- The paper demonstrates a clear dissociation between language and arithmetic representations in LLMs through linear classifiers and GDV metrics.
- It uses geometric analysis to map LLMs’ hidden layers, revealing perfect separation in most layers after the initial embedding.
- The study identifies challenges in integrating language and arithmetic reasoning in complex tasks like math word problems, suggesting future research directions.
Representational Dissociation of Language and Arithmetic in LLMs
The paper "On Representational Dissociation of Language and Arithmetic in LLMs" (2502.11932) explores an emerging question in the field of NLP: whether LLMs demonstrate a representational dissociation between language and arithmetic, akin to the dissociation observed in human brain activation patterns during linguistic and non-linguistic reasoning tasks.
Introduction
The longstanding philosophical inquiry into the association between language ability and non-linguistic thinking capabilities, such as logical reasoning, has found recent support in neuroscience. Studies have showcased distinct brain activity patterns for linguistic and non-linguistic reasoning tasks, suggesting a potential dissociation between these cognitive domains. Motivated by this evidence, this paper investigates whether similar dissociations exist within the internal representations of LLMs, using a geometric analysis approach. The study focuses on separating simple arithmetic skills and general language input to understand how these are encoded in LLMs' representation spaces.
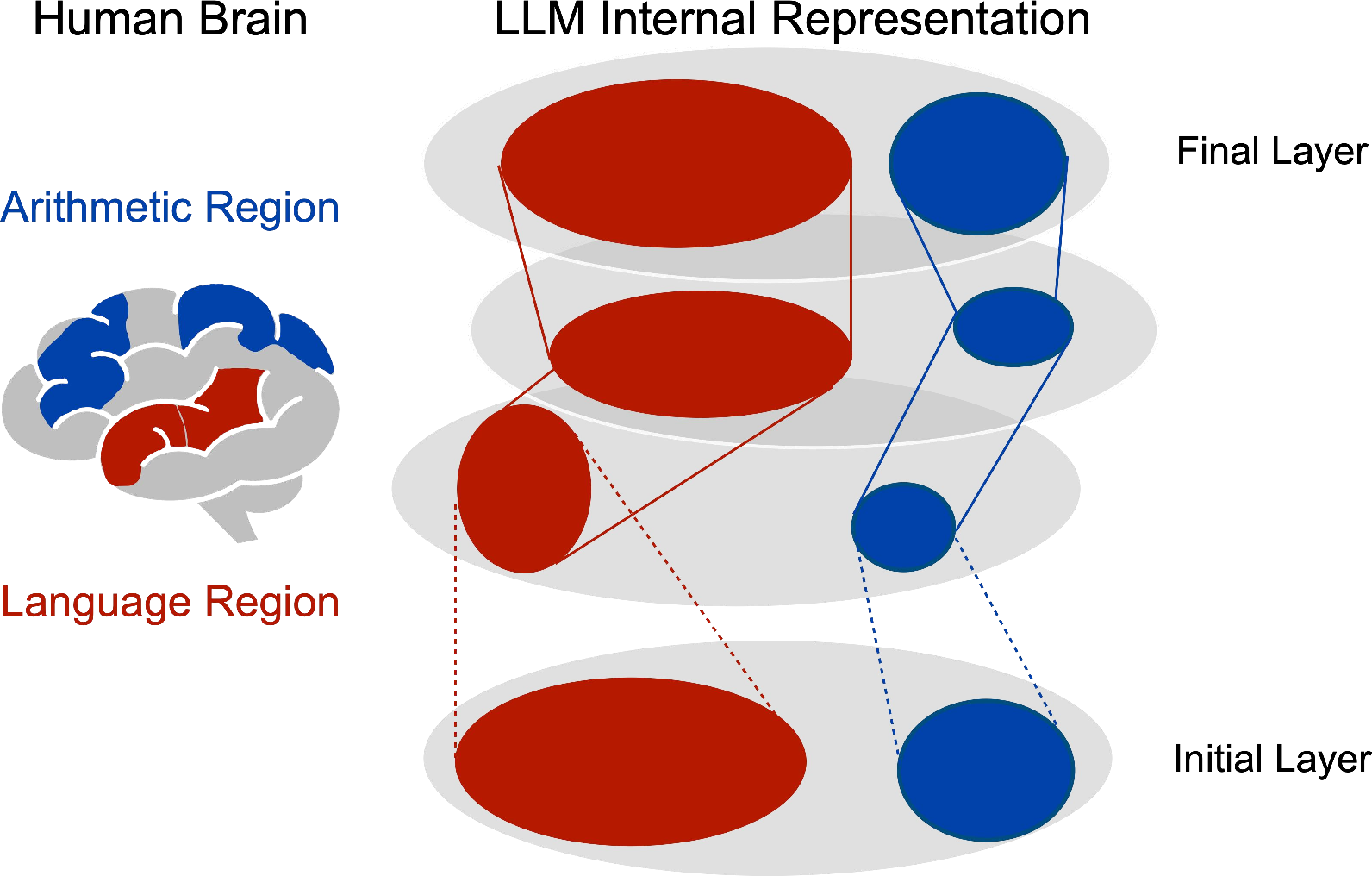
Figure 1: An illustration of our perspective to investigate the language-arithmetic representational dissociation within LMs — if brain imaging renders that the human brain activation patterns are different against linguistic and non-linguistic reasoning stimuli, what about LLMs?
Methodology
Problem Setting
The investigation targeted the spatial distribution of language and arithmetic inputs in LLM's internal representation space. This was conducted using two principal methods: a linear classifier and a cluster separability test known as the generalized discrimination value (GDV).
Linear Classification
A linear SVM classifier was utilized to differentiate between language and arithmetic representations based on representations from the LLM's hidden layers. The classifier took representations from the final token of sequences from both language and arithmetic input data sets and aimed to predict their associated classes using large-margin objective criteria in a 5-fold cross-validation setting.
Cluster Separability Test
The GDV score was used to measure the distances between clusters of representations within the LLM's internal space. This metric helps determine how separated language and arithmetic representations are by comparing normalized distances between intra-cluster and inter-cluster distances. A highly negative GDV score corresponds to well-separated clusters.
Experiments and Results
Experiments conducted with the Gemma-2-9b-it, Llama-3.1-8B-Instruction, and Qwen2.5-7B-Instruct models revealed a clear and consistent separation between language and arithmetic regions in their internal representation spaces. Notably, these regions were perfectly distinct from the first layer beyond the embedding layer, as evidenced by 100% classification accuracy using linear classifiers.
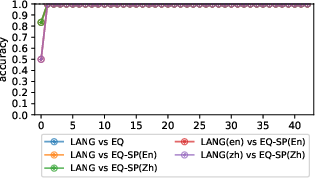
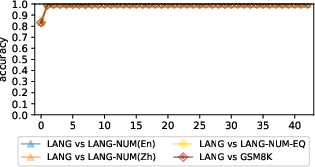
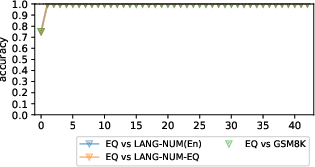
Figure 2: Liner classification results of gemma-2-9b-it.
Additionally, GDV scores calculated between pertinent cluster pairs demonstrated pronounced dissociation across most layers, with negative scores indicating the absence of overlap between language and arithmetic clusters.
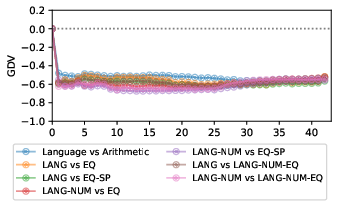
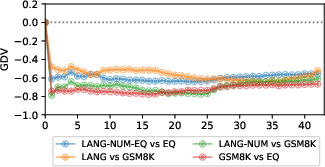
Figure 3: The GDV between clusters of interest (for Gemma-2). "Language vs. Arithmetic" is the distance between LangoplusLangNum and EqoplusEqSp.
An exception arose with combined language-arithmetic tasks, such as math word problems, which formed an independent cluster. These complex stimuli did not exist within language or arithmetic clusters and were, instead, always predicted to belong to language regions by the linear classifiers.
Implications and Future Directions
The findings provide preliminary evidence that LLMs may exhibit a dissociation between language processing and simple arithmetic reasoning, similar to human brain functions. However, the study also highlighted a potential limitation in LLMs: their inability to integrate linguistic and arithmetic reasoning when handling complex tasks such as math word problems. This distinct separation in representation implies that LLMs might not have a unified region for arithmetic reasoning, which contradicts the intuitive expectation for LLMs to unify complex task processing seamlessly.
This investigation opens the path for further exploration into the geometrical properties of LLMs' internal representational spaces, more sophisticated causal analyses, and the examination of LM-brain alignment within different cognitive frameworks. Future work should focus on exploring alternative methods of distinguishing task-specific LLM subspaces, as well as examining the cognitive processes in human reasoning to gain deeper insights into the language-thought dissociation in both human brains and artificial models.
Conclusion
This research lays the groundwork for examining the representational dissociation of language and arithmetic abilities in LLMs. It draws parallels to neuroimaging studies that demonstrate distinct activation for linguistic and non-linguistic stimuli in the human brain. LLMs encode language and arithmetic operations in distinct regions, aligning with the notion of a dissociation of these abilities. Future research is needed to further explore the geometry of LLM representational spaces and draw insights from human cognitive neuroscience to better understand LLMs' capacities for integrated reasoning tasks.