- The paper presents an end-to-end generative recommendation system that unifies retrieval and ranking, overcoming cascaded architectures with improved MFU and reduced OPEX.
- It employs collaborative-aware multimodal tokenization using QFormer and RQ-Kmeans to generate robust semantic IDs, enabling efficient handling of billion-scale item spaces.
- The architecture integrates multi-scale user modeling, a Mixture-of-Experts decoder, and RL-based reward optimization to achieve significant gains in both offline and online performance.
OneRec: End-to-End Generative Recommendation System Architecture and Scaling
Motivation and Systemic Limitations of Cascaded Recommendation
The OneRec Technical Report addresses fundamental inefficiencies in traditional multi-stage recommender system architectures, which rely on cascaded retrieval, pre-ranking, and ranking modules. These legacy systems suffer from fragmented compute, low Model FLOPs Utilization (MFU), and optimization inconsistencies due to conflicting objectives and cross-stage modeling. The paper demonstrates that, in production environments such as Kuaishou, over half of serving resources are consumed by communication and storage rather than high-precision computation, with MFU values for ranking models at only 4.6% (training) and 11.2% (inference), far below the 40% observed in LLMs on H100 GPUs.
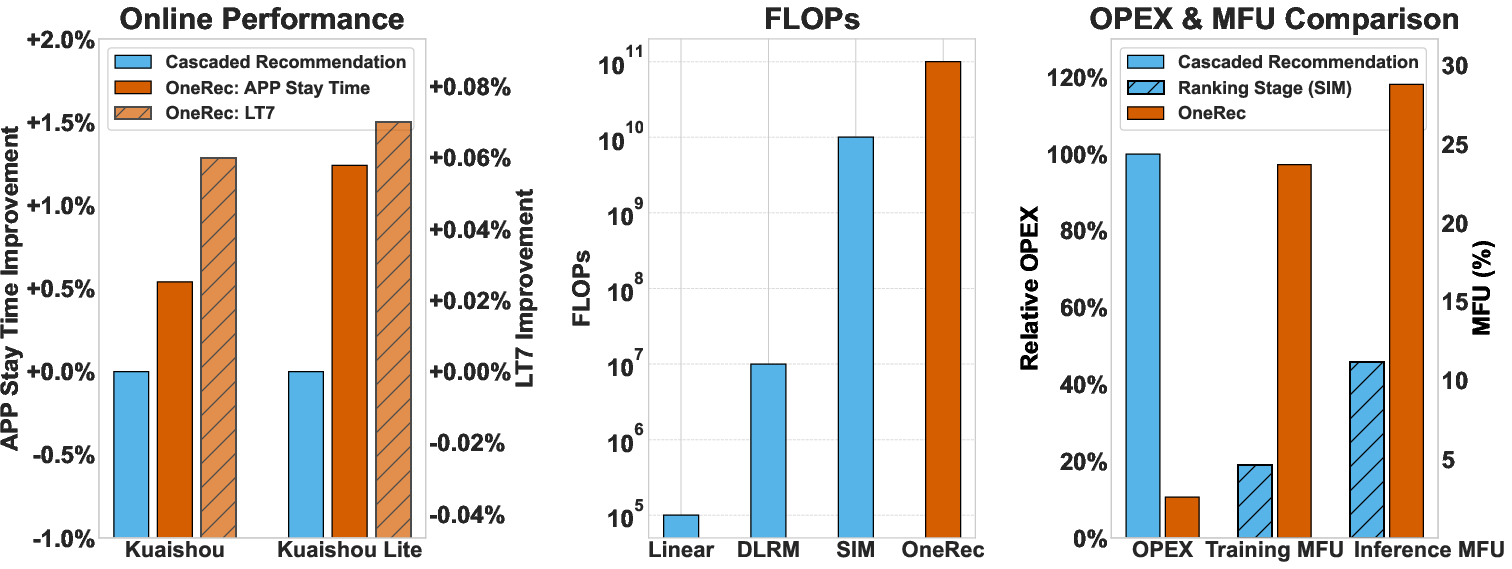
Figure 1: Online performance, FLOPs, OPEX, and MFU comparison.
The architectural gap has also hindered the adoption of recent advances in scaling laws, RL, and multimodal modeling from the broader AI community. OneRec proposes a unified, end-to-end generative framework that integrates retrieval and ranking, enabling direct optimization for final objectives and substantially improving computational efficiency.
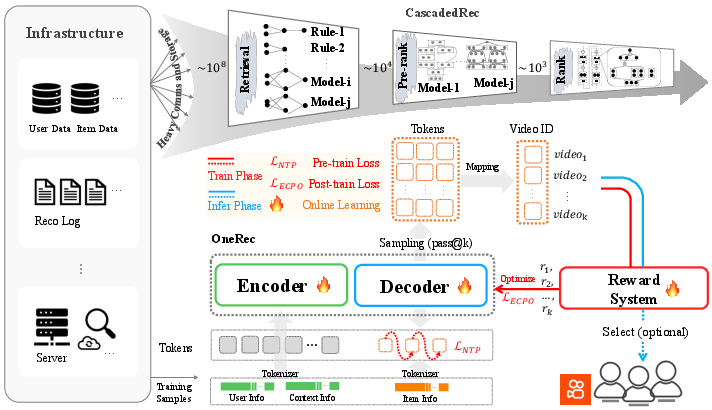
Figure 2: Comparison between a cascaded recommender system and the OneRec encoder-decoder architecture.
Tokenization: Collaborative-Aware Multimodal Semantic IDs
OneRec introduces a scalable tokenization pipeline for short videos, leveraging collaborative-aware multimodal representations. Unlike prior approaches that generate semantic IDs solely from context features, OneRec aligns multimodal content (caption, tag, ASR, OCR, cover image, sampled frames) with collaborative signals using QFormer compression and item-to-item contrastive loss. The tokenization employs RQ-Kmeans for residual quantization, producing coarse-to-fine semantic IDs with improved reconstruction quality, codebook utilization, and token distribution entropy compared to RQ-VAE.
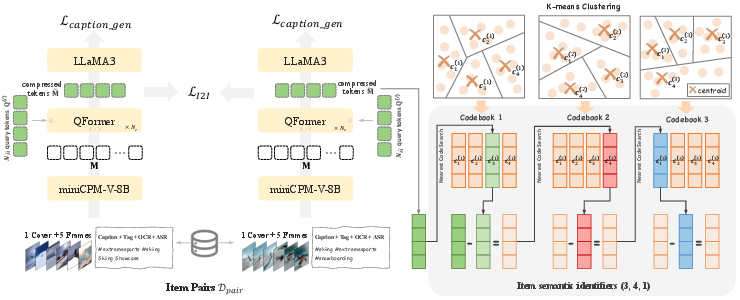
Figure 3: Tokenizer implementation: collaborative multimodal alignment and RQ-Kmeans tokenization.
This approach enables knowledge transfer among similar items and robust generalization to new items, supporting billion-scale item spaces with a fixed vocabulary.
Encoder-Decoder Architecture and Multi-Scale User Modeling
The encoder integrates multi-scale user behavior via four pathways: static, short-term, positive-feedback, and lifelong. Lifelong sequences (up to 100,000 interactions) are hierarchically compressed using K-means and QFormer, enabling efficient modeling of ultra-long user histories. The encoder concatenates all pathway outputs and processes them through transformer layers with RMSNorm.
The decoder adopts a point-wise generation paradigm, using semantic IDs as targets. It incorporates Mixture-of-Experts (MoE) feed-forward networks with top-k routing and loss-free load balancing, scaling model capacity without gradient interference. Training uses cross-entropy loss for next-token prediction on semantic IDs.
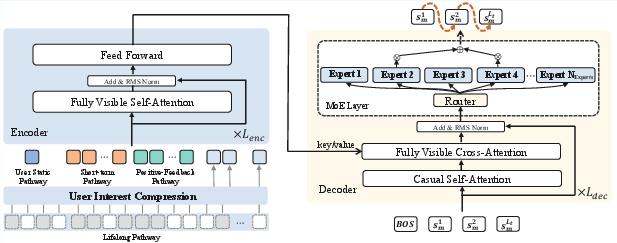
Figure 4: Encoder-decoder architecture integrating multi-scale user features and MoE decoder.
Reinforcement Learning and Reward System Design
OneRec's reward system comprises three components: Preference Reward (P-Score), Format Reward, and Industrial Reward. The P-Score is a neural fusion of multiple engagement objectives (clicks, likes, comments, watch time), learned via multi-tower MLPs for personalized preference alignment. Format Reward regularizes the legality of generated semantic ID sequences, mitigating the squeezing effect observed when RL increases the probability of illegal outputs. Industrial Reward enables targeted optimization for business constraints, such as suppressing viral content farms.
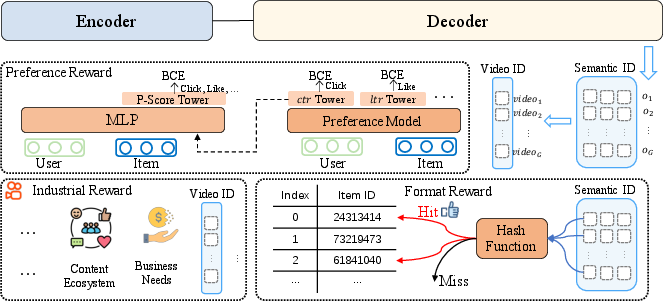
Figure 5: Reward system: preference, format, and industrial alignment modules.
The RL framework employs Early Clipped GRPO (ECPO), a modification of Group Policy Relative Optimization, to stabilize training by clipping large policy ratios for negative advantages, preventing gradient explosion. RL and supervised fine-tuning are performed jointly, with RL samples generated via external inference services and rewards computed on-the-fly.
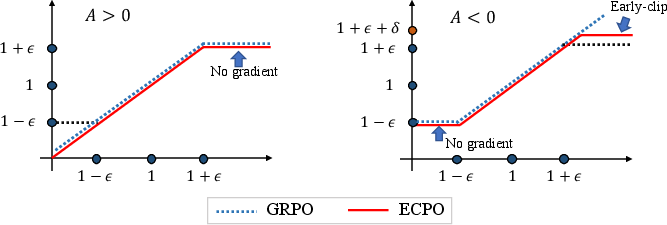
Figure 6: ECPO illustration: early clipping for negative advantages stabilizes policy updates.
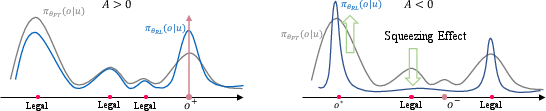
Figure 7: Squeezing effect: RL can compress probability mass into illegal tokens without format regularization.
Training Infrastructure and Scaling Laws
OneRec is trained on 90 servers with 8 flagship GPUs each, using NVLink and RDMA for high-bandwidth communication. Embedding acceleration is achieved via GPU-based parameter servers and unified embedding tables. Training employs data parallelism, ZERO1, gradient accumulation, and mixed precision (BFloat16). Compilation optimizations for attention networks further reduce overhead.
The system achieves 23.7% MFU in training and 28.8% in inference, a 5.2× and 2.6× improvement over legacy models, with OPEX reduced to 10.6% of traditional pipelines.
Empirical Scaling: Model, Feature, Codebook, and Inference
Parameter scaling experiments show that larger models (up to 2.633B parameters) achieve lower loss and improved convergence. Feature scaling demonstrates that comprehensive feature engineering yields substantial improvements in all engagement metrics and preference scores.
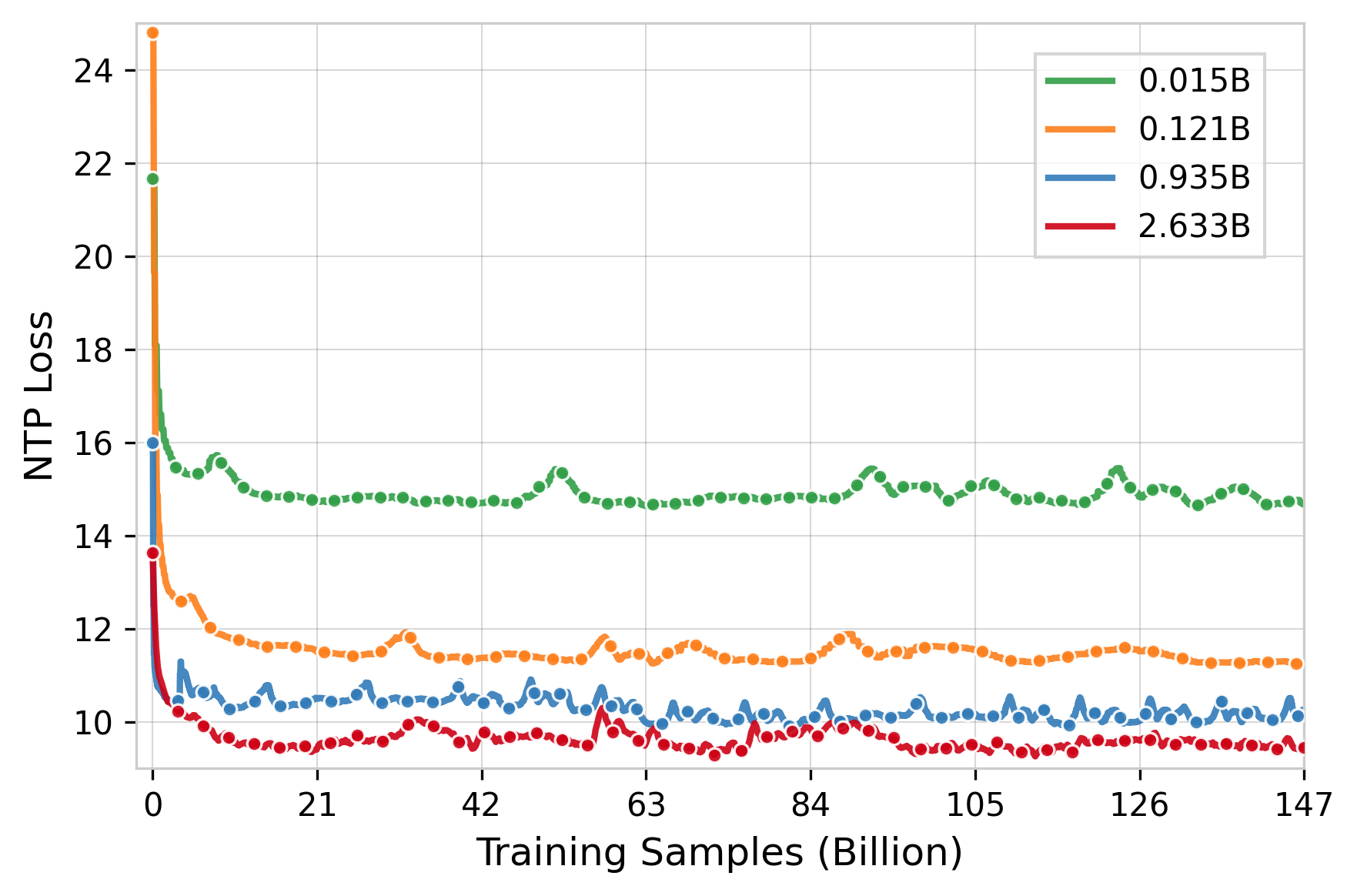
Figure 8: Loss curves for different OneRec model sizes, showing scaling behavior.
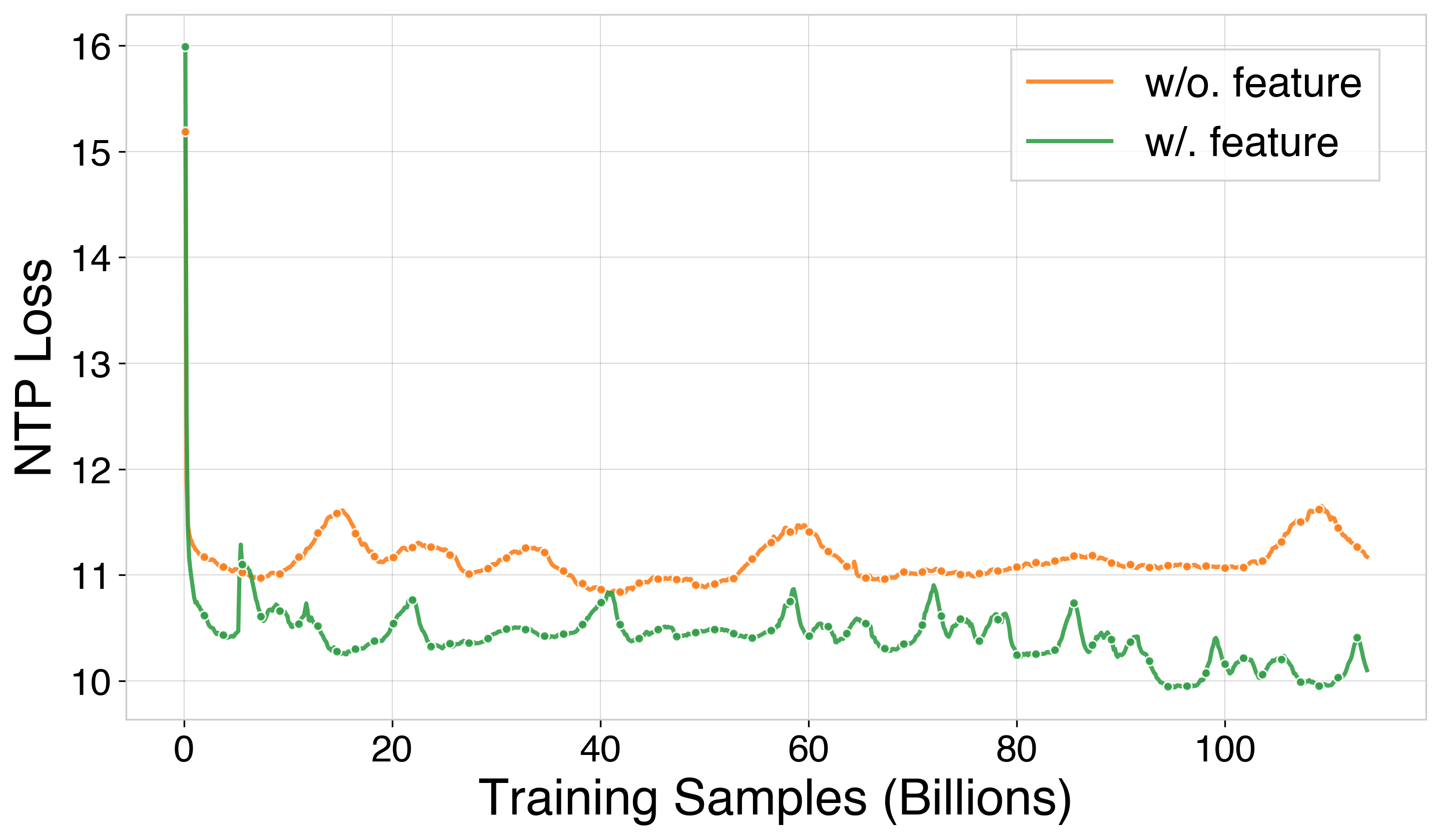
Figure 9: Training loss and performance improvement with additional features.
Codebook scaling (from 8K to 32K) improves playtime and interaction metrics, while inference scaling (Pass@K from 8 to 512) yields consistent gains, with diminishing returns beyond K=512. Semantic identifier input representation matches sparse embedding performance at scale, with advantages in parameter efficiency, communication, and sequence capacity.

Figure 10: Training loss and performance comparison: semantic identifier vs. sparse embedding input.
RL Ablations: Sampling, Search Space, Strategy, and Reference Model
RL increases sampling efficiency, especially at low Pass@K, and expanding the search space (group size) improves performance up to a point. Beam search outperforms top-k/top-p sampling due to the prefix tree structure of semantic IDs. On-policy reference models yield better offline reward evaluation, but online improvements are limited by reward definition.
Format reward integration restores legality rates to >95% and improves online metrics (+0.13% App Stay Time, +0.30% Watch Time). Industrial Reward (SIR) reduces viral content exposure by 9.59% without degrading core metrics.
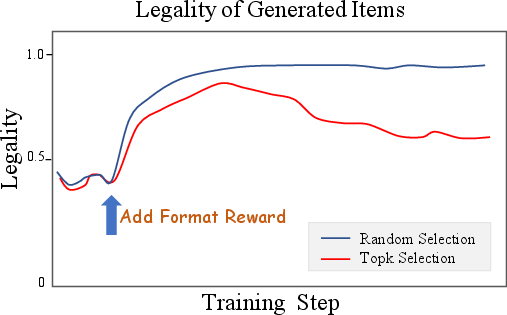
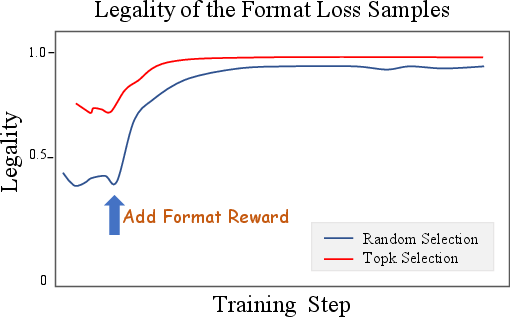
Figure 11: Format reward impact: sampling strategy and legality rates.
Tokenization and Representation Analysis
RQ-Kmeans outperforms RQ-VAE in reconstruction loss, codebook utilization, and entropy, supporting stable and generalizable tokenization. Qualitative analyses show that collaborative-aware multimodal representations retrieve videos with both semantic and behavioral relevance, overcoming limitations of unimodal approaches.
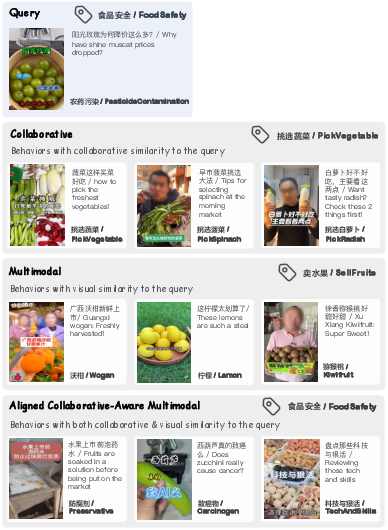
Figure 12: Top-ranked video retrieval using different representation types.

Figure 13: Coarse-to-fine semantic identifiers generated by RQ-Kmeans (Lt=5).
Online A/B Testing and Production Deployment
OneRec was deployed in Kuaishou and Kuaishou Lite, serving 25% of total QPS. In 5% traffic experimental groups, OneRec with reward model selection improved App Stay Time by +0.54% and +1.24%, and LT7 by +0.05% and +0.08%, respectively. These gains are statistically significant at scale. In Local Life Service, OneRec achieved 21.01% GMV growth and >17% increases in order volume, buyer numbers, and new buyer acquisition, taking over 100% of QPS in that scenario.
Inference is performed on NVIDIA L20 GPUs with TensorRT optimization, custom plugins, batching, and MPS, achieving a 5× throughput improvement and 28.8% MFU.
Implications, Limitations, and Future Directions
OneRec demonstrates that end-to-end generative architectures can surpass traditional multi-stage recommender systems in both effectiveness and efficiency, with strong scaling laws, RL integration, and robust tokenization. The system achieves high MFU and low OPEX, supporting large-scale production deployment.
However, inference stage scaling is not yet fully realized, and multimodal integration with LLMs/VLMs remains an open direction. The reward system design is still rudimentary, and further advances in reward modeling are expected to drive future improvements in recommendation quality and system consistency.
Conclusion
OneRec establishes a new paradigm for recommender systems, integrating retrieval and ranking in a unified generative framework with collaborative-aware multimodal tokenization, scalable encoder-decoder architecture, and RL-based reward alignment. The system achieves strong empirical results in both offline and online metrics, with significant improvements in computational efficiency and business impact. Future work should focus on enhancing inference reasoning, multimodal integration, and reward system sophistication to further advance the state of large-scale recommendation.