversarial tool outputs (prompt injection, content poisoning), and measure failure modes.
- Multi-factor step quality modeling
- Make the “multiple quality dimensions” explicit (interpretation accuracy, informativeness, plan quality, grounding, etc.); learn interpretable sub-scores and analyze per-dimension contributions to final guidance.
- Provide user/task-specific weighting of dimensions, and study how domain-dependent priors affect performance.
- Integration with planning and lookahead
- Move beyond myopic step scoring: incorporate lookahead (tree search, MCTS), global credit assignment, and plan-level evaluation to avoid locally optimal but globally suboptimal steps.
- Combine PRInTS with Outcome Reward Models (ORMs) and analyze ensemble or hierarchical guidance (step-level + trajectory-level).
- Training strategy and model scaling
- Compare the alternating SFT-GRPO schedule with joint multi-task training, different alternation ratios, or curriculum strategies; report training stability and convergence behavior.
- Study PRM backbone scaling laws (size, architecture), parameter sharing between f_S and f_I, and the benefits of specialized vs unified heads.
- Safety, alignment, and compliance
- Evaluate whether PRInTS-guided steps increase risky tool actions (e.g., unsafe browsing, data exfiltration) or amplify hallucinations; develop safeguards and red-teaming protocols.
- Measure and mitigate biases introduced by summarization and scoring (e.g., source trust bias, confirmation bias).
- Score calibration and cross-task comparability
- Calibrate dense scores across tasks/datasets so they are comparable; explore per-task normalization, temperature scaling, and threshold selection for decision-making.
- Provide diagnostics for miscalibration and confidence-aware step selection.
- Ablations and diagnostics not reported
- Vary rollout counts /, candidate-generation strategies, summary length/format, and PRM size; report their effects.
- Conduct qualitative error analysis (misranked steps, summary drift, evidence loss) and provide actionable fixes.
- Limitations in exact-evidence tasks
- Test scenarios requiring verbatim quotes or precise numerical details; measure whether compression drops essential tokens and develop evidence-preserving summaries.
- Online adaptation and continual learning
- Explore on-the-fly PRM adaptation from live trajectories (bandit/RL), domain-specific fine-tuning, and self-improving judges under distribution shift.
- Multimodality and tool diversity
- Extend PRInTS to multimodal information-seeking (images, tables, charts, PDFs) and specialized tools; quantify how modality/tool type affects summary and scoring quality.
- Reproducibility details
- Clarify Inspect-Eval environment configuration, tool interaction realism, and any constraints; enable end-to-end reproducible runs including tool calls and web content snapshots.
Practical Applications
Immediate Applications
These applications can be deployed now using PRInTS as a model-agnostic, test-time controller for long-horizon, tool-using agents. PRInTS acts as a sidecar “step scorer + summarizer” that ranks candidate next actions (best-of-n) and maintains compact, persistent summaries of the trajectory.
Industry
- Enterprise knowledge search and research copilots (software, pharma, consulting)
- Use PRInTS to steer multi-step web/KB retrieval, choose the most informative next search/browse/cite action, and maintain a concise evidence summary per query or dossier.
- Potential tools/products/workflows: “Step Scorer API,” “Trajectory Summarizer” memory service, best-of-n controller for ReAct-style agents; dashboards that surface PRInTS’ rationale per step to auditors.
- Assumptions/dependencies: access to tool connectors (web search, browser automation, internal KB APIs); tolerance for additional latency from evaluating multiple candidate steps; domain adaptation prompts for vertical terminology; data governance for storing summaries.
- Customer support and troubleshooting assistants (telecom, IT, consumer electronics)
- Rank diagnostic next steps (e.g., log inspection, config check, targeted search) and preserve a running case synopsis to avoid context overflow.
- Potential tools/products/workflows: “Next-best-diagnostic” recommender, ticket notes auto-summarizer, PRInTS-guided triage in call-center consoles.
- Assumptions/dependencies: integration with ticketing systems and diagnostic tools; guardrails to prevent over-exploration when resolution is already found; privacy controls on logs.
- Software engineering copilots (dev tools, DevOps, SRE)
- Guide multi-step debugging and code-understanding with tool calls (tests, static analysis, logs), rank which probe to run next, and summarize findings and hypotheses.
- Potential tools/products/workflows: CI/CD plugin to prioritize triage actions; PRInTS-guided “debug plan” builder; codebase exploration memory.
- Assumptions/dependencies: safe sandboxes for code execution; visibility into tool outputs; acceptance of extra tokens/latency for best-of-n.
- Financial and legal research (finance, legal tech)
- For due diligence, market mapping, and e-discovery, PRInTS selects the most informative next query/source and keeps a compact chain-of-evidence summary for auditability.
- Potential tools/products/workflows: diligence copilot with verification steps, caselaw navigator with evidence trail, PRInTS-based “citation sufficiency” checks.
- Assumptions/dependencies: compliance with access/licensing for proprietary databases; careful summary fidelity for legal/financial material; human-in-the-loop sign-off.
- Threat intelligence and security triage (cybersecurity)
- Prioritize the next enrichment (CVE lookups, IOC pivots, knowledge base checks) and track hypotheses across long-horizon investigations.
- Potential tools/products/workflows: SOC analyst assistant with PRInTS-scored pivots; incident timeline summarizer.
- Assumptions/dependencies: integration with TI feeds and SIEM/SOAR; strict data isolation; latency budgets for real-time triage.
- Data analytics and BI assistants
- Rank candidate next queries/transformations after inspecting previous query results; keep a “finding book” summary that persists across sessions.
- Potential tools/products/workflows: PRInTS-guided query planner; notebook copilot that summarizes results and suggests the next analysis.
- Assumptions/dependencies: governed access to data warehouses; sandboxed code execution; robust termination criteria to avoid over-exploration.
- Agent evaluation and debugging (MLOps)
- Use PRInTS as a generative judge to score step quality and produce rationales across multiple dimensions (tool choice, interpretation, plan), enabling offline A/B testing and regression monitoring.
- Potential tools/products/workflows: “Agent Evaluator” dashboard; CI gates that fail merges if step-quality metrics regress; dataset curation by filtering low-quality steps.
- Assumptions/dependencies: ability to capture agent trajectories; stable prompts/checklists; compute for batch scoring.
Academia
- Literature review and evidence synthesis assistants
- Guide long-horizon academic search (PubMed/arXiv/library systems), prioritize next retrievals, and maintain a compact synthesis with citations and open questions.
- Potential tools/products/workflows: PRInTS-augmented review workflow; “related work explorer” with hypothesis tracking.
- Assumptions/dependencies: access to scholarly APIs and full-text; citation management integration; care to avoid hallucinated claims.
- Dataset curation and weak supervision
- Use PRInTS to filter and rank intermediate reasoning steps in synthetic or logged trajectories to build higher-quality training corpora for agents/PRMs.
- Potential tools/products/workflows: preference-data factory; trajectory scoring pipelines.
- Assumptions/dependencies: representative source trajectories; calibration for target domains to reduce bias.
Policy and Government
- Analyst research assistants (public policy, compliance, OSINT)
- Select the most informative next source or FOIA document to inspect and maintain auditable summaries and evidence chains.
- Potential tools/products/workflows: OSINT agent with PRInTS-scored pivots; policy dossier builder with traceable sourcing.
- Assumptions/dependencies: clear sourcing constraints; PII handling; human validation before dissemination.
Daily Life
- Personal research copilots (travel, purchases, DIY)
- Rank the next site/search to check and keep a succinct “decision log” (criteria, trade-offs, best options) that persists across sessions.
- Potential tools/products/workflows: browser extension that adds PRInTS-guided next steps and a rolling summary panel.
- Assumptions/dependencies: user consent for session capture; rate limits on consumer APIs; UX controls to limit over-exploration.
Long-Term Applications
These applications are promising but likely need further research, domain adaptation, safety validation, or scale-up of tools and data.
Healthcare
- Clinical decision support and guideline synthesis
- Assist clinicians by prioritizing the next evidence lookup (guidelines, trials) and maintaining rigorously structured summaries with uncertainty tracking.
- Potential tools/products/workflows: CDS “research mode” that logs evidence trails; living guideline updater.
- Assumptions/dependencies: rigorous validation, bias/factuality checks, provenance guarantees, and regulatory approvals; domain-tuned PRInTS trained on biomedical corpora; strict PHI handling.
Science and R&D
- Autonomous literature-to-experiment agents
- Use information-gain scoring to plan the next experiment or data collection step, synthesizing multi-paper evidence and updating hypotheses.
- Potential tools/products/workflows: lab planning copilots; hypothesis trackers that link to instruments/ELNs.
- Assumptions/dependencies: integration with lab tools; domain-specific tool interfaces and simulators; robust uncertainty calibration.
Robotics and Embodied AI
- Long-horizon exploration and information-seeking
- Treat sensing/inspection/lookup as “tool calls,” scoring which next action yields maximal information about task-critical variables.
- Potential tools/products/workflows: PRInTS-based exploration controller; warehouse inspection planners.
- Assumptions/dependencies: extension to multimodal inputs (vision, proprioception); real-time constraints; safety and failure recovery.
Enterprise Knowledge Fabric
- Continuous knowledge graph/dossier construction
- Agents that continuously harvest, verify, and summarize changes across thousands of sources, preserving audit trails via PRInTS summaries.
- Potential tools/products/workflows: “living dossier” systems for competitors, suppliers, or risks.
- Assumptions/dependencies: scalable crawling with compliance; de-duplication and provenance; organization-wide memory governance.
Multi-agent Orchestration and AI Governance
- Judge-orchestrator for agent collectives
- PRInTS arbitrates proposals from multiple specialized agents, selecting next actions and summarizing consensus/rationale for oversight.
- Potential tools/products/workflows: council-of-agents controller; safety/ethics monitors that flag risky chains-of-thought.
- Assumptions/dependencies: interfaces for proposal exchange; conflict-resolution policies; auditing standards.
Education
- Exploratory tutors and research mentors
- Guide students’ inquiry processes by recommending the most informative next resource or activity and maintaining metacognitive summaries of progress.
- Potential tools/products/workflows: inquiry-based learning assistants; “learning trajectory” journals.
- Assumptions/dependencies: pedagogy-aligned evaluation; studies of learning outcomes; age-appropriate safety controls.
Finance and Compliance Automation
- End-to-end due diligence and monitoring
- Large-scale, verifiable pipelines that continuously gather, cross-check, and summarize evidence with PRInTS scoring of next probes.
- Potential tools/products/workflows: automated KYC/AML research assistants; audit-ready evidence trees.
- Assumptions/dependencies: regulator acceptance, robust provenance, adversarial robustness to misinformation.
Platformization and Standards
- PRM-as-a-Service and agent audit standards
- Standardized APIs for step scoring and trajectory summarization; benchmarks and reporting norms for agent step quality and over-exploration control.
- Potential tools/products/workflows: “PRInTS-SDK,” cloud PRM services, best-of-n controllers with budgeted stopping rules.
- Assumptions/dependencies: cost/latency optimization; caching and retrieval of summaries; interoperability across agent frameworks.
Cross-Modal and Cross-Domain Extensions
- Vision, audio, and code-heavy tasks
- Extend information-gain scoring to multi-modal tool outputs (e.g., GUI exploration, video retrieval, code execution traces).
- Potential tools/products/workflows: GUI testing agents; clinical imaging triage research assistants.
- Assumptions/dependencies: new annotations and training signals; robust summarization for non-text artifacts; domain calibration.
Notes on feasibility across applications:
- Compute/latency trade-offs: best-of-n improves outcomes but increases cost; n must be tuned, with stopping conditions to avoid over-exploration.
- Domain shift: PRInTS was trained on web information-seeking; specialized domains may require targeted prompts, summaries, or fine-tuning.
- Safety and compliance: summaries can omit critical details; use provenance, verification, and human oversight in high-stakes settings.
- Tool reliability: performance depends on high-quality tool outputs (search APIs, browsers, code sandboxes) and rate-limit management.
Glossary
- Ablation studies: Targeted experiments where components are removed or altered to assess their impact on performance. "our ablation studies reveal that providing compressed summaries outperforms using raw trajectories as input context"
- Adaptive weight: A dynamically set coefficient that adjusts the influence of a training signal based on context (e.g., score margins) to mitigate noise. "with an adaptive weight based on the ground-truth score margin"
- Agentic ReAct paradigm: An agent framework where an LLM interleaves reasoning with actions (tool calls) to solve tasks. "we adopt the agentic ReAct paradigm"
- Best-of- sampling: A test-time strategy where multiple candidate steps are scored and the best is selected to guide the agent. "best-of- sampling with PRInTS enhances information-seeking abilities"
- Chain-of-Thought (CoT): Explicit step-by-step reasoning generated by a model to analyze and justify decisions. "generating Chain-of-Thought analyses across multiple quality dimensions"
- Comparison Reward: A reinforcement learning signal that encourages a model to score preferred steps higher based on pairwise comparisons. "a Comparison Reward that teaches the model to assign higher scores to preferred trajectory steps"
- Dense scoring: Producing fine-grained, continuous scores reflecting multiple dimensions of step quality rather than binary judgments. "dense scoring based on the PRM's reasoning across multiple step quality dimensions"
- Frontier models: The strongest, often closed-source or cutting-edge models representing the current performance frontier. "matching or surpassing the performance of frontier models"
- Generative judges: Models that generate justifications and scores for evaluation, rather than outputting labels directly. "Recent advancements cast PRMs as generative judges that generate justifications for step scores"
- GRPO: A reinforcement learning algorithm (Generalized Reinforcement Policy Optimization) used to train scoring behavior. "We train this scoring capability using GRPO"
- Information gain: The estimated increase in the probability of reaching the correct answer attributable to a step. "we frame step evaluation as information gain estimation that quantifies how much each trajectory step increases the probability of reaching the correct answer."
- Information-seeking trajectory: The sequence of reasoning steps, tool calls, and tool outputs accumulated while solving a task. "referred to as the information-seeking trajectory"
- LLM-as-Judge (LasJ): An evaluation approach where an LLM scores or judges the correctness of outputs. "we adopt the LLM-as-Judge (LasJ) paradigm to measure benchmark performance"
- Monte Carlo rollouts: Repeated randomized simulations of possible futures used to estimate expected outcomes (e.g., accuracy). "uses Monte Carlo rollouts to estimate information gain scores"
- Outcome Reward Models (ORMs): Models that evaluate the correctness of complete trajectories, not intermediate steps. "Outcome Reward Models (ORMs) are used to predict the correctness of complete reasoning trajectories"
- Pairwise preferences: Comparative labels indicating which of two candidate steps is better, used for preference learning. "enforces pairwise preferences derived from annotated pairs"
- Preference pairs: Constructed pairs of candidate steps labeled to indicate a winner and loser for training evaluators. "constructing preference pairs grounded in information gain scores"
- Preference prediction: Learning to predict which of two candidate steps is better according to preference signals. "reinforcement learning with information gain estimation and preference prediction objectives"
- Process Reward Models (PRMs): Models that evaluate and score individual steps within a trajectory to guide reasoning processes. "While process reward models (PRMs) can guide agents by ranking candidate steps at test-time"
- ReAct: A framework that interleaves reasoning (thoughts) with actions (tool use) for agents. "equipped with frameworks like ReAct, which interleaves LLM reasoning with external tool interactions."
- Reinforcement learning: A training paradigm where models learn policies by maximizing reward signals over actions. "training via reinforcement learning with information gain estimation and preference prediction objectives"
- Score Reward: A reinforcement learning signal that encourages accurate prediction of step-level information gain. "a Score Reward that teaches the model to analyze the trajectory step quality and estimate the step's information gain score"
- Supervised fine-tuning (SFT): Training a model to imitate labeled target outputs, such as summaries. "We use supervised fine-tuning (SFT) on the annotated summaries"
- Test-time scaling: Improving performance by increasing computation at inference (e.g., generating and scoring more candidates). "enabling test-time scaling by ranking and selecting higher-quality actions or trajectories"
- Trajectory summarization: Compressing the accumulated context into a concise summary that preserves key information for evaluation. "trajectory summarization that compresses the growing context while preserving essential information for step evaluation."
Collections
Sign up for free to add this paper to one or more collections.

