OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment
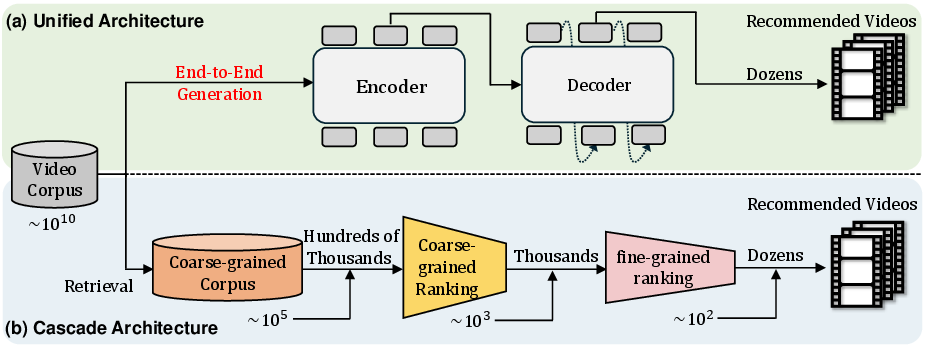
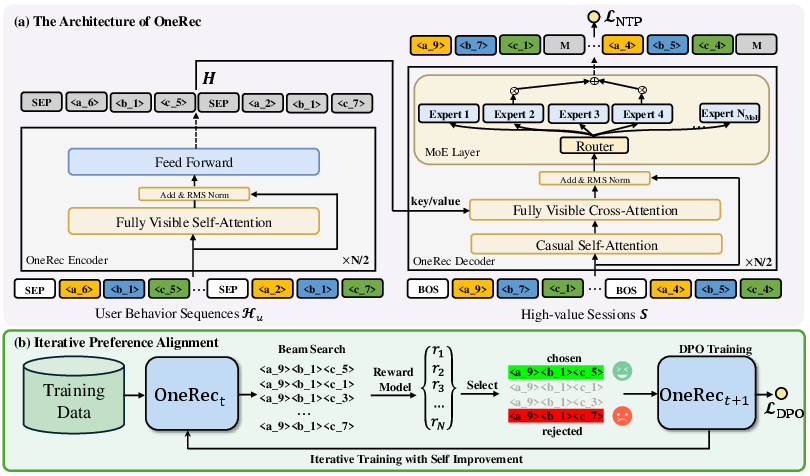
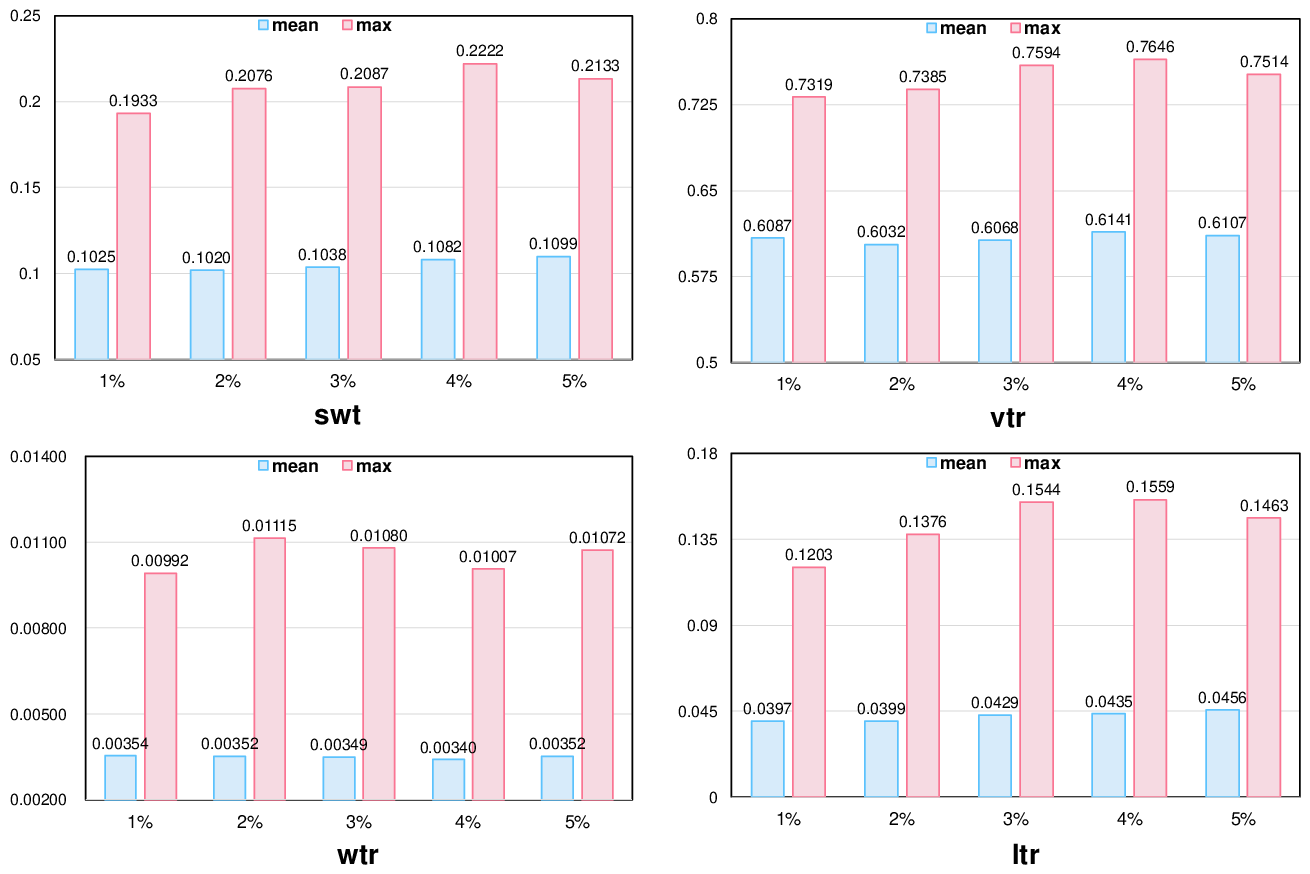
Abstract: Recently, generative retrieval-based recommendation systems have emerged as a promising paradigm. However, most modern recommender systems adopt a retrieve-and-rank strategy, where the generative model functions only as a selector during the retrieval stage. In this paper, we propose OneRec, which replaces the cascaded learning framework with a unified generative model. To the best of our knowledge, this is the first end-to-end generative model that significantly surpasses current complex and well-designed recommender systems in real-world scenarios. Specifically, OneRec includes: 1) an encoder-decoder structure, which encodes the user's historical behavior sequences and gradually decodes the videos that the user may be interested in. We adopt sparse Mixture-of-Experts (MoE) to scale model capacity without proportionally increasing computational FLOPs. 2) a session-wise generation approach. In contrast to traditional next-item prediction, we propose a session-wise generation, which is more elegant and contextually coherent than point-by-point generation that relies on hand-crafted rules to properly combine the generated results. 3) an Iterative Preference Alignment module combined with Direct Preference Optimization (DPO) to enhance the quality of the generated results. Unlike DPO in NLP, a recommendation system typically has only one opportunity to display results for each user's browsing request, making it impossible to obtain positive and negative samples simultaneously. To address this limitation, We design a reward model to simulate user generation and customize the sampling strategy. Extensive experiments have demonstrated that a limited number of DPO samples can align user interest preferences and significantly improve the quality of generated results. We deployed OneRec in the main scene of Kuaishou, achieving a 1.6\% increase in watch-time, which is a substantial improvement.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.