- The paper introduces Entropy-Guided Sequence Weighting (EGSW) to dynamically balance exploration and exploitation in RL-based LLM fine-tuning.
- EGSW integrates entropy regularization with advantage-based weighting to boost reward scores and enhance reasoning capabilities in LLMs.
- Experiments on Qwen2.5-Math models highlight that precise hyperparameter tuning of α and P is crucial for achieving stable and improved performance.
Entropy-Guided Sequence Weighting for Efficient Exploration in RL-Based LLM Fine-Tuning
This paper introduces @@@@1@@@@ (EGSW), a novel method designed to enhance exploration during RL-based fine-tuning of LLMs. EGSW dynamically adjusts the weights of generated sequences based on both their advantage and entropy, effectively balancing exploration and exploitation. The method aims to improve reasoning capabilities in LLMs by prioritizing high-reward, high-uncertainty steps, and it is generalizable to both step-wise and trajectory-wise RL frameworks.
Background and Motivation
The primary challenge in fine-tuning LLMs with RL lies in efficiently exploring high-dimensional state spaces. Traditional methods like MCTS are computationally expensive, rendering them impractical for LLM fine-tuning. While search-free methods such as GRPO offer computational efficiency, they often suffer from suboptimal exploration due to their reliance on policy-driven sampling. EGSW addresses these limitations by integrating entropy regularization with advantage-based weighting, promoting a more balanced and efficient exploration strategy.
Entropy-Guided Sequence Weighting (EGSW)
EGSW enhances the exploration-exploitation tradeoff by dynamically assigning weights to generated sequences based on their advantage and entropy. The raw weight for sequence t is computed as:
wi,traw=exp(PAi,t+αHi,t),
where Ai,t is the advantage, Hi,t is the entropy, α is a hyperparameter scaling the entropy contribution, and P is a temperature parameter controlling weight distribution sparsity. The entropy at step t, Hi,t, is calculated as:
Hi,t=−a∈A∑πθ(a∣q,ai,<t)logπθ(a∣q,ai,<t),
where πθ(a∣q,ai,<t) is the probability of selecting action a given state q under policy πθ, and A represents the action space. These raw weights are then normalized using a softmax function to ensure proper scaling and training stability:
wi,t=∑j=1Nwj,trawwi,traw=∑j=1Nexp(PAj,t+αHj,t)exp(PAi,t+αHi,t).
The normalized weights wi,t are used to reweight the policy gradient update, given by:
∇θJEGSW(θ)=K1i=1∑KNk1t=1∑Nkwi,t[A^i,t+β(πθ(ai,t∣q,ai,<t)πref(ai,t∣q,ai,<t)−1)]∇θlogπθ(ai,t∣q,ai,<t).
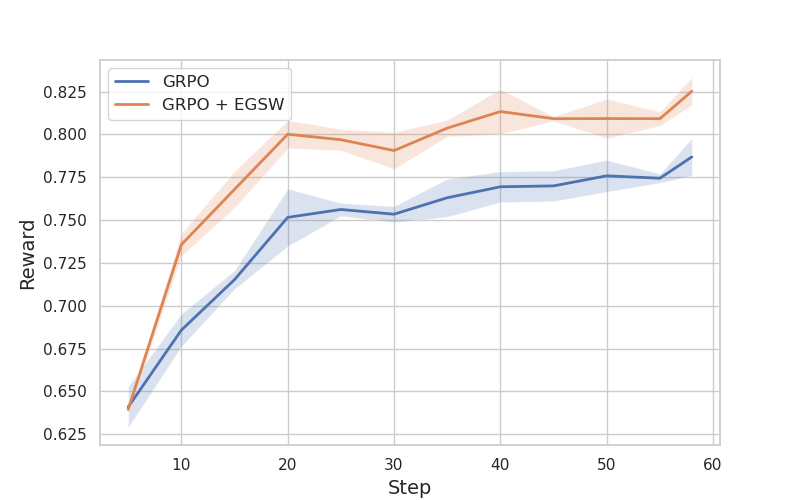
Figure 1: Training reward of the methods based on Qwen2.5-Math-7B.
Experimental Results
The authors fine-tuned EGSW on top of the GRPO framework, adopting the Simple-RL Reason approach with Qwen2.5-Math-7B and Qwen2.5-Math-7B-Instruct as base models. The integration was implemented using the Hugging Face open-r1, transformers, and trl repositories.
Experiments demonstrated that EGSW consistently outperformed standard GRPO in terms of reward scores. For hyperparameter tuning, the scaling coefficient α was adjusted between 0.15 and 0.50, and the temperature parameter P was explored between 1 and 2. The optimal performance for Qwen2.5-Math-7B-Instruct was achieved with normalized entropy, α=0.8, and P=1.8, while Qwen2.5-Math-7B performed best with normalized entropy, α=0.3, and P=1.
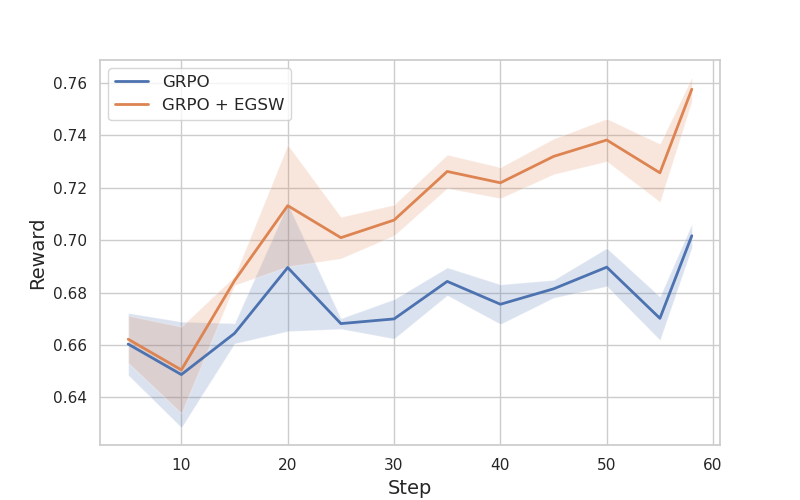
Figure 2: Training reward of the methods based on Qwen2.5-Math-7B-Instruct.
Discussion and Observations
A key observation is that fine-tuning Qwen2.5-Math-7B-Instruct with GRPO using an 8K MATH dataset alone did not improve the model’s reasoning capability, likely due to the model’s prior fine-tuning. However, incorporating EGSW enhanced the model’s reasoning ability, attributed to EGSW’s capacity to encourage better exploration. Moreover, the authors noted that effective exploration enables the model to generate fewer tokens while achieving higher rewards.
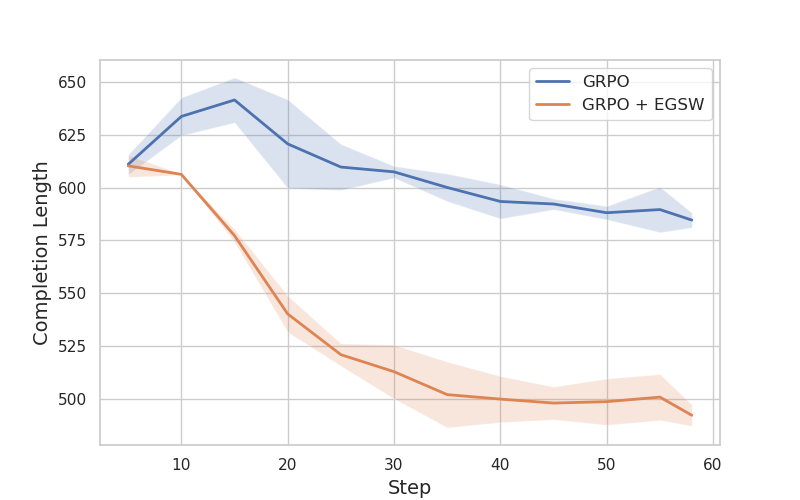
Figure 3: Completion length of the methods based on Qwen2.5-Math-7B.
The authors also highlight that EGSW is highly sensitive and requires careful hyperparameter tuning, particularly in balancing the entropy coefficient α to prevent excessive exploration. Additionally, EGSW reduces the overall gradient norm by using the weights, necessitating adjustments to the learning rate for stable learning.
Conclusion
The paper introduces EGSW as an effective method for enhancing the exploration-exploitation tradeoff in RL-based LLM fine-tuning. By integrating entropy into the weighting mechanism, EGSW promotes more diverse and informative trajectories while maintaining a focus on high-reward outputs. Empirical results demonstrate that EGSW enhances GRPO by achieving higher reward scores and improving reasoning capabilities. Future work could explore integrating EGSW with other reinforcement learning-based fine-tuning strategies to further enhance model performance across broader tasks.

