- The paper introduces a novel lazy decoder-only architecture that cuts computational operations by up to 94% and optimizes scaling.
- It integrates duration-aware reward shaping and Gradient-Bounded Policy Optimization to align recommendations with real-world user feedback.
- Empirical results demonstrate efficient scalability from 0.1B to 8B parameters, leading to improved convergence and enhanced interaction metrics.
OneRec-V2: Advancements in Generative Recommendation Systems
Introduction
The OneRec-V2 technical report presents significant improvements over the previously deployed OneRec-V1 recommender system, focusing on scaling efficiency and alignment with real-world user feedback. The key innovations include a lazy decoder-only architecture and the integration of user feedback signals for reinforcement learning, which address the limitations of the initial version's encoder-decoder architecture and reward model-based policy optimization.
Lazy Decoder-Only Architecture
The novel architecture employed by OneRec-V2 significantly enhances computational efficiency by re-engineering the decoder component of the model. In contrast to traditional encoder-decoder structures where most resources are consumed by context encoding, the lazy decoder-only architecture eliminates the encoder, thereby centralizing computational efforts on the token generation necessary for recommendation.
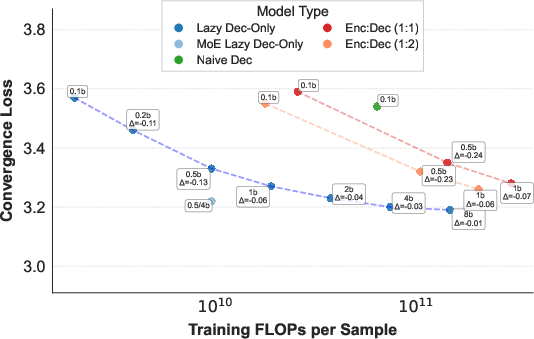
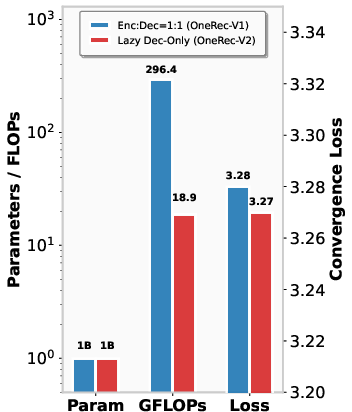
Figure 1: Left: Scaling curves for various model architectures from 0.1B to 8B parameters, among which Lazy Decoder-only models demonstrate best scaling efficiency. Right: OneRec-V1 v.s. OneRec-V2 at 1B parameters.
The lazy decoder achieves a marked reduction in computational requirements—cutting total operations by 94% and training resources by 90%. This efficiency enables the scaling of the model up to 8 billion parameters, providing substantial improvements in model performance without prohibitive resource costs.
Preference Alignment with Real-World User Interactions
OneRec-V2 introduces a novel system for aligning model outputs with user preferences using real-world user interaction data. Rather than wholly relying on constructed reward models, this system employs duration-aware reward shaping to mitigate biases implicit in raw user feedback, such as video duration bias. By considering the quantiles of video playtimes within user-specific duration buckets, the system ensures that user preference scoring more accurately reflects content quality rather than duration.
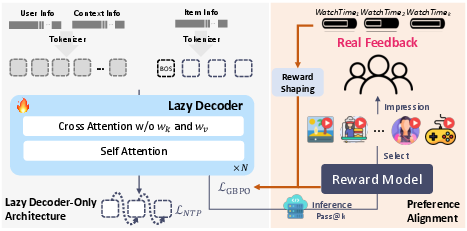
Figure 2: The overall architecture and post-training framework of OneRec-V2. The left panel illustrates the Lazy Decoder-Only Architecture, The right panel depicts the post-training preference alignment process.
Additionally, the implementation of Gradient-Bounded Policy Optimization (GBPO) offers an alternative to traditional ratio-clipping methods by fostering stable gradient dynamics across training samples. This approach facilitates the stable and effective integration of user feedback into the model's iterative learning process.
Empirical Results and Model Scaling
Extensive empirical analysis highlights the efficiency and scalability of the lazy decoder-only architecture. Across varying model sizes—from 0.1 billion to 8 billion parameters—the architecture exhibits improved convergence loss and computational efficiency compared to both encoder-decoder and naive decoder-only models.
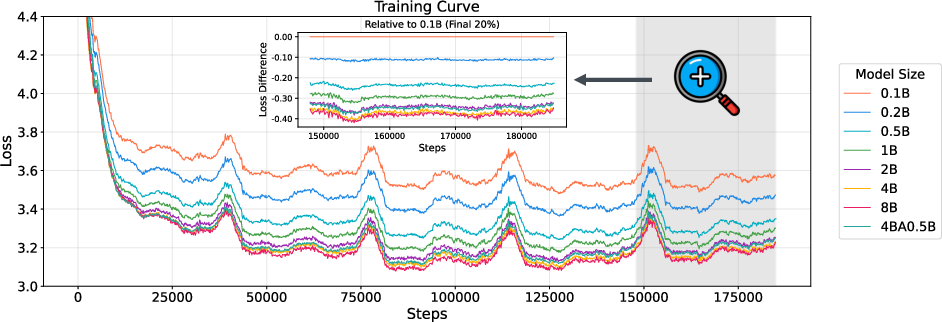
Figure 3: Training dynamics of lazy decoder architectures across model scales. Convergence loss decreases from 3.57 (0.1B) to 3.19 (8B). The 4B MoE variant (0.5B activated), denoted as 4BA0.5B in the figure, achieves competitive performance while maintaining computational efficiency.
The model effectively scales, with the 8B model achieving a convergence loss of 3.19, demonstrating strong scaling properties previously unachievable with OneRec-V1. The integration of Mixture-of-Experts (MoE) variants further enhances scaling potential, yielding competitive performance levels at computational budgets equivalent to much smaller dense models.
Online A/B Testing
Online A/B testing conducted on major platforms like Kuaishou shows that OneRec-V2 significantly advances over OneRec-V1. The platform observed a 0.467% increase in App Stay Time and positive improvements across interaction metrics such as likes, comments, and shares without seesaw effects that might unfavorably bias trade-offs between competing objectives.
Conclusion
The advancements realized in OneRec-V2 illustrate a sophisticated approach to scaling generative recommendation systems, with a focus on computational efficiency and relevance of user feedback. These contributions position OneRec-V2 as a critical asset in optimizing recommendation strategies across large-scale platforms. Future work can continue to refine scaling laws and enhance the reward system through refined user feedback mechanisms and long-term optimization strategies.