- The paper presents a novel hyperdimensional probe that decodes LLM embeddings by mapping them into VSA-encoded concept spaces, overcoming limitations of DLA and SAE methods.
- Methodology integrates clustering, k-means dimensionality reduction, and a neural VSA encoder to efficiently extract key latent concepts from diverse analogies.
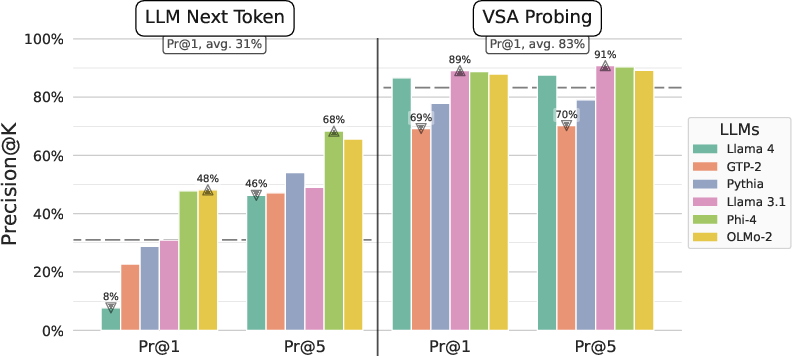
- Key experiments demonstrate up to 83% average probing accuracy, highlighting the probe’s superiority in extracting structured representations compared to token-based methods.
Hyperdimensional Probe: Decoding LLM Representations via Vector Symbolic Architectures
Introduction and Motivation
The paper introduces Hyperdimensional Probe, a novel paradigm for decoding latent representations in LLMs by leveraging Vector Symbolic Architectures (VSAs). The motivation stems from the limitations of existing interpretability methods—Direct Logit Attribution (DLA) and Sparse Autoencoders (SAEs)—which are constrained by output vocabulary and ambiguous feature naming, respectively. The proposed approach integrates symbolic representation principles with neural probing, enabling projection of the LLM residual stream into a controlled, interpretable concept space via VSA encodings. This hybrid probe aims to combine the disentangling capabilities of SAEs with the interpretability of supervised probes, while overcoming the vocabulary dependence of DLA.
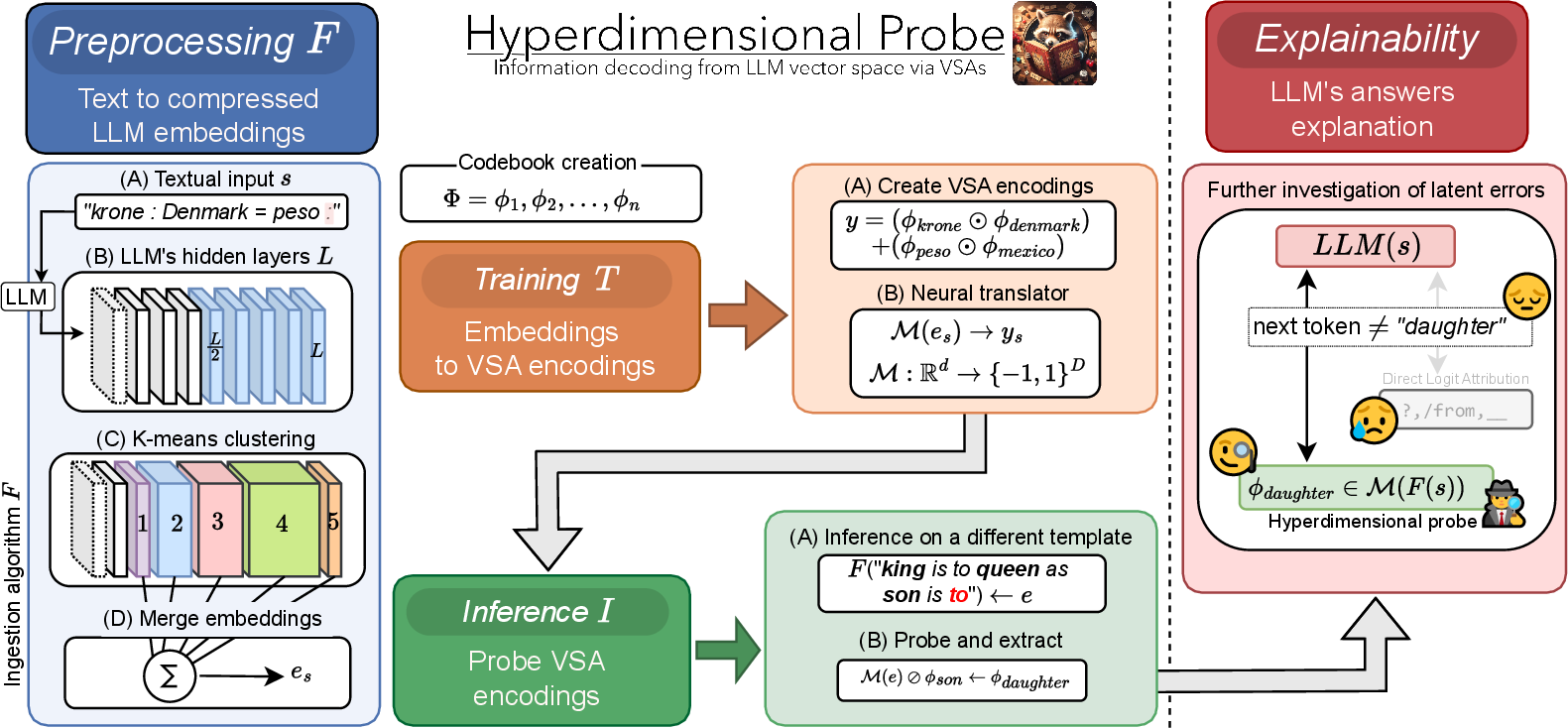
Figure 1: The Hyperdimensional Probe pipeline: compressing LLM neural representations, mapping them to VSA encodings, and extracting concepts via hypervector algebra for error analysis.
Methodology
Vector Symbolic Architectures and Hypervector Algebra
VSAs represent entities as nearly orthogonal random vectors in high-dimensional space, supporting compositionality through binding (Hadamard product) and bundling (element-wise sum). The MAP-Bipolar architecture is adopted, with codebooks mapping concepts to bipolar hypervectors. This enables encoding and retrieval of exponentially many distinct concepts, with cosine similarity as the primary metric for evaluation.
Pipeline Overview
- Corpus Construction: A synthetic dataset of analogies is generated, spanning factual, semantic, morphological, and mathematical domains. Each analogy is formatted as key-value pairs, e.g., "Denmark:krone = Mexico:peso".
- Input Representation: Concepts are mapped to hypervectors via the codebook. Input sentences are encoded by binding keys to values and bundling the results, maintaining the bipolar domain.
- LLM Embedding Processing: Textual inputs are fed to autoregressive transformers. The residual stream embeddings from the last token and the latter half of layers are extracted. Dimensionality reduction is performed via k-means clustering and sum pooling, reducing computational cost and redundancy.
- Neural VSA Encoder: A shallow, three-layer MLP (55M–71M parameters) is trained to map compressed LLM embeddings to VSA encodings. The model is optimized with BCE loss and MSE regularization, outputting bipolar vectors.
- Concept Extraction: The unbinding operation is used to retrieve embedded concepts from VSA encodings, enabling flexible querying without prior assumptions on the number of concepts.

Figure 2: Experimental setup with textual inputs exhibiting syntactic structures unseen during training.
Experimental Results
Experiments are conducted on six open-weight LLMs (355M–109B parameters) using the synthetic analogy corpus. The evaluation focuses on next-token prediction (precision@k) and the ability of the probe to extract target concepts from latent representations.
Error Analysis and Conceptual Richness
The probe reveals that blank representations are most frequent in mathematical analogies (88%) and semantic hierarchies (39%), while linguistic and factual analogies yield richer embeddings. In cases where DLA fails to extract concepts, the VSA-based probe successfully retrieves key-target pairs in 57% of instances, highlighting its superior abstraction capabilities.
Question Answering Extension
The methodology is extended to the SQuAD dataset for extractive QA. Input features are derived from lexical semantics using WordNet and DBpedia. The probe achieves a test-set cosine similarity of 0.44 and binary accuracy of 0.70 (Llama3.1). Analysis of concept drift shows that LLM failures correlate with decreased focus on question-related concepts after text generation, while answer-related concepts remain stable or slightly increase in error cases.

Figure 4: Concepts extracted before and after LLM text generation, distinguishing between question and answer features; red indicates failure cases.
Comparative Analysis
Direct comparison with DLA demonstrates that the hyperdimensional probe is less constrained by output vocabulary and can extract more abstract, structured features. DLA yields no concepts in 30% of analogies, while the VSA-based probe extracts relevant concepts in the majority of these cases. SAE-based methods are not directly compared due to their reliance on post hoc feature naming and single-layer analysis.
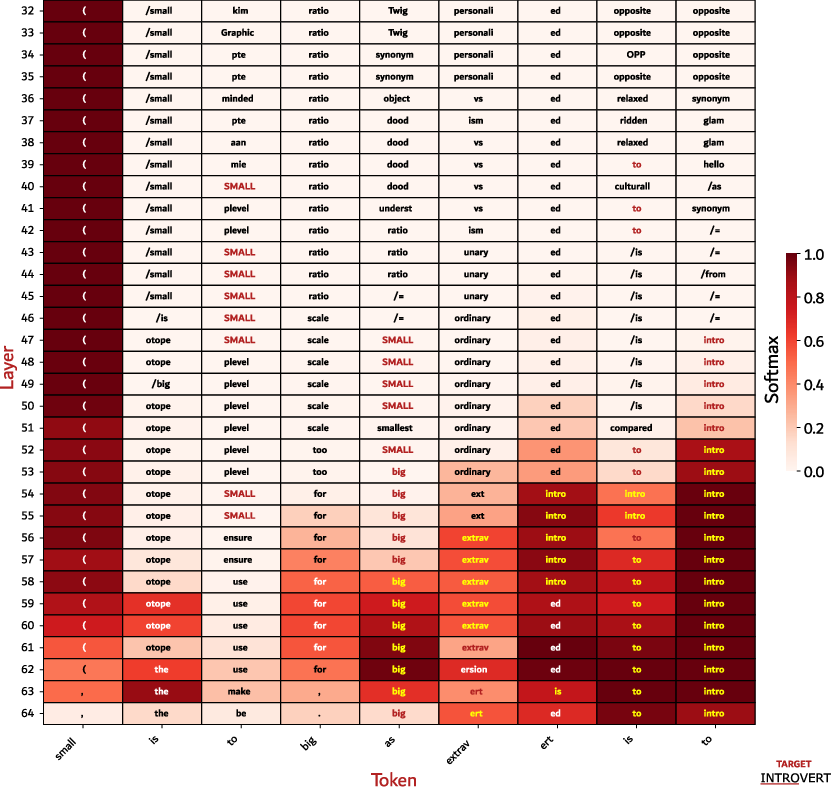
Figure 5: Raw outputs from DLA on OLMo-2 for a sampled analogy, illustrating the limitations of token-based probing.
Implementation Considerations
Theoretical and Practical Implications
The empirical results support the hypothesis that LLM embeddings can be accurately represented and decoded using VSAs. The hyperdimensional probe enables structured, interpretable extraction of latent concepts, facilitating error analysis and model debugging. The approach is robust to model size, embedding dimension, and input domain, and is computationally lightweight.
Theoretically, the work advances the understanding of distributed representations in transformers, providing evidence for the linear representation hypothesis and the utility of hyperdimensional algebra in mechanistic interpretability. Practically, it offers a scalable, model-agnostic tool for probing and analyzing LLMs, with potential applications in bias detection, toxicity analysis, and multimodal reasoning.
Future Directions
Potential avenues for future research include:
- Automated concept set generation and dynamic codebook expansion.
- Integration with unsupervised feature discovery to reduce reliance on predefined concepts.
- Application to real-world tasks such as bias and toxicity detection, and further exploration of multimodal probing.
- Investigation of layer-wise dynamics and representation drift across diverse architectures and training regimes.
Conclusion
The Hyperdimensional Probe paradigm demonstrates that VSAs provide a powerful framework for decoding and interpreting LLM latent representations. By combining symbolic compositionality with neural probing, the approach overcomes key limitations of existing methods, enabling extraction of human-interpretable, structured concepts from high-dimensional model states. The methodology is efficient, generalizable, and offers new insights into the internal mechanisms of LLMs, with broad implications for interpretability, model analysis, and downstream applications.