- The paper introduces DCL4KT+LLM, integrating contrastive learning with difficulty estimation to improve KT performance.
- It leverages pre-trained LLMs and fine-tuning strategies to predict difficulty for unseen questions, validated by enhanced AUC and RMSE scores.
- The approach combines traditional CTT with advanced language models, providing scalable insights for real-time educational systems.
Difficulty-Focused Contrastive Learning for Knowledge Tracing with a LLM-Based Difficulty Prediction
The paper "Difficulty-Focused Contrastive Learning for Knowledge Tracing with a LLM-Based Difficulty Prediction" explores an innovative approach to enhance the performance of Knowledge Tracing (KT) models through the integration of difficulty-focused contrastive learning and a LLM-based framework for difficulty prediction. The proposed model, DCL4KT+LLM, aims to accurately predict students' learning progress by analyzing interactions with educational content while incorporating the complexity of the questions and concepts as critical features.
Background and Motivation
Role of Difficulty in Knowledge Tracing
In the domain of educational technology, the difficulty of questions and concepts is acknowledged as a pivotal factor impacting learning outcomes and KT model performance. Traditional methods, such as Classical Test Theory (CTT) and Item Response Theory (IRT), are utilized for difficulty estimation. This research leverages CTT for computing difficulty levels and dynamically employs this information within a contrastive learning framework to enhance model accuracy and reliability.
Contrastive Learning Approaches
Contrastive learning has gained prominence in various fields, including computer vision and NLP, by effectively distinguishing between similar and dissimilar data points. The incorporation of contrastive learning to incorporate difficulty metrics into KT models represents a novel translation of these ideas, aiming to improve the model's ability to predict student interactions with educational materials.
Methodology
DCL4KT+LLM Model Architecture
The architecture of the DCL4KT+LLM model consists of embedding layers for positive and negative difficulty values, encoding layers based on the MonaCoBERT model, and a contrastive learning framework designed to utilize these embeddings effectively.
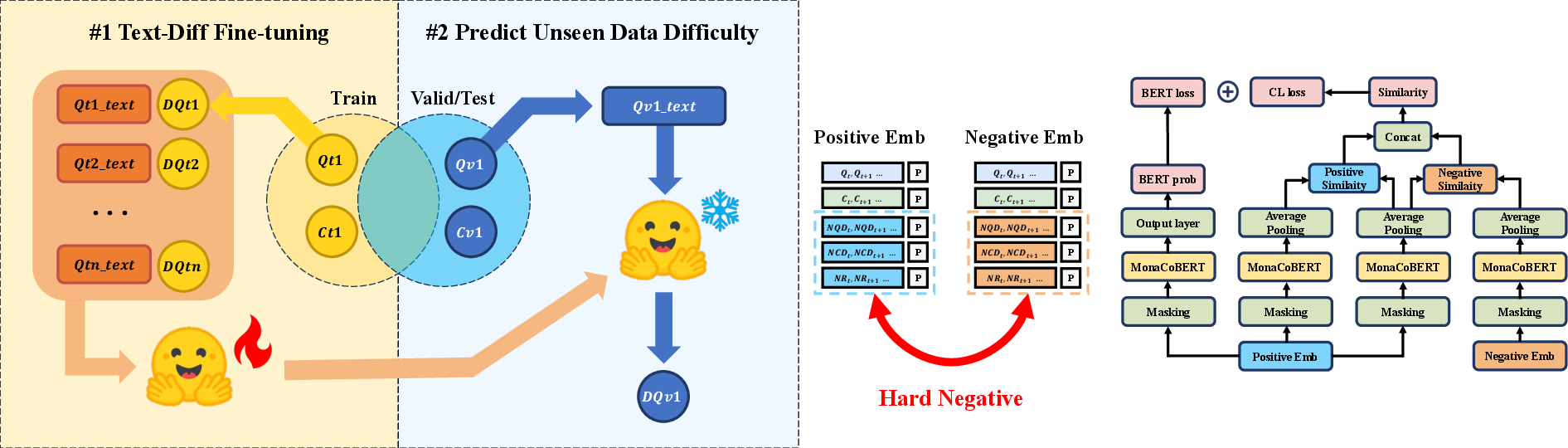
Figure 1: Architectures of DCL4KT+LLM. Left: LLM-based difficulty prediction framework in KT. Right: Whole architecture of DCL4KT+LLM.
Contrastive Learning Framework
The contrastive learning framework is uniquely designed to use difficulty embeddings, which highlight the distinctiveness of difficulty levels among question-answer interactions. This model employs a composite loss function that balances binary cross-entropy (BCE) and contrastive loss, allowing better alignment of model predictions with actual student performance.
LLM-based Difficulty Prediction
The novel contribution of this research is the use of LLMs for predicting the difficulty of questions and concepts that do not appear in the training set. Pre-trained models like KoBERT are fine-tuned using difficulty metrics extracted from training data, facilitating the prediction of difficulties for unseen interactions during validation and testing.
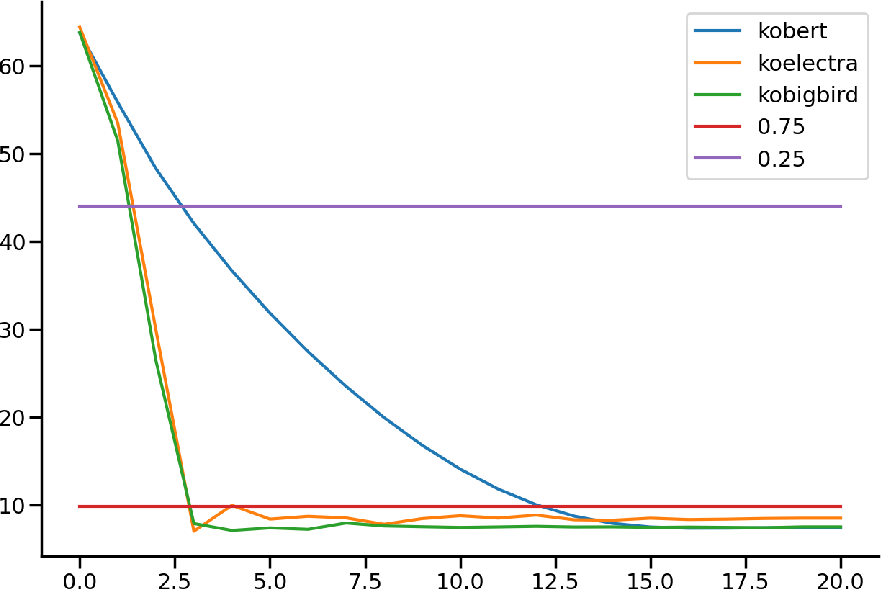
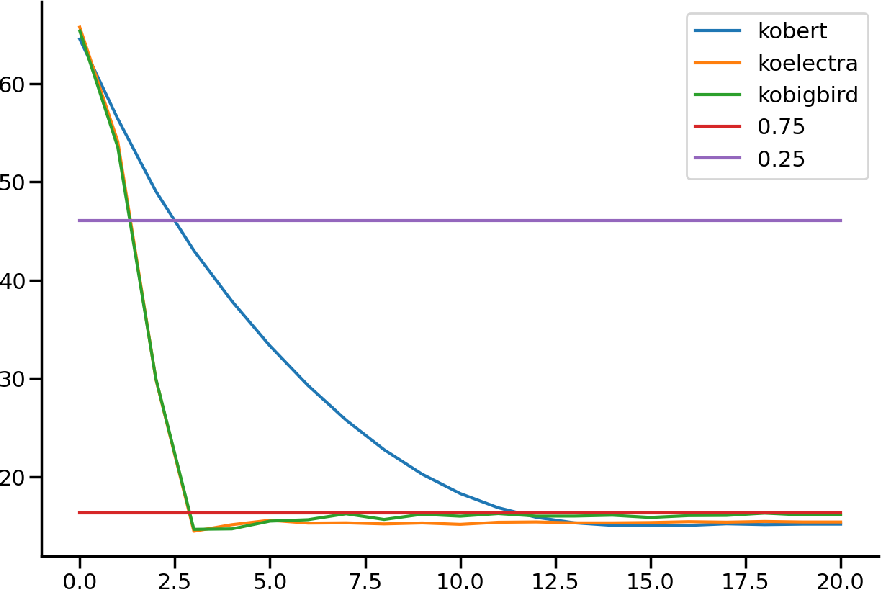
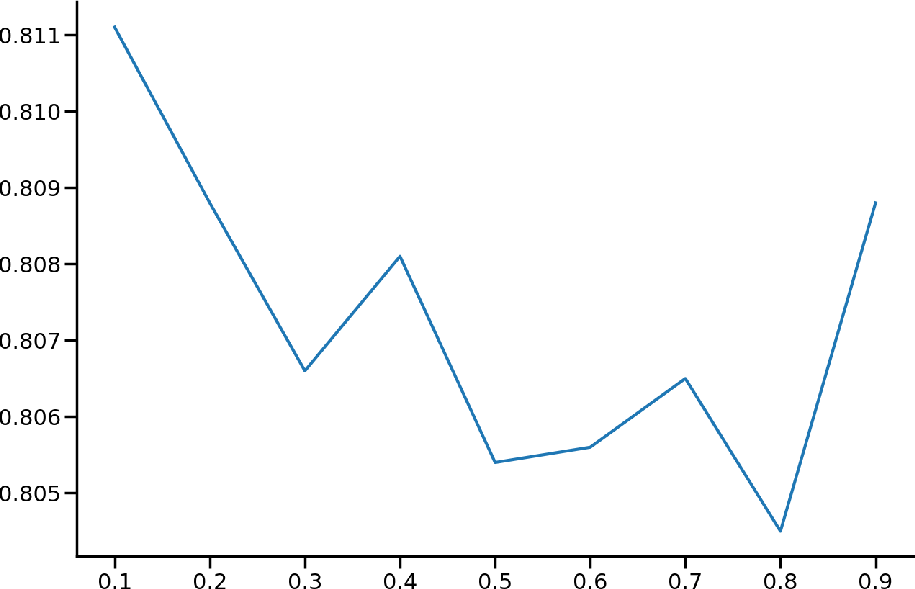
Figure 2: Left: Concept difficulty prediction. Center: Question difficulty prediction between LLMs. Right: Relationship between contrastive learning ratio and model's AUC score.
Results
The evaluation of the proposed model, DCL4KT, using benchmark datasets like ASSISTment09, Algebra05, and EdNet reveals significant improvements in AUC and RMSE scores compared to baseline models such as DKT, DKVMN, and CL4KT. The effect of data augmentation strategies, evaluated separately, also indicates enhanced performance when integrated with the proposed methodology.
Discussions
Difficulty-Focused Learning
Difficulty-focused contrastive learning showcases a robust mechanism for improving KT model predictions. The findings suggest that integrating difficulty properties within this framework significantly refines the capability to model student interactions accurately.
LLM Efficiency
LLMs demonstrate proficiency in projecting difficulty levels using textual data, offering a flexible tool for real-time educational systems which frequently introduce new content. Through fine-tuning methodologies, LLMs can align with ground-truth difficulty levels, thereby optimizing KT predictions.
Future Considerations
The intersection of language features and question difficulty is an avenue that warrants further exploration. Understanding the linguistic indicators of difficulty may facilitate the development of more nuanced educational technologies that adapt to diverse learning contexts.
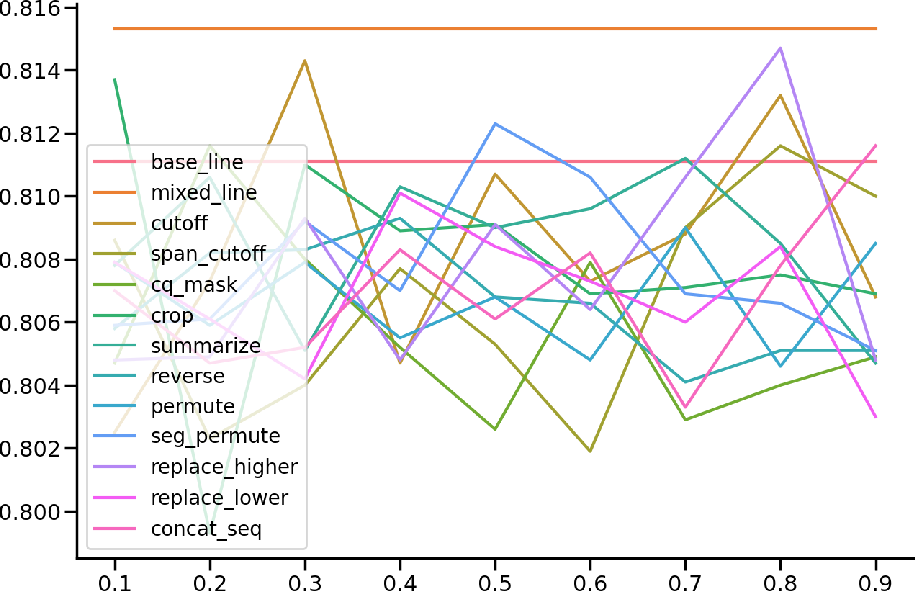
Figure 3: Comparing data augmentation strategies. The x-axis is data augment probabilities and y-axis means AUC score. The baseline is non-augmented DCL4KT.
Conclusion
"DCL4KT+LLM" advances the field of knowledge tracing by integrating contrastive learning focused on question difficulty and leveraging LLMs for difficulty prediction. The study confirms that LLMs can effectively replace heuristic and human-designed difficulty parameters, introducing significant enhancements to KT models. Further investigations into the linguistic components influencing difficulty levels could lead to expanding these frameworks into broader educational contexts.

