Think Right: Learning to Mitigate Under-Over Thinking via Adaptive, Attentive Compression
Abstract: Recent thinking models solve complex reasoning tasks by scaling test-time compute, but this scaling must be allocated in line with task difficulty. On one hand, short reasoning (underthinking) leads to errors on harder problems that require extended reasoning steps; but, excessively long reasoning (overthinking) can be token-inefficient, generating unnecessary steps even after reaching a correct intermediate solution. We refer to this as under-adaptivity, where the model fails to modulate its response length appropriately given problems of varying difficulty. To address under-adaptivity and strike a balance between under- and overthinking, we propose TRAAC (Think Right with Adaptive, Attentive Compression), an online post-training RL method that leverages the model's self-attention over a long reasoning trajectory to identify important steps and prune redundant ones. TRAAC also estimates difficulty and incorporates it into training rewards, thereby learning to allocate reasoning budget commensurate with example difficulty. Our approach improves accuracy, reduces reasoning steps, and enables adaptive thinking compared to base models and other RL baselines. Across a variety of tasks (AIME, AMC, GPQA-D, BBEH), TRAAC (Qwen3-4B) achieves an average absolute accuracy gain of 8.4% with a relative reduction in reasoning length of 36.8% compared to the base model, and a 7.9% accuracy gain paired with a 29.4% length drop compared to the best RL baseline. TRAAC also shows strong generalization: although our models are trained on math datasets, they show accuracy and efficiency gains on out-of-distribution non-math datasets like GPQA-D, BBEH, and OptimalThinkingBench. Our analysis further verifies that TRAAC provides fine-grained adjustments to thinking budget based on difficulty and that a combination of task-difficulty calibration and attention-based compression yields gains across diverse tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI LLMs to “think just right.” Sometimes these models stop too early on hard problems (underthinking) or keep going long after they’ve already found the answer on easy problems (overthinking). Both mistakes hurt accuracy and waste time and computing power. The authors introduce a training method called TRAAC (Think Right with Adaptive, Attentive Compression) that helps models adjust how much they think, depending on how hard the problem is, and cut out unnecessary steps.
Key Questions the Paper Tries to Answer
- How can an AI decide when to think more and when to stop early?
- Can we remove useless parts of the AI’s reasoning without losing the important steps?
- Can a model learn to use longer reasoning only when a problem is hard, and shorter reasoning when a problem is easy?
- Will this make the model both more accurate and more efficient (fewer tokens/steps)?
How TRAAC Works (Explained Simply)
Think of the AI solving a problem like a student writing out their thought process:
- Underthinking: The student stops writing too soon and gets the hard question wrong.
- Overthinking: The student keeps writing even after they have the right answer, wasting time.
- “Adaptive thinking”: The student writes more for hard questions, less for easy ones.
TRAAC teaches this adaptive behavior using three main ideas:
1) Practice with Feedback (Reinforcement Learning)
- The model tries multiple solutions per question (these are called “rollouts,” like practice attempts).
- Each attempt gets a score based on whether the final answer is correct and how long the reasoning was.
- The model learns to prefer attempts that are correct and appropriately short.
Analogy: Imagine taking several practice shots at a basketball hoop, then learning which style of shooting works best by looking at your results.
2) Difficulty Estimation
- The model estimates how hard a question is by checking the “pass rate”: out of several attempts, how many got the right answer?
- High pass rate → probably easy
- Low pass rate → probably hard
- The model uses difficulty to decide how much to compress (shorten) its reasoning:
- Easy problems: compress more (keep only the essential steps)
- Hard problems: compress less (keep more details)
Analogy: If a puzzle seems easy because you solved it quickly several times, you only keep a short summary. If it’s hard, you keep more notes.
3) Attentive Compression (Cutting Out Unimportant Steps)
- Modern AI models use “attention,” which tells us which parts of the text the model considers most important.
- TRAAC looks at attention from a special end-of-thinking marker (</think>) back over the reasoning steps.
- Steps that get low attention are likely less useful. TRAAC removes those to shorten the reasoning without losing the key ideas.
Analogy: When editing an essay, you highlight sentences that matter and delete the ones that don’t. Attention is like your highlighter.
4) Smart Rewards (What the Model Gets Praised For)
To guide learning, TRAAC uses three rewards:
- Correctness: Highest priority—did the final answer match the solution?
- Format: Did the model output clear reasoning followed by a final answer?
- Length: Encourage shorter reasoning—but gently, so slightly longer (but still correct) answers aren’t punished too much.
Analogy: A teacher grading your work gives most points for the right answer, some points for neatness, and a small bonus for being concise—especially if the question is easy.
What Did They Find?
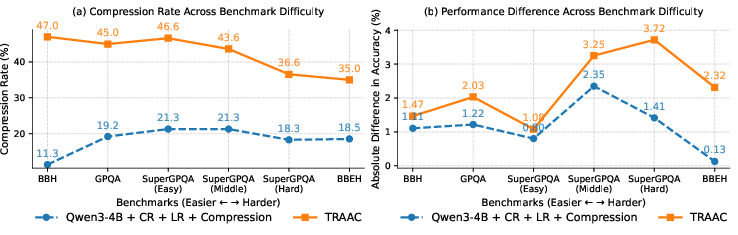
Across several benchmarks (like math contests AIME and AMC, and tough reasoning tests GPQA-D and BBEH), TRAAC consistently improved both accuracy and efficiency compared to strong baseline models.
Highlights:
- On Qwen3-4B:
- About +8.4 percentage points in accuracy on average.
- About 36.8% fewer reasoning tokens (shorter solutions).
- Compared to the best other adaptive method (AdaptThink), TRAAC still:
- Improved accuracy by about 7.9 points.
- Reduced length by about 29.4%.
- TRAAC trained on math, but also improved on non-math datasets, showing it generalizes (doesn’t just memorize one domain).
- On OptimalThinkingBench (which measures both overthinking and underthinking), TRAAC scored higher than the base models and other baselines, meaning it cut unnecessary thinking on easy tasks and avoided stopping too soon on hard ones.
- Attention-based compression worked better than:
- Randomly deleting steps, or
- Deleting steps the model felt “least confident” about.
- Adding compression only at test time (not during training) helped a bit, but training with TRAAC gave much bigger gains.
Why This Matters
- Smarter use of computing: The model thinks longer only when it needs to, saving time and energy.
- Better accuracy: By keeping more steps for hard problems, the model makes fewer mistakes.
- Practical impact: Tutors, coding assistants, and problem-solving bots become faster, cheaper to run, and more reliable.
- Scalable: TRAAC still helps even when you allow very long reasoning (it scales to bigger “thinking budgets”).
- Generalizable: Although trained on math, the approach improves reasoning across different kinds of tasks.
Simple Takeaway
TRAAC helps AI “think right” by:
- Figuring out how hard a problem is,
- Highlighting the most important parts of its reasoning,
- Cutting the fluff on easy questions,
- Keeping more detail on hard ones,
- And learning from feedback to balance accuracy and efficiency.
In short, it’s like giving the AI a smart editor and a good coach—so it doesn’t stop too early or ramble too long, and instead solves problems quickly and correctly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete directions that future research could address:
- Faithfulness of attention as an importance signal: The method assumes attention from
</think>faithfully tracks step importance. Validate across architectures and seeds, quantify when attention fails (e.g., diffuse attention, shortcut solutions), and compare to stronger attributions (e.g., leave-one-out, attention rollout, gradients, Integrated Gradients). - Sensitivity to the auxiliary “Time is up…” prompt: The compression relies on an auxiliary summarization cue to focus attention. Ablate this prompt, measure performance/efficiency sensitivity to its wording and placement, and explore prompt-free or learned mechanisms.
- Heuristic step segmentation: Steps are detected via hand-crafted special tokens/phrases. Assess robustness across models, domains, and languages; develop learned or structure-aware segmenters that do not rely on model-specific phrasing.
- Difficulty estimation by rollout pass rate: With N=8 samples, pass-rate estimates can be noisy and compute-intensive. Quantify variance, misclassification impacts, and explore low-cost single-pass predictors (e.g., entropy, early loss, self-consistency signals, verifier proxies) for both training and inference.
- Coarse difficulty binning: The easy/medium/hard bins and fixed compression rates are hand-set. Investigate continuous, learned difficulty-to-compression mappings (e.g., conditional policies, meta-learning) and problem-specific schedules.
- Reward shaping stability and credit assignment: Length reward is granted only when answers are correct, which may bias learning and hinder exploration. Analyze training dynamics, alternative credit assignment (e.g., per-step shaping, trajectory-level baselines), and safety against reward hacking (e.g., intentionally lowering pass rate to relax compression).
- Compute and memory overhead: Computing layer-/head-averaged attention over 10k-token traces and regenerating answers adds training/inference cost. Provide wall-clock, GPU memory, and energy measurements, and amortization analyses versus efficiency gains.
- Inference-time adaptivity: The test-time variant uses a fixed compression rate (no difficulty estimation). Develop robust, low-overhead inference-time difficulty estimators and adaptive controllers that do not require multiple rollouts.
- Generalization beyond verifiable tasks: The approach is evaluated on tasks with programmatically verifiable answers. Extend to open-ended reasoning (proofs, explanations), design reliable non-LLM judging or consensus signals, and assess trade-offs when rewards are noisy.
- Faithfulness and causality of compressed reasoning: Pruning may alter the causal chain or produce post-hoc rationales. Evaluate with counterfactual faithfulness tests and intervention-based metrics to ensure compressed traces remain faithful to the model’s actual computation.
- Adversarial robustness: Attention can be manipulated (e.g., via attention-grabbing tokens). Stress-test against adversarial prompts that distort attention and implement defenses (regularization, adversarial training, attention norm constraints).
- Coverage of domains and modalities: Training is math-only and evaluation excludes many modalities (code execution, tool use, retrieval-augmented reasoning). Test on program synthesis, multi-hop QA with tools, scientific reasoning, and multi-modal settings to probe transfer.
- Large-model and long-context scaling: Results are on 4B/7B models with 10k–15k contexts. Evaluate on larger models and longer contexts (32k–128k), quantify scaling laws for accuracy–compute Pareto fronts, and memory/runtime implications.
- Granularity of compression: TRAAC prunes entire steps; token-level or semantic summarization within steps might preserve critical information. Compare deletion vs. learned summarization/compaction and hybrid schemes.
- Alternative importance criteria: Compare attention to uncertainty-, confidence-, gradient-, influence-function-, or LOO-based pruning signals; study combinations (e.g., multi-criteria ranking) and per-head/per-layer weighting instead of uniform averaging.
- Failure mode analysis: Catalog cases where pruning harms performance (e.g., problems requiring verification loops) and refine the uniformity heuristic with richer uncertainty estimates (e.g., calibration, variance across drafts).
- Interaction with early-stopping/test-time compute schedulers: Integrate TRAAC with early-exit, speculative decoding, or configurable test-time scaling to assess composability and cumulative gains.
- Parameter sensitivity and reproducibility: Report and analyze sensitivity to bin thresholds, compression ratios, uniformity thresholds, reward weights, window sizes, and decoding parameters; provide principled tuning procedures.
- Theoretical framing: Provide formal analysis or guarantees (e.g., regret bounds or optimal compute allocation under difficulty uncertainty), and characterize the Pareto frontier of accuracy vs. reasoning length.
- Calibration and selective prediction: Measure how compression affects confidence calibration, abstention policies, and error detection; explore reward shaping for calibrated reasoning lengths.
- Multilingual robustness: Step segmentation and attention dynamics may differ across languages. Evaluate cross-lingual performance and design language-agnostic segmentation/compression.
- Fairness and bias: Pruning could disproportionately remove context relevant to underrepresented groups or domains. Audit differential effects and develop fairness-aware compression objectives.
- Handling missing
</think>or atypical reasoning formats: Define fallback strategies and guardrails when the model omits delimiters or uses unconventional structure, and measure their impact. - Human-centered evaluations: Beyond accuracy/length metrics, assess human readability, usefulness, and trust in compressed chains, especially for educational or decision-support settings.
Practical Applications
Immediate Applications
The following applications can be deployed with current open-source reasoning LLMs (e.g., Qwen3-4B, DeepSeek-R1-Distill-Qwen-7B) using TRAAC’s post-training method, or with the “test-time-only” variant where retraining is not possible. Reported empirical gains (from the paper) provide a basis for ROI: roughly 30–40% reduction in reasoning tokens paired with 3–8% absolute accuracy improvements across math and out-of-distribution reasoning tasks.
Software, Cloud, and Developer Tools
- Adaptive compute for production LLMs
- What: Integrate TRAAC-style adaptive, attention-based compression into internal LLM stacks to reduce overthinking on easy queries and avoid underthinking on hard ones.
- Value: 30–40% fewer tokens per response (cost/latency), while improving accuracy by ~3–8%.
- Tools/Workflows: “Reasoning Budget Controller” microservice that (a) estimates per-query difficulty via pass rate at train time; (b) prunes low-importance reasoning steps via attention; (c) enforces difficulty-aware length rewards during RL post-training.
- Assumptions/Dependencies: Access to model weights and attention matrices; the model must emit CoT with > …</think> delimiters; RL/GPU budget for online GRPO post-training; verifiable reward signals for correctness. > > - Test-time compression wrapper for open models > - What: Use TRAAC’s inference-only variant to compress reasoning after </think> using attention, with a fixed compression ratio (e.g., 0.4) when retraining is infeasible. > - Value: Immediate token savings with minimal engineering; no training required. > - Tools/Workflows: “Attention-based CoT Compressor” SDK that hooks into generation and prunes low-importance steps post </think>. > - Assumptions/Dependencies: Access to attention (or at least hidden states) at inference; smaller gains than full TRAAC training; static compression may underperform adaptive variant. > > - IDE and code assistant optimization > - What: Apply difficulty-aware reasoning to code generation, test synthesis, and bug explanation: compress verbose chains for trivial edits, extend thinking for complex refactors. > - Value: Faster suggestions, lower latency; fewer tokens consumed by agentic coding workflows. > - Tools/Workflows: “Adaptive Code-Think” plugin that monitors reasoning verbosity, prunes low-signal steps, and automatically tunes length penalties per task difficulty. > - Assumptions/Dependencies: Access to model internals; stable detection of code difficulty (proxy via pass rate on unit prompts or static analysis). > > - RAG and knowledge management > - What: Store compressed, salient chains-of-thought alongside retrieved context to reduce storage and improve retrieval relevance. > - Value: Smaller memory footprint; faster re-use of reasoning; less distractive context for follow-up queries. > - Tools/Workflows: “CoT Summarizer & Indexer” that uses attention scores from </think> to extract key steps for vector DB indexing. > - Assumptions/Dependencies: Consistent <think> delimiters; attention reliability as an importance proxy. > > ### Education and Training > > - Adaptive tutoring and grading assistants > - What: Deliver concise solutions for easy problems and more detailed, step-by-step reasoning for hard ones; auto-calibrate solution length based on estimated difficulty. > - Value: Better student engagement; shorter, clearer explanations without sacrificing rigor. > - Tools/Workflows: “Difficulty-Calibrated Explainer” that uses pass rate or historical student performance to set compression targets. > - Assumptions/Dependencies: Verifiable answer checks; domain-appropriate difficulty proxies (e.g., item response theory for problem sets). > > ### Operations, Customer Support, and Content > > - Tiered reasoning for support and routing > - What: Classify and resolve easy tickets with minimal thinking; escalate complex cases with deeper reasoning. > - Value: Reduced handle time and compute costs; stable accuracy on hard cases. > - Tools/Workflows: “Adaptive Ticket Reasoner” that prunes repetitive self-corrections and allocates reasoning budget only where needed. > - Assumptions/Dependencies: Ticket difficulty proxies (historical resolution rate, confidence thresholds); access to attention. > > - Content generation with verbosity control > - What: Automatically compress or extend rationale length in marketing, legal drafting, or technical writing based on task difficulty or target audience. > - Value: Faster generation; controlled verbosity; decreased editing overhead. > - Tools/Workflows: “Audience-Aware Reasoning Compressor” that maps difficulty/audience profiles to compression ratios. > - Assumptions/Dependencies: Reliable detection of task complexity; coherent output post-compression. > > ### ML Engineering and Research > > - Evaluation and procurement benchmarking > - What: Use OptimalThinkingBench (F1 combining overthinking and underthinking metrics) to select models that are both accurate and token-efficient. > - Value: Vendor-agnostic measure of cost-performance tradeoffs; transparent procurement. > - Tools/Workflows: “OTB Gate” in evaluation pipelines; dashboards reporting AUC_OAA and accuracy vs. length trends. > - Assumptions/Dependencies: Access to benchmark tasks with verifiable answers; standardized evaluation procedures. > > - Curriculum and data scheduling > - What: Use pass-rate-based difficulty to schedule training (easy→hard) and to set length rewards during RL. > - Value: More stable training; improved adaptivity without sacrificing accuracy. > - Tools/Workflows: “Difficulty Binner” for online RL with sliding windows, median-based smoothing, and per-bin length reward tracking. > - Assumptions/Dependencies: Sufficient rollouts per step (e.g., N=8) to estimate pass rate; compute budget. > > ### Energy and Cost Management > > - Compute and carbon reduction for LLM inference > - What: Deploy TRAAC to lower token counts in high-throughput settings (contact centers, search, summarization). > - Value: Reduced GPU-hours and cloud spend; lower energy use per request. > - Tools/Workflows: “Reasoning Budget Policy” that enforces per-product token ceilings with adaptive compression. > - Assumptions/Dependencies: Operational tolerance for slight variation in explanation length; monitoring to prevent overcompression on edge cases. > > ### Daily Life Assistants > > - Personalized verbosity for personal assistants > - What: Deliver quick answers to routine queries (weather, conversions) and detailed multi-step reasoning when asked for complex planning. > - Value: Less waiting, less clutter; more helpful on hard tasks. > - Tools/Workflows: “User Preference–Aware Think Length” that binds user verbosity preferences to compression ratios. > - Assumptions/Dependencies: On-device models or models with accessible internals for attention-based pruning. > > ## Long-Term Applications > > The following require further research, scaling, validation, or ecosystem support (e.g., standards, regulation, vendor adoption). > > ### Healthcare and Life Sciences > > - Clinical decision support with adaptive reasoning depth > - What: Allocate more reasoning to diagnostically complex cases and compress routine cases; retain salient steps for audit. > - Value: Shorter time-to-insight with maintained or improved accuracy; auditable rationales. > - Tools/Workflows: “Difficulty-Calibrated CDS” integrating EHR signals as difficulty proxies; regulated audit trails storing compressed reasoning. > - Assumptions/Dependencies: Rigorous clinical validation; domain-specific difficulty estimators beyond pass rate; regulatory approvals; privacy-safe handling of CoT. > > ### Finance and Compliance > > - Adaptive risk analysis and compliance report generation > - What: Compress straightforward cases, deepen analysis where policy conflicts or anomalies arise. > - Value: Lower cost per report; improved focus on edge cases. > - Tools/Workflows: “Adaptive Compliance Writer” with attention-based pruning plus rules for mandatory disclosures. > - Assumptions/Dependencies: Model transparency requirements; strong guardrails to avoid pruning legally required rationale. > > ### Robotics and Edge AI > > - On-device reasoning with token budgets > - What: Use adaptive compression to plan with limited compute, allocating more steps to complex maneuvers or uncertain environments. > - Value: Longer battery life; more reliable planning under constraints. > - Tools/Workflows: “Edge Reasoning Budgeter” for mobile/embedded LLMs that enforces per-task compute caps. > - Assumptions/Dependencies: Robustness to sensor noise; real-time attention extraction; safety validation. > > ### Multi-Agent and Tool-Use Systems > > - Budget-aware orchestration across agents > - What: Share compressed chains-of-thought among agents; deepen reasoning only for tasks that fail initial passes. > - Value: Reduced inter-agent bandwidth; faster convergence on complex tasks. > - Tools/Workflows: “CoT Exchange Protocol” that standardizes compressed rationale passing; difficulty-triggered escalation policies. > - Assumptions/Dependencies: Standard control tokens across agents; protocols for privacy and provenance of CoT. > > ### Foundation Model Training and Platform Integration > > - Native integration of adaptive compression into training stacks > - What: Bake difficulty-aware, attention-based compression into RLHF/RLAIF pipelines and long-context pretraining. > - Value: Models that “think right” out of the box; better scaling of test-time compute without waste. > - Tools/Workflows: “Adaptive RL Head” integrating GRPO with per-difficulty length rewards; uniformity checks to prevent harmful compression. > - Assumptions/Dependencies: Access to base model internals; compute scale; robust alternatives to pass rate as a difficulty estimator in open-ended tasks. > > ### Privacy, Safety, and Governance > > - Privacy-preserving rationale handling > - What: Compress or redact sensitive CoT while retaining salient logical steps for internal verification. > - Value: Reduced leakage risk; improved compliance with privacy policies. > - Tools/Workflows: “CoT Redactor” that applies attention-guided compression plus policy filters. > - Assumptions/Dependencies: Clear corporate policies on CoT retention; validated mappings between attention and sensitivity. > > - Policy frameworks for adaptive compute > - What: Standards and procurement guidelines that encourage adaptive test-time compute (e.g., reporting AUC_OAA, accuracy–length profiles). > - Value: Incentivizes energy-efficient, performant models; comparable benchmarks across vendors. > - Tools/Workflows: “Adaptive Compute Reporting” templates and audits. > - Assumptions/Dependencies: Cross-vendor agreement on metrics; third-party evaluation capacity. > > ### Search, QA, and Knowledge Tools > > - Long-context compression for archival and retrieval > - What: Apply attention-based compression to long reasoning traces to improve downstream retrieval and reduce storage. > - Value: Smaller corpora; better relevance; faster iterative reasoning under context limits. > - Tools/Workflows: “Reasoning Trace Archiver” that prunes low-importance sections while keeping key derivations. > - Assumptions/Dependencies: Persistent reliability of attention as an importance proxy; domain adaptation for non-math tasks. > > ### Standardization and Ecosystem > > - Control-token and telemetry standards for reasoning models > - What: Standardize <think>, , and step delimiters to enable interoperable compression, logging, and audit.
- Value: Tool portability; simpler compliance and monitoring.
- Tools/Workflows: “Reasoning Telemetry Spec” specifying attention exposure, step boundaries, and difficulty metadata.
- Assumptions/Dependencies: Vendor participation; consensus on safety implications of exposing CoT/attention.
Cross-Cutting Assumptions and Dependencies
- Access to internals: TRAAC requires access to model attention weights (across layers/heads) and chain-of-thought delimiters. Many closed APIs do not expose these; vendor adoption or open models are currently needed.
- Verifiable rewards: Training depends on correctness signals (math/MCQ/numeric answers). Porting to domains without auto-grading requires new verifiers or proxies (self-consistency checks, external tools).
- Difficulty estimation: The pass-rate proxy uses multiple rollouts during training (e.g., N=8). At inference, static or learned difficulty proxies may be needed to avoid extra sampling overhead.
- Compression safety: Overcompression risks removing necessary reasoning. TRAAC’s uniformity check and difficulty bins mitigate this, but domain tuning is required.
- Compute budget: Online RL post-training (GRPO) requires non-trivial compute. Organizations without this capacity may start with the test-time-only variant and plan migration.
- Privacy and compliance: Chains-of-thought may contain sensitive content. Compression/redaction policies and storage controls are required, especially in regulated sectors.
Glossary
- Ablation study: A controlled analysis where components of a system are removed or altered to assess their contributions. "cref{tab:compression_ablation} presents an ablation study comparing attention-based compression with other pruning techniques."
- Adaptive thinking: Dynamically adjusting the amount of reasoning based on problem difficulty. "This highlights the need for adaptive thinking"
- AdaptThink: An adaptive RL baseline that lets models choose between thinking and no-thinking modes under constraints. "When compared to the next-best performing baseline, AdaptThink~\citep{zhang2025adaptthinkreasoningmodelslearn}, we achieve an average accuracy improvement of 7.9\%"
- Advantage (RL): The performance of an action relative to a baseline, used to guide policy updates. "The advantage of each rollout is estimated using the standard GRPO objective"
- AIME: A competitive math benchmark (American Invitational Mathematics Examination) for evaluating mathematical reasoning. "Across a variety of tasks (AIME, AMC, GPQA-D, BBEH), TRAAC (Qwen3-4B) achieves an average absolute accuracy gain of 8.4\%"
- AMC: A math benchmark (American Mathematics Competitions) used to test problem-solving ability. "Across a variety of tasks (AIME, AMC, GPQA-D, BBEH), TRAAC (Qwen3-4B) achieves an average absolute accuracy gain of 8.4\%"
- Attention-based compression: A method that removes low-importance reasoning steps based on attention patterns. "a combination of task-difficulty calibration and attention-based compression yields gains across diverse tasks."
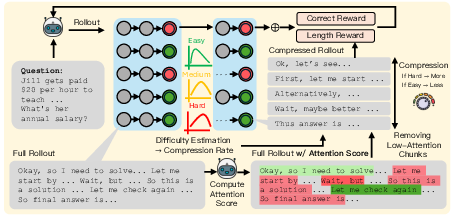
- Attention score: A numerical measure of how much the model attends to a token or step, often aggregated over layers and heads. "To calculate the attention score assigned to each token, we pass the reasoning trajectory (full rollout in \cref{fig:mainFigure}) through the initial policy model."
- AUC_OAA: An evaluation metric on OverthinkingBench capturing accuracy-efficiency trade-offs. "we also report the $\text{AUC}_{\text{OAA}$~\citep{aggarwal2025optimalthinkingbenchevaluatingunderthinkingllms}"
- Auxiliary prompt: An extra instruction appended to steer the model’s reasoning or attention. "we also append an auxiliary prompt ``Time is up. I should stop thinking and now write a summary containing all key steps required to solve the problem.''"
- BBEH (Big Bench Extra Hard): A challenging general reasoning benchmark from the BIG-bench family. "Tables~\ref{tab:mainResults} show the performance of TRAAC compared to other baselines on AIME, AMC, GPQA-D, BBEH (Big Bench Extra Hard) benchmarks."
- Budget-aware reward shaping: Tailoring rewards to encourage meeting compute or token budgets during reasoning. "Other more adaptive work has employed budget-aware reward shaping with a binary choice between thinking or not thinking"
- Chain-of-thought (CoT): Step-by-step natural language reasoning traces generated by a model. "These models extend the chain-of-thought~\citep[CoT;] []{wei2023chainofthoughtpromptingelicitsreasoning} paradigm"
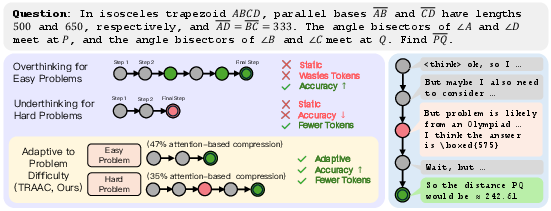
- Compression rate: The proportion of reasoning steps removed during compression. "For harder problems, TRAAC maintains a low compression rate"
- Correctness Reward (CR): A reward focused on getting the correct final answer, typically weighted highly. "Correctness Reward (CR): A high-weight reward is assigned to outputs that produce the correct final answer."
- Critic: In policy-gradient RL, a value estimator used to compute advantages; GRPO removes the critic. "by eliminating the critic and instead estimating the baseline from a group of sampled responses."
- DeepSeek-R1-Distill-Qwen-7B: A distilled long-reasoning LLM used as a base model. "DeepSeek-R1-Distill-Qwen-7B~\citep{deepseekai2025deepseekr1incentivizingreasoningcapability} (Deepseek-Qwen-7B)"
- Delimiter </think>: A special token marking the end of the reasoning and the start of the final answer. "its importance score is defined as the aggregated attention from the delimiter </think> across all layers and heads"
- Difficulty-Level Calibration: Adapting compression or rewards based on estimated task difficulty. "Difficulty-Level Calibration."
- F1 score: The harmonic mean of two metrics; here combining overthinking AUC and underthinking accuracy. "we combined the $\text{AUC}_{\text{OAA}$ from OverthinkingBench and accuracy from UnderthinkingBench into a single F1 score."
- Format Reward: A reward ensuring the output follows required structural conventions (e.g., delimiters). "Format Reward: A structure reward to ensure the presence of special delimiter tokens such as > and , ensuring that trajectory and final answer are easily distinguishable."
- GRPO (Group Reward Policy Optimization): An RL algorithm that estimates a baseline from a group of sampled responses instead of a critic. "TRAAC is based on Group Reward Policy Optimization~\citep[GRPO;] []{shao2024deepseekmathpushinglimitsmathematical}"
- L1-Max: An RL baseline that optimizes accuracy subject to a length constraint. "L1-Max: An RL framework proposed by ~\cite{aggarwal2025l1controllinglongreasoning} that optimizes for accuracy while adhering to user-specific length constraints."
- LC-R1: An RL baseline using an external model to compress the thinking process. "LC-R1: A compression-based RL framework by ~\cite{cheng2025optimizinglengthcompressionlarge} that uses an externally trained model to remove invalid portions of the thinking process."
- Length penalty: A training or inference strategy that penalizes overly long responses. "or RL methods with length penalties~\citep{arora2025traininglanguagemodelsreason, hou2025thinkprune}."
- Length Reward (LR): A reward that encourages shorter, efficient reasoning sequences, often conditioned on correctness. "Length Reward (LR): To regulate the verbosity of the reasoning process, we define a length-based reward that penalizes unnecessarily long reasoning traces while adapting to task difficulty."
- MCQ: Multiple-choice questions used for automatic evaluation. "i.e., MCQ and questions with numerical answer"
- Online reinforcement learning (RL): RL conducted during ongoing sampling and model updates, not purely offline. "online reinforcement learning~\citep[RL;] []{ shao2024deepseekmathpushinglimitsmathematical}"
- OptimalThinkingBench: A combined benchmark that evaluates both overthinking and underthinking behavior. "We test our TRAAC method on OptimalThinkingBench \citep{aggarwal2025optimalthinkingbenchevaluatingunderthinkingllms}"
- Out-of-distribution (OOD): Data or tasks different from the training distribution used to assess generalization. "Among these OOD tasks, TRAAC shows an average improvement of 3\% on Qwen3-4B"
- Overthinking: Excessively long reasoning on easy tasks that wastes computation. "overthinking occurs when models think excessively for simpler tasks, inflating test-time computation"
- OverthinkingBench: A benchmark designed to measure unnecessary long reasoning on easy queries. "OverthinkingBench/ UnderthinkingBench \citep{aggarwal2025optimalthinkingbenchevaluatingunderthinkingllms}"
- Pass rate: The proportion of correct rollouts used to estimate problem difficulty. "The difficulty of a task is estimated based on the pass rate of each problem during rollout."
- Policy model: The parameterized model that outputs tokens/actions in an RL setup. "Let denote the policy model"
- Proximal Policy Optimization (PPO): A stable policy-gradient RL algorithm often used for LLMs. "extends Proximal Policy Optimization~\citep{schulman2017proximalpolicyoptimizationalgorithms} by eliminating the critic"
- Pruning: Removing tokens or steps deemed unimportant to streamline reasoning. "prunes unnecessary reasoning steps while preserving essential information."
- Qwen3-4B: A 4B-parameter LLM used as a base for reasoning experiments. "TRAAC (Qwen3-4B) achieves an average absolute accuracy gain of 8.4\%"
- Reasoning trajectory: The full sequence of intermediate thoughts prior to the final answer. "where is the complete reasoning trajectory"
- Reinforcement learning (RL): A learning paradigm where a policy is optimized via rewards from interactions. "we propose TRAAC (Think Right with Adaptive, Attentive Compression), an online post-training RL method"
- Rollout: A sampled reasoning and answer sequence generated by the policy during training. "At each training step, the model generates rollouts"
- Self-attention: The Transformer mechanism that lets tokens attend to each other, used here to assess importance. "an online post-training RL method that leverages the model's self-attention over a long reasoning trajectory"
- Sigmoid-based smoothing: Using a sigmoid function to soften reward changes near a threshold (e.g., median length). "we introduce a sigmoid-based smoothing mechanism that provides a soft bonus () for rollouts beyond the median length."
- SFT (Supervised Fine-Tuning): Training a model directly on labeled outputs, often used as a baseline. "TokenSkip: An SFT based baseline as described by ~\cite{xia2025tokenskipcontrollablechainofthoughtcompression}"
- Sliding window: A moving window over recent samples to stabilize statistics like min/max/median. "we maintain a sliding window over the last 10 steps for each difficulty bin"
- Temperature (sampling): A decoding parameter controlling randomness in token sampling. "we set temperature to 1.0"
- Test-time compute: The amount of computation (e.g., tokens) used during inference. "scaling test-time compute across various domains"
- Test-time method: An inference-only variant of a method applied without additional training. "we evaluated TRAAC as a test-time method"
- Token budget: A limit on the number of tokens used for reasoning or generation. "saves token budgets"
- TokenSkip: A baseline that fine-tunes on compressed chain-of-thought data to reduce length. "TokenSkip: An SFT based baseline as described by ~\cite{xia2025tokenskipcontrollablechainofthoughtcompression}"
- Uniformity score: A measure of how evenly distributed attention scores are across tokens, used to modulate compression. "More details on calculating the uniformity score can be found in Appendix~\ref{appendix:uniformity_score}."
- Under-adaptivity: Failing to modulate reasoning length appropriately to problem difficulty. "We refer to the phenomenon of models misallocating thinking budget -- illustrated in \cref{fig:fig1} -- as under-adaptivity."
- Underthinking: Stopping reasoning too early on hard problems, leading to errors. "underthinking arises when models terminate too early on harder problems"
- UnderthinkingBench: A benchmark evaluating whether and when thinking is necessary on harder tasks. "UnderthinkingBench shows its generalization ability."
- Verifiable reward system: A reward setup based on automatically checkable criteria (e.g., correctness), reducing subjectivity. "Following standard GRPO practice of having a verifiable reward system~\citep{shao2024deepseekmathpushinglimitsmathematical}, our setup comprises three different reward signals"
Collections
Sign up for free to add this paper to one or more collections.