- The paper demonstrates that LLMs excel in abstract formulation but are hindered by arithmetic computation.
- It introduces a disentangled evaluation framework that separately assesses abstraction and computation using datasets like GSM8K and SVAMP.
- The study uncovers an abstract-then-compute mechanism in models such as Llama-3, providing insights for future LLM design improvements.
Introduction
The paper "Can LLMs Reason Abstractly Over Math Word Problems Without CoT? Disentangling Abstract Formulation From Arithmetic Computation" explores the capabilities of LLMs in solving mathematical word problems without relying on Chain-of-Thought (CoT) prompting.
Mathematical reasoning is a critical measure of LLMs, yet standard evaluations often conflate the ability to abstractly formulate relationships from word problems with the ability to perform arithmetic computations. Through disentangled evaluation on datasets like GSM8K and SVAMP, the paper reveals that final-answer accuracy is primarily limited by arithmetic computation rather than abstract formulation. It also introduces an abstract-then-compute mechanism identified within Llama-3 and Qwen2.5 models, demonstrating that problem abstractions are processed before computation within a single forward pass.
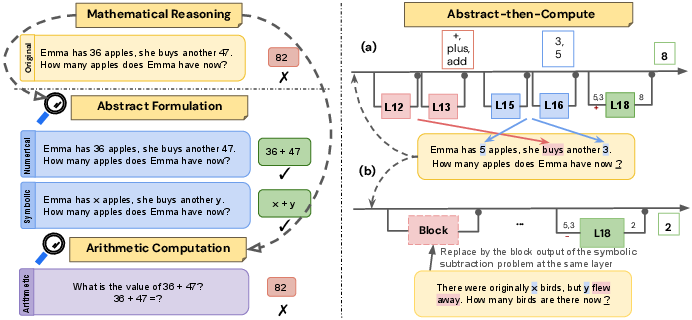
Figure 1: Left: Disentangled evaluation framework illustrating the separation between abstract formulation and arithmetic computation. Right: Abstract-then-Compute Mechanism in Llama-3 8B.
Methodology
Evaluation Framework
The authors introduce a framework to separately evaluate abstract formulation and arithmetic computation, allowing for discrete measurement of each sub-skill.
The evaluation measures:
- Abstract Formulation (Abstraction): Captures the ability to translate a problem into mathematical relationships.
- Arithmetic Computation (Computation): Concerns the execution of calculations to derive the final answer.
The models were tested under various configurations:
- Symbolic Abstraction: Using symbolic representations like x+y.
- Numerical Abstraction: Using concrete numbers without performing calculations.
- Arithmetic Computation: Execution of fully specified expressions.
Results indicate that models perform better on abstraction tasks than on computation tasks, challenging the implication that poor final-answer accuracy signifies reasoning limitations.
Results
Evaluation Results Without CoT
Disentangled evaluation shows that LLMs exhibit stronger capabilities in abstraction, even when CoT is not employed, suggesting computations are the main bottleneck in achieving high final-answer accuracy.
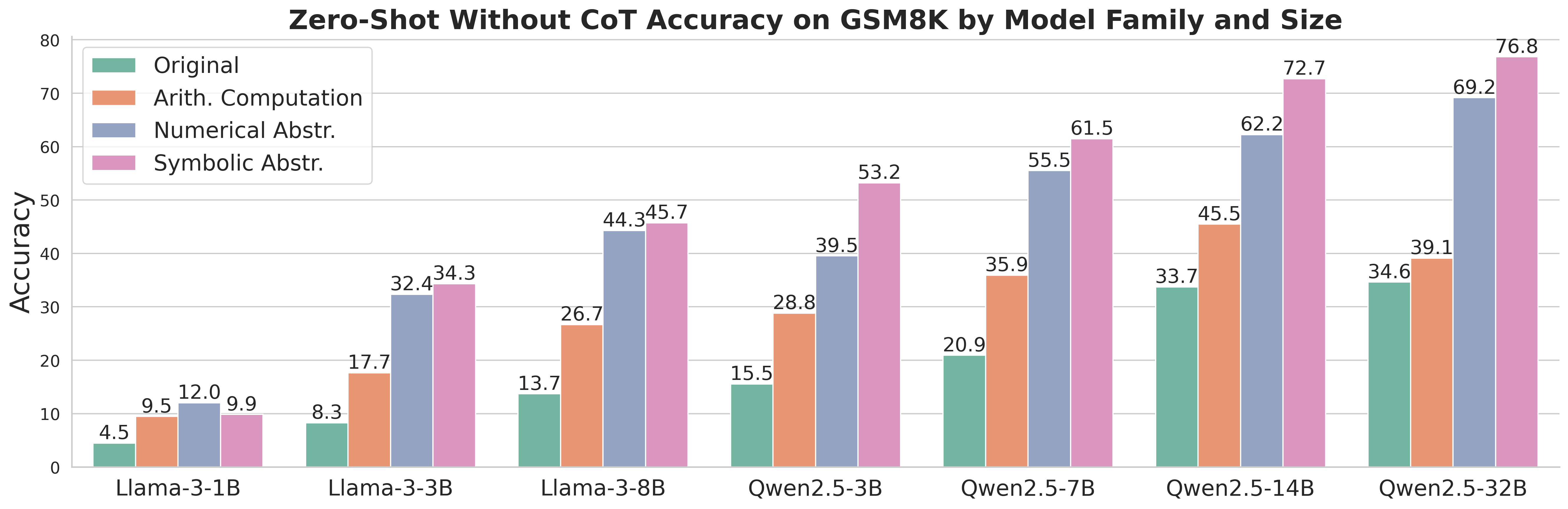
Figure 2: Model zero-shot without CoT performance on GSM8K indicates superior abstraction performance compared to arithmetic computation.
Impact of CoT
While CoT prompting significantly enhances computation performance, its effect on abstraction is limited. For instance, CoT yields substantial gains in arithmetic computation (e.g., +62.8%), yet improvements in abstraction are modest (e.g., +6.7%).
(Table 1)
Table 1: CoT impact shown as accuracy difference with and without CoT for various model sizes.
Mechanistic Interpretability
The study leverages logit attribution and activation patching to uncover the internal processes within LLMs, identifying a consistent abstract-then-compute mechanism.
Abstract-Then-Compute Hypothesis
The analysis reveals that models employ a sequential processing strategy: abstraction is detected in mid-layers, followed by computation in later layers. Activation patching further confirms that the abstraction stage involves the transfer of symbols while computation primarily occurs in the MLP layers.
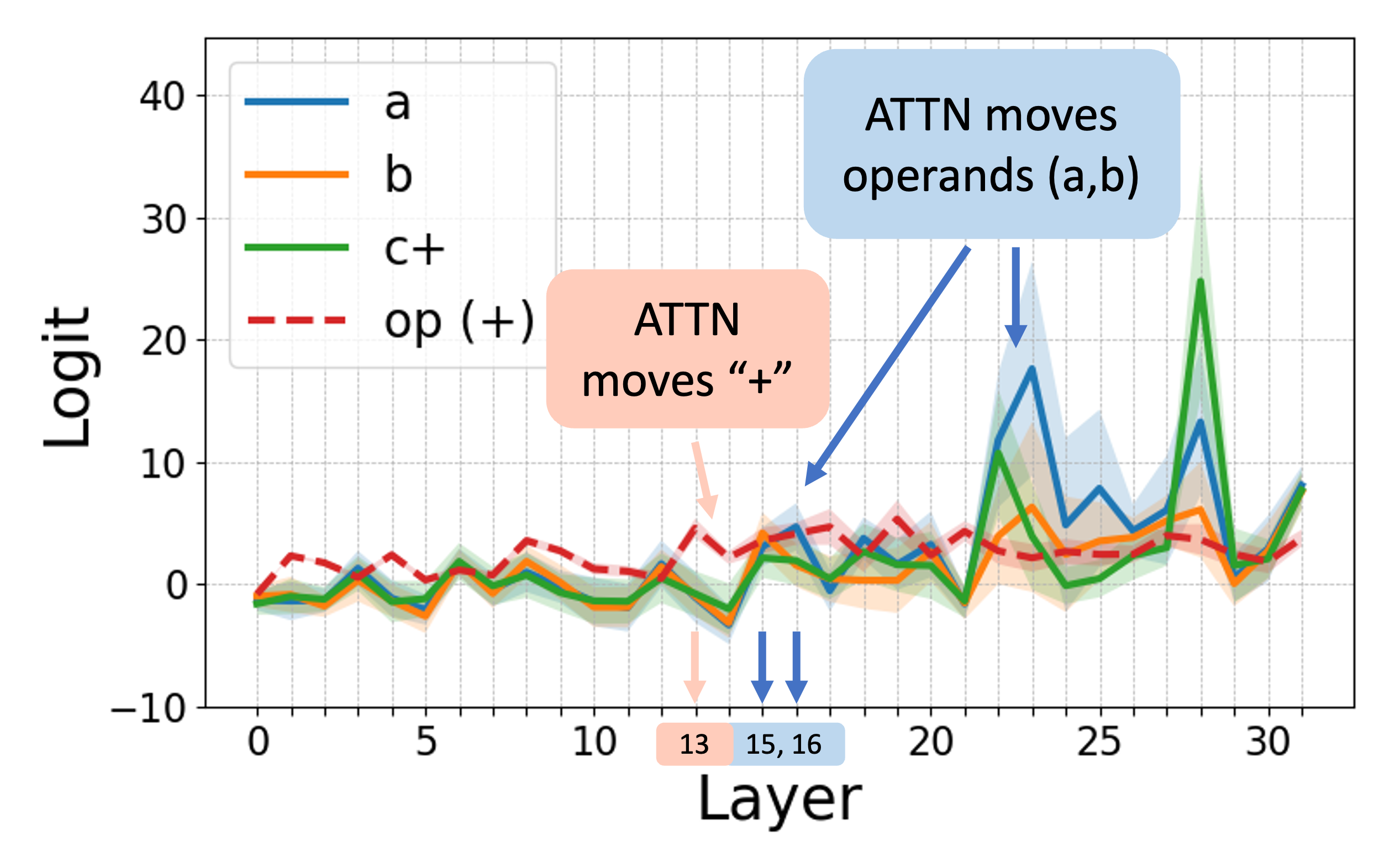
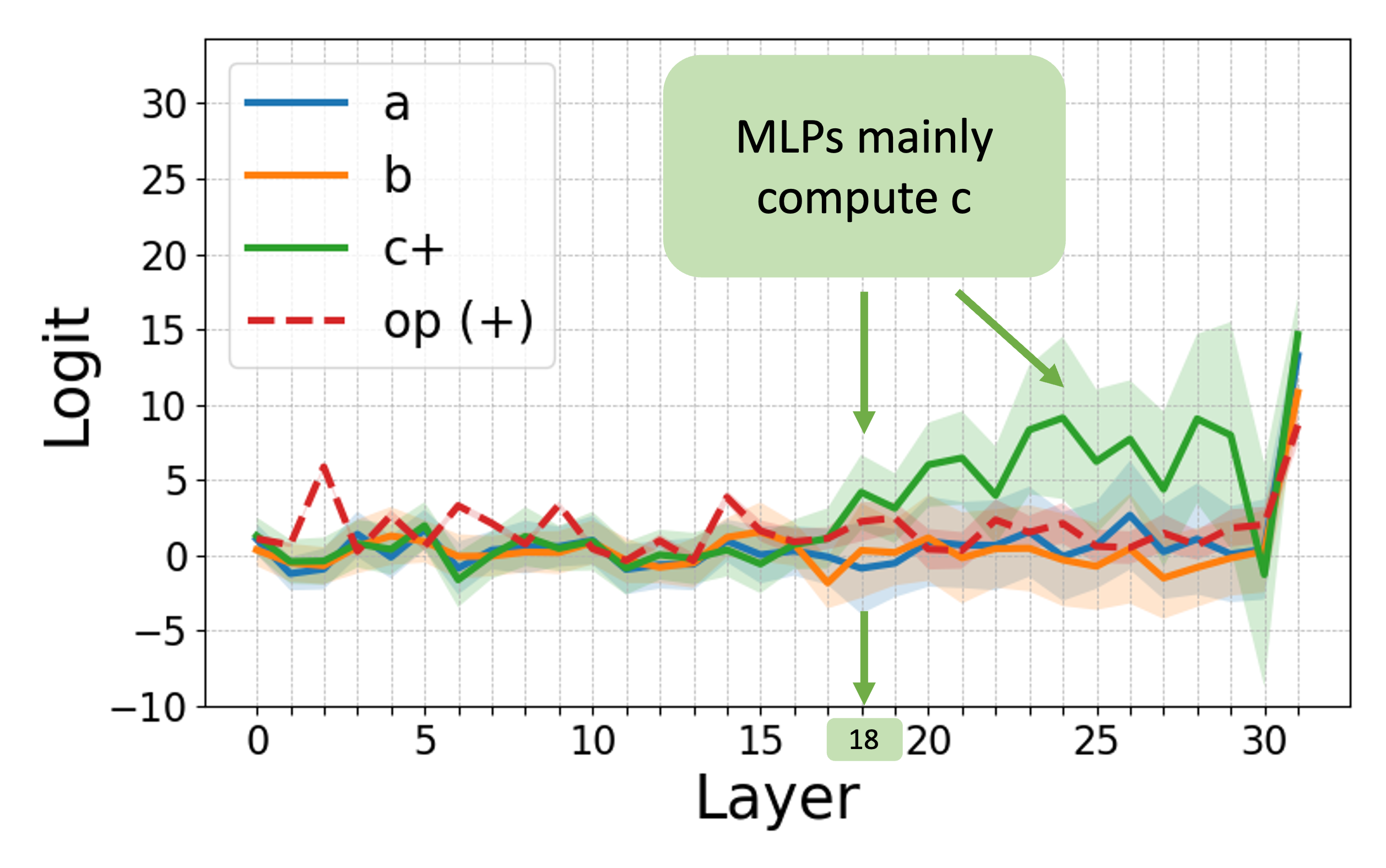
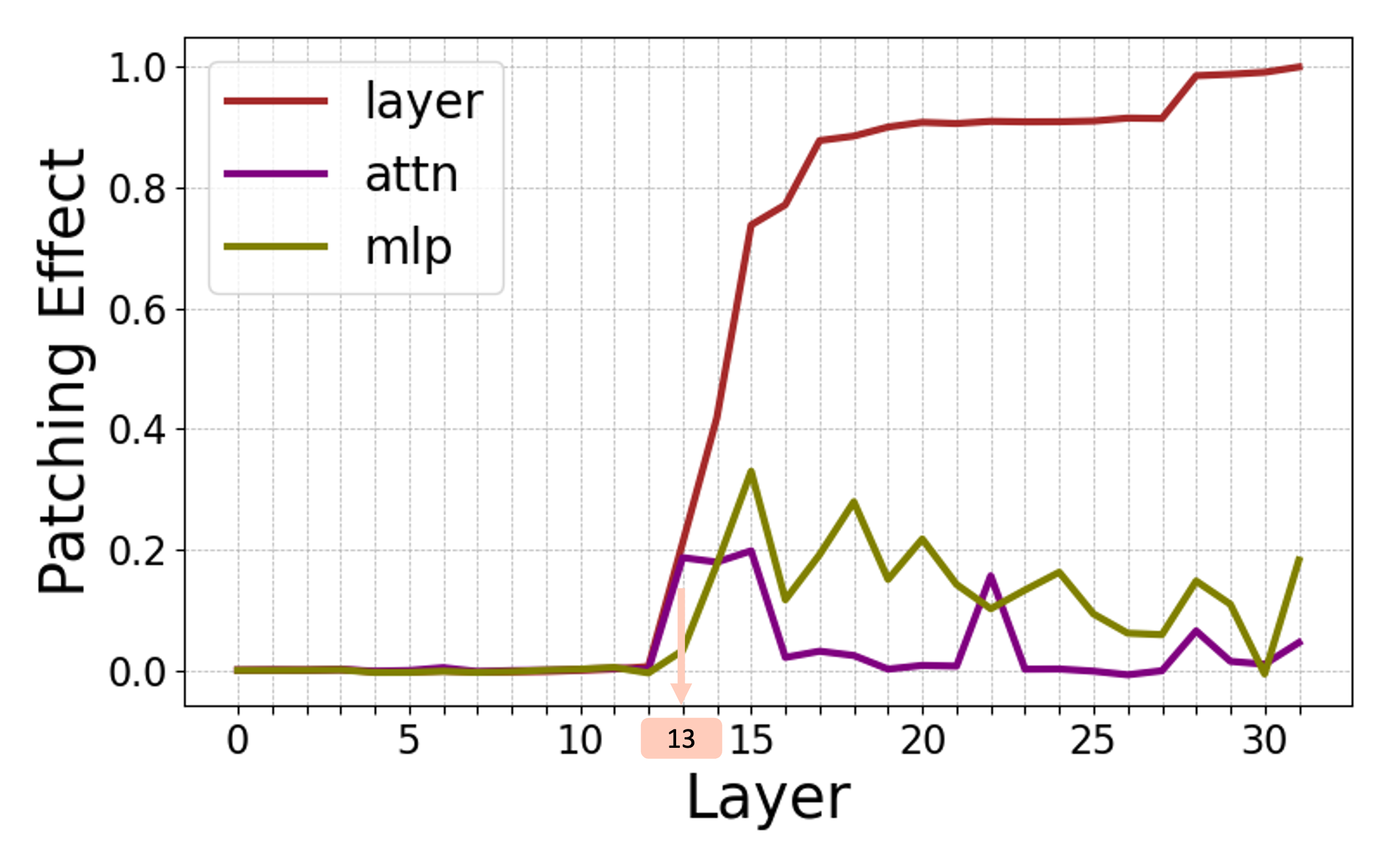
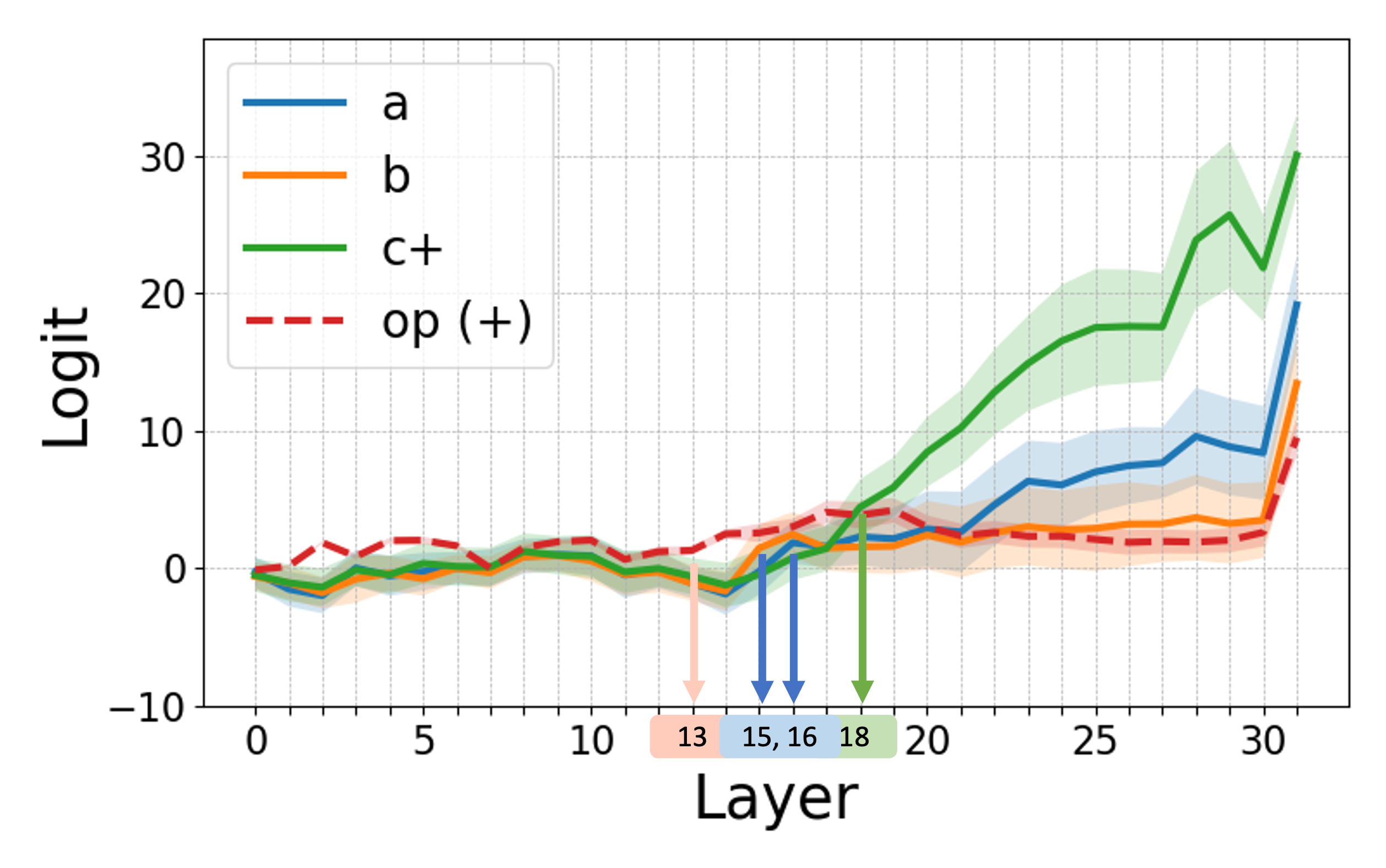
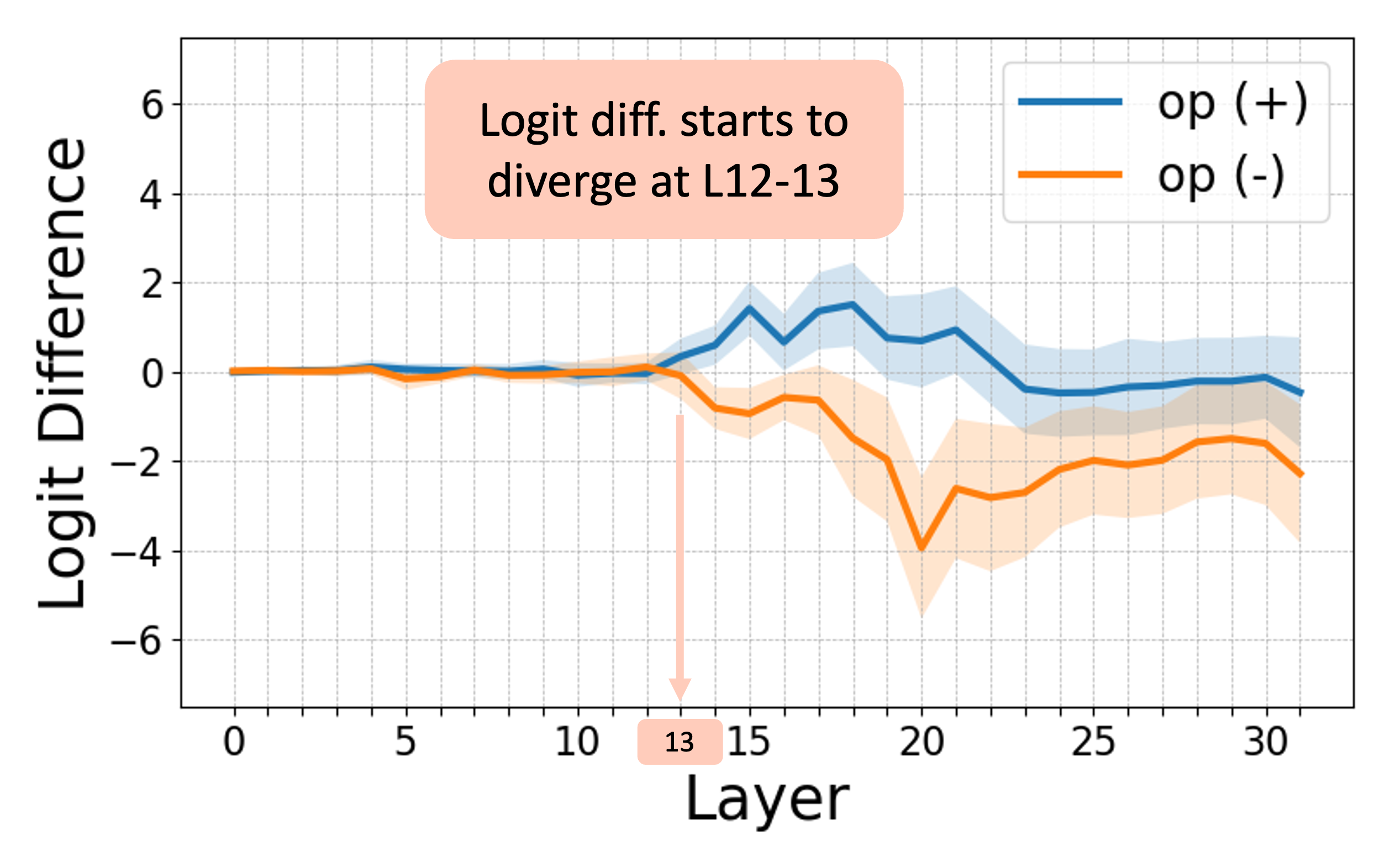
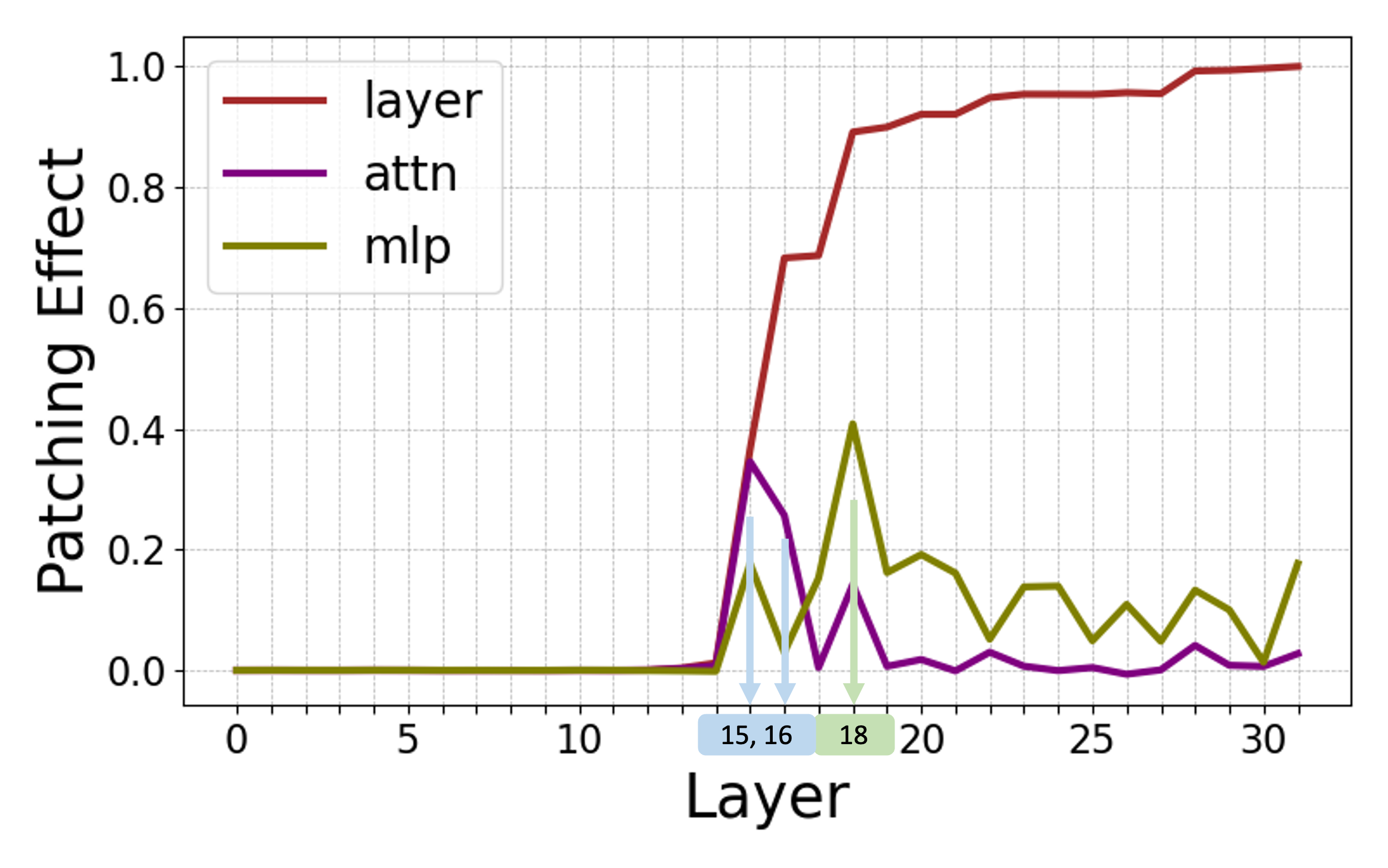
Figure 3: Internal computations visualized in Llama-3 8B for addition problems, demonstrating logit attribution and activation patching effects.
Cross-Prompt Patching
Experiments validate the transferability of abstraction across different prompt forms, demonstrating a template-invariant ability to adapt symbolic abstractions to numerical contexts, further supporting the sequential processing hypothesis.
Conclusion
The paper argues that disentangled evaluation provides a more precise assessment of LLM capabilities, particularly emphasizing the need for improvements in computational skills rather than abstract reasoning. It suggests a shifting narrative where models possess substantial reasoning abilities, constrained by their arithmetic limitations.
This work has implications for the design and evaluation of future LLMs, advocating for frameworks that isolate and independently evaluate abstraction and computation capabilities.
Future Work
Extending this methodology to multi-step reasoning tasks and exploring its applicability across diverse linguistic contexts represents a rich avenue for future research. Additionally, further insights into component-specific roles within LLM architecture could inform targeted enhancements in model design.

