- The paper introduces TARL, a turn-level adjudicated RL framework, to achieve fine-grained credit assignment in multimodal, multi-turn tool-use interactions.
- The approach combines robust sandbox environments and mixed-task curricula to yield significant improvements in performance metrics and extended response lengths.
- Experimental results underscore the necessity of mixed-modality training for stable and generalizable tool-use in both text and speech settings.
Introduction and Motivation
The paper addresses the challenge of training interactive agents capable of robust tool use in multimodal, multi-turn settings, with a particular focus on integrating speech and text modalities. The core problem is the development of agents that can perform Tool Integrated Reasoning (TIR): planning and executing sequences of tool calls in response to complex, often ambiguous user requests, which may be delivered via text or speech. The authors identify two primary obstacles: (1) effective credit assignment in long-horizon, multi-turn interactions, and (2) maintaining exploration during RL training, as models tend to become overconfident and exploitative, reducing their ability to discover improved strategies.
To address these, the paper introduces a sandbox environment for RL-based agent training, a novel Turn-level Adjudicated Reinforcement Learning (TARL) framework for fine-grained credit assignment, and a mixed-task curriculum that incorporates mathematical reasoning to sustain exploration. The approach is validated on both text and speech-based tool-use tasks, demonstrating significant improvements over strong RL baselines.
Sandbox Environment and Agent Architecture
The sandbox environment is designed to support realistic, multi-turn interactions between agents, users, and tools, with support for both text and speech modalities. The environment consists of a backend application with a relational database, a user simulator leveraging LLMs (e.g., GPT-4), and a rule-based verifier for trajectory evaluation.
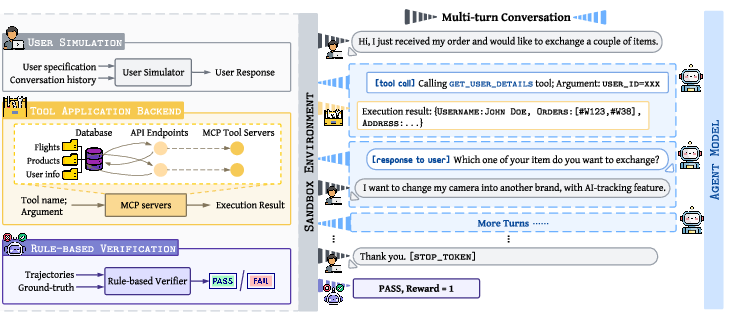
Figure 1: The environment setup for interactive tool-use agents, supporting both text and speech modalities for user simulation and tool execution.
Agents interact with the environment by generating tool calls and receiving feedback from either simulated users or tool execution results. The agent's policy backbone is an autoregressive LLM, and the state is the token sequence observed so far. The environment alternates between agent actions and environment feedback, supporting interleaved speech-text rollouts for multimodal training.
RL Algorithms and Credit Assignment
The agent training is formulated as an MDP, with the objective of maximizing expected reward over complete trajectories. The paper benchmarks several RL algorithms:
- PPO: Standard token-level policy gradient with clipping.
- GRPO: Group-based normalization of rewards for improved stability.
- RLOO: Leave-one-out baseline for variance reduction.
A key insight is that vanilla RL with trajectory-level rewards leads to sparse credit assignment, especially problematic in long, multi-turn dialogues. This results in suboptimal learning, as the agent cannot easily attribute success or failure to specific actions.
Turn-level Adjudicated Reinforcement Learning (TARL)
To address the credit assignment problem, the authors propose TARL, which employs an LLM-based judge to provide turn-level rewards. After each turn, the judge evaluates the agent's action in the context of the full conversation and ground-truth annotations, assigning a reward of −1, $0$, or $1$ per turn, with a single −1 allowed per trajectory to penalize major deviations.
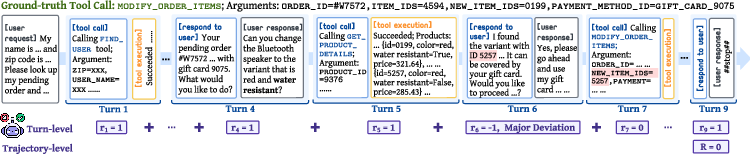
Figure 2: The LLM-based judge provides turn-level rewards by assessing each turn in the context of the full conversation and ground-truth annotations.
The final reward for a trajectory is a combination of the terminal (task completion) reward and the sum of scaled turn-level rewards, yielding a more informative and discriminative signal for policy optimization. The integration of TARL into GRPO and PPO is straightforward for the former (sum over trajectory), while for PPO, the authors find that applying the aggregated trajectory-level reward uniformly across all tokens is more stable than per-turn assignment.
Mixed-Task Training for Exploration
To counteract the reduction in exploration observed during RL training, the authors introduce a mixed-task curriculum that interleaves medium-difficulty math problems (from DeepScaleR) with tool-use tasks. This leverages the base model's pretraining on mathematical reasoning, encouraging longer chain-of-thought (CoT) trajectories and increased self-reflection, which empirically leads to more exploratory behavior.
Experimental Results: Text-Based Agents
The proposed methods are evaluated on the Retail domain of the τ-bench environment, using Qwen3-8B as the base model. The main findings are:
- TARL yields consistent improvements over vanilla RL baselines, with a 2.6–3.5% absolute gain in passk metrics.
- Mixed-task training with TARL achieves a 6% relative improvement over GRPO and a 15% improvement over the base model, reaching 57.4% pass1.
- Models trained with TARL and mixed-task curriculum exhibit longer responses and more frequent self-correction, as measured by the number of "wait" tokens and response length.
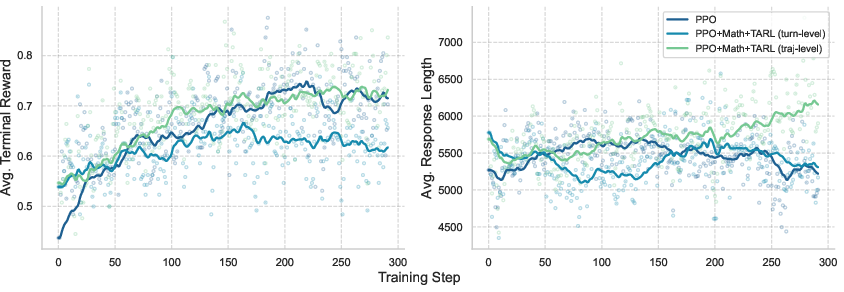
Figure 3: PPO-based training strategies show that trajectory-level reward assignment with turn-level evaluation (TARL traj-level) achieves the best performance.
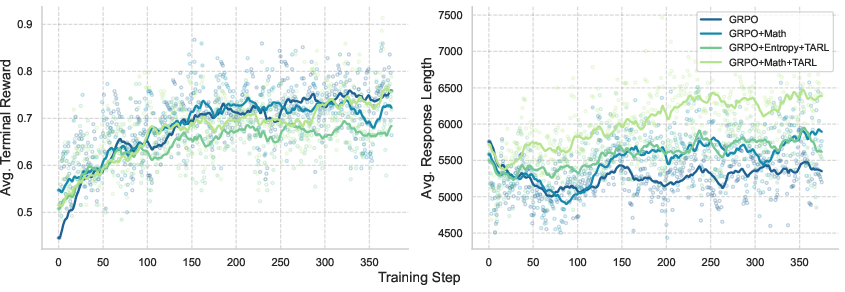
Figure 4: Mixed-task training with fine-grained turn-level evaluation (GRPO+Math+TARL) achieves the highest average reward and response length, indicating enhanced exploration and generalization.
Multimodal Agent Training and Evaluation
The framework is extended to train agents on interleaved speech-text rollouts using Qwen2.5-Omni-7B as the base model. Speech-based user simulation is achieved via SeedTTS. The authors employ a curriculum learning phase to warm up the agent's tool-use abilities, followed by mixed-modality training alternating between math, text-only, and speech-text tasks.
Key results:
- GRPO+Math+TARL improves pass1 by over 20% compared to the base model in both text and speech evaluation modes.
- Training exclusively on text degrades speech-mode performance, underscoring the necessity of mixed-modality training for robust voice agents.
Analysis of Training Strategies
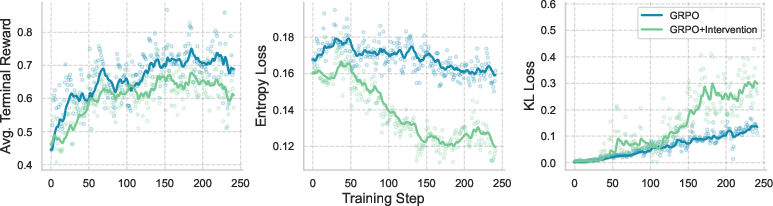
The paper provides a detailed analysis of reward granularity and exploration incentives:
Implications and Future Directions
The results demonstrate that process-supervised RL with fine-grained, LLM-judged turn-level rewards and mixed-task curricula can substantially improve the reliability and generalization of tool-use agents in both text and speech modalities. The findings suggest that:
- Simple, robust reward structures and curriculum design are more effective than complex interventions for long-horizon, multi-turn RL in LLM agents.
- Mixed-modality training is essential for maintaining and improving speech understanding and tool-use capabilities in multimodal foundation models.
- The approach is generalizable and can be extended to more diverse domains and more challenging user-agent-tool interaction environments as benchmarks evolve.
Theoretically, the work advances the understanding of credit assignment and exploration in RL for LLM-based agents, providing empirical evidence that process-level supervision (via LLM judges) is a scalable and effective alternative to purely outcome-based or rule-based reward modeling.
Conclusion
This paper presents a comprehensive framework for training interactive, multimodal tool-use agents via process-supervised RL. By combining a sandbox environment, turn-level adjudicated rewards from LLM judges, and a mixed-task curriculum, the approach achieves strong improvements over established RL baselines in both text and speech settings. The results highlight the importance of fine-grained credit assignment and sustained exploration, and provide a foundation for future research on robust, generalizable agentic LLMs capable of complex, real-world tool use.