- The paper introduces AgentPRM and InversePRM frameworks, using Monte Carlo rollouts to compute reward targets for improved LLM agent performance.
- The framework integrates supervised learning with RL to efficiently train agents, achieving high success rates on complex text-based tasks.
- The study demonstrates scalability and sample efficiency, achieving up to 91.0% success rate while reducing reliance on extensive human feedback.
Process Reward Models for LLM Agents: Practical Framework and Directions
Introduction
The paper "Process Reward Models for LLM Agents: Practical Framework and Directions" (arXiv ID: (2502.10325)) introduces Agent Process Reward Models (AgentPRM) as a framework for training LLM agents using reinforcement learning (RL) principles. This innovation aims to enhance LLM agents' ability to refine their decision-making policies through interactions, minimizing the need for extensive human supervision typically required in supervised fine-tuning (SFT) and RL from human feedback (RLHF).
Framework Overview
AgentPRM operates within an actor-critic paradigm, leveraging Monte Carlo rollouts to compute reward targets and optimize policies in multi-turn interaction settings.
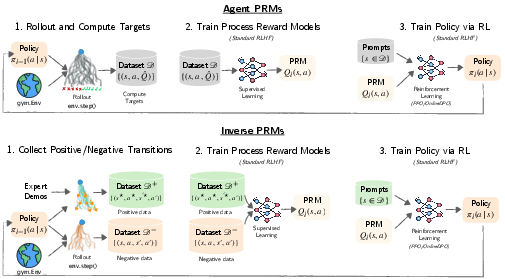
Figure 1: Overview of AgentPRM and InversePRM framework for training LLM policies.
The framework consists of three iterative stages (as shown in Figure 1):
- Rollout and Compute Target: The current policy πi−1 is executed to generate rollouts and calculate process reward model targets.
- Train Process Reward Model: The PRM Qi is trained with supervised learning on the collected dataset.
- Training Policy via RL: Using the updated PRM, the LLM policy is optimized to improve interaction outcomes.
Distinctively, this approach enhances efficiency by providing early-stage and granular feedback, mitigating issues of sparse rewards in traditional outcome-based RL.
Key Innovations and Algorithms
The paper highlights several contributions:
- AgentPRM: Enhances LLM policies by calculating PRMs during the rollout phase, providing a structured form of feedback akin to critic functions in RL.
- InversePRM: Derived from demonstrations, this model learns PRMs directly without explicit outcome rewards, improving sample efficiency and performance even from limited data.
- Implementation Simplicity: Both models remain compatible with existing RLHF pipelines, requiring minimal modifications and ensuring scalability within practical environments.
Experimental Evaluation
The effectiveness of AgentPRM and InversePRM is demonstrated on ALFWorld, a benchmark involving complex text-game interactions.
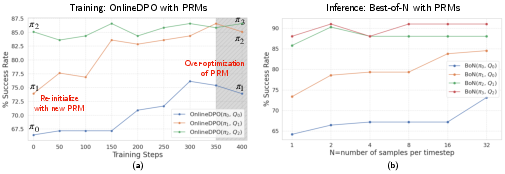
Figure 2: Training and Inference performance showing success rates across training steps with Online DPO and Best-of-N inference strategies.
- AgentPRM outperformed strong GPT-4o baselines with 3B models, achieving a notable 91.0% success rate in test environments.
- InversePRM achieved near-expert performance with heightened sample efficiency, reaching similar success rates with substantially fewer iterations compared to traditional methods.
Challenges and Opportunities
Exploration: Exploring effective strategies is vital due to the sparse nature of feedback in long-horizon tasks. The paper proposes techniques like reset distribution and steered exploration, which leverage LLMs' inherent characteristics to steer exploration more intelligently.
Process Reward Shaping: Addressing noise in low-sample regimes, the paper demonstrates how shaping rewards with advantage functions from reference policies can stabilize training.
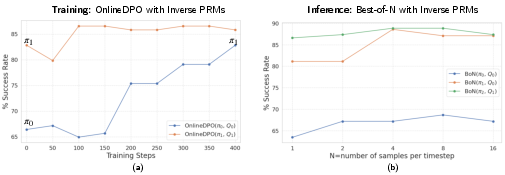
Figure 3: Best-of-N inference analysis showing the impact of policy quality and PRM optimization on success rates.
Model-Predictive Reasoning: By embedding multi-stage reasoning within agent policies, the approach suggests simulating outcomes to enhance decision-making, reducing costly environment interactions. This method parallels model-predictive control, traditionally used in robotics.
Conclusion
The introduction of AgentPRM and InversePRM signifies a meaningful progression in training LLM agents, enhancing their sample efficiency and decision-making capabilities. Addressing exploration and reward shaping challenges with innovative strategies suggests a path forward for broader adoption in more complex domains. Future work will likely focus on scaling these methods to more intricate environments and continuing to leverage LLM-specific capabilities for more effective learning paradigms.