- The paper introduces Exploratory Annealed Decoding (EAD) as a novel method that dynamically adjusts sampling temperature to balance exploration and stability in RL.
- It employs a global-step-aware decay rate and truncated importance sampling to enhance training efficiency and correct off-policy bias.
- Experimental validation on the Numina-Math dataset shows improved Pass@16 performance, promoting robust and verifiable model reasoning.
Let it Calm: Exploratory Annealed Decoding for Verifiable Reinforcement Learning
Introduction
The paper "Let it Calm: Exploratory Annealed Decoding for Verifiable Reinforcement Learning" introduces a novel method called Exploratory Annealed Decoding (EAD) designed to enhance Reinforcement Learning with Verifiable Rewards (RLVR). Traditional methods of exploration in reinforcement learning often struggle with balancing sample quality and training stability. EAD addresses these challenges by dynamically adjusting the sampling temperature during the generation process. This process starts with high temperature for diversity and gradually decreases towards lower temperatures to ensure quality and coherence. This approach presents a lightweight, effectively integrable method for enabling improved model reasoning capabilities in LLMs.
Methodology
EAD modifies the traditional fixed-temperature sampling by introducing an annealing schedule that adapts during sequence generation. It employs a strategy where the temperature begins at a higher level and is progressively reduced as generation proceeds. This is based on the autroregressive insights that require more exploration as the sequence starts, while stability is crucial towards the end of generation.
Temperature Annealing Scheme
The methodology relies on setting initial high temperatures to encourage exploration. As new tokens are generated, the temperature is gradually reduced according to a predefined schedule, as illustrated in the figure below. This ensures the initial tokens are diverse but increasingly stabilize as more specific context is established.
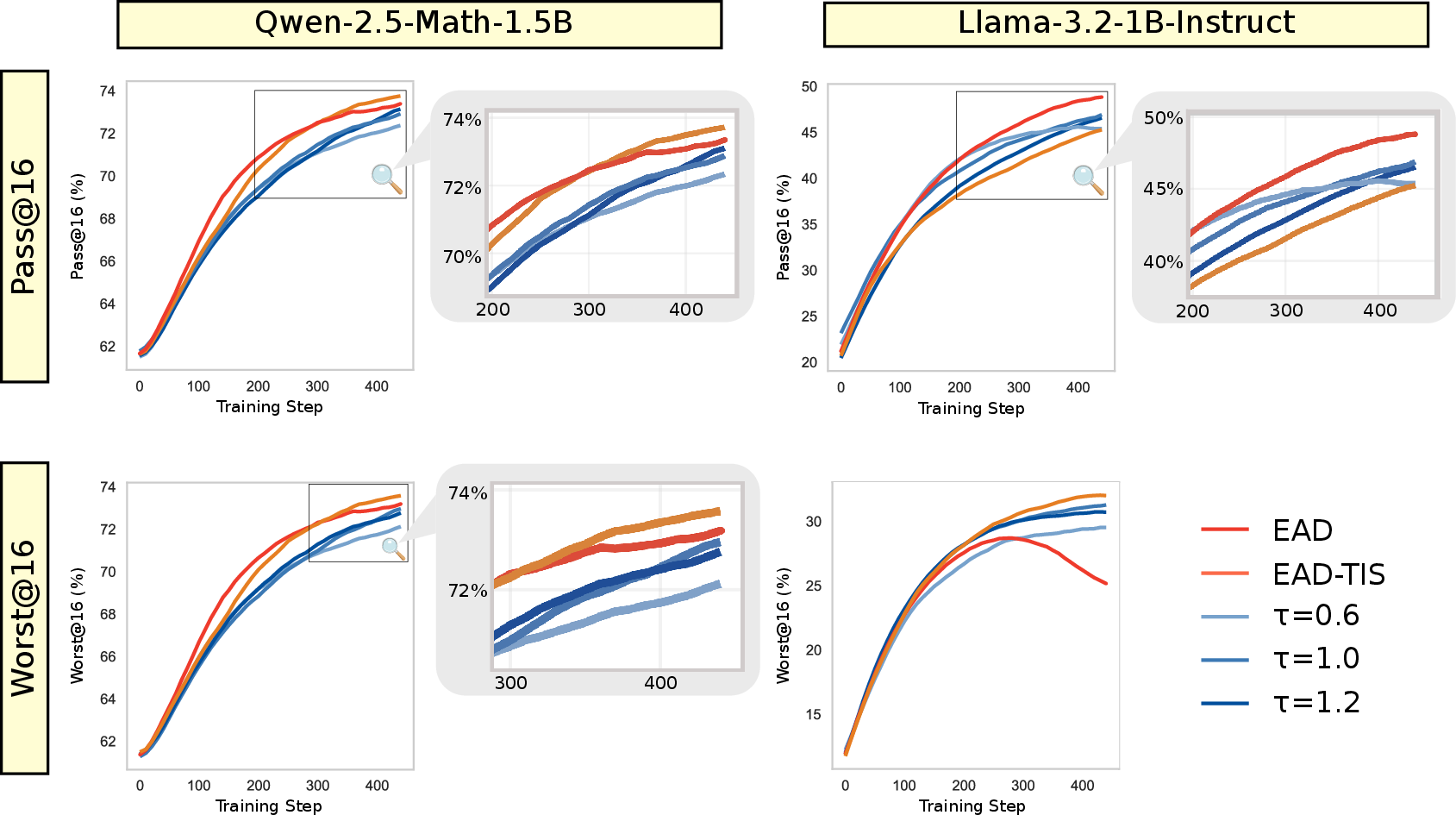
Figure 1: Pass@16 and Worst@16 performance evaluation in RL training. While EAD improves exploration of high-quality samples (even the worst outperform temperature sampling), the gain diminishes over time; importance sampling can supplement to correct bias and sustain training.
Global-Step-Aware Decay Rate
To accommodate the increased length of generation as training progresses, EAD incorporates a decay rate that is adaptive with global steps. This mitigates the risk of over-exploration at later stages by ensuring the gradual cooling adjusts with the complexity and difficulty of longer sequences.
Truncated Importance Sampling
To address the off-policy issues introduced by aggressive exploration, EAD employs Truncated Importance Sampling (TIS) to correct estimates of gradients. This helps prevent instability caused by high variance in importance weights during training.
Experimental Validation
Comprehensive experiments conducted on the Numina-Math dataset demonstrate EAD's effectiveness. EAD significantly enhances training efficiency, sampling diversity, and overall sample quality across several RLVR algorithms and LLM sizes.
Pass@16 Performance
EAD consistently outperforms fixed-temperature baselines in Pass@16 metrics, validating its ability to generate high-quality, exploratory samples. The annealing method facilitates broader and more efficient exploration early in the sequence which in turn supports the RL algorithm in escaping local optima.
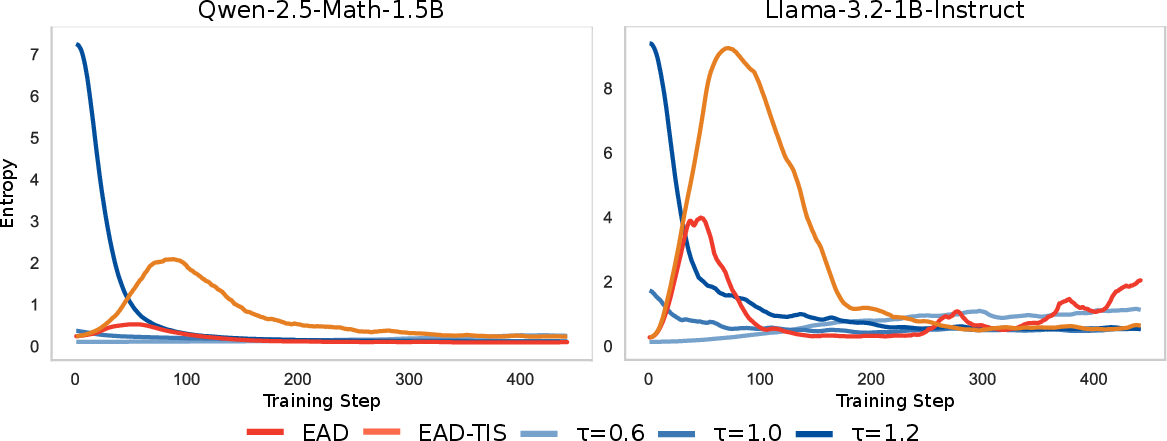
Figure 2: Entropy Dynamics in RL Training. Under commonly-used temperature sampling, trained with RL algorithm would make entropy decrease, sharply shrinking the exploration space for RL from beginning. While EAD could help RL algorithm to escape local minimum and do exploration when needed in the middle of RL training.
Implications and Future Work
The proposed method highlights the importance of dynamically adapting exploration strategies in sequential tasks within LLM contexts. It offers computational efficiency by minimizing oversampling while maintaining robust gains in exploration diversity. Future work could extend EAD by incorporating adaptive schedules specific to prompt nature and by further improving the computational footprint using more advanced importance sampling techniques.
Given its plug-and-play nature and compatibility with existing architectures, EAD presents a promising direction for enhancing the reasoning capabilities of LLMs in challenging RLVR tasks.
Conclusion
EAD successfully integrates dynamic temperature modulation into reinforcement learning tasks, addressing long-standing issues associated with exploration-exploitation trade-offs. It delivers improved performance in model reasoning capabilities while maintaining computational efficiency and stability, positioning it as a key approach in advancing RLVR methodologies. As RLVR continues to be a pivotal strategy in LLM enhancement, EAD's adaptable approach is likely to inspire further innovation and research in the field.

