- The paper demonstrates that LLMs encode problem difficulty in final-token representations via linear probes with measurable accuracy.
- It identifies attention head patterns that correlate strongly with perceived difficulty, validated through experiments on DeepMath tasks.
- This method enables automatic difficulty annotation, potentially reducing human labeling and supporting adaptive reasoning in LLMs.
Probing the Difficulty Perception Mechanism of LLMs
Abstract
The paper addresses the challenge of understanding how LLMs internally perceive problem difficulty, particularly in mathematical reasoning tasks. By employing linear probes on final-token representations, it showcases that problem difficulty levels can be modeled linearly within these representations. The research highlights the significance of attention heads in perceiving difficulty, suggesting these can be leveraged for automatic difficulty annotation, potentially reducing the need for human labeling.
Introduction
The study investigates the capability of LLMs to internally assess the difficulty of reasoning tasks. The primary objective is to discern whether these models encode difficulty perception in their internal structures, specifically through attention heads in the Transformer architecture. The research uses the DeepMath dataset as a benchmark to explore these perceptions and suggests practical applications in automatic difficulty annotation.
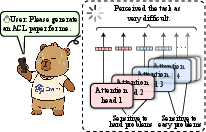
Figure 1: The LLM's perception of problem difficulty depends on the activation state of its specific attention heads.
High-dimensional Linear Probe Methodology
The research outlines a method using high-dimensional linear probes to evaluate difficulty perception. The probes apply a simple linear regression approach to predict difficulty scores from token embeddings. This methodology capitalizes on the high-dimensional capacity of LLMs to encode complex problem attributes.
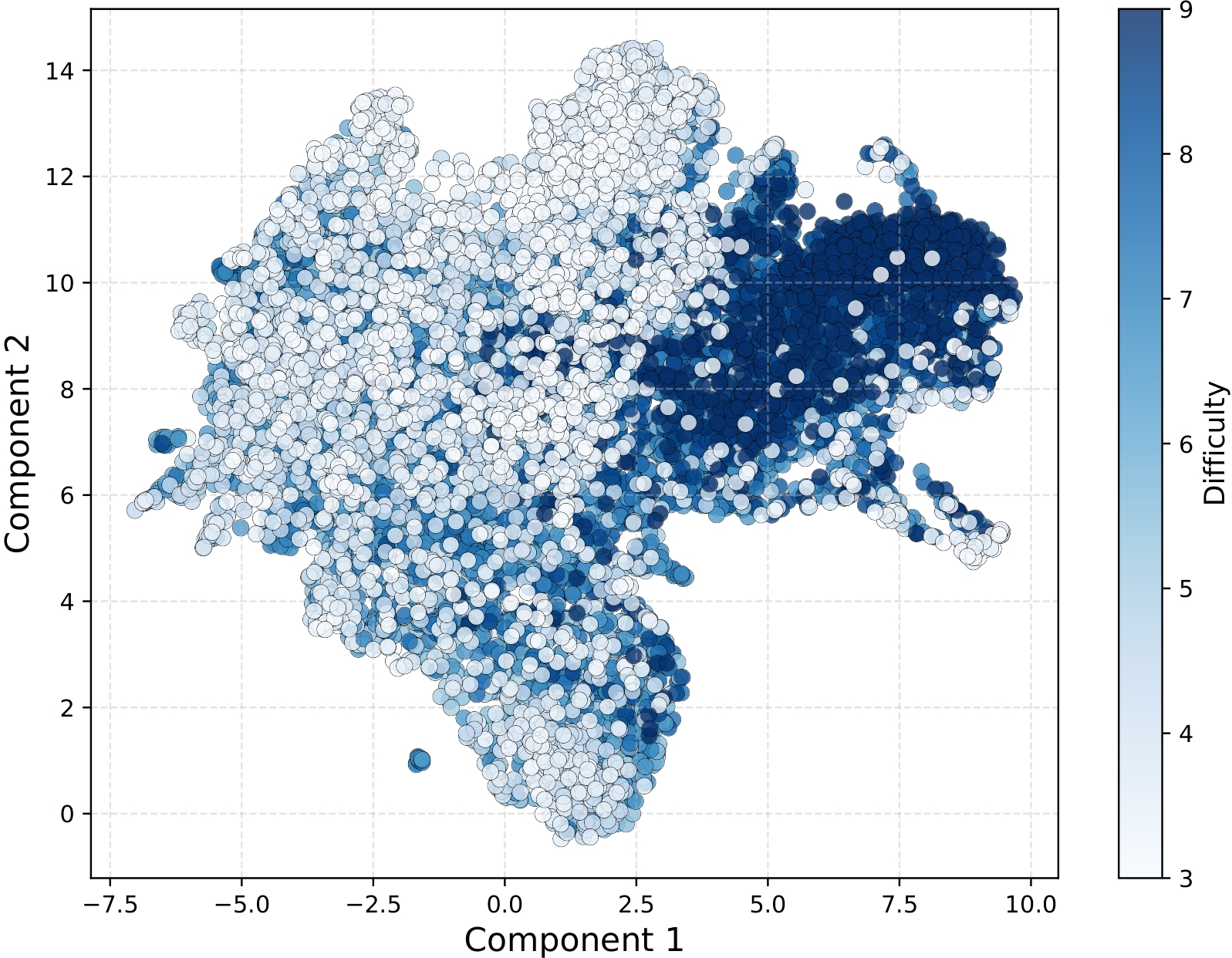
Figure 2: Qwen2.5-7B-Instruct's low-dimensional representation for DeepMath problems and difficulty is meticulously annotated by humans.
Attention Head Pattern Recognition
Attention heads in LLMs play a critical role in difficulty perception. By mapping probe results to attention head activations, the study identifies distinct patterns associated with problem difficulty. Heads exhibiting specialized sensitivity to varying difficulty levels provide insights into how LLMs allocate resources during task execution.
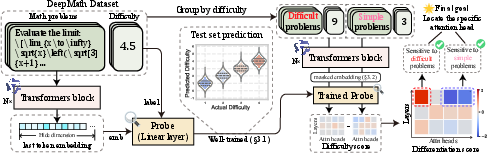
Figure 3: Probe training and attention heads pattern recognition.
Experiments and Results
Experiments demonstrate the reliability of the probe and attention head pattern recognition across different architectures. The study finds consistent attention head patterns in Qwen2.5-7B-Instruct models, validating the hypothesis that difficulty perception is encoded within specific heads. The probe results align with human annotations, confirming their accuracy.
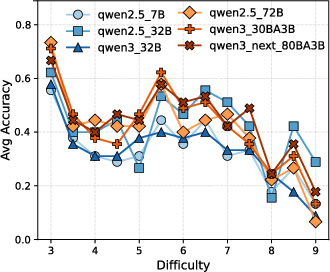
Figure 4: Accuracy rates of various models at different difficulty levels in DeepMath.
Probe Training and Validation
The paper details the training and validation process for the linear probe, highlighting normal convergence without overfitting. The probe effectively distinguishes difficulty levels in both in-distribution and out-of-distribution datasets, underscoring its robustness.
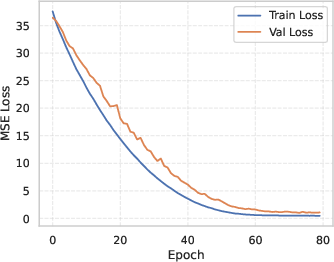
Figure 5: Probe training and validation loss.
Attention Heads Ablation Study
Ablation experiments confirm the functional specialization of attention heads concerning difficulty perception. By manipulating these heads, the study demonstrates the impact on perceived problem difficulty, providing causal evidence for attention head specificity.
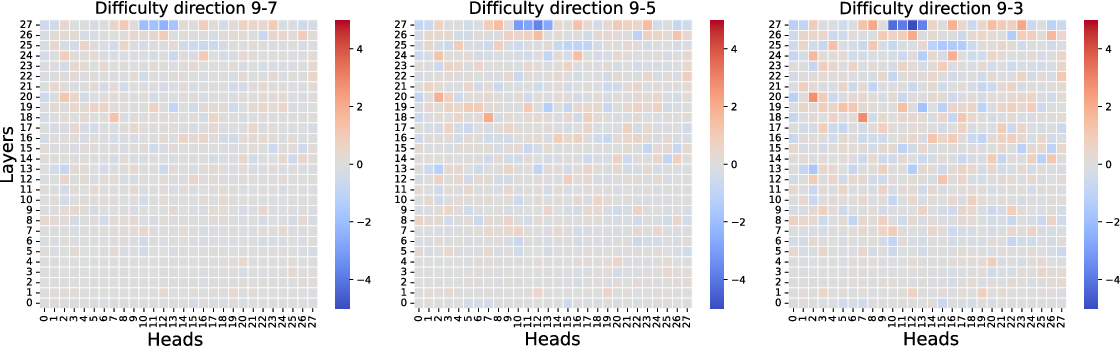
Figure 6: Qwen2.5-7B-Instruct attention head pattern recognition results.
Case Study: Perception vs. Entropy
Token-level analysis reveals discrepancies between difficulty perception and entropy during inference. While entropy often serves as a proxy for uncertainty, it does not consistently align with perceived difficulty, indicating the need for more nuanced measures in adaptive reasoning.
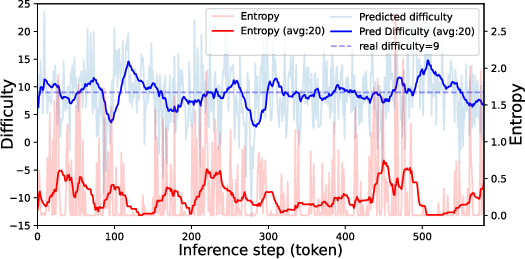
Figure 7: In the inference of a difficult math question (9.0), the change of entropy and difficulty perception.
Conclusion
The paper successfully uncovers mechanisms of difficulty perception within LLMs, suggesting potential applications in adaptive reasoning and automatic annotation. Future research may explore the influence of pre-training and distillation on difficulty perception capabilities.
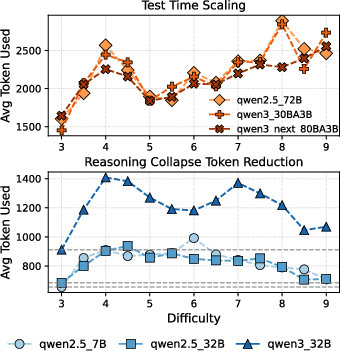
Figure 8: Reasoning Collapse Token Reduction.
Limitations and Future Work
Open questions remain regarding the universality of difficulty perception across different model architectures and their application in RL reward systems. Further exploration could lead to more efficient curriculum learning models by leveraging perceived difficulty.
Ethical Considerations
The study emphasizes responsible usage of LLMs and their attention manipulation methods, advocating against malicious applications while promoting research insights that enhance understanding of model capabilities.

