OpenOneRec Technical Report
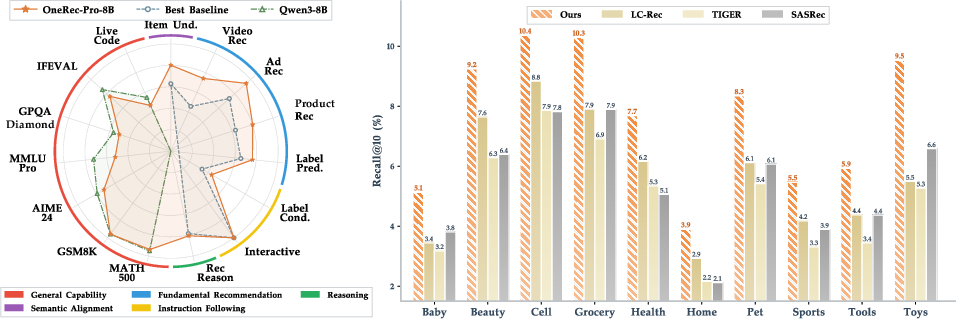
Abstract: While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
First 10 authors:


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about building smarter, more general-purpose recommendation systems—the kind that suggest videos, products, or ads you might like. The authors introduce a new family of models called OneRec-Foundation and a big, carefully designed benchmark called RecIF-Bench. Their goal is to make recommenders work more like modern LLMs: able to understand instructions, reason, and explain their choices, not just match patterns.
What questions were they trying to answer?
- How can we teach a recommendation model to be good at lots of different tasks, not just predicting the “next item”?
- Can we connect recommendation data (like user-item interactions) with language, so the model can follow instructions and explain itself?
- If we train on massive data like LLMs do, will recommendation abilities grow in a predictable way—and can we avoid forgetting general knowledge (like math or coding)?
- Can one model work well across different domains (short videos, ads, products) and transfer to new datasets (like Amazon) while still doing well on general LLM tests?
How did they do it?
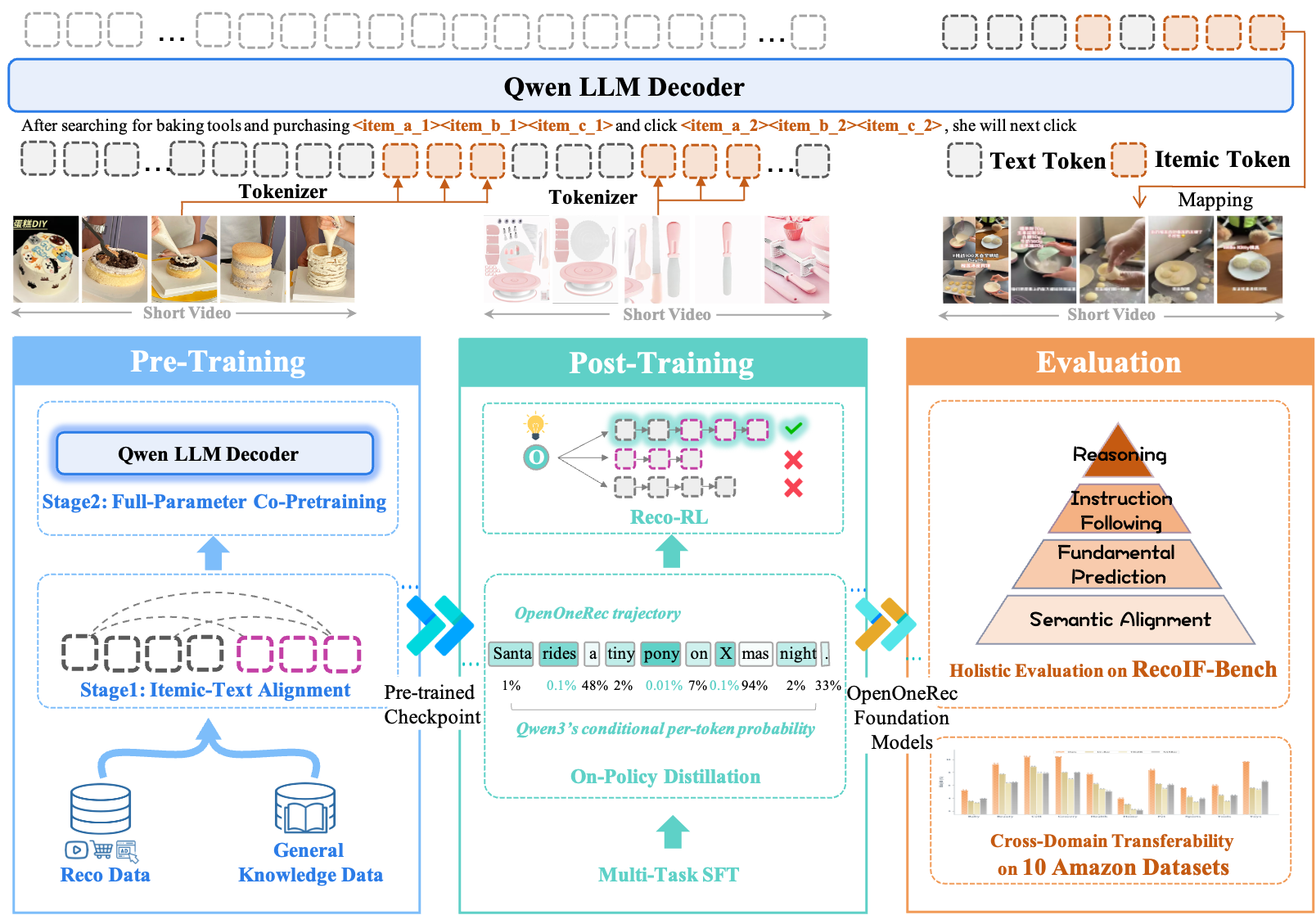
Turning items into tokens (like giving items short nicknames)
Normally, LLMs read words. Items (like videos or products) aren’t words. So the authors create “itemic tokens,” short code-like sequences that represent each item. Think of it like compressing a movie’s description into a few letters that still capture its meaning. Similar items share parts of their code, so the model can learn relationships between items just like it learns relationships between words.
One model for many tasks
They treat everything—predicting the next item, answering questions, or generating explanations—as the same basic job: “what should the next token be?” This way, the same model and training pipeline can handle recommendations and language tasks together.
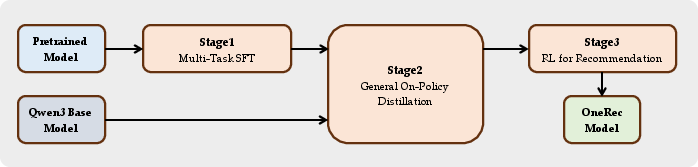
Training in two big steps
- Step 1: Alignment. They teach the model to “understand” item tokens by linking them to text (titles, captions). Only the new item-token embeddings are trained here so the model learns the bridge from items to language.
- Step 2: Co-pretraining. They fully train the model on a mix of recommendation data (long user histories, item metadata) plus general text (math, coding, medical, etc.). Mixing in general text helps prevent the model from “forgetting” how to think or follow instructions.
They use long context windows (up to 32,000 tokens) so the model can read long user histories, like scrolling through a timeline of what someone watched and clicked.
Testing with a new benchmark: RecIF-Bench
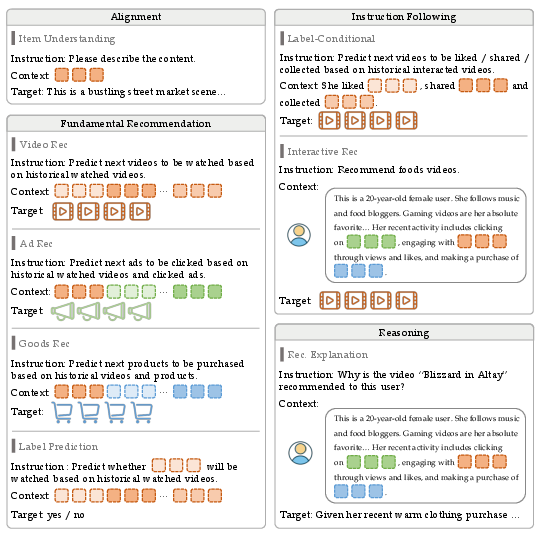
To see if the model is truly “intelligent,” they built RecIF-Bench, which covers 8 tasks across 4 levels:
- Layer 0: Alignment (can the model describe items from their tokens?)
- Layer 1: Fundamentals (can it predict the next video/ad/product or whether a user will engage?)
- Layer 2: Instruction following (can it react to natural-language queries or target specific behaviors like “items the user would Like”?)
- Layer 3: Reasoning (can it explain why an item fits a user?)
They also test on general LLM benchmarks (like math, coding, and knowledge quizzes) to check the model still has broad smarts.
Keeping general smarts while specializing
A common problem is “catastrophic forgetting”: when you train a model too much on one domain, it forgets other skills. To avoid this:
- They mix in general-domain data during training.
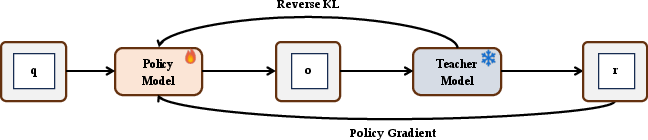
- They use “on-policy distillation,” where the student model generates its own answers and a teacher model (like the original Qwen3) guides it back toward strong reasoning and instruction-following.
- They use reinforcement learning focused on recommendation to polish precision without breaking general abilities.
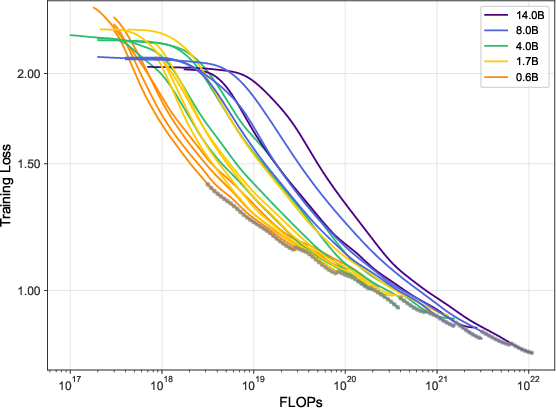
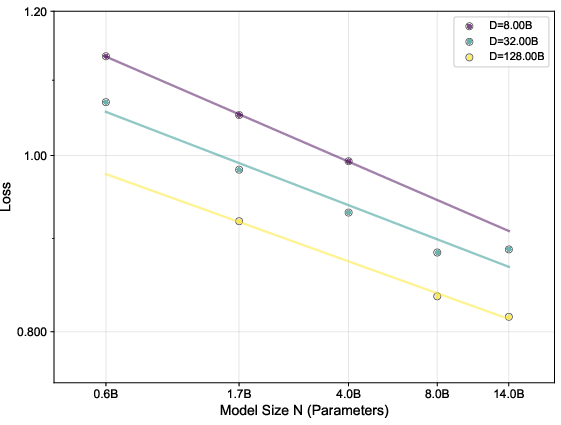
Understanding scaling (does more data or a bigger model help more?)
They study “scaling laws” for recommendation and find a key difference from typical language modeling: as you spend more compute, you should grow training data even faster than model size. In simple terms, practice (more diverse interactions) helps more than just making the model bigger. This suggests recommendation models are especially “data-hungry.”
What did they find?
- OneRec-Foundation models (1.7B and 8B parameters) set state-of-the-art results across all tasks in RecIF-Bench.
- On 10 Amazon datasets, they beat strong baselines by an average of 26.8% in Recall@10 (a measure of how often the correct item appears in the top 10 suggestions).
- The models keep general abilities: they perform well on math, coding, and knowledge tests (like MATH500, LiveCodeBench, and GPQA-Diamond), showing they didn’t forget how to reason or follow instructions.
- Their scaling study shows recommendation training benefits more from adding data than from only increasing model size, which is a practical guide for future training.
Why are these results important?
- Better predictions: The models suggest items more accurately.
- More flexible: They can follow instructions (“show me relaxing short videos”) and explain why they recommended something.
- More robust: They work across different types of content and transfer well to new datasets.
- Still smart: They keep general knowledge and reasoning skills.
Why does it matter?
If recommenders can understand language, reason, and explain themselves, they become more helpful and trustworthy. For users, that means:
- Personalized suggestions that match both your long-term tastes and your current mood.
- Clear explanations of “why this was recommended,” which can build trust.
- Better discovery across different apps and domains (videos, shopping, ads).
For researchers and developers:
- The open data, code, and training recipes make results reproducible and push the field forward.
- RecIF-Bench offers a realistic, multi-task testbed that goes beyond simple “top-N” rankings.
- The scaling insights help teams invest in the right things—collecting diverse, high-quality interaction data—rather than only making models bigger.
In short, this work takes a big step toward recommendation systems that act more like intelligent assistants: they can predict, understand, follow instructions, and explain, all in one unified framework.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
- Validity and reliability of LLM-as-Judge: no empirical calibration (e.g., inter-judge agreement, correlation with human ratings) or sensitivity analyses across different judges and prompts.
- Ground-truth generation for reasoning (Layer 3) via Gemini-2.5-Pro: absence of validation that references are unbiased, accurate, and representative; no human verification or cross-model checks.
- Candidate set definition for Pass@K/Recall@K: unclear whether decoding is constrained to the full inventory or restricted subsets; reproducibility of candidate construction and search space is unaddressed.
- Constrained decoding for itemic tokens: no measurement of invalid or non-existent item code generation rates; lack of guardrails to ensure only valid item tuples are produced.
- Cold-start robustness: no dedicated evaluation for unseen users/items or sparse-history scenarios; strategies for rapid adaptation with minimal data are not explored.
- Dynamic inventory and tokenization updates: how codebooks, itemic tokens, and mappings are maintained as items churn, new items arrive, or metadata changes is unspecified.
- Itemic tokenization design space: no ablations on codebook sizes, quantization depth (#layers), or alternative discretization methods; trade-offs in accuracy vs compression are unquantified.
- Faithfulness of explanations: no tests verifying that generated rationales are causally or diagnostically linked to model decisions (e.g., counterfactual faithfulness or rationale sufficiency).
- Propensity and exposure bias: evaluation relies on logged interactions without off-policy correction, counterfactual estimation, or causal inference to mitigate bias.
- Long-term objectives: Rec-RL design does not report optimization for user well-being or satisfaction beyond immediate engagement; lack of metrics capturing long-term utility or diversity.
- Rec-RL details: reward shaping, off-policy/online setup, stability, and safety constraints are not specified; risk of overfitting to popularity or clickbait remains unaddressed.
- On-policy distillation vocabulary mismatch: teacher lacks itemic tokens; the paper is truncated and does not explain the mapping/handling strategy, training stability, or performance impact.
- Scaling laws measured only on training loss: missing linkage between loss envelope and downstream RecIF-Bench metrics; need validation that scaling exponents predict real recommendation performance.
- Non-from-scratch scaling confounds: acknowledged but unresolved separation of backbone pretraining effects from recommendation-domain scaling; calls for larger-scale, from-scratch studies.
- Compute and latency constraints: 32K context windows and 8B+ models pose inference challenges; no profiling or strategies for truncation, retrieval, caching, or efficient serving in production.
- Multimodal integration: item-side embeddings are provided, but the model architecture appears text-only; end-to-end multimodal training and the impact of raw vision/audio inputs are unexplored.
- Fairness and bias: no audits across demographics, regions, or content categories; absence of fairness metrics, parity analyses, or mitigation methods.
- Privacy risks: “user portraits” include rich behavioral and demographic details; privacy guarantees (e.g., k-anonymity, differential privacy) for the open dataset are not documented.
- Safety and ethics: no safeguards against amplifying harmful content, manipulative ads, or addictive recommendation loops; lack of policy-compliance evaluation (beyond IFEVAL prompt adherence).
- Interactive recommendation queries: unclear origin (mined vs synthesized), linguistic diversity, and realism; robustness to ambiguous, adversarial, or multi-turn queries is not assessed.
- Interleaved data processing limits: no ablations quantifying how much user portrait interleaving contributes vs sequential logs; potential overfitting to narrative structures is unexamined.
- Cross-domain transfer breadth: transfer is shown to Amazon datasets, but other platforms, languages, and modalities are not tested; generalization to non-video/product domains is unknown.
- Component contribution: no systematic ablations disentangling gains from Itemic Dense Captions, Sequential Behavior, Persona Grounding, SFT, on-policy distillation, and Rec-RL.
- Human evaluation: user studies or A/B tests are absent; offline metrics may not reflect user satisfaction, diversity, or serendipity.
- Data quality and noise: label noise in multi-behavior logs, impression bias, and missing negatives are not quantified; data cleaning for recommendation-specific corpora is under-specified.
- Licensing and usage constraints: terms for the released dataset and checkpoints (commercial use, redistribution, derivative works) are unspecified; reproducibility boundaries are unclear.
- Model size trade-offs: limited exploration beyond 8B deployment; resource/performance curves, quantization/pruning, and memory optimization strategies are not presented.
- OOD robustness: no stress tests under distribution shift (e.g., seasonal changes, policy shifts, content floods), nor strategies for continual learning without forgetting.
- Inventory coverage vs semantic alignment: claim that hierarchical itemic tokens aid proximity transfer is not empirically validated with cluster-level analyses or controlled semantic similarity tests.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient update in Adam to improve generalization. "We use the AdamW optimizer"
- AUC: Area Under the ROC Curve; a metric for binary classification performance. "AUC"
- Autoregressive generation: A modeling approach that predicts the next token conditioned on previous tokens. "formulate the recommendation task as a standard autoregressive generation problem."
- Catastrophic forgetting: The loss of previously learned knowledge when training on new data distributions. "mitigating catastrophic forgetting of general knowledge."
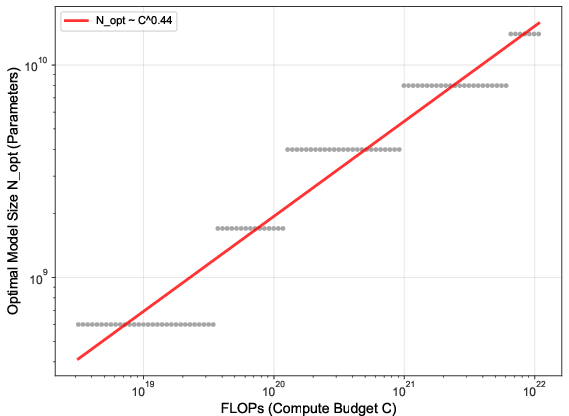
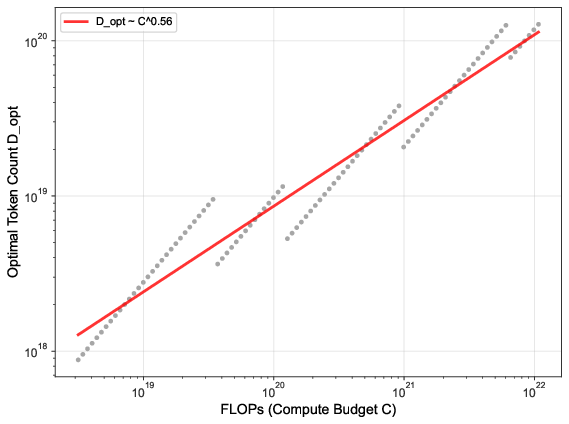
- Chinchilla scaling laws: Empirical rules describing compute/data/model size trade-offs for optimal LM training. "deviates significantly from the Chinchilla scaling laws for general text"
- Compute budget: The total computational resources (often in FLOPs) allocated for training. "optimal allocation of compute budget between model parameters and training tokens "
- Compute-optimal frontier: The best achievable loss for a given compute budget across model/data choices. "define the compute-optimal frontier"
- Convex hull: The smallest convex set containing a set of points; used here to define the optimal loss envelope. "constructing the convex hull of the final training loss"
- Cosine decay schedule: A learning rate schedule that decays following a cosine curve. "The learning rate follows a cosine decay schedule"
- Cross-domain transferability: The ability of a model trained in one domain to perform well in another. "validates cross-domain transferability on Amazon datasets."
- Data silos: Isolated datasets that prevent scalable data sharing and learning. "isolated data silos"
- FLOPs: Floating point operations; a proxy for compute used to compare training runs. "training loss vs. FLOPs for different model sizes"
- Hierarchical quantization: Multi-level discretization of continuous embeddings into codebooks for compact representation. "apply the hierarchical quantization strategy"
- Interleaved Data: Inputs that combine text tokens with specialized item tokens in a single sequence. "Interleaved Data"
- Irreducible entropy: The inherent uncertainty in the data distribution that sets a lower bound on achievable loss. "represents the irreducible entropy of the data distribution"
- Itemic Tokens: Discrete token sequences that represent items via quantized embeddings. "Itemic Tokens"
- LLM-as-Judge: An evaluation protocol where an independent large model assesses generated outputs. "LLM-as-Judge"
- MinHash algorithm: A probabilistic technique for fast similarity estimation and deduplication. "we employ the MinHash algorithm"
- On-policy distillation: Knowledge transfer where the student is supervised on trajectories it generates itself. "on-policy distillation"
- Pass@K: Metric indicating whether the ground-truth item appears among the top-K generated candidates. "Pass@K measures whether the ground truth item appears in the top-K generated candidates"
- Policy gradient: A reinforcement learning method that optimizes policies via gradients of expected rewards. "policy gradient methods"
- Power-law scaling relations: Relationships where optimal sizes or losses scale as powers of compute/data. "fitted to power-law scaling relations"
- Recall@10: The fraction of relevant items retrieved among the top 10 predictions. "26.8% improvement in Recall@10"
- Rec-RL: Reinforcement learning methods tailored to optimize recommendation objectives. "recommendation-oriented Reinforcement Learning (Rec-RL)"
- Reverse KL divergence: A divergence measure used here as a per-token objective to align student with teacher distributions. "per-token reverse KL divergence"
- RQ-Kmeans: A residual quantization approach using K-means to discretize embeddings into hierarchical codes. "We employ RQ-Kmeans"
- Scaling laws: Empirical rules that describe how performance scales with data, model size, and compute. "validate scaling laws in recommendation"
- Sequence-to-sequence problem: Framing tasks as mapping an input sequence to an output sequence. "instantiate each task as a sequence-to-sequence problem"
- Tied embeddings: A configuration where input embeddings and output projection weights are shared. "employ tied embeddings"
- User Portrait: A unified narrative profile interleaving natural language attributes with item tokens. "User Portrait"
Practical Applications
Immediate Applications
Below are practical, deployable use cases that organizations and individuals can adopt now, leveraging the paper’s released models, datasets, methods, and tooling.
- Open-source foundation recommender deployment across content, ads, and commerce
- Sectors: media/short-video, advertising, e-commerce
- What: Fine-tune and deploy OneRec-Foundation (1.7B/8B) as a unified generative recommender for short videos, ad targeting, and product recommendations; exploit demonstrated cross-domain gains (e.g., +26.8% Recall@10 on Amazon benchmarks).
- Tools/workflows: Use the released training pipeline (PyTorch + VeRL), itemic tokenizer, co-pretraining, and post-training recipes to adapt models on proprietary logs; run A/B tests against existing recommenders.
- Assumptions/dependencies: Access to domain logs and item metadata; compute for 32K context; compliance with data governance; integration with existing ranking/retrieval stacks.
- Interactive, instruction-following recommendation in apps and web
- Sectors: media, retail, travel, education (analogous content catalogs)
- What: Power conversational “find me something relaxing/funny/under $50” experiences using the L2 Interactive Rec task; support user-in-the-loop preference control via natural language.
- Tools/workflows: Chat interface + model prompts combining user portrait and recent context; guardrails with SFT prompts; use Label-Conditional Rec for action-specific responses (e.g., “likely to like/share”).
- Assumptions/dependencies: Reliable portrait construction pipelines; latency-optimized serving; prompt safety filters; user consent for personalization signals.
- Explainable recommendations for transparency and trust
- Sectors: regulated platforms (EU DSA/AI Act contexts), commerce, media
- What: Generate natural-language justifications (L3) that tie item features to user profiles and histories, boosting transparency and support/appeals workflows.
- Tools/workflows: Explanations API that uses RecIF-Bench reasoning prompts; log explanations with recommendations; UX components for “Why this?” affordances.
- Assumptions/dependencies: High-quality user portraits; oversight to avoid hallucinated or sensitive explanations; monitoring for bias.
- Action-optimized targeting for ads and campaigns
- Sectors: advertising/marketing technology
- What: Label-Conditional Recommendation (L2) to target by desired downstream action (e.g., like, share, purchase proxy), enabling goal-conditioned delivery.
- Tools/workflows: Campaign setup with behavioral goal; inference workflow that conditions on action token; offline policy evaluation; A/B flighting.
- Assumptions/dependencies: Calibrated labels; clear success metrics; guard against reward hacking; traffic allocation controls.
- Cold-start and catalog enrichment via itemic-text alignment
- Sectors: retail marketplaces, media libraries
- What: Use Item Understanding (L0) to synthesize or standardize captions/titles from itemic tokens; mitigate cold-start by aligning discrete IDs to rich text semantics.
- Tools/workflows: Itemic tokenizer on multimodal embeddings; batch captioning pipelines; metadata QA with LLM-as-judge scoring.
- Assumptions/dependencies: Availability of multimodal embeddings; human-in-the-loop QA; IP considerations for generated descriptions.
- Unifying siloed pipelines into an end-to-end generative flow
- Sectors: platforms with fragmented rec stages (candidate gen, ranking, re-ranking)
- What: Replace multi-stage heuristic stacks with the unified Next-Token Prediction formulation across retrieval, ranking, label prediction, and explanations.
- Tools/workflows: Single policy model with instruction templates per task; shared vocabulary over text and item tokens; multi-task SFT + Rec-RL.
- Assumptions/dependencies: Transition plan with shadow traffic; safe fallback ranking; feature parity checks.
- RecIF-Bench as a regression suite for recommender QA
- Sectors: industry R&D, MLOps
- What: Use the benchmark’s 8-task battery (prediction→reasoning) to gate model updates, avoiding regressions in instruction-following or reasoning while improving core metrics.
- Tools/workflows: CI pipelines that run RecIF-Bench; LLM-as-judge harness for text tasks; dashboards across Pass@K/Recall@K and explanation quality.
- Assumptions/dependencies: Stable benchmark seeds; judge-model version pinning; fairness and safety checks outside benchmark scope.
- Data-mixing and co-pretraining to mitigate catastrophic forgetting
- Sectors: any LLM-based recommender development
- What: Adopt the paper’s recipe of mixing general-domain reasoning/coding text with rec-domain logs to retain world knowledge and instruction following.
- Tools/workflows: Token budget planners; deduplication (MinHash) to avoid leakage; curriculum from itemic-text alignment to full co-pretraining.
- Assumptions/dependencies: High-quality general corpora (licenses); compute to sustain long-context training; careful data mixing ratios.
- On-policy distillation to restore general reasoning in specialized recommenders
- Sectors: LLM platform teams; applied research
- What: Use reverse-KL on-policy distillation from a general teacher (e.g., Qwen3) to the rec-specialized student to recover math/coding/logic abilities without hurting rec performance.
- Tools/workflows: Teacher-student training harness; per-token clipped reverse KL rewards; stability tuning.
- Assumptions/dependencies: Compatible licenses for teacher; vocabulary bridging for item tokens; reward clipping/calibration.
- Practical scaling-law guidance for compute and data budgeting
- Sectors: MLOps, research planning
- What: Apply the empirically derived data-intensive scaling (N_opt ∝ C0.44, D_opt ∝ C0.56) to prioritize dataset growth/curation over parameter count at higher budgets.
- Tools/workflows: “Scaling planner” spreadsheet/service that recommends model/data mix per compute; dataset quality monitoring.
- Assumptions/dependencies: Similar data regime to paper; transfer from warm-start settings; re-validation at larger scales.
- On-device or edge personalization with compact models
- Sectors: mobile platforms, set-top devices, in-car systems
- What: Quantize and distill the 1.7B model for low-latency, privacy-preserving local ranking, using cloud for heavy tasks (explanations, long-horizon).
- Tools/workflows: 4/8-bit quantization; mixed cloud-edge orchestration; periodic federated updates (optional).
- Assumptions/dependencies: Hardware acceleration; memory for 32K context may need truncation/windowing; privacy policies for feature storage.
Long-Term Applications
These opportunities are promising but require further research, scaling, engineering, or cross-organizational coordination.
- Generalist, cross-domain foundation recommender for multi-app ecosystems
- Sectors: super-apps, conglomerates, consumer platforms
- What: A single policy that personalizes across short video, ads, shopping, live streams, and services with instruction-following and reasoning.
- Tools/products: Organization-wide itemic vocabulary and shared user portrait standard; unified policy with domain adapters.
- Dependencies: Cross-unit data sharing agreements; identity resolution; robust safety and objective arbitration across domains.
- Standardized explainability and compliance reporting
- Sectors: policy/regulatory tech, platforms in regulated markets
- What: Use L3 reasoning outputs to meet “meaningful information about logic” requirements; build auditable explanation stores and user-facing controls.
- Tools/products: Compliance dashboards; audit trails linking inputs→recommendations→explanations; redress workflows.
- Dependencies: Regulatory acceptance of LLM-generated rationales; bias/fairness testing; templated, non-sensitive explanations.
- Goal-aware, long-term utility optimization via Rec-RL
- Sectors: media and commerce platforms optimizing satisfaction/LTV
- What: Reinforcement learning that balances short-term CTR with long-term retention, diversity, or well-being; multi-objective policy control.
- Tools/products: Offline RL with counterfactual estimators; simulators; safe policy constraints; diversity/novelty regularizers.
- Dependencies: Logged propensities/CAUSAL signals; robust simulators; safe deployment protocols; stakeholder-aligned objectives.
- Zero-shot and few-shot transfer to new domains with itemic tokenization
- Sectors: marketplaces, education platforms, travel, job matching
- What: Rapidly bring a new catalog online by quantizing multimodal item embeddings, enabling initial recommendations before dense interaction accumulation.
- Tools/products: Domain-agnostic itemic tokenizer service; semantic bootstrapping from captions/images.
- Dependencies: Strong multimodal encoders; well-covered codebooks; domain-specific evaluation and safety checks.
- Privacy-preserving, federated foundation recommenders
- Sectors: mobile ecosystems, healthcare-like sensitive domains (adapted use)
- What: Train or adapt models across devices/institutions without raw data centralization using federated and secure aggregation techniques.
- Tools/products: Federated co-pretraining; privacy accounting; secure itemic token updates.
- Dependencies: Communication-efficient 32K-context handling; DP guarantees; institutional buy-in; robust drift detection.
- Marketplace of standardized itemic vocabularies and embeddings
- Sectors: data vendors, platforms, interoperable ecosystems
- What: Shared, versioned itemic codebooks per vertical to ease interop and cold-start for third-party apps and small businesses.
- Tools/products: Registry services; validation suites; embedding-to-token calibration APIs.
- Dependencies: Governance and IP frameworks; consensus on standards; backward compatibility.
- Adaptive user-portrait memory systems with controllable transparency
- Sectors: consumer apps, productivity tools, enterprise portals
- What: Dynamic, user-editable portraits that integrate history, preferences, and intents across contexts; user controls to steer recommendations.
- Tools/products: Memory management UIs; privacy-preserving storage; portrait editing and “preference scripts.”
- Dependencies: Clear consent and UX; consistent cross-app identity; secure storage and sync.
- Multi-modal, multi-agent recommendation reasoning
- Sectors: complex B2B procurement, creative discovery, education
- What: Agents that debate or critique recommendations, incorporating vision/language signals and constraints (budget, diversity, skills).
- Tools/products: Judge/critic models; committee-of-experts routing; tool-use for inventory/pricing.
- Dependencies: Orchestration frameworks; latency budgets; robust evaluation beyond LLM-as-judge.
- AutoML for recommender scaling and budgeting
- Sectors: platform infra, MLOps vendors
- What: Systems that select model size, token budgets, and data-mixing ratios based on the paper’s scaling laws and observed loss curves.
- Tools/products: Budget planners; automatic curriculum scheduling; token allocation optimizers.
- Dependencies: Reliable telemetry of loss vs. compute; generalization of scaling exponents beyond current range; cost governance.
- Safety- and fairness-aware instruction-following recommenders
- Sectors: platforms with UGC and sensitive catalogs
- What: Policies that heed user instructions while enforcing safety, de-biasing, and exposure diversity, with auditable controls.
- Tools/products: Constraint prompts; counterfactual fairness tests; diversity targets; policy simulation tools.
- Dependencies: Agreed safety taxonomies; labeled datasets for fairness; governance review; measurable KPIs.
- Edge-native models with lifelong personalization
- Sectors: wearables, vehicles, home devices
- What: Continual learning on-device that adapts the 1.7B backbone with streaming histories, syncing sparse updates to cloud models.
- Tools/products: Lightweight adapters/LoRA; rehearsal buffers; drift and forgetting monitors.
- Dependencies: Efficient continual learning algorithms; privacy policies; battery/compute constraints.
Notes on Assumptions and Dependencies Across Applications
- Itemic tokens presume access to robust multimodal embeddings and a representative, stable codebook; re-quantization may be required as catalogs drift.
- 32K-token context enables long-horizon modeling but increases compute and latency; production systems often need truncation, windowing, or retrieval-augmented context.
- LLM-as-judge metrics are convenient but imperfect; human evaluation and counterfactual testing are advisable for critical decisions.
- Co-pretraining and on-policy distillation depend on dataset quality and teacher availability/licensing; monitor for license and policy compliance.
- The reported scaling laws were derived from warm-start training and the observed data regime; re-validate when changing domains, scales, or architectures.
Collections
Sign up for free to add this paper to one or more collections.

